


简单例子
实例:
处理集合时,通常会迭代遍历它的元素,并在每个元素上执行某项操作,例如假设我们想要对某本的所有长单词进行计数,首先需要将所有单词放到一个列表中
var contents = new String(Files.readAllBytes(Paths.get("a.txt")), StandardCharsets.UTF_8); //var 是jdk10 用法
List<String> worlds = List.of(contents.split("\\PL+")); // jdk9 的语法规则
//开始迭代
int count = 0;
for(String w: worlds){
if(w.length()>12) count++;
}
解释:
- 声明变量:
var contents这行代码声明了一个变量contents,并使用了 Java 10 引入的新语法var。var关键字可以让编译器自动推断出变量的类型,因此在这里声明的contents变量类型为String。 - 创建对象:
new String(Files.readAllBytes(Paths.get("a.txt")), StandardCharsets.UTF_8),这一部分用来读取文件 "a.txt" 的内容,并将其作为字符串返回。首先,使用Paths.get("a.txt")方法获取文件的路径,然后使用Files.readAllBytes()方法读取文件的内容。读取到的内容是一个字节数组,所以需要使用new String(...)构造方法将字节数组转换为字符串。此外,因为文件的内容是以 UTF-8 编码的,所以还需要使用StandardCharsets.UTF_8参数告诉构造方法使用 UTF-8 编码来解码字节数组。 - 赋值:
contents = new String(...),这一部分用来将上面创建的字符串对象赋值给变量contents。
注意:
-
Java 的 List.of() 方法是 Java 9 引入的新方法
-
jdk8替换方案
List<String>list = Arrays.asList(1,2,3,4);
-
-
var contents 是Java 10 引入的语法
-
jdk8改为String
String contents = new String(Files.readAllBytes(Paths.get("a.txt")), StandardCharsets.UTF_8);
-
更改后
String contents = new String(Files.readAllBytes(Paths.get("a.txt")), StandardCharsets.UTF_8);
List<String> worlds = Arrays.asList(contents.split("\\PL+"));
int count = 0;
for (String w : worlds) {
if (w.length() > 3) {
count++;
}
}
System.out.println("单词数量为:" + count);
流方式1
String contents = new String(Files.readAllBytes(Paths.get("a.txt")), StandardCharsets.UTF_8);
List<String> worlds = Arrays.asList(contents.split("\\PL+"));
Long s = worlds.stream()
.filter(x -> x.length() > 3)
.count();
System.out.println("单词数量为:" + s);
并行流2
修改parallelStream就可以让流库以并行方式运行
long count1 = worlds.parallelStream()
.filter(x -> x.length() > 3)
.count();
System.out.println("并行流统计单词数量为:" + count1);
操作流的流程
- 创建源,比如通过Collection.stream()方法创建一个集合的流:
List<String> list = Arrays.asList("a", "b", "c");
Stream<String> stream = list.stream();
- 通过中间操作,对流进行过滤、排序、转换等操作,并返回新的流对象:
Stream<String> newStream = stream.filter(x -> x.startsWith("a"))
.sorted()
.map(x -> x.toUpperCase());
- 通过终止操作,对流进行收集、计算、迭代等操作,并返回结果:
List<String> result = newStream.collect(Collectors.toList());
完整代码如下:
List<String> list = Arrays.asList("a", "b", "c");
Stream<String> stream = list.stream();
Stream<String> newStream = stream.filter(x -> x.startsWith("a"))
.sorted()
.map(x -> x.toUpperCase());
List<String> result = newStream.collect(Collectors.toList());
流的创建
- 通过集合或数组的.stream()方法创建:
List<String> list = Arrays.asList("a", "b", "c");
Stream<String> stream = list.stream();
String[] array = {"a", "b", "c"};
Stream<String> stream1 = Arrays.stream(array);
- 通过Stream.of()方法创建:
Stream<String> stream3 = Stream.of("a", "b", "c");
- 通过Stream.generate()或Stream.iterate()方法创建,可以生成无限流:
Stream<String> stream4 = Stream.generate(() -> "a");
Stream<Integer> stream5 = Stream.iterate(1, x -> x + 1);
这段代码创建了一个包含无限个字符串 "a" 的流。
它使用 Stream.generate() 方法,该方法接收一个工厂函数,并根据这个函数来生成一个无限的流。在这个例子中,工厂函数是一个 lambda 表达式,它返回一个字符串 "a"。
请注意,这个流是无限的,并且可能会引起内存溢出,除非您对它进行某些限制。例如,您可以使用 limit() 方法来限制流中元素的数量。
Stream<String> stream4 = Stream.generate(() -> "a").limit(10);
这段代码会创建一个包含 10 个字符串 "a" 的流。
- 通过其他流的.flatMap()方法创建,可以将一个流的每个元素都转换成一个流,再把这些流扁平化成一个流:
Stream<String> stream6 = Stream.of("a,b,c", "d,e,f", "g,h,i")
.flatMap(x -> Stream.of(x.split(",")));
Stream的中间操作
Stream 的中间操作
多个中间操作可以连接起来形成一个流水线,除非流水线上触发终止操作,否则中间操作不会执行任何的处理!而在终止操作时一次性全部处理,称为“惰性求值”。
1-筛选与切片

//1-筛选与切片
@Test
public void test1(){
List<Employee> list = EmployeeData.getEmployees();
//filter(Predicate p)——接收 Lambda , 从流中排除某些元素。
//练习:查询员工表中薪资大于7000的员工信息
list.stream()
.filter( (employee -> employee.getSalary() >= 7000 ) )
.forEach(System.out::println);
System.out.println();
//limit(n)——截断流,使其元素不超过给定数量。
list.stream()
.limit(3)
.forEach(System.out::println);
System.out.println();
//skip(n) —— 跳过元素,返回一个扔掉了前 n 个元素的流。若流中元素不足 n 个,则返回一个空流。与 limit(n) 互补
list.stream()
.skip(3)
.forEach(System.out::println);
System.out.println();
//distinct()——筛选,通过流所生成元素的 hashCode() 和 equals() 去除重复元素
list.add(new Employee(1010,"刘强东",40,8000));
list.add(new Employee(1010,"刘强东",40,8000));
list.add(new Employee(1010,"刘强东",41,8000));
list.add(new Employee(1010,"刘强东",41,8000));
list.stream().distinct().forEach(System.out::println);
}
2-映射
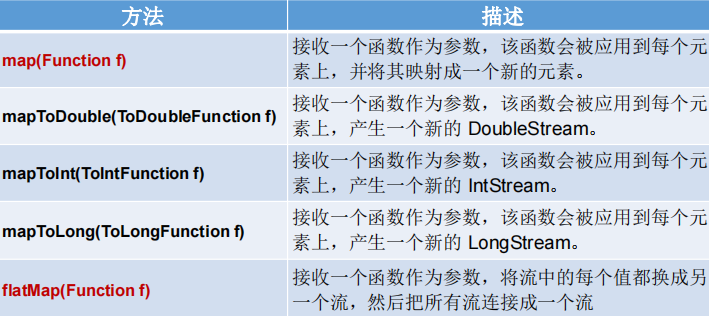
map
public void run4() {
Arrays.asList(1, 2, 3, 4)
.stream()
.map(x -> x + 1)
.forEach(System.out::println);
}
这段代码使用Java的Stream API来遍历一个整数列表,并将每个整数加一。
首先,使用Arrays.asList()方法创建了一个包含四个整数的列表。然后,使用list.stream()获取该列表的流,并调用流的map()方法来对每个整数执行转换。
具体来说,map()方法接受一个函数作为参数,该函数用于将流中的每个元素转换为另一个值。在这里,我们传入了一个匿名函数x -> x + 1,它接受一个整数x作为参数,并返回该整数加一的结果。因此,每个整数都会被加一。
最后,使用流的forEach()方法来遍历流中的所有元素,并将它们打印到控制台。forEach()方法接受一个消费函数作为参数,该函数用于处理流中的每个元素。在这里,我们传入了另一个方法引用System.out::println,它指向System.out对象中的println()方法,因此每个整数都会被打印到控制台。
mapToDouble
@Test
public void run5() {
DoubleStream doubleStream = Arrays.asList(1, 2, 3, 4)
.stream()
.mapToDouble(Math::sqrt);
doubleStream.forEach(System.out::println);
}
在上面的代码中,mapToDouble()方法接受一个函数作为参数,该函数用于将流中的每个元素转换为一个双精度浮点数。我们传入了一个方法引用Math::sqrt,它指向Math类中的sqrt()方法。因此,每个整数都会被转换为它的平方根。
最后,我们创建了一个新的流,squareRoots,它包含了原来的四个整数的平方根。我们可以使用forEach()方法来遍历该流,并将每个平方根打印到控制台
mapToInt
@Test
public void run6() {
int sum = Arrays.asList("1", "2", "3", "4").stream()
.mapToInt(Integer::parseInt)
.sum();
System.out.println(sum);
}
使用stream()获取该列表的流,然后调用mapToInt()方法对每个字符串执行转换。mapToInt()方法接受一个函数作为参数,该函数用于将流中的每个元素转换为整数。在这里,我们传入了一个方法引用Integer::parseInt,它指向Integer类中的parseInt()方法,该方法用于将字符串转换为整数。因此,每个字符串都会被转换为一个整数。
最后,调用sum()方法来求出转换后的整数的和。该方法会对流中的所有元素求和,并返回结果
flatMap
类似scale的扁平化
@Test
public void run7() {
List<String> strings = Arrays.asList("java", "python", "c++");
strings.stream()
.flatMap(x -> Arrays.stream(x.split(" ")))
.forEach(System.out::println);
}
获取了一个字符串列表,然后使用words.stream()获取该列表的流。接着,我们调用流的flatMap()方法,并传入一个函数,该函数将每个字符串转换为一个包含该字符串中所有单词的流。具体来说,我们使用Arrays.stream()方法来将字符串转换为流,并使用字符串的split()方法将字符串拆分为多个单词
3-排序
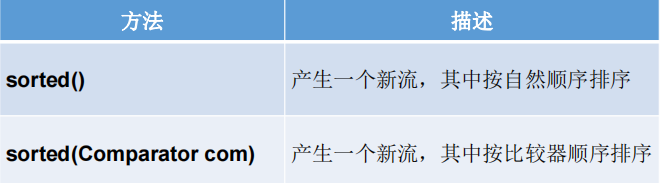
sorted
@Test
public void run8() {
Arrays.asList(1, 2, 3).stream()
.sorted(Comparator.reverseOrder()) //降序排序
.forEach(System.out::println);
}
stream sorted()方法按照比较器对流中的元素进行排序。默认情况下,该方法按照元素的自然顺序进行排序。如果需要按照其他顺序进行排序,可以传入一个比较器参数。
示例:
List<Integer> list = Arrays.asList(5, 3, 7, 1, 9);
list.stream()
.sorted()
.forEach(System.out::println); // 输出:1 3 5 7 9
List<String> words = Arrays.asList("apple", "banana", "orange");
words.stream()
.sorted((s1, s2) -> s2.length() - s1.length())
.forEach(System.out::println); // 输出:orange banana apple
Stream终止操作
-
终端操作会从流的流水线生成结果。其结果可以是任何不是流的值,例如:List、Integer,甚至是 void 。
-
流进行了终止操作后,不能再次使用。
1-匹配与查找
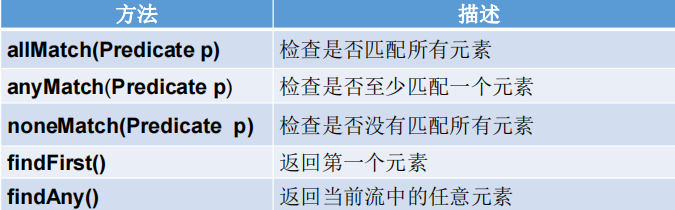

//1-匹配与查找
@Test
public void test1() {
List<Employee> employees = EmployeeData.getEmployees();
//allMatch(Predicate p)——检查是否匹配所有元素。
//练习:是否所有的员工的年龄都大于18
boolean flag = employees.stream().allMatch(employee -> employee.getAge() > 18);
System.out.println(flag);
//anyMatch(Predicate p)——检查是否至少匹配一个元素。
//练习:是否存在员工的工资大于 10000
flag = employees.stream().anyMatch(employee -> employee.getSalary() > 10000);
System.out.println(flag);
//noneMatch(Predicate p)——检查是否没有匹配的元素。
//练习:是否存在员工姓“雷”
flag = employees.stream().noneMatch(employee -> employee.getName().startsWith("雷"));
System.out.println(flag);
//findFirst——返回第一个元素
Optional<Employee> employee = employees.stream().findFirst();
System.out.println(employee);
//findAny——返回当前流中的任意元素
Optional<Employee> any = employees.parallelStream().findAny();
System.out.println(any);
}
@Test
public void test2() {
List<Employee> employees = EmployeeData.getEmployees();
// count——返回流中元素的总个数
long count = employees.stream().filter(e -> e.getSalary() > 5000).count();
System.out.println(count);
System.out.println();
//max(Comparator c)——返回流中最大值
//练习:返回最高的工资:
Optional<Double> max = employees.stream().map(e -> e.getSalary()).max((m1, m2) -> (int) (m1 - m2));
System.out.println(max);
System.out.println();
//min(Comparator c)——返回流中最小值
//练习:返回最低工资的员工
Optional<Employee> min = employees.stream().min((e1, e2) -> (int) (e1.getSalary() - e2.getSalary()));
System.out.println(min);
System.out.println();
//forEach(Consumer c)——内部迭代
employees.stream().forEach(System.out::println);
System.out.println();
//使用集合的遍历操作 --外部迭代
employees.forEach(System.out::println);
}
2-归约
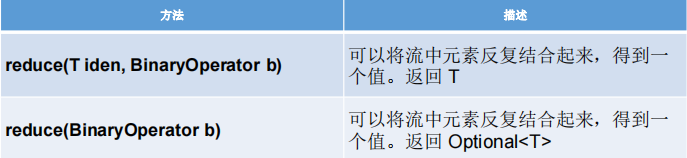
备注:map 和 reduce 的连接通常称为 map-reduce 模式,因 Google 用它来进行网络搜索而出名
reduce
List<Integer> list = Arrays.asList(1,2,3,4,5,6,7,8,9,10);
Integer sum1 = list.stream().reduce(0, Integer::sum);
Integer sum2 = list.stream().reduce(0, (s1,s2)-> s1 + s2);
第一种方式使用了Integer类的静态方法sum()来求和,它接受两个整数类型的参数,返回两个参数的和。
该方法被用作reduce()方法的第二个参数,它会将该列表中的所有元素一个个累加起来,最后返回一个整数类型的和。
第二种方式是使用了Lambda表达式来求和,它接受两个整数类型的参数s1和s2,返回两个参数的和。
该表达式被用作reduce()方法的第二个参数,它会将该列表中的所有元素一个个累加起来,最后返回一个整数类型的和。
两种方式的结果都是相同的,即为该列表中所有元素的和。
第一个参数0代表啥
reduce()方法的第一个参数是初始值,即在累加过程中,第一个元素的初始值。在上面的代码中,第一个参数的值为0,代表在累加过程中,第一个元素的初始值为0。
如果不指定初始值,则默认使用流中的第一个元素作为初始值。例如:
List<Integer> list = Arrays.asList(1,2,3,4,5,6,7,8,9,10);
Integer sum = list.stream().reduce((s1, s2) -> s1 + s2).get(); // sum的值为55,即所有元素的和
List<String> words = Arrays.asList("apple", "banana", "orange");
String concat = words.stream().reduce((s1, s2) -> s1 + "-" + s2).get(); // concat的值为"apple-banana-orange"即所有元素拼接而成的字符串
上面的代码中,没有指定初始值,所以使用了流中的第一个元素作为初始值。
Optional<Double> sumMoney1 = employees.stream()
.map(Employee::getSalary)
.reduce(Double::sum);
Optional<Double> sumMoney2 = employees.stream()
.map(Employee::getSalary)
.reduce((s1,s2)->s1 + s2);
map()方法将一个雇员列表中的每个员工转换为其工资,然后通过reduce()方法将所有工资累加起来。
map()方法的第一个参数是一个Function接口的实例,它接受一个Employee类型的参数,并返回一个Double类型的结果。在这里,它使用了Employee类的getSalary()方法来获取员工的工资。map()方法会将该列表中的每个员工都转换为工资,并返回一个包含所有工资的流。
reduce()方法的第一个参数是一个BinaryOperator接口的实例,它接受两个Double类型的参数,并返回一个Double类型的结果。在这里,它使用了Double类的静态方法sum()来求和,它会将所有工资累加起来,并返回一个Optional
最终结果是一个Optional
double totalSalary = sumMoney1.get(); // totalSalary的值为所有员工的工资和。
3-收集

Collector 接口中方法的实现决定了如何对流执行收集的操作(如收集到 List、Set、Map)。
另外, Collectors 实用类提供了很多静态方法,可以方便地创建常见收集器实例,具体方法与实例如下表:

实例
@Test
public void run12() {
/**
* 返回年龄大于20的用户,并返回为list或者set
*/
List<User> users = User.getUserList();
users.stream()
.filter(user -> user.getAge() > 20)
.collect(Collectors.toList())
.forEach(x -> System.out.println(x.toString()));
}
Optional类
比如在查询数据库时,可能会返回一个可能为空的结果集,如果直接使用这个结果集来获取数据,可能会导致空指针异常。在这种情况下,可以使用Optional类来包装该结果集,然后通过isPresent()方法判断该结果集是否为空,再通过get()方法获取数据,避免空指针异常的发生。
例如:
// 创建一个可能为空的结果集
Optional<ResultSet> result = queryDatabase();
// 判断该结果集是否为空
if (result.isPresent()) {
// 获取结果集中的数据
ResultSet rs = result.get();
while (rs.next()) {
System.out.println(rs.getString("name"));
}
}
上面的代码中,使用Optional类来包装了一个可能为空的结果集,然后通过isPresent()方法来判断该结果集是否为空,如果不为空,则通过get()方法获取结果集中的数据,避免空指针异常的发生。
另外,如果Optional类中的值为空,可以通过orElse()方法来指定一个默认值,以便在获取值时避免空指针异常的发生。
例如:
// 创建一个可能为空的结果集
Optional<ResultSet> result = queryDatabase();
// 获取结果集中的数据,如果为空,则返回默认值null
ResultSet rs = result.orElse(null);
if (rs != null) {
while (rs.next()) {
System.out.println(rs.getString("name"));
}
}
上面的代码中,使用orElse()方法指定了一个默认值null,如果结果集为空,则orElse()方法返回该默认值。这样,在获取结果集中的数据时,就不会出现空指针异常的情况。
总之,Optional类主要用于处理可能为空的值,它提供了一系列方法用于判断值是否为空,获取值,或指定默认值,可以有效避免空指针异常的发生。
User user = new User("张三", 21);
Optional<User> user1 = Optional.ofNullable(user);
如果你想在代码中创建一个 Optional 类对象,并包含一个 User 对象,你可以使用 Optional 的 ofNullable() 方法来创建该对象。例如:
User user = new User("张三", 21);
Optional<User> user1 = Optional.ofNullable(user);
这样就可以创建一个 Optional 对象,并包含一个 User 对象。如果你在创建 Optional 对象时传入的值为 null,那么 Optional 对象也会是空的。例如:
Optional<User> user2 = Optional.ofNullable(null);
这样就创建了一个空的 Optional 对象。你可以通过 isPresent() 方法来检查 Optional 对象是否为空,例如:
if (user2.isPresent()) {
// 在这里处理 user2 对象
} else {
// 在这里处理空的 Optional 对象
}
你也可以通过使用 map() 方法,将 Optional 对象映射到其他值,例如:
Optional<String> userName = user1.map(User::getName);
上面的代码将 User 对象的 name 属性映射到一个 Optional
总之,你可以使用上述方法之一来创建和使用 Optional 类对象。
新时间日期和API
LocalDate、LocalTime、LocalDateTime
LocalDate、LocalTime、LocalDateTime 类的实例是不可变的对象,分别表示使用 ISO-8601日历系统的日期、时间、日期和时间。它们提供了简单的日期或时间,并不包含当前的时间信息。也不包含与时区相关的信息。
注:ISO-8601日历系统是国际标准化组织制定的现代公民的日期和时间的表示法
Java 8 提供了三个新的时间和日期 API 类:LocalDate、LocalTime 和 LocalDateTime,用来替代 Java 旧版本中的 java.util.Date 类。
LocalDate 类表示日期,例如:2020-05-20。
LocalTime 类表示时间,例如:16:23:58.555。
LocalDateTime 类表示日期和时间,例如:2020-05-20T16:23:58.555。
你可以使用以下方法来创建 LocalDate、LocalTime 和 LocalDateTime 对象:
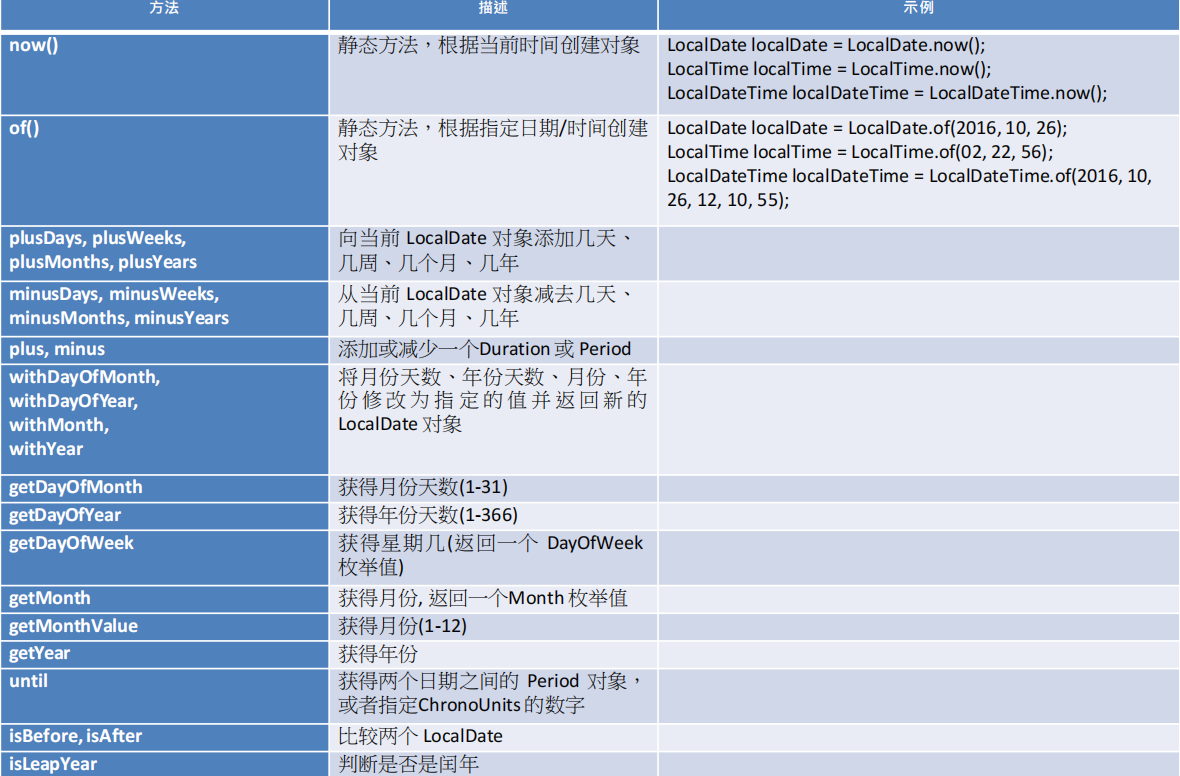
- 使用静态工厂方法:
LocalDate date = LocalDate.of(2020, 5, 20);
LocalTime time = LocalTime.of(16, 23, 58, 555);
LocalDateTime dateTime = LocalDateTime.of(2020, 5, 20, 16, 23, 58, 555);
- 使用静态工厂方法 now(),它将创建一个表示当前时间的对象:
LocalDate date = LocalDate.now();
LocalTime time = LocalTime.now();
LocalDateTime dateTime = LocalDateTime.now();
你还可以通过以下方法来访问 LocalDate、LocalTime 和 LocalDateTime 对象的值:
int year = date.getYear();
Month month = date.getMonth();
int day = date.getDayOfMonth();
int hour = time.getHour();
int minute = time.getMinute();
int second = time.getSecond();
你也可以通过使用 plus() 和 minus() 方法来修改 LocalDate、LocalTime 和 LocalDateTime 对象,例如:
LocalDate date = LocalDate.of(2020, 5, 20);
LocalTime time = LocalTime.of(16, 23, 58, 555);
LocalDateTime dateTime = LocalDateTime.of(2020, 5, 20, 16, 23, 58, 555);
// 增加一天
date = date.plusDays(1);
time = time.plusHours(1);
dateTime = dateTime.plusSeconds(1);
// 减少一天
date = date.minusDays(1);
time = time.minusHours(1);
dateTime = dateTime.minusSeconds(1);
instant
Instant是一种不可变的、线程安全的时间日期对象,它适用于在Java程序中表示时间点。它的主要优点是提供了一种简单的方式来处理时间点,并提供了一些方法来操作时间点。
例如,你可以使用Instant类来获取当前时间点,或者将时间点转换为其他时区的时间点,或者计算两个时间点之间的时间差。
下面是一些使用Instant类的示例代码:
//时间戳
Instant now = Instant.now(Clock.systemDefaultZone());
System.out.println("单位时间秒戳" + now.getEpochSecond());
System.out.println("单位时间为毫秒" + now.toEpochMilli());
System.out.println("字符串表示形式" + now.toString());
//dateformat形式
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
System.out.println(now.atZone(ZoneId.systemDefault()).format(formatter));
// 获取当前时间点
Instant instant1 = Instant.now();
// 将时间点转换为指定时区的时间点
ZoneId zoneId = ZoneId.of("America/New_York");
Instant instant2 = instant1.atZone(zoneId).toInstant();
// 计算两个时间点之间的时间差
Duration duration = Duration.between(instant1, instant2);
long seconds = duration.getSeconds();
Duration 和 Period
-
Duration:用于计算两个“时间”间隔
-
Period:用于计算两个“日期”间隔
Instant ins1 = Instant.now();
Thread.sleep(1000);
Instant ins2 = Instant.now();
System.out.println("所耗费时间为:" + Duration.between(ins1, ins2));
System.out.println("----------------------------------");
LocalDate ld1 = LocalDate.now();
LocalDate ld2 = LocalDate.of(2011, 1, 1);
System.out.println(Period.between(ld1,ld2));
日期的操纵
-
TemporalAdjuster : 时间校正器。有时我们可能需要获取例如:将日期调整到“下个周日”等操作。
-
TemporalAdjusters: 该类通过静态方法提供了大量的常用 TemporalAdjuster 的实现。
LocalDateTime ldt1 = LocalDateTime.now();
System.out.println(ldt1);
LocalDateTime ldt2 = ldt1.withDayOfMonth(10);
System.out.println(ldt2);
//TemporalAdjusters 静态方法对TemporalAdjuster的实现 | 下个周日
LocalDateTime ldt3 = ldt1.with(TemporalAdjusters.next(DayOfWeek.SUNDAY));
System.out.println(ldt3);
//TemporalAdjuster 自定义:下个工作日
LocalDateTime ldt4 = ldt1.with(l->{
LocalDateTime ldt5 = (LocalDateTime) l;
DayOfWeek dayOfWeek = ldt5.getDayOfWeek();
if(dayOfWeek.equals(DayOfWeek.FRIDAY)){
return ldt5.plusDays(3);
}else if(dayOfWeek.equals(DayOfWeek.SATURDAY)){
return ldt5.plusDays(2);
}else{
return ldt5.plusDays(1);
}
});
System.out.println(ldt4);
解释:
这段代码使用了Java 8中的时间日期API。它的目的是演示如何使用LocalDateTime类的一些方法来操作日期时间。
首先,代码使用LocalDateTime.now()方法获取当前日期时间,并将其存储在变量ldt1中。然后,它输出ldt1的值,应该会输出当前的日期时间。
接着,代码使用ldt1.withDayOfMonth(10)方法计算出指定日期时间(ldt1)所在月份的第10天的日期时间,并将结果存储在变量ldt2中。然后,它输出ldt2的值,应该会输出这个日期时间。
接下来,代码使用ldt1.with(TemporalAdjusters.next(DayOfWeek.SUNDAY))方法计算出指定日期时间(ldt1)所在周的下一个星期天的日期时间,并将结果存储在变量ldt3中。然后,它输出ldt3的值,应该会输出这个日期时间。
最后,代码使用ldt1.with()方法和一个Lambda表达式来计算出指定日期时间(ldt1)所在周的下一个工作日的日期时间,并将结果存储在变量ldt4中。然后,它输出ldt4的值,应该会输出这个日期时间。
时区的处理
- Java8 中加入了对时区的支持,带时区的时间为分别为:ZonedDate、ZonedTime、ZonedDateTime
其中每个时区都对应着 ID,地区ID都为 “{区域}/{城市}”的格式
例如 :Asia/Shanghai 等
ZoneId:该类中包含了所有的时区信息
getAvailableZoneIds() : 可以获取所有时区时区信息
of(id) : 用指定的时区信息获取ZoneId 对象
//获取所有的时区
Set<String> set = ZoneId.getAvailableZoneIds();
set.forEach(System.out::println);
LocalDateTime ldt = LocalDateTime.now(ZoneId.of("US/Pacific"));
System.out.println(ldt);
ZonedDateTime zdt = ZonedDateTime.now(ZoneId.of("US/Pacific"));
System.out.println(zdt);
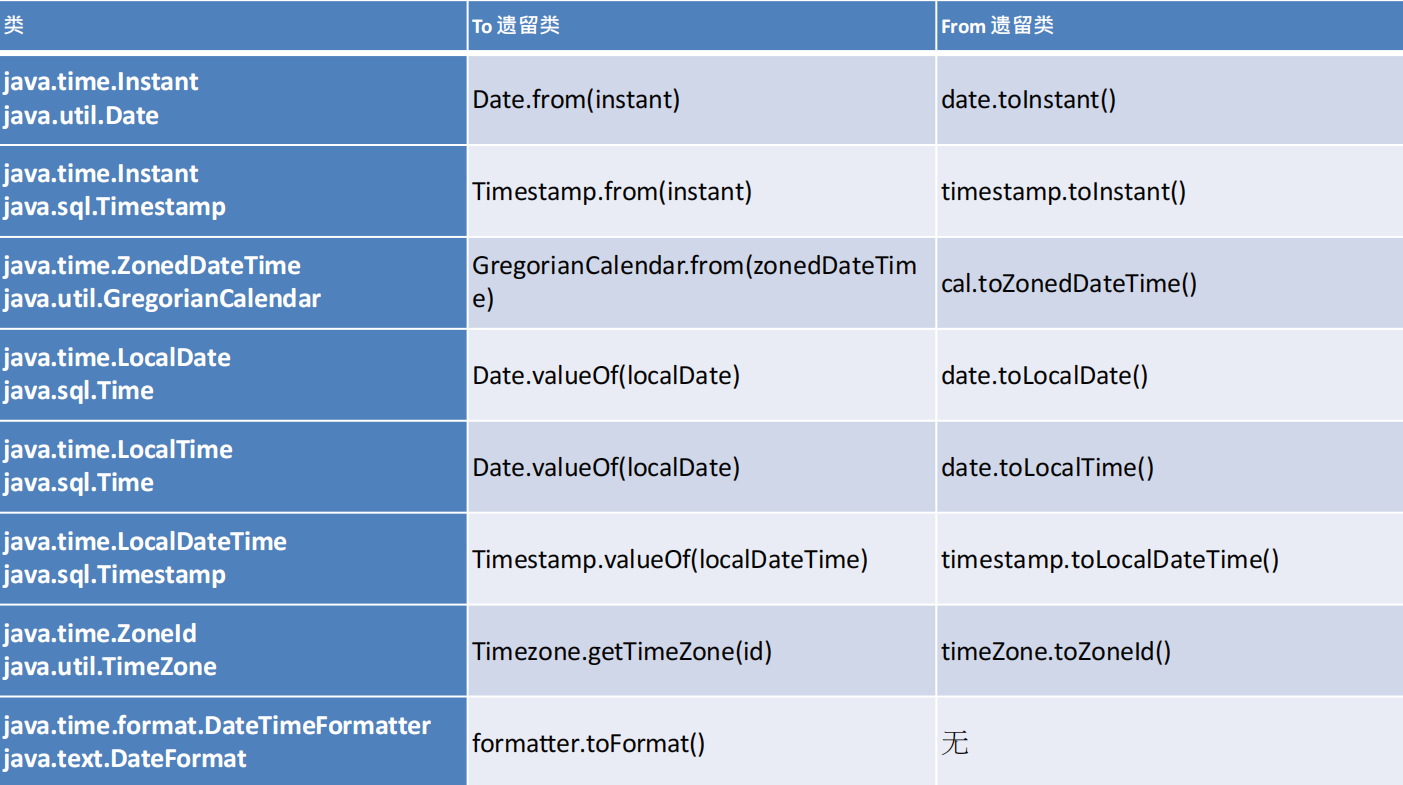
与传统日期处理的转换
接口中的默认方法与静态方法
Java8之前的接口中只能定义全局常量,抽象方法,
Java8之后的接口中能定义全局常量,抽象方法,默认方法以及静态方法
默认方法
Java 8中允许接口中包含具有具体实现的方法,该方法称为“默认方法”,默认方法使用 default 关键字修饰。

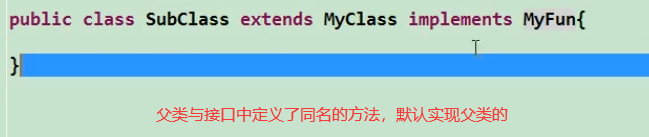
接口中的默认方接口默认方法的”类优先”原则
若一个接口中定义了一个默认方法,而另外一个父类或接口中又定义了一个同名的方法时
(情况一)选择父类中的方法。如果一个父类提供了具体的实现,那么接口中具有相同名称和参数的默认方法会被忽略。
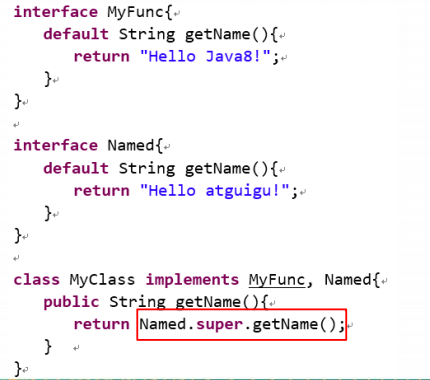
(情况二)接口冲突。如果一个父接口提供一个默认方法,而另一个接口也提供了一个具有相同名称和参数列表的方法(不管方法是否是默认方法),那么必须覆盖该方法来解决冲突
情况一:
情况二:
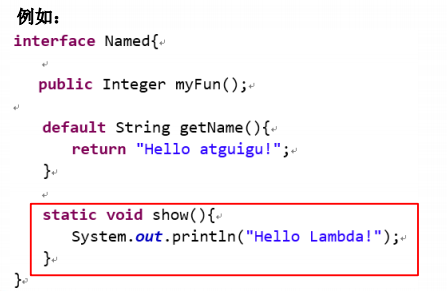
接口中的静态方法
Java8 中,接口中允许添加静态方法。
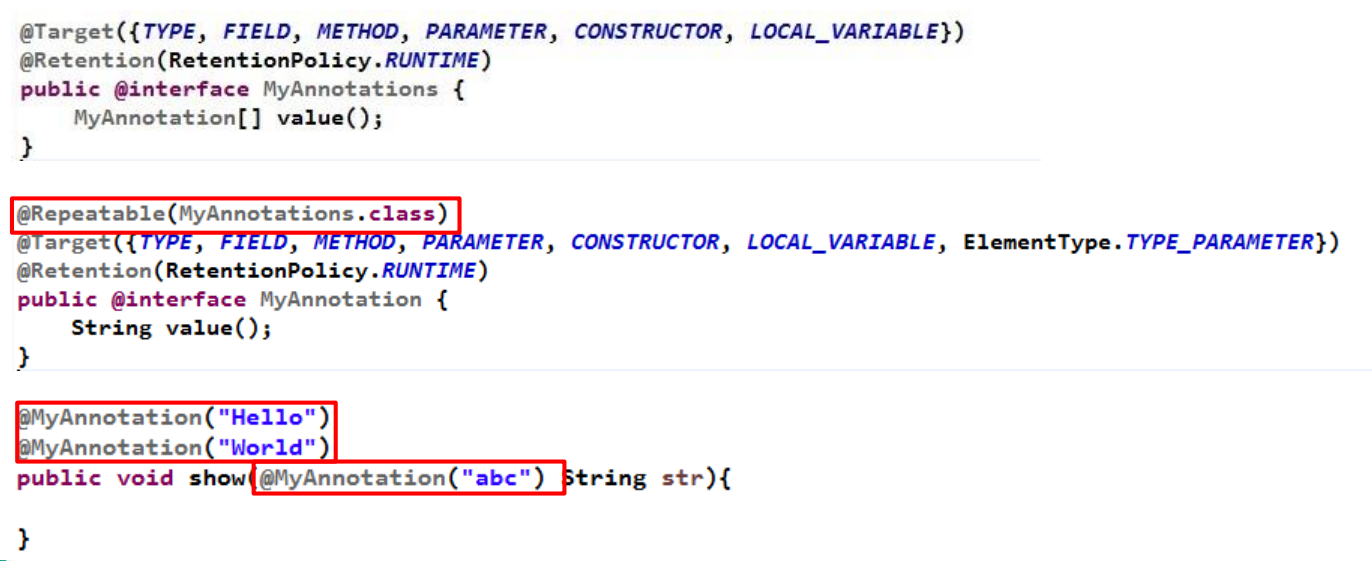
重复注解与类型注解
Java 8对注解处理提供了两点改进:可重复的注解及可用于类型的注解。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· AI与.NET技术实操系列(六):基于图像分类模型对图像进行分类