

第四天
第四天
新建文件和目录的默认权限
文件权限
umask 的值可以用来保留在创建文件权限
实现方式:
新建文件的默认权限: 666-umask,如果所得结果某位存在执行(奇数)权限,则将其权限+1,偶数不变
新建目录的默认权限: 777-umask
非特权用户umask默认是 002
root的umask 默认是 022
查看**umask**
持久保存umask
全局设置: /etc/bashrc
用户设置:~/.bashrc
r--4
w--2
x--1
umask
显示或设置创建文件的权限掩码。
概要
umask [-p] [-S] [mode]
主要用途
显示当前的文件权限掩码。
通过八进制数的方式设置创建文件的权限掩码。
通过符号组合的方式设置创建文件的权限掩码。
参数
mode(可选):八进制数或符号组合。
选项
-p:当没有参数时指定该选项,执行产生的输出格式可复用为输入;
-S:以符号组合的方式输出创建文件的权限掩码,不使用该选项时以八进制数的形式输出。
返回值
返回状态为成功除非给出了非法选项或非法参数。
例子
以下的例子均假设文件权限掩码为0022。
# 以八进制数的形式输出创建文件的权限掩码。
umask -p
# 执行结果:
umask 0022
# 以符号组合的方式输出创建文件的权限掩码。
umask -S
# 执行结果:
u=rwx,g=rx,o=rx
参考man chmod文档的DESCRIPTION段落得知:
u符号代表当前用户。
g符号代表和当前用户在同一个组的用户,以下简称组用户。
o符号代表其他用户。
a符号代表所有用户。
r符号代表读权限以及八进制数4。
w符号代表写权限以及八进制数2。
x符号代表执行权限以及八进制数1。
+符号代表添加目标用户相应的权限。
-符号代表删除目标用户相应的权限。
=符号代表添加目标用户相应的权限,删除未提到的权限。
那么刚才以符号形式输出的结果u=rwx,g=rx,o=rx转化为八进制数等于0755;
用八进制数来设置同样的权限,umask需要额外的执行减法0777 - 0755即0022,而chmod不需要。
符号组合模式的添加、删除、赋值权限。
# 添加权限:
# 为组用户添加写权限。
umask g+w
# 删除权限:
# 删除其他用户的写、执行权限
umask o-wx
# 赋值权限:
# 赋值全部用户所有权限,等价于umask u=rwx,g=rwx,o=rwx
umask a=rwx
# 清除其他用户的读、写、执行权限。
umask o=
创建文件夹、文件(假设当前目录不存在)
# 创建文件
touch test.sh
# 查看权限,发现执行权限的设置不起作用。
stat test.sh
# 创建文件夹
touch newdir
# 查看权限,发现执行权限的设置可以起作用。
stat newdir
注意
该命令是bash内建命令,相关的帮助信息请查看help命令。
chmod用于更改已有对象的权限,umask影响之后新建对象的权限。
请谨慎使用该命令,特别是不要取消当前用户的读取权限,那样会导致你在终端使用TAB键补全时报错。
重点
文件的执行是非常危险的,但是目录的执行权限是常规的
如果没有执行权限,root也无法执行
基于安全考虑,默认新建的文件不允许有执行权限(这也是为什么奇数要加1的原因)
root默认umask为022 。其他用户默认为022
umask值越大意味着,权限越小,越安全
为什么root的umask值要大呢?
相对root的文件更重要,所以权限要越小一些
安全和便利是一对矛盾
只实现临时性的文件权限为000
$$
$$
1. touch a.txt ; chmod 000 a.txt
2. umask 777 ; touch a.txt;umask 022
3.(umask 777;touch a.txt) 小括号内的umask是可以一次性有效
Linux****文件系统上的特殊权限
前面介绍了三种常见的权限:r, w, x 还有三种特殊权限:SUID, SGID, Sticky
特殊权限
SUID 作用于二进制可执行文件上,用户将继承此程序所有者的权限
SGID
作用于二进制可执行文件上,用户将继承此程序所有组的权限
作于于目录上, 此目录中新建的文件的所属组将自动从此目录继承
STICKY 作用于目录上,此目录中的文件只能由所有者自已来删除
**** 特殊权限****SUID
前提:进程有属主和属组;文件有属主和属组
任何一个可执行程序文件能不能启动为进程,取决发起者对程序文件是否拥有执行权限
启动为进程之后,其进程的属主为发起者,进程的属组为发起者所属的组
进程访问文件时的权限,取决于进程的发起者
二进制的可执行文件上SUID权限功能:
任何一个可执行程序文件能不能启动为进程:取决发起者对程序文件是否拥有执行权限
启动为进程之后,其进程的属主为原程序文件的属主
SUID只对二进制可执行程序有效
SUID设置在目录上无意义
SUID权限设定:
chmod u+s FILE...
chmod 4xxx FILE
chmod u-s FILE...
范例
[root@centos8 ~]#ls -l /usr/bin/passwd
-rwsr-xr-x. 1 root root 34928 May 11 2019 /usr/bin/passwd
特殊权限****SGID
二进制的可执行文件上SGID权限功能:
任何一个可执行程序文件能不能启动为进程:取决发起者对程序文件是否拥有执行权限
启动为进程之后,其进程的属组为原程序文件的属组
SGID权限设定:
chmod g+s FILE...
chmod 2xxx FILE
chmod g-s FILE...
目录上的SGID权限功能:
默认情况下,用户创建文件时,其属组为此用户所属的主组,一旦某目录被设定了SGID,则对此目录有
写权限的用户在此目录中创建的文件所属的组为此目录的属组,通常用于创建一个协作目录
SGID权限设定:
chmod g+s DIR...
chmod 2xxx DIR
chmod g-s DIR...
特殊权限 Sticky 位
具有写权限的目录通常用户可以删除该目录中的任何文件,无论该文件的权限或拥有权
在目录设置Sticky 位,只有文件的所有者或root可以删除该文件
sticky 设置在文件上无意义
Sticky权限设定:
chmod o+t DIR...
chmod 1xxx DIR
chmod o-t DIR...
范例
[root@centos8 ~]#ll -d /tmp
drwxrwxrwt. 15 root root 4096 Dec 12 20:16 /tmp
特殊权限数字法
SUID SGID STICKY
000 0
001 1
010 2
011 3
100 4
101 5
110 6
111 7
范例
chmod 4777 /tmp/a.txt
权限位映射
SUID: user,占据属主的执行权限位
s:属主拥有x权限
S:属主没有x权限
SGID: group,占据属组的执行权限位
s: group拥有x权限
S:group没有x权限
Sticky: other,占据other的执行权限位
t:other拥有x权限
T:other没有x权限
设定文件特殊属性
chattr
用来改变文件属性
补充说明
chattr命令 用来改变文件属性。这项指令可改变存放在ext2文件系统上的文件或目录属性,这些属性共有以下8种模式:
语法
chattr(选项)
选项
a:让文件或目录仅供附加用途;
b:不更新文件或目录的最后存取时间;
c:将文件或目录压缩后存放;
d:将文件或目录排除在倾倒操作之外;
i:不得任意更动文件或目录;
s:保密性删除文件或目录;
S:即时更新文件或目录;
u:预防意外删除。
-R:递归处理,将指令目录下的所有文件及子目录一并处理;
-v<版本编号>:设置文件或目录版本;
-V:显示指令执行过程;
+<属性>:开启文件或目录的该项属性;
-<属性>:关闭文件或目录的该项属性;
=<属性>:指定文件或目录的该项属性。
实例
用chattr命令防止系统中某个关键文件被修改:
chattr +i /etc/fstab
然后试一下rm、mv、rename等命令操作于该文件,都是得到Operation not permitted的结果。
让某个文件只能往里面追加内容,不能删除,一些日志文件适用于这种操作:
chattr +a /data1/user_act.log
lsattr
查看文件的第二扩展文件系统属性
补充说明
lsattr命令 用于查看文件的第二扩展文件系统属性。
语法
lsattr(选项)(参数)
选项
-E:可显示设备属性的当前值,但这个当前值是从用户设备数据库中获得的,而不是从设备直接获得的。
-D:显示属性的名称,属性的默认值,描述和用户是否可以修改属性值的标志。
-R:递归的操作方式;
-V:显示指令的版本信息;
-a:列出目录中的所有文件,包括隐藏文件。
lsattr经常使用的几个选项-D,-E,-R这三个选项不可以一起使用,它们是互斥的,经常使用的还有-l,-H,使用lsattr时,必须指出具体的设备名,用-l选项指出要显示设备的逻辑名称,否则要用-c,-s,-t等选项唯一的确定某个已存在的设备。
参数
文件:指定显示文件系统属性的文件名。
实例
lsattr -E -l rmt0 -H
lsattr -EO -l rmt0
访问控制列表 ACL
ACL:Access Control List,实现灵活的权限管理
除了文件的所有者,所属组和其它人,可以对更多的用户设置权限
CentOS7 默认创建的xfs和ext4文件系统具有ACL功能
CentOS7 之前版本,默认手工创建的ext4文件系统无ACL功能,需手动增加
setfacl
设置文件访问控制列表
补充说明
setfacl命令 是用来在命令行里设置ACL(访问控制列表)。在命令行里,一系列的命令跟随以一系列的文件名。
选项
-b,--remove-all:删除所有扩展的acl规则,基本的acl规则(所有者,群组,其他)将被保留。
-k,--remove-default:删除缺省的acl规则。如果没有缺省规则,将不提示。
-n,--no-mask:不要重新计算有效权限。setfacl默认会重新计算ACL mask,除非mask被明确的制定。
--mask:重新计算有效权限,即使ACL mask被明确指定。
-d,--default:设定默认的acl规则。
--restore=file:从文件恢复备份的acl规则(这些文件可由getfacl -R产生)。通过这种机制可以恢复整个目录树的acl规则。此参数不能和除--test以外的任何参数一同执行。
--test:测试模式,不会改变任何文件的acl规则,操作后的acl规格将被列出。
-R,--recursive:递归的对所有文件及目录进行操作。
-L,--logical:跟踪符号链接,默认情况下只跟踪符号链接文件,跳过符号链接目录。
-P,--physical:跳过所有符号链接,包括符号链接文件。
--version:输出setfacl的版本号并退出。
--help:输出帮助信息。
--:标识命令行参数结束,其后的所有参数都将被认为是文件名
-:如果文件名是-,则setfacl将从标准输入读取文件名。
选项-m和-x后边跟以acl规则。多条acl规则以逗号(,)隔开。选项-M和-X用来从文件或标准输入读取acl规则。
选项--set和--set-file用来设置文件或目录的acl规则,先前的设定将被覆盖。
选项-m(--modify)和-M(--modify-file)选项修改文件或目录的acl规则。
选项-x(--remove)和-X(--remove-file)选项删除acl规则。
当使用-M,-X选项从文件中读取规则时,setfacl接受getfacl命令输出的格式。每行至少一条规则,以#开始的行将被视为注释。
当在不支持ACLs的文件系统上使用setfacl命令时,setfacl将修改文件权限位。如果acl规则并不完全匹配文件权限位,setfacl将会修改文件权限位使其尽可能的反应acl规则,并会向standard error发送错误消息,以大于0的状态返回。
权限
文件的所有者以及有CAP_FOWNER的用户进程可以设置一个文件的acl。(在目前的linux系统上,root用户是唯一有CAP_FOWNER能力的用户)
ACL规则
setfacl命令可以识别以下的规则格式:
[d[efault]:] [u[ser]:]uid [:perms] 指定用户的权限,文件所有者的权限(如果uid没有指定)。
[d[efault]:] g[roup]:gid [:perms] 指定群组的权限,文件所有群组的权限(如果gid未指定)
[d[efault]:] m[ask][:] [:perms] 有效权限掩码
[d[efault]:] o[ther] [:perms] 其他的权限
恰当的acl规则被用在修改和设定的操作中,对于uid和gid,可以指定一个数字,也可指定一个名字。perms域是一个代表各种权限的字母的组合:读-r写-w执行-x,执行只适合目录和一些可执行的文件。pers域也可设置为八进制格式。
自动创建的规则
最初的,文件目录仅包含3个基本的acl规则。为了使规则能正常执行,需要满足以下规则。
3个基本规则不能被删除。
任何一条包含指定的用户名或群组名的规则必须包含有效的权限组合。
任何一条包含缺省规则的规则在使用时,缺省规则必须存在。
ACL的名词定义*
先来看看在ACL里面每一个名词的定义,这些名词我大多从man page上摘下来虽然有些枯燥,但是对于理解下面的内容还是很有帮助的。
ACL是由一系列的Access Entry所组成的,每一条Access Entry定义了特定的类别可以对文件拥有的操作权限。Access Entry有三个组成部分:Entry tag type, qualifier (optional), permission。
我们先来看一下最重要的Entry tag type,它有以下几个类型:
ACL_USER_OBJ:相当于Linux里file_owner的permission
ACL_USER:定义了额外的用户可以对此文件拥有的permission
ACL_GROUP_OBJ:相当于Linux里group的permission
ACL_GROUP:定义了额外的组可以对此文件拥有的permission
ACL_MASK:定义了ACL_USER, ACL_GROUP_OBJ和ACL_GROUP的最大权限 (这个我下面还会专门讨论)
ACL_OTHER:相当于Linux里other的permission
让我们来据个例子说明一下,下面我们就用getfacl命令来查看一个定义好了的ACL文件:
[root@localhost ~]# getfacl ./test.txt
# file: test.txt
# owner: root
# group: admin
user::rw-
user:john:rw-
group::rw-
group:dev:r--
mask::rw- other::r--
前面三个以#开头的定义了文件名,file owner和group。这些信息没有太大的作用,接下来我们可以用--omit-header来省略掉。
user::rw- 定义了ACL_USER_OBJ, 说明file owner拥有read and write permission
user:john:rw- 定义了ACL_USER,这样用户john就拥有了对文件的读写权限,实现了我们一开始要达到的目的
group::rw- 定义了ACL_GROUP_OBJ,说明文件的group拥有read and write permission
group:dev:r-- 定义了ACL_GROUP,使得dev组拥有了对文件的read permission
mask::rw- 定义了ACL_MASK的权限为read and write
other::r-- 定义了ACL_OTHER的权限为read
从这里我们就可以看出ACL提供了我们可以定义特定用户和用户组的功能,那么接下来我们就来看一下如何设置一个文件的ACL:
如何设置ACL文件
首先我们还是要讲一下设置ACL文件的格式,从上面的例子中我们可以看到每一个Access Entry都是由三个被:号分隔开的字段所组成,第一个就是Entry tag type。
user 对应了ACL_USER_OBJ和ACL_USER
group 对应了ACL_GROUP_OBJ和ACL_GROUP
mask 对应了ACL_MASK
other 对应了ACL_OTHER
第二个字段称之为qualifier,也就是上面例子中的john和dev组,它定义了特定用户和拥护组对于文件的权限。这里我们也可以发现只有user和group才有qualifier,其他的都为空。第三个字段就是我们熟悉的permission了。它和Linux的permission一样定义,这里就不多讲了。
下面我们就来看一下怎么设置test.txt这个文件的ACL让它来达到我们上面的要求。
一开始文件没有ACL的额外属性:
[root@localhost ~]# ls -l
-rw-rw-r-- 1 root admin 0 Jul 3 22:06 test.txt
[root@localhost ~]# getfacl --omit-header ./test.txt
user::rw- group::rw- other::r--
我们先让用户john拥有对test.txt文件的读写权限:
[root@localhost ~]# setfacl -m user:john:rw- ./test.txt
[root@localhost ~]# getfacl --omit-header ./test.txt
user::rw-
user:john:rw-
group::rw-
mask::rw-
other::r--
这时我们就可以看到john用户在ACL里面已经拥有了对文件的读写权。这个时候如果我们查看一下linux的permission我们还会发现一个不一样的地方。
[root@localhost ~]# ls -l ./test.txt
-rw-rw-r--+ 1 root admin 0 Jul 3 22:06 ./test.txt
在文件permission的最后多了一个+号,当任何一个文件拥有了ACL_USER或者ACL_GROUP的值以后我们就可以称它为ACL文件,这个+号就是用来提示我们的。我们还可以发现当一个文件拥有了ACL_USER或者ACL_GROUP的值时ACL_MASK同时也会被定义。
接下来我们来设置dev组拥有read permission:
[root@localhost ~]# setfacl -m group:dev:r-- ./test.txt
[root@localhost ~]# getfacl --omit-header ./test.txt
user::rw-
user:john:rw-
group::rw-
group:dev:r--
mask::rw-
other::r--
到这里就完成了我们上面讲到的要求,是不是很简单呢。
ACL_MASK和Effective permission
这里需要重点讲一下ACL_MASK,因为这是掌握ACL的另一个关键,在Linux file permission里面大家都知道比如对于rw-rw-r--来说, 当中的那个rw-是指文件组的permission. 但是在ACL里面这种情况只是在ACL_MASK不存在的情况下成立。如果文件有ACL_MASK值,那么当中那个rw-代表的就是mask值而不再是group permission了。
让我们来看下面这个例子:
[root@localhost ~]# ls -l
-rwxrw-r-- 1 root admin 0 Jul 3 23:10 test.sh
这里说明test.sh文件只有file owner: root拥有read, write, execute/search permission。admin组只有read and write permission,现在我们想让用户john也对test.sh具有和root一样的permission。
[root@localhost ~]# setfacl -m user:john:rwx ./test.sh
[root@localhost ~]# getfacl --omit-header ./test.sh
user::rwx user:john:rwx
group::rw-
mask::rwx
other::r--
这里我们看到john已经拥有了rwx的permission,mask值也被设定为rwx,那是因为它规定了ACL_USER,ACL_GROUP和ACL_GROUP_OBJ的最大值,现在我们再来看test.sh的Linux permission,它已经变成了:
[root@localhost ~]# ls -l
-rwxrwxr--+ 1 root admin 0 Jul 3 23:10 test.sh
那么如果现在admin组的用户想要执行test.sh的程序会发生什么情况呢?它会被permission deny。原因在于实际上admin组的用户只有read and write permission,这里当中显示的rwx是ACL_MASK的值而不是group的permission。
所以从这里我们就可以知道,如果一个文件后面有+标记,我们都需要用getfacl来确认它的permission,以免发生混淆。
下面我们再来继续看一个例子,假如现在我们设置test.sh的mask为read only,那么admin组的用户还会有write permission吗?
[root@localhost ~]# setfacl -m mask::r-- ./test.sh
[root@localhost ~]# getfacl --omit-header ./test.sh
user::rwx
user:john:rwx #effective:r--
group::rw- #effective:r--
mask::r--
other::r--
这时候我们可以看到ACL_USER和ACL_GROUP_OBJ旁边多了个#effective:r--,这是什么意思呢?让我们再来回顾一下ACL_MASK的定义。它规定了ACL_USER,ACL_GROUP_OBJ和ACL_GROUP的最大权限。那么在我们这个例子中他们的最大权限也就是read only。虽然我们这里给ACL_USER和ACL_GROUP_OBJ设置了其他权限,但是他们真正有效果的只有read权限。
这时我们再来查看test.sh的Linux file permission时它的group permission也会显示其mask的值(i.e. r--)
[root@localhost ~]# ls -l
-rwxr--r--+ 1 root admin 0 Jul 3 23:10 test.sh
Default ACL
上面我们所有讲的都是Access ACL,也就是对文件而言。下面我简单讲一下Default ACL。Default ACL是指对于一个目录进行Default ACL设置,并且在此目录下建立的文件都将继承此目录的ACL。
同样我们来做一个试验说明,比如现在root用户建立了一个dir目录:
[root@localhost ~]# mkdir dir
他希望所有在此目录下建立的文件都可以被john用户所访问,那么我们就应该对dir目录设置Default ACL。
[root@localhost ~]# setfacl -d -m user:john:rw ./dir
[root@localhost ~]# getfacl --omit-header ./dir
user::rwx
group::rwx
other::r-x
default:user::rwx
default:user:john:rwx
default:group::rwx
default:mask::rwx
default: other::r-x
这里我们可以看到ACL定义了default选项,john用户拥有了default的read, write, excute/search permission。所有没有定义的default都将从file permission里copy过来,现在root用户在dir下建立一个test.txt文件。
[root@localhost ~]# touch ./dir/test.txt
[root@localhost ~]# ls -l ./dir/test.txt
-rw-rw-r--+ 1 root root 0 Jul 3 23:46 ./dir/test.txt
[root@localhost ~]# getfacl --omit-header ./dir/test.txt
user::rw-
user:john:rw-
group::rwx #effective:rw-
mask::rw-
other::r--
这里我们看到在dir下建立的文件john用户自动就有了read and write permission,
ACL相关命令
前面的例子中我们都注意到了getfacl命令是用来读取文件的ACL,setfacl是用来设定文件的Acess ACL。这里还有一个chacl是用来改变文件和目录的Access ACL and Default ACL,它的具体参数大家可以去看man page。我只想提及一下chacl -B。它可以彻底删除文件或者目录的ACL属性(包括Default ACL),比如你即使用了setfacl -x删除了所有文件的ACL属性,那个+号还是会出现在文件的末尾,所以正确的删除方法应该是用chacl -B用cp来复制文件的时候我们现在可以加上-p选项。这样在拷贝文件的时候也将拷贝文件的ACL属性,对于不能拷贝的ACL属性将给出警告。
mv命令将会默认地移动文件的ACL属性,同样如果操作不允许的情况下会给出警告。
需要注意的几点
如果你的文件系统不支持ACL的话,你也许需要重新mount你的file system:
mount -o remount, acl [mount point]
如果用chmod命令改变Linux file permission的时候相应的ACL值也会改变,反之改变ACL的值,相应的file permission也会改变。
文本处理工具
vim
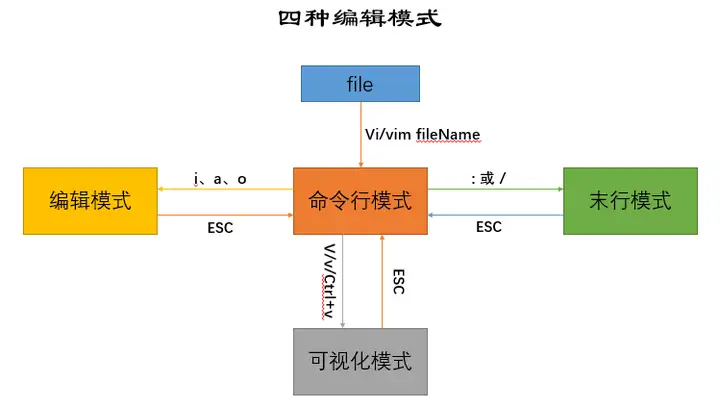
文本编辑种类:
全屏编辑器:nano(字符工具), gedit(图形化工具),vi,vim
行编辑器:sed
vi
Visual editor,文本编辑器,是 Linux 必备工具之一,功能强大,学习曲线较陡峭,学习难度大
vim
VIsual editor iMproved ,和 vi 使用方法一致,但功能更为强大,不是必备软件
vi
功能强大的纯文本编辑器
补充说明
vi命令 是UNIX操作系统和类UNIX操作系统中最通用的全屏幕纯文本编辑器。Linux中的vi编辑器叫vim,它是vi的增强版(vi Improved),与vi编辑器完全兼容,而且实现了很多增强功能。
vi编辑器支持编辑模式和命令模式,编辑模式下可以完成文本的编辑功能,命令模式下可以完成对文件的操作命令,要正确使用vi编辑器就必须熟练掌握着两种模式的切换。默认情况下,打开vi编辑器后自动进入命令模式。从编辑模式切换到命令模式使用“esc”键,从命令模式切换到编辑模式使用“A”、“a”、“O”、“o”、“I”、“i”键。
vi编辑器提供了丰富的内置命令,有些内置命令使用键盘组合键即可完成,有些内置命令则需要以冒号“:”开头输入。常用内置命令如下:
Ctrl+u:向文件首翻半屏;
Ctrl+d:向文件尾翻半屏;
Ctrl+f:向文件尾翻一屏;
Ctrl+b:向文件首翻一屏;
Esc:从编辑模式切换到命令模式;
ZZ:命令模式下保存当前文件所做的修改后退出vi;
:行号:光标跳转到指定行的行首;
:$:光标跳转到最后一行的行首;
x或X:删除一个字符,x删除光标后的,而X删除光标前的;
D:删除从当前光标到光标所在行尾的全部字符;
dd:删除光标行正行内容;
ndd:删除当前行及其后n-1行;
nyy:将当前行及其下n行的内容保存到寄存器?中,其中?为一个字母,n为一个数字;
p:粘贴文本操作,用于将缓存区的内容粘贴到当前光标所在位置的下方;
P:粘贴文本操作,用于将缓存区的内容粘贴到当前光标所在位置的上方;
/字符串:文本查找操作,用于从当前光标所在位置开始向文件尾部查找指定字符串的内容,查找的字符串会被加亮显示;
?字符串:文本查找操作,用于从当前光标所在位置开始向文件头部查找指定字符串的内容,查找的字符串会被加亮显示;
a,bs/F/T:替换文本操作,用于在第a行到第b行之间,将F字符串换成T字符串。其中,“s/”表示进行替换操作;
a:在当前字符后添加文本;
A:在行末添加文本;
i:在当前字符前插入文本;
I:在行首插入文本;
o:在当前行后面插入一空行;
O:在当前行前面插入一空行;
:wq:在命令模式下,执行存盘退出操作;
:w:在命令模式下,执行存盘操作;
:w!:在命令模式下,执行强制存盘操作;
:q:在命令模式下,执行退出vi操作;
:q!:在命令模式下,执行强制退出vi操作;
:e文件名:在命令模式下,打开并编辑指定名称的文件;
:n:在命令模式下,如果同时打开多个文件,则继续编辑下一个文件;
:f:在命令模式下,用于显示当前的文件名、光标所在行的行号以及显示比例;
:set number:在命令模式下,用于在最左端显示行号;
:set nonumber:在命令模式下,用于在最左端不显示行号;
语法
vi(选项)(参数)
选项
+<行号>:从指定行号的行开始显示文本内容;
-b:以二进制模式打开文件,用于编辑二进制文件和可执行文件;
-c<指令>:在完成对第一个文件编辑任务后,执行给出的指令;
-d:以diff模式打开文件,当多个文件编辑时,显示文件差异部分;
-l:使用lisp模式,打开“lisp”和“showmatch”;
-m:取消写文件功能,重设“write”选项;
-M:关闭修改功能;
-n:不实用缓存功能;
-o<文件数目>:指定同时打开指定数目的文件;
-R:以只读方式打开文件;
-s:安静模式,不现实指令的任何错误信息。
参数
文件列表:指定要编辑的文件列表。多个文件之间使用空格分隔开。
知识扩展
vi编辑器有三种工作方式:命令方式、输入方式和ex转义方式。通过相应的命令或操作,在这三种工作方式之间可以进行转换。
命令方式
在Shell提示符后输入命令vi,进入vi编辑器,并处于vi的命令方式。此时,从键盘上输入的任何字符都被作为编辑命令来解释,例如,a(append)表示附加命令,i(insert)表示插入命令,x表示删除字符命令等。如果输入的字符不是vi的合法命令,则机器发出“报警声”,光标不移动。另外,在命令方式下输入的字符(即vi命令)并不在屏幕上显示出来,例如,输入i,屏幕上并无变化,但通过执行i命令,编辑器的工作方式却发生变化:由命令方式变为输入方式。
输入方式
通过输入vi的插入命令(i)、附加命令(a)、打开命令(o)、替换命令(s)、修改命令(c)或取代命令(r)可以从命令方式进入输入方式。在输入方式下,从键盘上输入的所有字符都被插入到正在编辑的缓冲区中,被当做该文件的正文。进入输入方式后,输入的可见字符都在屏幕上显示出来,而编辑命令不再起作用,仅作为普通字母出现。例如,在命令方式下输入字母i,进到输入方式,然后再输入i,就在屏幕上相应光标处添加一个字母i。
由输入方式回到命令方式的办法是按下Esc键。如果已在命令方式下,那么按下Esc键就会发出“嘟嘟”声。为了确保用户想执行的vi命令是在命令方式下输入的,不妨多按几下Esc键,听到嘟声后再输入命令。
ex转义方式
vi和ex编辑器的功能是相同的,二者的主要区别是用户界面。在vi中,命令通常是单个字母,如a,x,r等。而在ex中,命令是以Enter;键结束的命令行。vi有一个专门的“转义”命令,可访问很多面向行的ex命令。为使用ex转义方式,可输入一个冒号(:)。作为ex命令提示符,冒号出现在状态行(通常在屏幕最下一行)。按下中断键(通常是Del键),可终止正在执行的命令。多数文件管理命令都是在ex转义方式下执行的(例如,读取文件,把编辑缓冲区的内容写到文件中等)。转义命令执行后,自动回到命令方式。例如:
:1,$s/I/i/g 按Enter键
则从文件第一行至文件末尾($)将大写I全部替换成小写i。vi编辑器的三种工作方式之间的转换如图所示。
!vi
vim
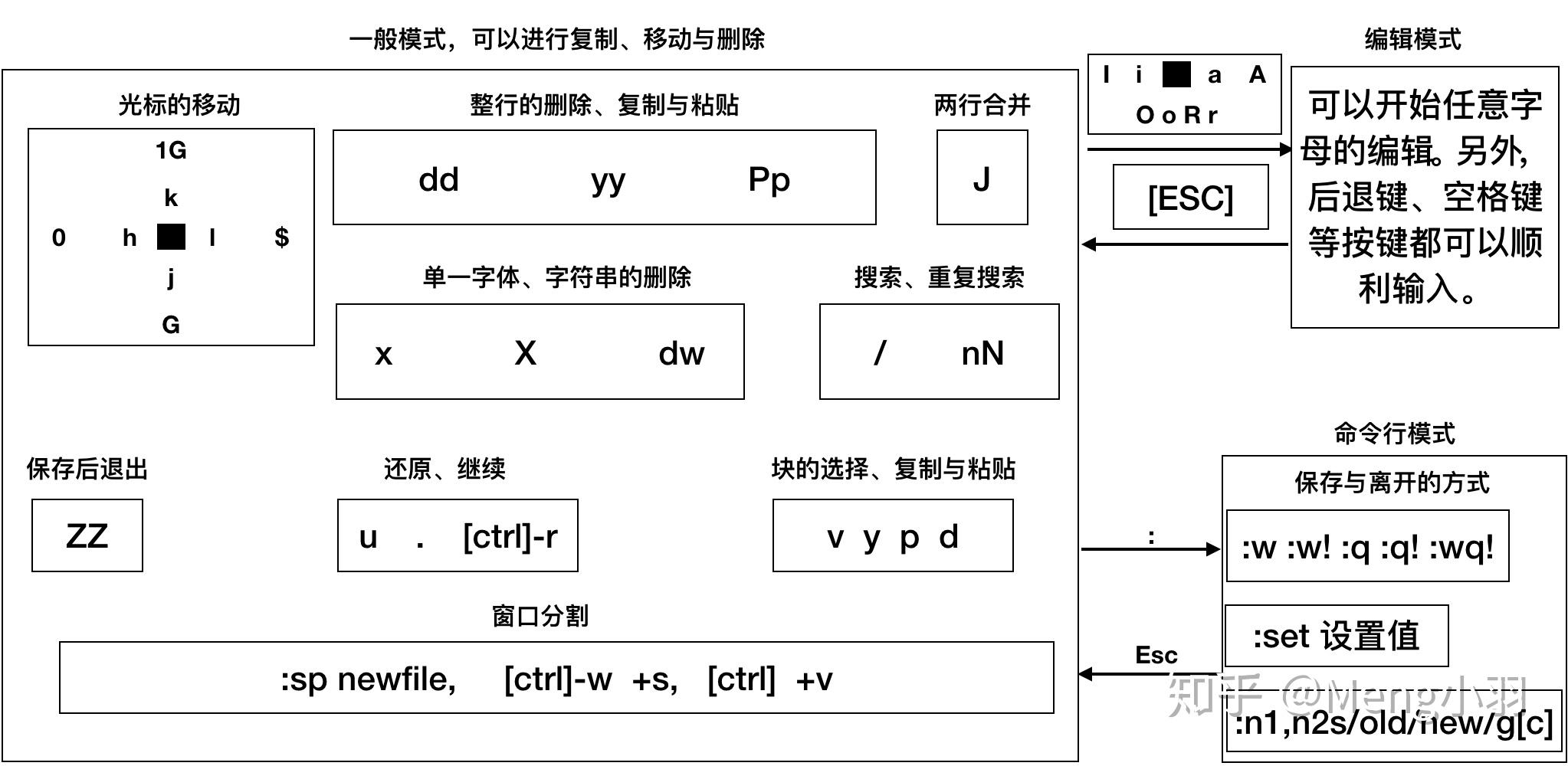
i insert, 在光标所在处输入
I 在当前光标所在行的行首输入
a append, 在光标所在处后面输入
A 在当前光标所在行的行尾输入
o 在当前光标所在行的下方打开一个新行
O 在当前光标所在行的上方打开一个新行
插入模式 --- ESC-----> 命令模式
命令模式 ---- : ----> 扩展命令模式
扩展命令模式 ----ESC,enter----> 命令模式
(按“:”进入Ex模式 ,创建一个命令提示符: 处于底部的屏幕左侧)
扩展命令模式基本命令
w 写(存)磁盘文件
wq 写入并退出
x 写入并退出
X 加密
q 退出
q! 不存盘退出,即使更改都将丢失
r filename 读文件内容到当前文件中
w filename 将当前文件内容写入另一个文件
!command 执行命令
r!command 读入命令的输出
地址定界格式
格式
:start_pos,end_pos CMD
# #具体第#行,例如2表示第2行
#,# #从左侧#表示起始行,到右侧#表示结尾行
#,+# #从左侧#表示的起始行,加上右侧#表示的行数,范例:2,+3 表示2到5行
. #当前行
$ #最后一行
.,$-1 #当前行到倒数第二行
% #全文, 相当于1,$
/pattern/ #从当前行向下查找,直到匹配pattern的第一行,即:正则表达式
/pat1/,/pat2/ #从第一次被pat1模式匹配到的行开始,一直到第一次被pat2匹配到的行结束
#,/pat/ #从指定行开始,一直找到第一个匹配pattern的行结束
/pat/,$ #向下找到第一个匹配patttern的行到整个文件的结尾的所有行
地址定界后跟一个编辑命令
d #删除
y #复制
w file #将范围内的行另存至指定文件中
r file #在指定位置插入指定文件中的所有内容
t#行号 将前面指定的行复制到#行后
m#行号 将前面指定的行移动到#行后





视图模式下
0 HOme ^ 快速移动光标到行首
$ End 快速移动光标到行尾
u 撤销所有操作
x 删除单个字符
G 快速移动光标到文件尾部 1G
gg 快速移动光标到首行
10G 快速移动光标到第10行
dd 快速删除光标所在的行 剪切
3dd 快速删除光标所在至第3行
dG 快速删除光标所在至文件尾部
D 快速删除光标至行尾
d^ d0 d+home 快速删除光标至行首
C 快速删除光标所在至行尾并进入编辑模式
yy 复制当前光标所在行
3yy 复制3行内容
p 粘贴复制的行
3p 连续粘贴3次
进入编辑模式
a 在所在光标后一格进入编辑模式 下方显示INSERT
i 在光标前进入编辑模式 下方显示INSERT
o 在光标所在下一行进去编辑模式
O 在光标所在上一行进入编辑模式
批量编辑
ctrl + v 选中区域(↑↓←→四个按键选择区域 x键可生产所选内容)
输入I ke输入心得内容
按两次esc键
退出
输入:进入底行模式
:set nu 显示行号
:set nonu 不显示行号
:w 保存当前内容
:q 退出不保存改动过的内容
:wq 保存并退出
:q! 强制退出不保存
:wq! 强制保存并退出
文本查看工具
cat
连接多个文件并打印到标准输出。
概要
cat [OPTION]... [FILE]...
主要用途
显示文件内容,如果没有文件或文件为-则读取标准输入。
将多个文件的内容进行连接并打印到标准输出。
显示文件内容中的不可见字符(控制字符、换行符、制表符等)。
参数
FILE(可选):要处理的文件,可以为一或多个。
选项
长选项与短选项等价
-A, --show-all 等价于"-vET"组合选项。
-b, --number-nonblank 只对非空行编号,从1开始编号,覆盖"-n"选项。
-e 等价于"-vE"组合选项。
-E, --show-ends 在每行的结尾显示'$'字符。
-n, --number 对所有行编号,从1开始编号。
-s, --squeeze-blank 压缩连续的空行到一行。
-t 等价于"-vT"组合选项。
-T, --show-tabs 使用"^I"表示TAB(制表符)。
-u POSIX兼容性选项,无意义。
-v, --show-nonprinting 使用"^"和"M-"符号显示控制字符,除了LFD(line feed,即换行符'\n')和TAB(制表符)。
--help 显示帮助信息并退出。
--version 显示版本信息并退出。
返回值
返回状态为成功除非给出了非法选项或非法参数。
例子
# 合并显示多个文件
cat ./1.log ./2.log ./3.log
# 显示文件中的非打印字符、tab、换行符
cat -A test.log
# 压缩文件的空行
cat -s test.log
# 显示文件并在所有行开头附加行号
cat -n test.log
# 显示文件并在所有非空行开头附加行号
cat -b test.log
# 将标准输入的内容和文件内容一并显示
echo '######' |cat - test.log
注意
该命令是GNU coreutils包中的命令,相关的帮助信息请查看man -s 1 cat或info coreutils 'cat invocation'。
当使用cat命令查看体积较大的文件时,文本在屏幕上迅速闪过(滚屏),用户往往看不清所显示的内容,为了控制滚屏,可以按Ctrl+s键停止滚屏;按Ctrl+q键恢复滚屏;按Ctrl+c(中断)键可以终止该命令的执行,返回Shell提示符状态。
建议您查看体积较大的文件时使用less、more命令或emacs、vi等文本编辑器。
参考链接
Question about LFD key
nl
为每一个文件添加行号。
概要
nl [OPTION]... [FILE]...
主要用途
将每一个输入的文件添加行号后发送到标准输出。
当没有文件或文件为-时,读取标准输入
处理逻辑页(logical page)。
选项
-b, --body-numbering=STYLE 使用STYLE 为body部分的行附加行号。
-d, --section-delimiter=CC 使用CC作为logical page的分隔符。
-f, --footer-numbering=STYLE 使用STYLE 为footer部分的行附加行号。
-h, --header-numbering=STYLE 使用STYLE 为header部分的行附加行号。
-i, --line-increment=NUMBER 行号递增间隔为NUMBER。
-l, --join-blank-lines=NUMBER 连续NUMBER行的空行作为一行处理。
-n, --number-format=FORMAT 根据FORMAT插入行号。
-p, --no-renumber 不要在每个部分重置行号。
-s, --number-separator=STRING 在行号后添加字符串STRING。
-v, --starting-line-number=NUMBER 每部分的起始行号。
-w, --number-width=NUMBER 行号宽度为NUMBER。
--help 显示帮助信息并退出。
--version 显示版本信息并退出。
默认选项为:-bt -d'\:' -fn -hn -i1 -l1 -nrn -sTAB -v1 -w6
CC是由两个字符组成的,默认为\: ,第二个字符如果缺失则默认为:
STYLE可以为下列可用值之一:
a 所有行标记行号。
t 仅为非空行标记行号。
n 不标记行号。
pBRE 符合基础正则表达式(BRE)的行会标记行号。
FORMAT可以为下列可用值之一:
ln 左对齐,不会在开始部分补充0以满足宽度。
rn 右对齐,不会在开始部分补充0以满足宽度。
rz 右对齐,会在开始部分补充0以满足宽度。
logical page
三部分组成(header, body, footer)
起始标记(header \:\:\:, body \:\:, footer \:)
参数
FILE(可选):要处理的文件,可以为一或多个。
返回值
返回0表示成功,返回非0值表示失败。
例子
nl_logicalpage.txt:该文件用于说明nl命令处理逻辑页,内容如下:
\:\:\:
header_1
\:\:
body_1
\:
footer_1
\:\:\:
header_2
\:\:
body_2
\:
footer_2
[user2@pc ~]$ nl nl_logicalpage.txt
header_1
1 body_1
footer_1
header_2
1 body_2
footer_2
[user2@pc ~]$ nl -v0 -fa -ha nl_logicalpage.txt
0 header_1
1 body_1
2 footer_1
0 header_2
1 body_2
2 footer_2
[user2@pc ~]$ nl -p -fa -ha nl_logicalpage.txt
1 header_1
2 body_1
3 footer_1
4 header_2
5 body_2
6 footer_2
nl_normal.txt:该文件用于说明nl命令处理普通文件,内容如下:
ZhuangZhu-74
2019-11-21
127.0.0.1
[user2@pc ~]$ nl nl_normal.txt
1 ZhuangZhu-74
2 2019-11-21
3 127.0.0.1
[user2@pc ~]$ nl -b p'1$' nl_normal.txt
ZhuangZhu-74
1 2019-11-21
2 127.0.0.1
[user2@pc ~]$ nl -b p'^[A-Z]' nl_normal.txt
1 ZhuangZhu-74
2019-11-21
127.0.0.1
注意
该命令是GNU coreutils包中的命令,相关的帮助信息请查看man -s 1 nl,info coreutils 'nl invocation'。
tac
连接多个文件并以行为单位反向打印到标准输出。
概要
tac [OPTION]... [FILE]...
主要用途
按行为单位反向显示文件内容,如果没有文件或文件为-则读取标准输入。
处理多个文件时,依次将每个文件反向显示,而不是将所有文件连在一起再反向显示。
参数
FILE(可选):要处理的文件,可以为一或多个。
选项
长选项与短选项等价
-b, --before 在之前而不是之后连接分隔符。
-r, --regex 将分隔符作为基础正则表达式(BRE)处理。
-s, --separator=STRING 使用STRING作为分隔符代替默认的换行符。
--help 显示帮助信息并退出。
--version 显示版本信息并退出。
返回值
返回状态为成功除非给出了非法选项或非法参数。
例子
# 选自官方info文档的例子:
# 一个接着一个字符的反转一个文件:
tac -r -s 'x\|[^x]' test.log
# 关于-b选项:
seq 1 3 |tac
# 输出
3
2
1
# 使用-b选项:
seq 1 3 |tac -b
# 输出,注意21后面没有换行符:
3
21
# 前一个例子相当于将 '1\n2\n3\n' 转换为 '3\n2\n1\n'
# 前一个例子相当于将 '1\n2\n3\n' 转换为 '\n\n3\n21'
注意
该命令是GNU coreutils包中的命令,相关的帮助信息请查看man -s 1 tac或info coreutils 'tac invocation'。
关于基础正则表达式(BRE)的内容,详见man -s 1 grep的REGULAR EXPRESSIONS段落。
rev
将文件内容以字符为单位反序输出
补充说明
rev命令 将文件中的每行内容以字符为单位反序输出,即第一个字符最后输出,最后一个字符最先输出,依次类推。
语法
rev(参数)
参数
文件:指定要反序显示内容的文件。
实例
[root@localhost ~]# cat iptables.bak
# Generated by iptables-save v1.3.5 on Thu Dec 26 21:25:15 2013
*filter
:INPUT DROP [48113:2690676]
:FORWARD accept [0:0]
:OUTPUT ACCEPT [3381959:1818595115]
-A INPUT -i lo -j ACCEPT
-A INPUT -p tcp -m tcp --dport 22 -j ACCEPT
-A INPUT -p tcp -m tcp --dport 80 -j ACCEPT
-A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT
-A INPUT -p icmp -j ACCEPT
-A OUTPUT -o lo -j ACCEPT
COMMIT
# Completed on Thu Dec 26 21:25:15 2013
[root@localhost ~]# rev iptables.bak
3102 51:52:12 62 ceD uhT no 5.3.1v evas-selbatpi yb detareneG #
retlif*
]6760962:31184[ PORD TUPNI:
]0:0[ TPECCA DRAWROF:
]5115958181:9591833[ TPECCA TUPTUO:
TPECCA j- ol i- TUPNI A-
TPECCA j- 22 tropd-- pct m- pct p- TUPNI A-
TPECCA j- 08 tropd-- pct m- pct p- TUPNI A-
TPECCA j- DEHSILBATSE,DETALER etats-- etats m- TUPNI A-
TPECCA j- pmci p- TUPNI A-
TPECCA j- ol o- TUPTUO A-
TIMMOC
3102 51:52:12 62 ceD uhT no detelpmoC #
查看非文本内容
hexdump
显示文件十六进制格式
补充说明
hexdump命令 一般用来查看“二进制”文件的十六进制编码,但实际上它能查看任何文件,而不只限于二进制文件。
语法
hexdump [选项] [文件]...
选项
-n length 只格式化输入文件的前length个字节。
-C 输出规范的十六进制和ASCII码。
-b 单字节八进制显示。
-c 单字节字符显示。
-d 双字节十进制显示。
-o 双字节八进制显示。
-x 双字节十六进制显示。
-s 从偏移量开始输出。
-e 指定格式字符串,格式字符串包含在一对单引号中,格式字符串形如:'a/b "format1" "format2"'。
每个格式字符串由三部分组成,每个由空格分隔,第一个形如a/b,b表示对每b个输入字节应用format1格式,a表示对每a个输入字节应用format2格式,一般a>b,且b只能为1,2,4,另外a可以省略,省略则a=1。format1和format2中可以使用类似printf的格式字符串,如:
%02d:两位十进制
%03x:三位十六进制
%02o:两位八进制
%c:单个字符等
还有一些特殊的用法:
%_ad:标记下一个输出字节的序号,用十进制表示。
%_ax:标记下一个输出字节的序号,用十六进制表示。
%_ao:标记下一个输出字节的序号,用八进制表示。
%_p:对不能以常规字符显示的用 . 代替。
同一行如果要显示多个格式字符串,则可以跟多个-e选项。
实例
hexdump -e '16/1 "%02X " " | "' -e '16/1 "%_p" "\n"' test
00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F | ................
10 11 12 13 14 15 16 17 18 19 1A 1B 1C 1D 1E 1F | ................
20 21 22 23 24 25 26 27 28 29 2A 2B 2C 2D 2E 2F | !"#$%&'()*+,-./
分页查看文件内容
more
显示文件内容,每次显示一屏
补充说明
more命令 是一个基于vi编辑器文本过滤器,它以全屏幕的方式按页显示文本文件的内容,支持vi中的关键字定位操作。more名单中内置了若干快捷键,常用的有H(获得帮助信息),Enter(向下翻滚一行),空格(向下滚动一屏),Q(退出命令)。
该命令一次显示一屏文本,满屏后停下来,并且在屏幕的底部出现一个提示信息,给出至今己显示的该文件的百分比:--More--(XX%)可以用下列不同的方法对提示做出回答:
按 Space 键:显示文本的下一屏内容。
按 Enter 键:只显示文本的下一行内容。
按斜线符|:接着输入一个模式,可以在文本中寻找下一个相匹配的模式。
按H键:显示帮助屏,该屏上有相关的帮助信息。
按B键:显示上一屏内容。
按Q键:退出more命令。
语法
more(语法)(参数)
选项
-<数字>:指定每屏显示的行数;
-d:显示“[press space to continue,'q' to quit.]”和“[Press 'h' for instructions]”;
-c:不进行滚屏操作。每次刷新这个屏幕;
-s:将多个空行压缩成一行显示;
-u:禁止下划线;
+<数字>:从指定数字的行开始显示。
参数
文件:指定分页显示内容的文件。
实例
显示文件file的内容,但在显示之前先清屏,并且在屏幕的最下方显示完成的百分比。
more -dc file
显示文件file的内容,每10行显示一次,而且在显示之前先清屏。
more -c -10 file
less
分屏上下翻页浏览文件内容
补充说明
less命令 的作用与more十分相似,都可以用来浏览文字档案的内容,不同的是less命令允许用户向前或向后浏览文件,而more命令只能向前浏览。用less命令显示文件时,用PageUp键向上翻页,用PageDown键向下翻页。要退出less程序,应按Q键。
语法
less(选项)(参数)
选项
-e:文件内容显示完毕后,自动退出;
-f:强制显示文件;
-g:不加亮显示搜索到的所有关键词,仅显示当前显示的关键字,以提高显示速度;
-l:搜索时忽略大小写的差异;
-N:每一行行首显示行号;
-s:将连续多个空行压缩成一行显示;
-S:在单行显示较长的内容,而不换行显示;
-x<数字>:将TAB字符显示为指定个数的空格字符。
参数
文件:指定要分屏显示内容的文件。
实例
[root@centos8 ~]#less /etc/init.d/functions
# -*-Shell-script-*-
#
# functions This file contains functions to be used by most or all
# shell scripts in the /etc/init.d directory.
#
TEXTDOMAIN=initscripts
# Make sure umask is sane
umask 022
# Set up a default search path.
PATH="/sbin:/usr/sbin:/bin:/usr/bin"
export PATH
...省略...
显示文本前面或后面的行内容
head
显示文件的开头部分
概要
head [OPTION]... [FILE]...
主要用途
在未指定行数时默认显示前10行。
处理多个文件时会在各个文件之前附加含有文件名的行。
当没有文件或文件为-时,读取标准输入。
选项
-c, --bytes=[-]NUM 显示前NUM字节;如果NUM前有"-",那么会打印除了文件末尾的NUM字节以外的其他内容。
-n, --lines=[-]NUM 显示前NUM行而不是默认的10行;如果NUM前有"-",那么会打印除了文件末尾的NUM行以外的其他行。
-q, --quiet, --silent 不打印文件名行。
-v, --verbose 总是打印文件名行。
-z, --zero-terminated 行终止符为NUL而不是换行符。
--help 显示帮助信息并退出。
--version 显示版本信息并退出。
NUM可以有一个乘数后缀:
b 512
kB 1000
k 1024
MB 1000*1000
M 1024*1024
GB 1000*1000*1000
G 1024*1024*1024
T、P、E、Z、Y等以此类推。
也可以使用二进制前缀:
KiB=K
MiB=M
以此类推。
参数
FILE(可选):要处理的文件,可以为一或多个。
返回值
返回0表示成功,返回非0值表示失败。
例子
[11:20:18 root@localhost ~][#head a.txt
sdlfkjals sdklfj
sdkflasdb
fklashdfkasb
sdkfjlasdhfb
sdklfhklasfhb
kdfsk
askhjdfub
jkdfhka 2k23
[11:20:21 root@localhost ~][#head -3 a.txt
sdlfkjals sdklfj
sdkflasdb
fklashdfkasb
[11:20:41 root@localhost ~][#head -n 3 a.txt
sdlfkjals sdklfj
sdkflasdb
fklashdfkasb
[11:20:52 root@localhost ~][#
#可结合管道符使用
[11:21:42 root@localhost ~][#seq 42|head -n 3
1
2
3
[11:22:07 root@localhost ~][#seq 500|head -3
1
2
3
#比较n选项的区别
[11:22:21 root@localhost ~][#seq 500|head -8
1
2
3
4
5
6
7
8
[11:23:52 root@localhost ~][#seq 500|head -n -8
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
# 查看历史文件的前6行:
[user2@pc ~]$ head -n 6 ~/.bash_history
#1575425555
cd ~
#1575425558
ls -lh
#1575425562
vi ~/Desktop/ZhuangZhu-74.txt
# 查看多个文件:
[user2@pc ~]$ head -n ~/.bash_history ~/.bashrc
==> /allhome/user2/.bash_history <==
#1575425555
cd ~
#1575425558
ls -lh
#1575425562
vi ~/Desktop/ZhuangZhu-74.txt
#1575425566
uptime
#1575425570
find ~/ -maxdepth 3 -name 'test.sh' -exec lh {} \;
==> /allhome/user2/.bashrc <==
# .bashrc
# forbid use Ctrl+D to exit shell.
set -o ignoreeof
# Source global definitions.
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi
注意
该命令是GNU coreutils包中的命令,相关的帮助信息请查看man -s 1 head,info coreutils 'head invocation'。
范例:
tail
在屏幕上显示指定文件的末尾若干行
补充说明
tail命令 用于输入文件中的尾部内容。
默认在屏幕上显示指定文件的末尾10行。
处理多个文件时会在各个文件之前附加含有文件名的行。
如果没有指定文件或者文件名为-,则读取标准输入。
如果表示字节或行数的NUM值之前有一个+号,则从文件开头的第NUM项开始显示,而不是显示文件的最后NUM项。
NUM值后面可以有后缀:
b : 512
kB : 1000
k : 1024
MB : 1000 * 1000
M : 1024 * 1024
GB : 1000 * 1000 * 1000
G : 1024 * 1024 * 1024
T、P、E、Z、Y等以此类推。
语法
tail (选项) (参数)
选项
-c, --bytes=NUM 输出文件尾部的NUM(NUM为整数)个字节内容。
-f, --follow[={name|descript}] 显示文件最新追加的内容。“name”表示以文件名的方式监视文件的变化。
-F 与 “--follow=name --retry” 功能相同。
-n, --line=NUM 输出文件的尾部NUM(NUM位数字)行内容。
--pid=<进程号> 与“-f”选项连用,当指定的进程号的进程终止后,自动退出tail命令。
-q, --quiet, --silent 当有多个文件参数时,不输出各个文件名。
--retry 即是在tail命令启动时,文件不可访问或者文件稍后变得不可访问,都始终尝试打开文件。使用此选项时需要与选项“--follow=name”连用。
-s, --sleep-interal=<秒数> 与“-f”选项连用,指定监视文件变化时间隔的秒数。
-v, --verbose 当有多个文件参数时,总是输出各个文件名。
--help 显示指令的帮助信息。
--version 显示指令的版本信息。
参数
文件列表:指定要显示尾部内容的文件列表。
实例
tail file #(显示文件file的最后10行)
tail -n +20 file #(显示文件file的内容,从第20行至文件末尾)
tail -c 10 file #(显示文件file的最后10个字节)
tail -25 mail.log # 显示 mail.log 最后的 25 行
tail -f mail.log # 等同于--follow=descriptor,根据文件描述符进行追踪,当文件改名或被删除,追踪停止
tail -F mail.log # 等同于--follow=name --retry,根据文件名进行追踪,并保持重试,即该文件被删除或改名后,如果再次创建相同的文件名,会继续追踪
范例
[11:26:34 root@localhost ~][#tail -n 5 a.txt
jkdfhka 2k23
34545hbsdg
kj43k5hjk
fnaksej
[11:39:16 root@localhost ~][#tail /var/log/messages
Feb 24 11:19:22 localhost systemd[2027]: Finished Cleanup of User's Temporary Files and Directories.
Feb 24 11:19:57 localhost chronyd[889]: Selected source 84.16.67.12 (2.rocky.pool.ntp.org)
Feb 24 11:28:19 localhost NetworkManager[1066]: <info> [1708774099.5041] dhcp4 (ens160): state changed new lease, address=10.0.0.133
Feb 24 11:28:19 localhost systemd[1]: Starting Cleanup of Temporary Directories...
Feb 24 11:28:19 localhost systemd[1]: Starting Network Manager Script Dispatcher Service...
Feb 24 11:28:19 localhost systemd[1]: Started Network Manager Script Dispatcher Service.
Feb 24 11:28:19 localhost systemd[1]: systemd-tmpfiles-clean.service: Deactivated successfully.
Feb 24 11:28:19 localhost systemd[1]: Finished Cleanup of Temporary Directories.
Feb 24 11:28:19 localhost systemd[1]: run-credentials-systemd\x2dtmpfiles\x2dclean.service.mount: Deactivated successfully.
Feb 24 11:28:29 localhost systemd[1]: NetworkManager-dispatcher.service: Deactivated successfully.
范例
#
cut -f:显示指定字段的内容;
[11:46:23 root@localhost ~][#cut -d: -f1,3,4,7 /etc/passwd
root:0:0:/bin/bash
bin:1:1:/sbin/nologin
daemon:2:2:/sbin/nologin
adm:3:4:/sbin/nologin
lp:4:7:/sbin/nologin
sync:5:0:/bin/sync
shutdown:6:0:/sbin/shutdown
halt:7:0:/sbin/halt
mail:8:12:/sbin/nologin
operator:11:0:/sbin/nologin
games:12:100:/sbin/nologin
ftp:14:50:/sbin/nologin
nobody:65534:65534:/sbin/nologin
systemd-coredump:999:997:/sbin/nologin
dbus:81:81:/sbin/nologin
polkitd:998:996:/sbin/nologin
avahi:70:70:/sbin/nologin
rtkit:172:172:/sbin/nologin
pipewire:997:993:/sbin/nologin
sssd:996:992:/sbin/nologin
libstoragemgmt:990:990:/usr/sbin/nologin
systemd-oom:989:989:/usr/sbin/nologin
tss:59:59:/usr/sbin/nologin
geoclue:988:987:/sbin/nologin
cockpit-ws:987:986:/sbin/nologin
cockpit-wsinstance:986:985:/sbin/nologin
flatpak:985:984:/sbin/nologin
colord:984:983:/sbin/nologin
clevis:983:982:/usr/sbin/nologin
setroubleshoot:982:981:/usr/sbin/nologin
gdm:42:42:/sbin/nologin
gnome-initial-setup:981:980:/sbin/nologin
sshd:74:74:/sbin/nologin
chrony:980:979:/sbin/nologin
dnsmasq:979:978:/usr/sbin/nologin
tcpdump:72:72:/sbin/nologin
wang:1000:1000:/bin/bash
postfix:89:89:/sbin/nologin
范例
[11:55:21 root@localhost ~][#df|cut -d% -f1|rev|cut -d" " -f1
esU
0
0
2
8
1
23
1
1
分析这条命令
df|cut -d% -f1|rev|cut -d" " -f1
df:这是Unix和类Unix操作系统中的一个命令,用来显示文件系统的总空间、已使用空间、剩余空间以及挂载点等信息。
|:管道符号,将前一个命令(df)的输出作为后一个命令的输入。
cut -d% -f1:cut命令用于从每一行的标准输入中裁剪指定字段。这里的参数:
-d% 表示以百分号(%)为分隔符。
-f1 表示选择第一个字段,即每个输出行中百分号前面的部分,也就是各个分区的已用磁盘空间百分比。
|:再次使用管道,将上一步骤得到的结果传递给下一个命令。
rev:这个命令用于反转每一行字符的顺序,通常是为了处理特殊格式的数据。在这个场景下,由于Linux下的df命令默认输出中,已用磁盘空间百分比是倒数第二个字段,但通过前面的cut命令已经提取到第一个字段,所以这里使用rev可能是多余的。
|:最后一个管道,将上一步骤的结果传给最后的命令。
cut -d" " -f1:又一个cut命令,这次是以空格为分隔符,并选择第一字段。如果前面的rev命令多余的话,这一步也是多余的,因为之前就已经得到了百分比数据。但如果原始目的是为了获取百分比数值而排除可能存在的其他字符,那么这一步可以确保只获取数字部分。
[11:56:56 root@localhost ~][#df|cut -d% -f1|rev|cut -d" " -f1 |rev
Use
0
0
2
8
1
32
1
1
df|cut -d% -f1|rev|cut -d" " -f1 |rev
范例
如何ifconfig 头部的两行 以及只显示第二行
[11:32:15 root@localhost ~][#ifconfig ens160
ens160: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.0.0.133 netmask 255.255.255.0 broadcast 10.0.0.255
inet6 fe80::20c:29ff:fe13:ba48 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:13:ba:48 txqueuelen 1000 (Ethernet)
RX packets 1486 bytes 156710 (153.0 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1070 bytes 114148 (111.4 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
解答:
[11:35:11 root@localhost ~][#ifconfig ens160|head -n 2
ens160: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.0.0.133 netmask 255.255.255.0 broadcast 10.0.0.255
[11:35:52 root@localhost ~][#ifconfig ens160|tail -n +2|head -n1
inet 10.0.0.133 netmask 255.255.255.0 broadcast 10.0.0.255
ifconfig
配置和显示Linux系统网卡的网络参数
补充说明
ifconfig命令 被用于配置和显示Linux内核中网络接口的网络参数。用ifconfig命令配置的网卡信息,在网卡重启后机器重启后,配置就不存在。要想将上述的配置信息永远的存的电脑里,那就要修改网卡的配置文件了。
语法
ifconfig(参数)
参数
add<地址>:设置网络设备IPv6的ip地址;
del<地址>:删除网络设备IPv6的IP地址;
down:关闭指定的网络设备;
<hw<网络设备类型><硬件地址>:设置网络设备的类型与硬件地址;
io_addr<I/O地址>:设置网络设备的I/O地址;
irq<IRQ地址>:设置网络设备的IRQ;
media<网络媒介类型>:设置网络设备的媒介类型;
mem_start<内存地址>:设置网络设备在主内存所占用的起始地址;
metric<数目>:指定在计算数据包的转送次数时,所要加上的数目;
mtu<字节>:设置网络设备的MTU;
netmask<子网掩码>:设置网络设备的子网掩码;
tunnel<地址>:建立IPv4与IPv6之间的隧道通信地址;
up:启动指定的网络设备;
-broadcast<地址>:将要送往指定地址的数据包当成广播数据包来处理;
-pointopoint<地址>:与指定地址的网络设备建立直接连线,此模式具有保密功能;
-promisc:关闭或启动指定网络设备的promiscuous模式;
IP地址:指定网络设备的IP地址;
网络设备:指定网络设备的名称。
实例
显示网络设备信息(激活状态的):
[root@localhost ~]# ifconfig
eth0 Link encap:Ethernet HWaddr 00:16:3E:00:1E:51
inet addr:10.160.7.81 Bcast:10.160.15.255 Mask:255.255.240.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:61430830 errors:0 dropped:0 overruns:0 frame:0
TX packets:88534 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:3607197869 (3.3 GiB) TX bytes:6115042 (5.8 MiB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:56103 errors:0 dropped:0 overruns:0 frame:0
TX packets:56103 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:5079451 (4.8 MiB) TX bytes:5079451 (4.8 MiB)
说明:
eth0 表示第一块网卡,其中HWaddr表示网卡的物理地址,可以看到目前这个网卡的物理地址(MAC地址)是00:16:3E:00:1E:51。
inet addr 用来表示网卡的IP地址,此网卡的IP地址是10.160.7.81,广播地址Bcast:10.160.15.255,掩码地址Mask:255.255.240.0。
lo 是表示主机的回坏地址,这个一般是用来测试一个网络程序,但又不想让局域网或外网的用户能够查看,只能在此台主机上运行和查看所用的网络接口。比如把 httpd服务器的指定到回坏地址,在浏览器输入127.0.0.1就能看到你所架WEB网站了。但只是您能看得到,局域网的其它主机或用户无从知道。
第一行:连接类型:Ethernet(以太网)HWaddr(硬件mac地址)。
第二行:网卡的IP地址、子网、掩码。
第三行:UP(代表网卡开启状态)RUNNING(代表网卡的网线被接上)MULTICAST(支持组播)MTU:1500(最大传输单元):1500字节。
第四、五行:接收、发送数据包情况统计。
第七行:接收、发送数据字节数统计信息。
启动关闭指定网卡:
ifconfig eth0 up
ifconfig eth0 down
ifconfig eth0 up为启动网卡eth0,ifconfig eth0 down为关闭网卡eth0。ssh登陆linux服务器操作要小心,关闭了就不能开启了,除非你有多网卡。
为网卡配置和删除IPv6地址:
ifconfig eth0 add 33ffe:3240:800:1005::2/64 #为网卡eth0配置IPv6地址
ifconfig eth0 del 33ffe:3240:800:1005::2/64 #为网卡eth0删除IPv6地址
用ifconfig修改MAC地址:
ifconfig eth0 hw ether 00:AA:BB:CC:dd:EE
配置IP地址:
[root@localhost ~]# ifconfig eth0 192.168.2.10
[root@localhost ~]# ifconfig eth0 192.168.2.10 netmask 255.255.255.0
[root@localhost ~]# ifconfig eth0 192.168.2.10 netmask 255.255.255.0 broadcast 192.168.2.255
启用和关闭arp协议:
ifconfig eth0 arp #开启网卡eth0 的arp协议
ifconfig eth0 -arp #关闭网卡eth0 的arp协议
设置最大传输单元:
ifconfig eth0 mtu 1500 #设置能通过的最大数据包大小为 1500 bytes
其它实例
ifconfig #处于激活状态的网络接口
ifconfig -a #所有配置的网络接口,不论其是否激活
ifconfig eth0 #显示eth0的网卡信息
head 和 tail 总结
范例
seq 20| head -n 6|tail -n1
seq 20| tail -n +6 |head -n1
[07:18:52 root@localhost ~][#seq 20| head -n 6|tail -n1
6
[08:31:30 root@localhost ~][#seq 20| tail -n +6 |head -n1
6
按列抽取文本 --cut
cut
连接文件并打印到标准输出设备上
补充说明
cut 命令 用来显示行中的指定部分,删除文件中指定字段。cut 经常用来显示文件的内容,类似于 type 命令。
说明:该命令有两项功能,其一是用来显示文件的内容,它依次读取由参数 file 所指 明的文件,将它们的内容输出到标准输出上;其二是连接两个或多个文件,如cut fl f2 > f3将把文件 fl 和 f2 的内容合并起来,然后通过输出重定向符“>”的作用,将它们放入文件 f3 中。
当文件较大时,文本在屏幕上迅速闪过(滚屏),用户往往看不清所显示的内容。因此,一般用 more 等命令分屏显示。为了控制滚屏,可以按 Ctrl+S 键,停止滚屏;按 Ctrl+Q 键可以恢复滚屏。按 Ctrl+C(中断)键可以终止该命令的执行,并且返回 Shell 提示符状态。
语法
cut(选项)(参数)
选项
-b:仅显示行中指定直接范围的内容;
-c:仅显示行中指定范围的字符;
-d:指定字段的分隔符,默认的字段分隔符为“TAB”;
-f:显示指定字段的内容;
-n:与“-b”选项连用,不分割多字节字符;
--complement:补足被选择的字节、字符或字段;
--out-delimiter= 字段分隔符:指定输出内容是的字段分割符;
--help:显示指令的帮助信息;
--version:显示指令的版本信息。
参数
文件:指定要进行内容过滤的文件。
实例
例如有一个学生报表信息,包含 No、Name、Mark、Percent:
[root@localhost text]# cat test.txt
No Name Mark Percent
01 tom 69 91
02 jack 71 87
03 alex 68 98
使用 -f 选项提取指定字段(这里的 f 参数可以简单记忆为 --fields的缩写):
[root@localhost text]# cut -f 1 test.txt
No
01
02
03
[root@localhost text]# cut -f2,3 test.txt
Name Mark
tom 69
jack 71
alex 68
--complement 选项提取指定字段之外的列(打印除了第二列之外的列):
[root@localhost text]# cut -f2 --complement test.txt
No Mark Percent
01 69 91
02 71 87
03 68 98
使用 -d 选项指定字段分隔符:
[root@localhost text]# cat test2.txt
No;Name;Mark;Percent
01;tom;69;91
02;jack;71;87
03;alex;68;98
[root@localhost text]# cut -f2 -d";" test2.txt
Name
tom
jack
alex
指定字段的字符或者字节范围
cut 命令可以将一串字符作为列来显示,字符字段的记法:
N- :从第 N 个字节、字符、字段到结尾;
N-M :从第 N 个字节、字符、字段到第 M 个(包括 M 在内)字节、字符、字段;
-M :从第 1 个字节、字符、字段到第 M 个(包括 M 在内)字节、字符、字段。
上面是记法,结合下面选项将摸个范围的字节、字符指定为字段:
-b 表示字节;
-c 表示字符;
-f 表示定义字段。
示例
[root@localhost text]# cat test.txt
abcdefghijklmnopqrstuvwxyz
abcdefghijklmnopqrstuvwxyz
abcdefghijklmnopqrstuvwxyz
abcdefghijklmnopqrstuvwxyz
abcdefghijklmnopqrstuvwxyz
打印第 1 个到第 3 个字符:
[root@localhost text]# cut -c1-3 test.txt
abc
abc
abc
abc
abc
打印前 2 个字符:
[root@localhost text]# cut -c-2 test.txt
ab
ab
ab
ab
ab
打印从第 5 个字符开始到结尾:
[root@localhost text]# cut -c5- test.txt
efghijklmnopqrstuvwxyz
efghijklmnopqrstuvwxyz
efghijklmnopqrstuvwxyz
efghijklmnopqrstuvwxyz
efghijklmnopqrstuvwxyzcut
paste
将多个文件按列队列合并
补充说明
paste命令 用于将多个文件按照列队列进行合并。
语法
paste(选项)(参数)
选项
-d<间隔字符>或--delimiters=<间隔字符>:用指定的间隔字符取代跳格字符;
-s或——serial串列进行而非平行处理。
参数
文件列表:指定需要合并的文件列表
实例
[root@centos8 ~]#cat alpha.log
a
b
c
d
e
f
g
h
[root@centos8 ~]#cat seq.log
1
2
3
4
5
[root@centos8 ~]#cat alpha.log seq.log
a
b
c
d
e
f
g
h
1
2
3
4
5
[root@centos8 ~]#paste alpha.log seq.log
a 1
b 2
c 3
d 4
e 5
f
g
h
[root@centos8 ~]#paste -d":" alpha.log seq.log
a:1
b:2
c:3
d:4
e:5
f:
g:
h:
[root@centos8 ~]#paste -s seq.log
1 2 3 4 5
[root@centos8 ~]#paste -s alpha.log
a b c d e f g h
[root@centos8 ~]#paste -s alpha.log seq.log
a b c d e f g h
1 2 3 4 5
[root@centos8 ~]#cat title.txt
ceo
coo
cto
[root@centos8 ~]#cat emp.txt
mage
zhang
wang
xu
[root@centos8 ~]#paste title.txt emp.txt
ceo mage
coo zhang
cto wang
xu
[root@centos8 ~]#paste -s title.txt emp.txt
ceo coo cto
mage zhang wang xu
[root@centos8 ~]#paste -s -d: f1.log f2.log
1:2:3:4:5:6:7:8:9:10
a:b:c:d:e:f:g:h:i:j
[root@centos8 ~]#seq 10
1
2
3
4
5
6
7
8
9
10
[root@centos8 ~]#seq 10 |paste -s -d+|bc
55
分析文本的工具
文本数据统计:wc
整理文本:sort
比较文件:diff和patch
收集文本统计数据wc
wc
统计文件的字节数、字数、行数
补充说明
wc命令 统计指定文件中的字节数、字数、行数,并将统计结果显示输出。利用wc指令我们可以计算文件的Byte数、字数或是列数,若不指定文件名称,或是所给予的文件名为“-”,则wc指令会从标准输入设备读取数据。wc同时也给出所指定文件的总统计数。
语法
wc(选项)(参数)
wc [选项]... [文件]...
wc [选项]... --files0-from=F
选项
-c # 统计字节数,或--bytes或——chars:只显示Bytes数;。
-l # 统计行数,或——lines:只显示列数;。
-m # 统计字符数。这个标志不能与 -c 标志一起使用。
-w # 统计字数,或——words:只显示字数。一个字被定义为由空白、跳格或换行字符分隔的字符串。
-L # 打印最长行的长度。
-help # 显示帮助信息
--version # 显示版本信息
参数
文件:需要统计的文件列表。
例子
wc -l * # 统计当前目录下的所有文件行数及总计行数。
wc -l *.js # 统计当前目录下的所有 .js 后缀的文件行数及总计行数。
find . * | xargs wc -l # 当前目录以及子目录的所有文件行数及总计行数。
查看文件的字节数、字数、行数
wc test.txt
# 输出结果
7 8 70 test.txt
# 行数 单词数 字节数 文件名
用wc命令怎么做到只打印统计数字不打印文件名
wc -l < test.txt
# 输出结果
7
用来统计当前目录下的文件数(不包含隐藏文件)
# 要去除TOTAL行
expr $(ls -l | wc -l) - 1
# 输出结果
8
统计当前目录下的所有文件行数及总计行数
[root@centos7 ~]# wc -l *
21 LICENSE
270 README.md
wc: example: read: Is a directory
785 lerna-debug.log
25 lerna.json
wc: node_modules: read: Is a directory
23603 package-lock.json
79 package.json
3 renovate.json
24786 total
文本排序
sort
对文本文件中所有行进行排序
概要
sort [OPTION]... [FILE]...
sort [OPTION]... --files0-from=F
主要用途
将所有输入文件的内容排序后并输出。
当没有文件或文件为-时,读取标准输入。
选项
排序选项:
-b, --ignore-leading-blanks 忽略开头的空白。
-d, --dictionary-order 仅考虑空白、字母、数字。
-f, --ignore-case 将小写字母作为大写字母考虑。
-g, --general-numeric-sort 根据数字排序。
-i, --ignore-nonprinting 排除不可打印字符。
-M, --month-sort 按照非月份、一月、十二月的顺序排序。
-h, --human-numeric-sort 根据存储容量排序(注意使用大写字母,例如:2K 1G)。
-n, --numeric-sort 根据数字排序。
-R, --random-sort 随机排序,但分组相同的行。
--random-source=FILE 从FILE中获取随机长度的字节。
-r, --reverse 将结果倒序排列。
--sort=WORD 根据WORD排序,其中: general-numeric 等价于 -g,human-numeric 等价于 -h,month 等价于 -M,numeric 等价于 -n,random 等价于 -R,version 等价于 -V。
-V, --version-sort 文本中(版本)数字的自然排序。
其他选项:
--batch-size=NMERGE 一次合并最多NMERGE个输入;超过部分使用临时文件。
-c, --check, --check=diagnose-first 检查输入是否已排序,该操作不会执行排序。
-C, --check=quiet, --check=silent 类似于 -c 选项,但不输出第一个未排序的行。
--compress-program=PROG 使用PROG压缩临时文件;使用PROG -d解压缩。
--debug 注释用于排序的行,发送可疑用法的警报到stderr。
--files0-from=F 从文件F中读取以NUL结尾的所有文件名称;如果F是 - ,那么从标准输入中读取名字。
-k, --key=KEYDEF 通过一个key排序;KEYDEF给出位置和类型。
-m, --merge 合并已排序文件,之后不再排序。
-o, --output=FILE 将结果写入FILE而不是标准输出。
-s, --stable 通过禁用最后的比较来稳定排序。
-S, --buffer-size=SIZE 使用SIZE作为内存缓存大小。
-t, --field-separator=SEP 使用SEP作为列的分隔符。
-T, --temporary-directory=DIR 使用DIR作为临时目录,而不是 $TMPDIR 或 /tmp;多次使用该选项指定多个临时目录。
--parallel=N 将并发运行的排序数更改为N。
-u, --unique 同时使用-c,严格检查排序;不同时使用-c,输出排序后去重的结果。
-z, --zero-terminated 设置行终止符为NUL(空),而不是换行符。
--help 显示帮助信息并退出。
--version 显示版本信息并退出。
KEYDEF的格式为:F[.C][OPTS][,F[.C][OPTS]] ,表示开始到结束的位置。
F表示列的编号
C表示
OPTS为[bdfgiMhnRrV]中的一到多个字符,用于覆盖当前排序选项。
使用--debug选项可诊断出错误的用法。
SIZE 可以有以下的乘法后缀:
% 内存的1%;
b 1;
K 1024(默认);
剩余的 M, G, T, P, E, Z, Y 可以类推出来。
参数
FILE(可选):要处理的文件,可以为任意数量。
返回值
返回0表示成功,返回非0值表示失败。
例子
sort将文件/文本的每一行作为一个单位相互比较,比较原则是从首字符向后依次按ASCII码值进行比较,最后将他们按升序输出。
root@[mail text]# cat sort.txt
aaa:10:1.1
ccc:30:3.3
ddd:40:4.4
bbb:20:2.2
eee:50:5.5
eee:50:5.5
[root@mail text]# sort sort.txt
aaa:10:1.1
bbb:20:2.2
ccc:30:3.3
ddd:40:4.4
eee:50:5.5
eee:50:5.5
忽略相同行使用-u选项或者uniq:
[root@mail text]# cat sort.txt
aaa:10:1.1
ccc:30:3.3
ddd:40:4.4
bbb:20:2.2
eee:50:5.5
eee:50:5.5
[root@mail text]# sort -u sort.txt
aaa:10:1.1
bbb:20:2.2
ccc:30:3.3
ddd:40:4.4
eee:50:5.5
[root@mail text]# uniq sort.txt
aaa:10:1.1
ccc:30:3.3
ddd:40:4.4
bbb:20:2.2
eee:50:5.5
sort的-n、-r、-k、-t选项的使用:
[root@mail text]# cat sort.txt
AAA:BB:CC
aaa:30:1.6
ccc:50:3.3
ddd:20:4.2
bbb:10:2.5
eee:40:5.4
eee:60:5.1
# 将BB列按照数字从小到大顺序排列:
[root@mail text]# sort -nk 2 -t: sort.txt
AAA:BB:CC
bbb:10:2.5
ddd:20:4.2
aaa:30:1.6
eee:40:5.4
ccc:50:3.3
eee:60:5.1
# 将CC列数字从大到小顺序排列:
# -n是按照数字大小排序,-r是以相反顺序,-k是指定需要排序的栏位,-t指定栏位分隔符为冒号
[root@mail text]# sort -nrk 3 -t: sort.txt
eee:40:5.4
eee:60:5.1
ddd:20:4.2
ccc:50:3.3
bbb:10:2.5
aaa:30:1.6
AAA:BB:CC
关于-k选项的解读和例子:
-k选项深度解读:
FStart.CStart Modifier,FEnd.CEnd Modifier
-------Start--------,-------End--------
FStart.CStart 选项 , FEnd.CEnd 选项
这个语法格式可以被其中的逗号,分为两大部分,Start 部分和 End 部分。 Start部分由三部分组成,其中的Modifier部分就是我们之前说过的选项部分; 我们重点说说Start部分的FStart和C.Start;C.Start是可以省略的,省略的话就表示从本域的开头部分开始。FStart.CStart,其中FStart就是表示使用的域,而CStart则表示在FStart域中从第几个字符开始算排序首字符。 同理,在End部分中,你可以设定FEnd.CEnd,如果你省略.CEnd或将它设定为0,则表示结尾到本域的最后一个字符。
例子:从公司英文名称的第二个字母开始排序:
$ sort -t ' ' -k 1.2 facebook.txt
baidu 100 5000
sohu 100 4500
google 110 5000
guge 50 3000
解读:使用了-k 1.2,表示对第一个域的第二个字符开始到本域的最后一个字符为止的字符串进行排序。你会发现baidu因为第二个字母是a而名列榜首。sohu和google第二个字符都是o,但sohu的h在google的o前面,所以两者分别排在第二和第三。guge只能屈居第四了。
例子:只针对公司英文名称的第二个字母进行排序,如果相同的按照员工工资进行降序排序:
$ sort -t ' ' -k 1.2,1.2 -nrk 3,3 facebook.txt
baidu 100 5000
google 110 5000
sohu 100 4500
guge 50 3000
解读:由于只对第二个字母进行排序,所以我们使用了-k 1.2,1.2的表示方式,表示我们只对第二个字母进行排序(如果你问我使用-k 1.2怎么不行?当然不行,因为你省略了End部分,这就意味着你将对从第二个字母起到本域最后一个字符为止的字符串进行排序)。 对员工工资进行排序,我们也使用了-k 3,3,这是最准确的表述,表示我们只对本域进行排序,因为如果你省略了后面的3,就变成了我们对第3个域开始到最后一个域位置的内容进行排序了。
注意
关于-g和-n选项的区别:stackoverflow
关于这个复杂命令的学习,建议您阅读info文档及参考博客、问答网站等。
该命令是GNU coreutils包中的命令,相关的帮助信息请查看man -s 1 shuf,info coreutils 'shuf invocation'。
范例:
[12:17:15 root@localhost ~][#cut -d: -f1,3 /etc/passwd | sort -t: -rnk2
nobody:65534
wang:1000
systemd-coredump:999
polkitd:998
pipewire:997
sssd:996
libstoragemgmt:990
systemd-oom:989
geoclue:988
cockpit-ws:987
cockpit-wsinstance:986
flatpak:985
colord:984
clevis:983
setroubleshoot:982
gnome-initial-setup:981
chrony:980
dnsmasq:979
rtkit:172
postfix:89
dbus:81
sshd:74
tcpdump:72
avahi:70
tss:59
gdm:42
ftp:14
games:12
operator:11
mail:8
halt:7
shutdown:6
sync:5
lp:4
adm:3
daemon:2
bin:1
root:0
范例
分析这个命令
cut -d: -f1,3 /etc/passwd | sort -t: -rnk2
这个命令组合是用来从`/etc/passwd`文件中提取用户ID(UID)和用户名,并按照用户的UID进行降序排序。
具体解释如下:
1. `cut -d: -f1,3 /etc/passwd`:
- `cut`命令用于从文件每一行中按指定分隔符切割出需要的字段。
- `-d:` 表示使用冒号(:)作为字段分隔符,因为`/etc/passwd`文件中的各个字段就是用冒号隔开的。
- `-f1,3` 表示选择第一和第三个字段。在`/etc/passwd`文件中,第一个字段是用户名,第三个字段是用户ID(UID)。
2. `|`:管道符号,将前面命令的结果作为后面命令的输入。
3. `sort -t: -rnk2`:
- `sort`命令用于对输入数据进行排序。
- `-t:` 表示这次使用冒号作为排序键的分隔符。
- `-rnk2` 参数组合表示:
- `-r` 表示反向排序,即降序排列。
- `-n` 表示以数值大小进行排序。
- `-k2` 表示按照第二列(由于Linux Shell默认从1开始计数,所以这里的第二列实际上是原始数据的第三列,也就是我们通过`cut`命令提取出的UID部分)进行排序。
因此,整个命令的目的是:读取`/etc/passwd`文件,提取用户名和对应的用户ID,然后按照用户ID的数值大小进行降序排列。
范例
[12:25:24 root@localhost ~][#df
Filesystem 1K-blocks Used Available Use% Mounted on
devtmpfs 4096 0 4096 0% /dev
tmpfs 886860 0 886860 0% /dev/shm
tmpfs 354744 5756 348988 2% /run
/dev/mapper/rl-root 73334784 5306228 68028556 8% /
/dev/mapper/rl-home 133091328 966204 132125124 1% /home
/dev/nvme0n1p1 983040 307796 675244 32% /boot
tmpfs 177372 52 177320 1% /run/user/42
tmpfs 177372 36 177336 1% /run/user/0
[12:28:09 root@localhost ~][#df |tail -n +2
devtmpfs 4096 0 4096 0% /dev
tmpfs 886860 0 886860 0% /dev/shm
tmpfs 354744 5756 348988 2% /run
/dev/mapper/rl-root 73334784 5306228 68028556 8% /
/dev/mapper/rl-home 133091328 966204 132125124 1% /home
/dev/nvme0n1p1 983040 307796 675244 32% /boot
tmpfs 177372 52 177320 1% /run/user/42
tmpfs 177372 36 177336 1% /run/user/0
[12:28:15 root@localhost ~][#df |tail -n +2|tr -s ' ' %
devtmpfs%4096%0%4096%0%/dev
tmpfs%886860%0%886860%0%/dev/shm
tmpfs%354744%5756%348988%2%/run
/dev/mapper/rl-root%73334784%5306228%68028556%8%/
/dev/mapper/rl-home%133091328%966204%132125124%1%/home
/dev/nvme0n1p1%983040%307796%675244%32%/boot
tmpfs%177372%52%177320%1%/run/user/42
tmpfs%177372%36%177336%1%/run/user/0
[12:28:44 root@localhost ~][#df |tail -n +2|tr -s ' ' % |cut -d% -f5
0
0
2
8
1
32
1
1
[12:29:11 root@localhost ~][#df |tail -n +2|tr -s ' ' % |cut -d% -f5|sort -nr
32
8
2
1
1
1
0
0
[12:29:27 root@localhost ~][#df |tail -n +2|tr -s ' ' % |cut -d% -f5|sort -nr|head -n3
32
8
2
分析命令
df |tail -n +2|tr -s ' ' % |cut -d% -f5|sort -nr|head -n3
这个命令组合的作用是获取系统中使用率最高的前3个磁盘分区及其使用率。具体步骤如下:
1. `df`:显示文件系统的总空间、已用空间、剩余空间以及挂载点等信息。
2. `| tail -n +2`:
- 使用管道将`df`的输出传递给`tail`命令。
- `tail -n +2`表示从第二行开始打印输出,因为`df`命令的第一行通常是列标题,不包含实际的磁盘使用信息。
3. `| tr -s ' ' %`:
- 将空格替换为百分号(%)。由于`df`默认输出中,磁盘使用率后面通常跟有一个百分号,这里替换空格可能旨在确保所有空格都被替换为百分号,使得后续的切割操作能够正确识别使用率字段。
4. `| cut -d% -f5`:
- 使用管道将上一步的结果传递给`cut`命令。
- `-d%`指定以百分号作为分隔符。
- `-f5`表示提取第五个字段,即使用率字段。
5. `| sort -nr`:
- 将提取出的使用率数值按降序排序。
- `-n`表示按照数值大小进行排序。
- `-r`表示反向排序,即从大到小排序。
6. `| head -n3`:
- 从排序后的结果中取出前3条数据,也就是使用率最高的前3个磁盘分区的信息。
总结来说,该命令链执行的结果是显示出系统中磁盘使用率最高的前3个分区及其对应的使用率。不过要注意的是,在实际应用中,由于不同版本的`df`命令输出格式可能有差异,因此在处理时需要根据实际情况调整命令中的参数。例如在一些Linux发行版中,使用率可能是倒数第二个字段而不是第五个字段。
去重uniq
uniq
显示或忽略重复的行。
概要
uniq [OPTION]... [INPUT [OUTPUT]]
主要用途
将输入文件(或标准输入)中邻近的重复行写入到输出文件(或标准输出)中。
当没有选项时,邻近的重复行将合并为一个。
选项
-c, --count 在每行开头增加重复次数。
-d, --repeated 所有邻近的重复行只被打印一次。
-D 所有邻近的重复行将全部打印。
--all-repeated[=METHOD] 类似于 -D,但允许每组之间以空行分割。METHOD取值范围{none(默认),prepend,separate}。
-f, --skip-fields=N 跳过对前N个列的比较。
--group[=METHOD] 显示所有行,允许每组之间以空行分割。METHOD取值范围:{separate(默认),prepend,append,both}。
-i, --ignore-case 忽略大小写的差异。
-s, --skip-chars=N 跳过对前N个字符的比较。
-u, --unique 只打印非邻近的重复行。
-z, --zero-terminated 设置行终止符为NUL(空),而不是换行符。
-w, --check-chars=N 只对每行前N个字符进行比较。
--help 显示帮助信息并退出。
--version 显示版本信息并退出。
参数
INPUT(可选):输入文件,不提供时为标准输入。
OUTPUT(可选):输出文件,不提供时为标准输出。
返回值
返回0表示成功,返回非0值表示失败。
例子
注意:命令2和命令3结果一样,命令1仅作了相邻行的去重。
uniq file.txt
sort file.txt | uniq
sort -u file.txt
只显示单一行,区别在于是否执行排序:
uniq -u file.txt
sort file.txt | uniq -u
统计各行在文件中出现的次数:
sort file.txt | uniq -c
在文件中找出重复的行:
sort file.txt | uniq -d
注意
uniq只检测邻近的行是否重复,sort -u将输入文件先排序然后再处理重复行。
该命令是GNU coreutils包中的命令,相关的帮助信息请查看man -s 1 uniq,info coreutils 'uniq invocation'。
diff
比较给定的两个文件的不同
补充说明
diff命令 在最简单的情况下,比较给定的两个文件的不同。如果使用“-”代替“文件”参数,则要比较的内容将来自标准输入。diff命令是以逐行的方式,比较文本文件的异同处。如果该命令指定进行目录的比较,则将会比较该目录中具有相同文件名的文件,而不会对其子目录文件进行任何比较操作。
语法
diff(选项)(参数)
选项
-<行数>:指定要显示多少行的文本。此参数必须与-c或-u参数一并使用;
-a或——text:diff预设只会逐行比较文本文件;
-b或--ignore-space-change:不检查空格字符的不同;
-B或--ignore-blank-lines:不检查空白行;
-c:显示全部内容,并标出不同之处;
-C<行数>或--context<行数>:与执行“-c-<行数>”指令相同;
-d或——minimal:使用不同的演算法,以小的单位来做比较;
-D<巨集名称>或ifdef<巨集名称>:此参数的输出格式可用于前置处理器巨集;
-e或——ed:此参数的输出格式可用于ed的script文件;
-f或-forward-ed:输出的格式类似ed的script文件,但按照原来文件的顺序来显示不同处;
-H或--speed-large-files:比较大文件时,可加快速度;
-l<字符或字符串>或--ignore-matching-lines<字符或字符串>:若两个文件在某几行有所不同,而之际航同时都包含了选项中指定的字符或字符串,则不显示这两个文件的差异;
-i或--ignore-case:不检查大小写的不同;
-l或——paginate:将结果交由pr程序来分页;
-n或——rcs:将比较结果以RCS的格式来显示;
-N或--new-file:在比较目录时,若文件A仅出现在某个目录中,预设会显示:Only in目录,文件A 若使用-N参数,则diff会将文件A 与一个空白的文件比较;
-p:若比较的文件为C语言的程序码文件时,显示差异所在的函数名称;
-P或--unidirectional-new-file:与-N类似,但只有当第二个目录包含了第一个目录所没有的文件时,才会将这个文件与空白的文件做比较;
-q或--brief:仅显示有无差异,不显示详细的信息;
-r或——recursive:比较子目录中的文件;
-s或--report-identical-files:若没有发现任何差异,仍然显示信息;
-S<文件>或--starting-file<文件>:在比较目录时,从指定的文件开始比较;
-t或--expand-tabs:在输出时,将tab字符展开;
-T或--initial-tab:在每行前面加上tab字符以便对齐;
-u,-U<列数>或--unified=<列数>:以合并的方式来显示文件内容的不同;
-v或——version:显示版本信息;
-w或--ignore-all-space:忽略全部的空格字符;
-W<宽度>或--width<宽度>:在使用-y参数时,指定栏宽;
-x<文件名或目录>或--exclude<文件名或目录>:不比较选项中所指定的文件或目录;
-X<文件>或--exclude-from<文件>;您可以将文件或目录类型存成文本文件,然后在=<文件>中指定此文本文件;
-y或--side-by-side:以并列的方式显示文件的异同之处;
--help:显示帮助;
--left-column:在使用-y参数时,若两个文件某一行内容相同,则仅在左侧的栏位显示该行内容;
--suppress-common-lines:在使用-y参数时,仅显示不同之处。
参数
文件1:指定要比较的第一个文件;
文件2:指定要比较的第二个文件。
实例
将目录/usr/li下的文件"test.txt"与当前目录下的文件"test.txt"进行比较,输入如下命令:
diff /usr/li test.txt #使用diff指令对文件进行比较
上面的命令执行后,会将比较后的不同之处以指定的形式列出,如下所示:
n1 a n3,n4
n1,n2 d n3
n1,n2 c n3,n4
其中,字母"a"、"d"、"c"分别表示添加、删除及修改操作。而"n1"、"n2"表示在文件1中的行号,"n3"、"n4"表示在文件2中的行号。
注意:以上说明指定了两个文件中不同处的行号及其相应的操作。在输出形式中,每一行后面将跟随受到影响的若干行。其中,以<开始的行属于文件1,以>开始的行属于文件2。
patch
patch 复制在其它文件中进行的改变(要谨慎使用)
为开放源代码软件安装补丁程序
-b或--backup:备份每一个原始文件;
补充说明
patch命令 被用于为开放源代码软件安装补丁程序。让用户利用设置修补文件的方式,修改,更新原始文件。如果一次仅修改一个文件,可直接在命令列中下达指令依序执行。如果配合修补文件的方式则能一次修补大批文件,这也是Linux系统核心的升级方法之一。
语法
patch(选项)(参数)
选项
-b或--backup:备份每一个原始文件;
-B<备份字首字符串>或--prefix=<备份字首字符串>:设置文件备份时,附加在文件名称前面的字首字符串,该字符串可以是路径名称;
-c或--context:把修补数据解译成关联性的差异;
-d<工作目录>或--directory=<工作目录>:设置工作目录;
-D<标示符号>或--ifdef=<标示符号>:用指定的符号把改变的地方标示出来;
-e或--ed:把修补数据解译成ed指令可用的叙述文件;
-E或--remove-empty-files:若修补过后输出的文件其内容是一片空白,则移除该文件;
-f或--force:此参数的效果和指定"-t"参数类似,但会假设修补数据的版本为新版本;
-F<监别列数>或--fuzz<监别列数>:设置监别列数的最大值;
-g<控制数值>或--get=<控制数值>:设置以RSC或SCCS控制修补作业;
-i<修补文件>或--input=<修补文件>:读取指定的修补问家你;
-l或--ignore-whitespace:忽略修补数据与输入数据的跳格,空格字符;
-n或--normal:把修补数据解译成一般性的差异;
-N或--forward:忽略修补的数据较原始文件的版本更旧,或该版本的修补数据已使 用过;
-o<输出文件>或--output=<输出文件>:设置输出文件的名称,修补过的文件会以该名称存放;
-p<剥离层级>或--strip=<剥离层级>:设置欲剥离几层路径名称;
-f<拒绝文件>或--reject-file=<拒绝文件>:设置保存拒绝修补相关信息的文件名称,预设的文件名称为.rej;
-R或--reverse:假设修补数据是由新旧文件交换位置而产生;
-s或--quiet或--silent:不显示指令执行过程,除非发生错误;
-t或--batch:自动略过错误,不询问任何问题;
-T或--set-time:此参数的效果和指定"-Z"参数类似,但以本地时间为主;
-u或--unified:把修补数据解译成一致化的差异;
-v或--version:显示版本信息;
-V<备份方式>或--version-control=<备份方式>:用"-b"参数备份目标文件后,备份文件的字尾会被加上一个备份字符串,这个字符串不仅可用"-z"参数变更,当使用"-V"参数指定不同备份方式时,也会产生不同字尾的备份字符串;
-Y<备份字首字符串>或--basename-prefix=--<备份字首字符串>:设置文件备份时,附加在文件基本名称开头的字首字符串;
-z<备份字尾字符串>或--suffix=<备份字尾字符串>:此参数的效果和指定"-B"参数类似,差别在于修补作业使用的路径与文件名若为src/linux/fs/super.c,加上"backup/"字符串后,文件super.c会备份于/src/linux/fs/backup目录里;
-Z或--set-utc:把修补过的文件更改,存取时间设为UTC;
--backup-if-mismatch:在修补数据不完全吻合,且没有刻意指定要备份文件时,才备份文件;
--binary:以二进制模式读写数据,而不通过标准输出设备;
--help:在线帮助;
--nobackup-if-mismatch:在修补数据不完全吻合,且没有刻意指定要备份文件时,不要备份文件;
--verbose:详细显示指令的执行过程。
参数
原文件:指定需要打补丁的原始文件;
补丁文件:指定补丁文件。
vimdiff
相当于vim -d
cmp
比较两个文件是否有差异
补充说明
cmp命令 用来比较两个文件是否有差异。当相互比较的两个文件完全一样时,则该指令不会显示任何信息。若发现有差异,预设会标示出第一个不通之处的字符和列数编号。若不指定任何文件名称或是所给予的文件名为“-”,则cmp指令会从标准输入设备读取数据。
语法
cmp(选项)(参数)
选项
-c或--print-chars:除了标明差异处的十进制字码之外,一并显示该字符所对应字符;
-i<字符数目>或--ignore-initial=<字符数目>:指定一个数目;
-l或——verbose:标示出所有不一样的地方;
-s或--quiet或——silent:不显示错误信息;
-v或——version:显示版本信息;
--help:在线帮助。
参数
目录:比较两个文件的差异。
实例
使用cmp命令比较文件"testfile"和文件"testfile1"两个文件,则输入下面的命令:
cmp testfile testfile1 #比较两个指定的文件
在上述指令执行之前,使用cat命令查看两个指定的文件内容,如下所示:
cat testfile #查看文件内容
Absncn 50 #显示文件“testfile”
Asldssja 60
Jslkadjls 85
cat testfile1 #查看文件内容
Absncn 50 #显示文件“testfile1”
AsldssjE 62
Jslkadjls 85
然后,再执行cmp命令,并返回比较结果,具体如下所示:
cmp testfile testfile1 #比较两个文件
testfile testfile1 #有差异:第8字节,第2行
注意:在比较结果中,只能够显示第一比较结果。
正则表达式
REGEXP: Regular Expressions,由一类特殊字符及文本字符所编写的模式,其中有些字符(元字符)
不表示字符字面意义,而表示控制或通配的功能,类似于增强版的通配符功能,但与通配符不同,通配
符功能是用来处理文件名,而正则表达式是处理文本内容中字符
正则表达式被很多程序和开发语言所广泛支持:vim, less,grep,sed,awk, nginx,mysql 等
正则表达式分两类:
基本正则表达式:BRE Basic Regular Expressions
扩展正则表达式:ERE Extended Regular Expressions
正则表达式引擎:
采用不同算法,检查处理正则表达式的软件模块,如:PCRE(Perl Compatible Regular
Expressions)
正则表达式的元字符分类:字符匹配、匹配次数、位置锚定、分组
帮助:man 7 regex
基本正则表达式元字符
字符匹配
. 匹配任意单个字符(除了\n),可以是一个汉字或其它国家的文字
[] 匹配指定范围内的任意单个字符,示例:[wang] [0-9] [a-z] [a-zA-Z]
[^] 匹配指定范围外的任意单个字符,示例:[^wang]
[:alnum:] 字母和数字
[:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z
[:lower:] 小写字母,示例:[[:lower:]],相当于[a-z]
[:upper:] 大写字母
[:blank:] 空白字符(空格和制表符)
[:space:] 包括空格、制表符(水平和垂直)、换行符、回车符等各种类型的空白,比[:blank:]包含的范围
广
[:cntrl:] 不可打印的控制字符(退格、删除、警铃...)
[:digit:] 十进制数字
[:xdigit:]十六进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 标点符号
-----------------
\s #匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [\f\r\t\v]。注意 Unicode
正则表达式会匹配全角空格符
\S #匹配任何非空白字符。等价于 [^\f\r\t\v]
\w #匹配一个字母,数字,下划线,汉字,其它国家文字的字符,等价于[_[:alnum:]字]
\W #匹配一个非字母,数字,下划线,汉字,其它国家文字的字符,等价于[^_[:alnum:]字]
范例
[root@centos8 ~]#ls /etc/ | grep 'rc[.0-6]'
rc0.d
rc1.d
rc2.d
rc3.d
rc4.d
rc5.d
rc6.d
rc.d
rc.local
[root@centos8 ~]#ls /etc/ | grep 'rc[.0-6].'
rc0.d
rc1.d
rc2.d
rc3.d
rc4.d
rc5.d
rc6.d
rc.d
rc.local
[root@centos8 ~]#ls /etc/ | grep 'rc[.0-6]\.'
rc0.d
rc1.d
rc2.d
rc3.d
rc4.d
rc5.d
rc6.d
匹配次数
用在要指定次数的字符后面,用于指定前面的字符要出现的次数
* #匹配前面的字符任意次,包括0次,贪婪模式:尽可能长的匹配
.* #任意长度的任意字符
\? #匹配其前面的字符出现0次或1次,即:可有可无
\+ #匹配其前面的字符出现最少1次,即:肯定有且 >=1 次
\{n\} #匹配前面的字符n次
\{m,n\} #匹配前面的字符至少m次,至多n次
\{,n\} #匹配前面的字符至多n次,<=n
\{n,\} #匹配前面的字符至少n次
范例
[root@centos8 ~]#echo /etc/ |grep "/etc/\?"
/etc/
[root@centos8 ~]#echo /etc |grep "/etc/\?"
/etc
范例
[root@centos8 ~]#cat test.txt
google
goooooooooooooooooogle
ggle
gogle
gooooOOOOO00000gle
gooogle
[root@centos8 ~]#grep 'go\{2,\}gle' test.txt
google
goooooooooooooooooogle
gooogle
[root@centos8 ~]#grep 'goo\+gle' test.txt
google
goooooooooooooooooogle
gooogle
[root@centos8 ~]#grep 'goo*gle' test.txt
google
goooooooooooooooooogle
gogle
gooogle
[root@centos8 ~]#grep 'gooo*gle' test.txt
google
goooooooooooooooooogle
gooogle
范例:匹配正负数
[root@centos8 ~]#echo -1 -2 123 -123 234 |grep '-\?[0-9]\+'
grep: invalid option -- '\'
Usage: grep [OPTION]... PATTERN [FILE]...
Try 'grep --help' for more information.
[root@centos8 ~]#echo -1 -2 123 -123 234 |grep '\-\?[0-9]\+'
-1 -2 123 -123 234
[root@centos8 ~]#echo -1 -2 123 -123 234 |grep -E '-?[0-9]+'
grep: invalid option -- '?'
Usage: grep [OPTION]... PATTERN [FILE]...
Try 'grep --help' for more information.
[root@centos8 ~]#echo -1 -2 123 -123 234 |grep -E '\-?[0-9]+'
-1 -2 123 -123 234
[root@centos8 ~]#echo -1 -2 123 -123 234 |grep -E -- '-?[0-9]+'
-1 -2 123 -123 234
[root@centos8 ~]#echo -1 -2 123 -123 234 |grep -E '(-)?[0-9]+'
-1 -2 123 -123 234
范例:取ip地址
[root@centos8 ~]#ifconfig eth0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.0.0.8 netmask 255.255.255.0 broadcast 10.0.0.255
inet6 fe80::20c:29ff:fee1:e53 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:e1:0e:53 txqueuelen 1000 (Ethernet)
RX packets 45953 bytes 21739254 (20.7 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 35886 bytes 26575579 (25.3 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[root@centos8 ~]#ifconfig eth0|grep netmask |grep -o '[0-9]\{1,3\}\.[0-9]\
{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}'|head -n1
10.0.0.8
[root@centos8 ~]#ifconfig eth0|grep -o '[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\
{1,3\}\.[0-9]\{1,3\}'|head -n1
10.0.0.8
位置锚定
位置锚定可以用于定位出现的位置
^ #行首锚定, 用于模式的最左侧
$ #行尾锚定,用于模式的最右侧
^PATTERN$ #用于模式匹配整行
^$ #空行
^[[:space:]]*$ #空白行
\< 或 \b #词首锚定,用于单词模式的左侧
\> 或 \b #词尾锚定,用于单词模式的右侧
\<PATTERN\> #匹配整个单词
#注意: 单词是由字母,数字,下划线组成
范例
[root@centos8 ~]#grep '^[^#]' /etc/fstab
UUID=acf9bd1f-caae-4e28-87be-e53afec61347 / xfs
defaults 0 0
UUID=1770b87e-db5a-445e-bff1-1653ac64b3d6 /boot ext4
defaults 1 2
UUID=ffffd919-d674-44d9-a4e7-402874f0a1f0 /data xfs
defaults 0 0
UUID=409e36d2-ac5e-423f-ad78-9b12db4576bd swap swap
defaults 0 0
范例:排除空行和#开头的行
[root@centos8 ~]#grep -v '^$' /etc/profile|grep -v '^#'
[root@centos8 ~]#grep '^[^#]' /etc/profile
[root@centos8 ~]#grep -v '^$\|#' /etc/profile
分组其他
分组
分组:() 将多个字符捆绑在一起,当作一个整体处理,如:(root)+
后向引用:分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这些变量的命名
方式为: \1, \2, \3, ...
\1 表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符
注意: \0 表示正则表达式匹配的所有字符
示例:
\(string1\(string2\)\)
\1 :string1\(string2\)
\2 :string2
注意: 后向引用 引用前面的分组括号中的模式所匹配字符,而非模式本身
或者
或者:|
示例:
a\|b #a或b
C\|cat #C或cat
\(C\|c\)at #Cat或cat
范例:排除空行和#开头的行
[root@centos6 ~]#grep -v '^#' /etc/httpd/conf/httpd.conf |grep -v ^$
[root@centos6 ~]#grep -v '^#\|^$' /etc/httpd/conf/httpd.conf
[root@centos6 ~]#grep -v '^\(#\|$\)' /etc/httpd/conf/httpd.conf
[root@centos6 ~]#grep "^[^#]" /etc/httpd/conf/httpd.conf


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南