
matplotlib Series.plot()---柱状图、直方图、密度图、线形图
pandas.Series.plot
Series.plot(kind='line', ax=None, figsize=None, use_index=True, title=None, grid=None, legend=False, style=None, logx=False, logy=False, loglog=False, xticks=None, yticks=None, xlim=None, ylim=None, rot=None, fontsize=None, colormap=None, table=False, yerr=None, xerr=None, label=None, secondary_y=False, **kwds)¶
功能:画柱状图、直方图、密度图、线形图
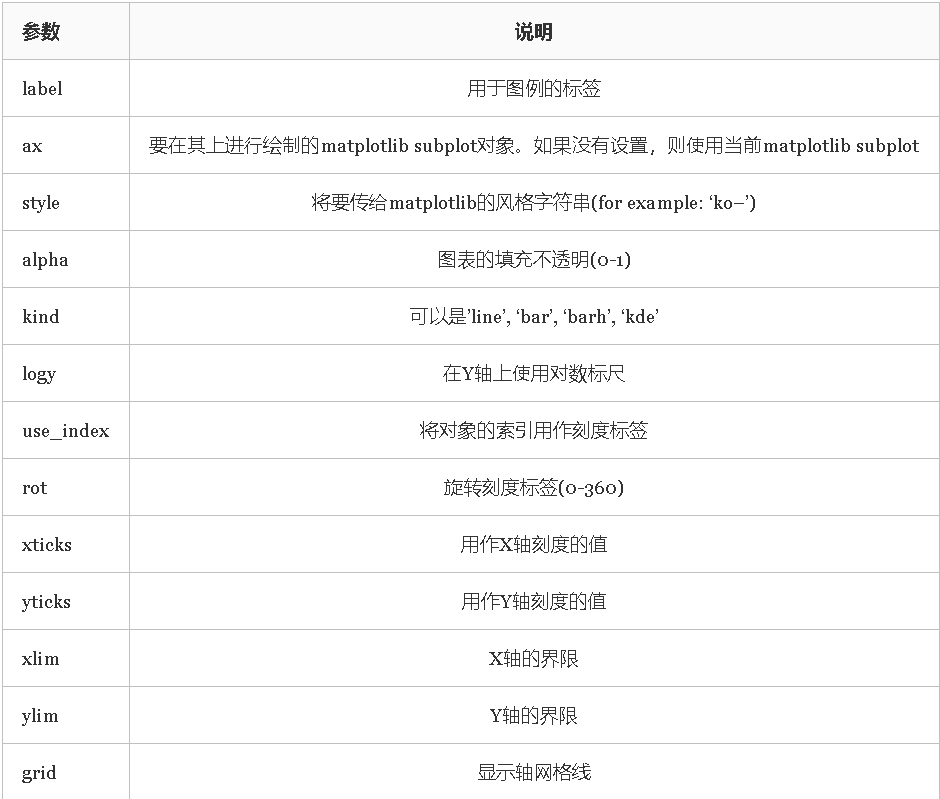
1.柱状图(kind='bar')
优点:人眼对高度较敏感,直观各组数据差异性,强调个体与个体之间的比较
缺点:不适合大量的数据集数据(项数较多)
适用场景:一个维度数据比较、数据单纯性展示、排序数据展示
适用数据:数据集不大, 二维数据
from pylab import mpl mpl.rcParams['font.sans-serif'] = ['SimHei'] # 雅黑字体 mpl.rcParams['axes.unicode_minus'] = False import matplotlib.pyplot as plt fig = plt.figure() from pylab import mpl mpl.rcParams['font.sans-serif'] = ['SimHei'] # 雅黑字体 mpl.rcParams['axes.unicode_minus'] = False fig.set(alpha=0.5) # 设定图表颜色alpha参数 data_train.Survived.value_counts().plot(kind='bar')#柱状图 plots a bar graph of those who surived vs those who did not. plt.title(u"获救情况 (1为获救)") # puts a title on our graph plt.ylabel(u"人数")

2.柱状图(kind='bar')

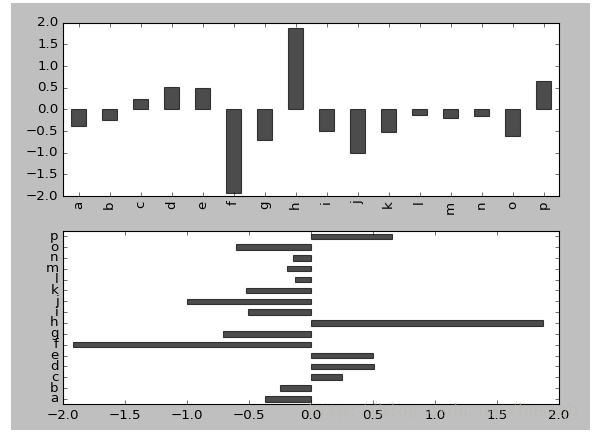
sns.countplot(x='SibSp',hue='Survived',data=df)
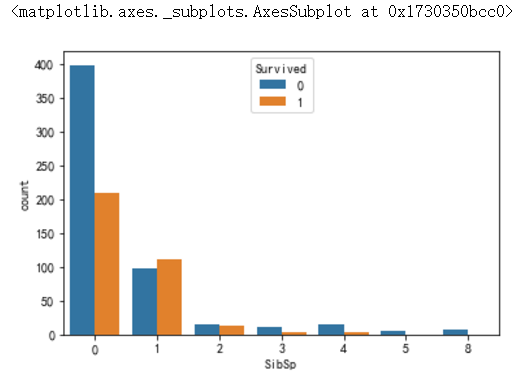
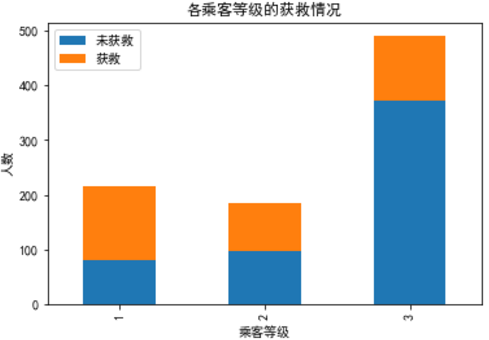
多分类累积柱状图

3.直方图(kind='hist')
直方图(histogram)是一种可以对值频率进行离散化显示的柱状图。数据点被拆分到离散的、间隔均匀的面元中,绘制的是各面元中数据点的数量。
4.密度图(kind='kde')
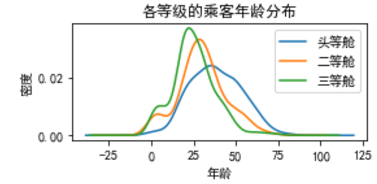
data_train.Age[data_train.Pclass == 1].plot(kind = 'kde')
data_train.Age[data_train.Pclass == 2].plot(kind = 'kde')
data_train.Age[data_train.Pclass == 3].plot(kind = 'kde')
plt.xlabel('年龄')
plt.ylabel('密度')
plt.title('各等级的乘客年龄分布')
plt.legend(('头等舱','二等舱','三等舱'),loc = 'best')
4.线性图(kind='line')
折线图分为 直线折线图和曲线折线图,直线折线图一般适用于离散变量,曲线折线图一般适用于连续变量。
优点:直观反映数据变化趋势
缺点:数据集太小时显示不直观
适用场景:需要反映变化趋势,关联性。
适用数据:时间序列类数据、关联类数据(如电流跟随电压变化而变化)

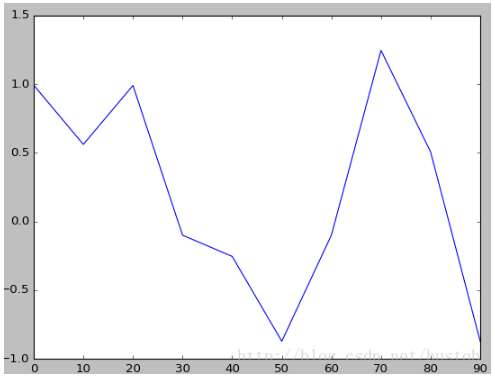
pandas的大部分绘图方法都有一个可选的ax参数,它可以是一个matplotlib的subplot对象。这是你能够在网络布局中更为灵活地处理subplot的位置。DataFrame的plot方法会在一个subplot中为各列绘制一条线,并自动创建图例
df = pd.DataFrame(np.random.randn(10, 4).cumsum(0), columns=list('ABCD'), index=np.arange(0, 100, 10))
df.plot()
plt.show()
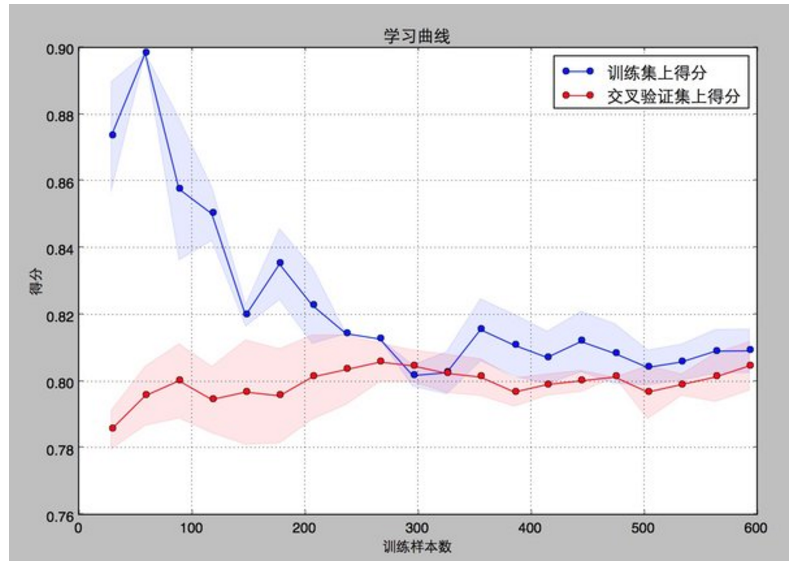
举例:画验证集的学习曲线


5.饼图(kind='pie')
优点: 直观显示各项占总体的占比,分布情况,强调整个与个体间的比较。
缺点:数据不精细,不适合分类较多的情况
适用场景:一个维度各项指标(一般不超过5个项目)占总体的占比情况,分布情况。(例如:不同状态下的车辆分布,公司内各个团队营收收入)
适用数据:具有整体意义的各项相同数据

