



1).Python运算符
1.Python算数运算符
描述:
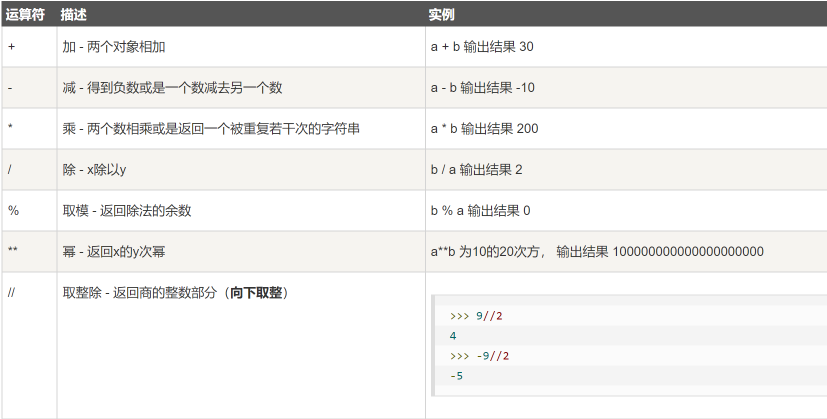
例子:
a = 21
b = 10
c = 0
c = a + b #31
c = a - b #11
c = a * b #210
c = a / b #2.1
c = a % b #1
c = a ** b # 21^10 16679880978201
c = a // b #2
2.Python比较运算符
描述
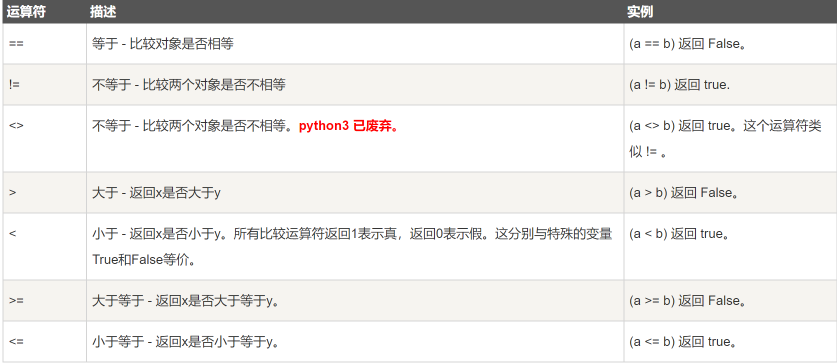
3.Python赋值运算符
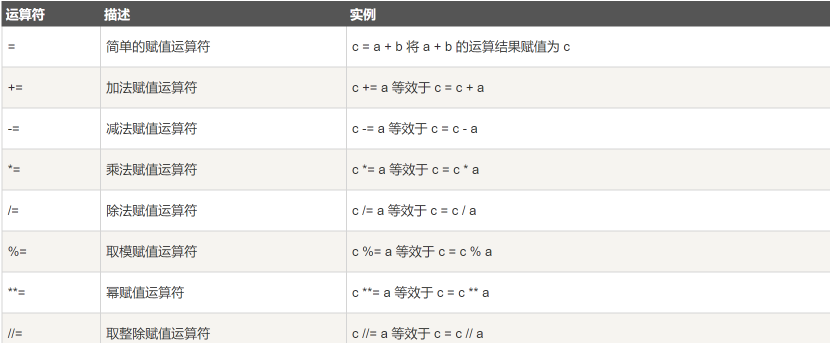
>>> a = 21
>>> b = 10
>>> c = 0
>>> c = a + b
>>> print(c)
31
>>> a+=b
>>> print(a)
31
>>> a-=b
>>> print(a)
21
>>> a*=b
>>> print(a)
210
>>> a/=b
>>> print(a)
21.0
>>> a%=b
>>> print(a)
1.0
>>> a**b
1.0
>>> a//b
0.0
>>>
4.Python位运算符
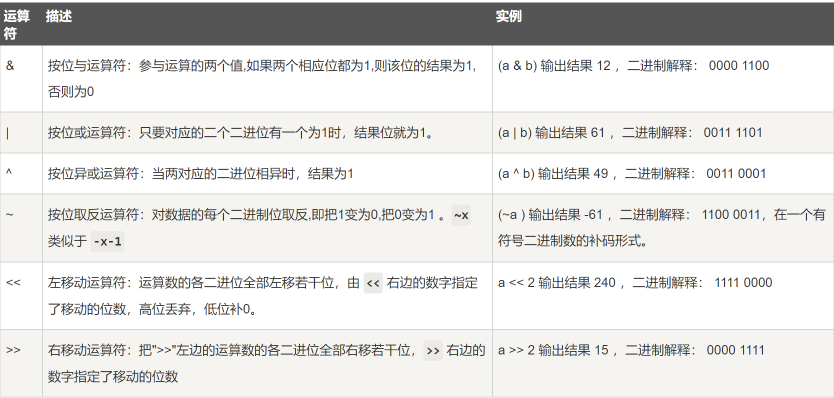
a = 60 # 60 = 0011 1100
b = 13 # 13 = 0000 1101
c = 0
c = a & b; # 12 = 0000 1100
print "1 - c 的值为:", c
c = a | b; # 61 = 0011 1101
print "2 - c 的值为:", c
c = a ^ b; # 49 = 0011 0001
print "3 - c 的值为:", c
c = ~a; # -61 = 1100 0011
print "4 - c 的值为:", c
c = a << 2; # 240 = 1111 0000
print "5 - c 的值为:", c
c = a >> 2; # 15 = 0000 1111
print "6 - c 的值为:", c
5.Python逻辑运算符

a = 1
b = 0
if a and b:
print("变量a和b都为true")
else:
print("变量a和b至少一个为false")
if a or b:
print("a和b当中有至少一个为true")
else:
print("a和b都为false")
if not(a and b):
print("a和b当中至少有一为false")
else:
print("a和b都为true")
6.Python成员运算符
a in b 判断a是否在b中
if ( a in list ):
print "1 - 变量 a 在给定的列表中 list 中"
else:
print "1 - 变量 a 不在给定的列表中 list 中"
7.Python身份运算符
身份运算符用于比较两个对象的存储单元

>>> id(d)
2797830932560
>>> a = 10
>>> b = 10
>>> id(a)
2797830930960
>>> id(b)
2797830930960
>>>
is 与 == 区别:
is 用于判断两个变量引用对象是否为同一个(同一块内存空间), == 用于判断引用变量的值是否相等。
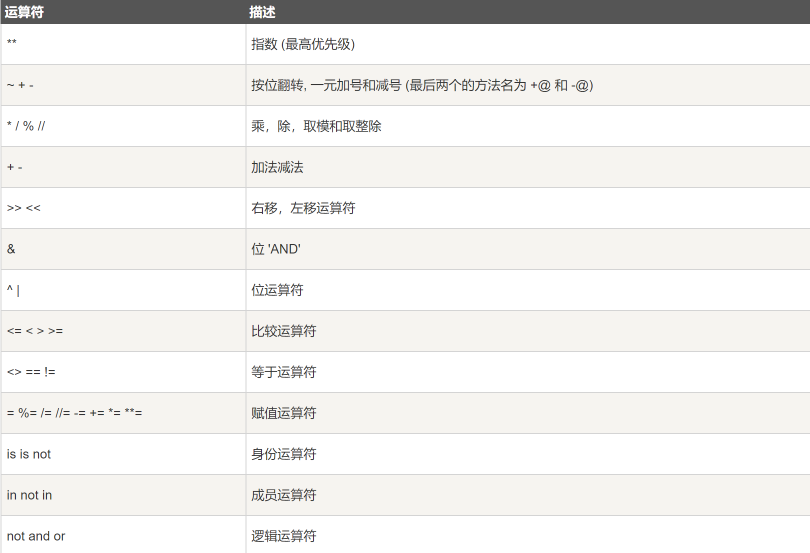
8.Python运算符优先级
2). Python条件语句
if 判断条件:
执行语句……
else:
执行语句……
num = 5
if num > 5:
print(">5")
elif num == 4:
print("=4")
elif num < 4 & num >1:
print("<4")
else:
print("=5")
if num > 5: print(">5")
3).Python While 循环语句
while 判断条件(condition):
执行语句(statements)……
例子:
while len(numbers) > 0:
a = numbers.pop()
if a % 2 == 0:
list1.append(a)
else:
list2.append(a)
print(list1)
print(list2)
无限循环
如果条件判断语句永远为 true,循环将会无限的执行下去,如下实例:
var = 1
while var == 1:
var1 = input("enter a number:")
print("you entered:",var1)
print("good bye")
循环使用 else 语句
count = 0
while count < 5:
print("count:",count)
count = count + 1
else:
print("conunt >= 5")
4).Python for 循环语句
for iterating_var in sequence:
statements(s)
str = "helloworld" #遍历字符串
str1 = [3,5,1,2,4,8] #遍历列表
str2 = ("this","is","python") #遍历元组
str3 = {"name":"zhangsan","age":19} #遍历字典 只会遍历key
for x in str3:
print(x)
通过序列索引迭代
str1 = [3,5,1,2,4,8] #遍历列表
for y in range(len(str1)):
print(str1[y])
循环使用 else 语句
for num in range(10, 20):
for y in range(2, num):
if num % y == 0:
z = num / y
print('%d = % d * %d' % (num, y, z))
break
else:
print('%d is 质数' % num)
5).Python 循环嵌套
Python for 循环嵌套语法:
for iterating_var in sequence:
for iterating_var in sequence:
statements(s)
statements(s)
Python while 循环嵌套语法:
while expression:
while expression:
statement(s)
statement(s)
6).Python break 语句
Python break语句,就像在C语言中,打破了最小封闭for或while循环。
break语句用来终止循环语句,即循环条件没有False条件或者序列还没被完全递归完,也会停止执行循环语句。
break语句用在while和for循环中。
如果您使用嵌套循环,break语句将停止执行最深层的循环,并开始执行下一行代码。
7).Python continue 语句
Python continue 语句跳出本次循环,而break跳出整个循环。
continue 语句用来告诉Python跳过当前循环的剩余语句,然后继续进行下一轮循环。
continue语句用在while和for循环中。
a = 'hello,python'
for x in a:
if x == 'o':
continue
print(x)
var = 10
while var > 0:
var = var - 1
if var == 5:
continue
print(var)
8).Python Number(数字)
Python Number 数据类型用于存储数值。
数据类型是不允许改变的,这就意味着如果改变 Number 数据类型的值,将重新分配内存空间。
以下实例在变量赋值时 Number 对象将被创建:
var1 = 1
var2 = 2
使用del语句删除一些数字的引用
del var1 var2
del删除多个对象
del var1,var2
1. 四种不同的数值类型
int 1 2
long 10L #长整型也可以使用小写"L",但是还是建议您使用大写"L",避免与数字"1"混淆。Python使用"L"来显示长整型
float 12.12
complex 3+26J #Python还支持复数,复数由实数部分和虚数部分构成,可以用a + bj,或者complex(a,b)表示, 复数的实部a和虚部b都是浮点型
2.Python Number 类型转换
int(x [,base ]) 将x转换为一个整数
long(x [,base ]) 将x转换为一个长整数
float(x ) 将x转换到一个浮点数
complex(real [,imag ]) 创建一个复数
str(x ) 将对象 x 转换为字符串
repr(x ) 将对象 x 转换为表达式字符串
eval(str ) 用来计算在字符串中的有效Python表达式,并返回一个对象
tuple(s ) 将序列 s 转换为一个元组
list(s ) 将序列 s 转换为一个列表
chr(x ) 将一个整数转换为一个字符
unichr(x ) 将一个整数转换为Unicode字符
ord(x ) 将一个字符转换为它的整数值
hex(x ) 将一个整数转换为一个十六进制字符串
oct(x ) 将一个整数转换为一个八进制字符串
3.Python随机数函数

import random
random.choice(seq) #seq可以试字符串、列表、元组
random.randrange ([start,] stop [,step]) ## 从start 到 stop ,步长为2
random.random() # 返回0-1之间的值
random.shuffle(lst) #将lst随机排序
random.uniform(x, y) #生成一个x-y之间的实数
int(random.uniform(x,y)) # 可以做如下修改,改为整数
9).Python 字符串
字符串是 Python 中最常用的数据类型。我们可以使用引号 ( ' 或 " ) 来创建字符串。
创建字符串很简单,只要为变量分配一个值即可。例如:
var1 = 'python'
var2 = "python2"
访问字符串的值
var1 = 'Hello World!'
var2 = "Python Runoob"
print "var1[0]: ", var1[0]
print "var2[1:5]: ", var2[1:5]
Python 字符串连接
Python字符串运算符
+ 字符串连接
* 重复输出
[] 通过索引获取字符串字符
[:] 截取字符串的一部分
in 成员运算符
not in 如果字符串不包含在给定的字符中
r/R 原始字符串 没有不能打印的字符
% 格式化字符串
>>> var1 = 'python'
>>> var2 = var1 + "666"
>>> var2
'python666'
>>> var1 * 2
'pythonpython'
>>> var1[1]
'y'
>>> var1[1:]
'ython'
>>> 'p' in var1
True
>>> 'p' not in var1
False
>>> print(r'\n\t\z')
\n\t\z
>>>
Python 字符串格式化
基本的用法是将一个值插入到一个有字符串格式符 %s 的字符串中。
print "My name is %s and weight is %d kg!" % ('Zara', 21)
Python 三引号
Python 中三引号可以将复杂的字符串进行赋值。
Python 三引号允许一个字符串跨多行,字符串中可以包含换行符、制表符以及其他特殊字符。
三引号的语法是一对连续的单引号或者双引号(通常都是成对的用)。
>>> h = '''ahsia
... asasa
... asa'''
>>> print(h)
ahsia
asasa
asa
>>>
python的字符串内建函数
10). Python 列表(List)
列表的数据项不需要具有相同的类型
序列都可以进行的操作包括索引,切片,加,乘,检查成员
Python已经内置确定序列的长度以及确定最大和最小的元素的方法
list = [1,2,3,'a','4','test']
访问列表中的值
list1 = list[0]
list1 = list[5:]
更新列表
可以使用append()方法来添加列表项
list = [] #空列表
list.append('good') #添加元素
删除列元素
var = [1,2,'python'] #定义一个列表
del var #删除列表
del var1,var2 #删除多个列表
del var[2] #删除列表中第三个元素
列表脚本操作符
len(a) # a可以试字符串、列表、元组、字典
3 in[2,3,4] #3存在的话,返回True
列表截取
a = ['java','python','c++']
0 1 2
-3 -2 -1
a[0] 和a[-3] 取到的值为 ’java‘
#截取
a[1:] # 取下标为1到最后
列表中的函数和方法
| 序号 | 函数 |
|---|---|
| 1 | cmp(list1, list2) 比较两个列表的元素 |
| 2 | len(list) 列表元素个数 |
| 3 | max(list) 返回列表元素最大值 |
| 4 | min(list) 返回列表元素最小值 |
| 5 | list(seq) 将元组转换为列表 |
| 1 | list.append(obj) 在列表末尾添加新的对象 |
|---|---|
| 2 | list.count(obj) 统计某个元素在列表中出现的次数 |
| 3 | list.extend(seq) 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
| 4 | list.index(obj) 从列表中找出某个值第一个匹配项的索引位置 |
| 5 | list.insert(index, obj) 将对象插入列表 |
| 6 | [list.pop(index=-1]) 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 |
| 7 | list.remove(obj) 移除列表中某个值的第一个匹配项 |
| 8 | list.reverse() 反向列表中元素 |
| 9 | list.sort(cmp=None, key=None, reverse=False) 对原列表进行排序 |
11).Python元组
元组与列表类似,不同之处在于元组的元素不能修改
元组用’( )‘ ,列表用’[ ]‘
定义:
创建空元组
tup1 = ()
tup1 = (50,) #插入一个元素时,需要在元素后面添加逗号
访问元组:
和字符串类似,下标索引从0开始,可以进行截取,组合等
实例:
tupe1 = ('hello','python','china')
print(tuple1[1]) # 'python'
print(yuple1[1:]) # ['python' 'china']
修改元组:
由于元组不可修改,所以只能进行组合操作
a = (1,2,3)
b = (4,5,6)
c = a + b # (1,2,3,4,5,6) 创建一个新的元组
元组运算符:
len((1,2,3))
(1,2,3) + (4,5,6)
('hi') * 3
3 in (1,2,3)
for x in (1,2,3): print(x)
元组索引,截取
L = ('spam', 'Spam', 'SPAM!')
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| L[2] | 'SPAM!' | 读取第三个元素 |
| L[-2] | 'Spam' | 反向读取,读取倒数第二个元素 |
| L[1:] | ('Spam', 'SPAM!') | 截取元素 |
元组内置函数
| 1 | cmp(tuple1, tuple2) 比较两个元组元素。 |
|---|---|
| 2 | len(tuple) 计算元组元素个数。 |
| 3 | max(tuple) 返回元组中元素最大值。 |
| 4 | min(tuple) 返回元组中元素最小值。 |
| 5 | tuple(seq) 将列表转换为元组。 |
12).Python字典
- 可存储任意类型对象
- 采用key:value 对,用冒号分隔
- 键是唯一的,如果重复,最后一个键的值会替换前面的,值不需要唯一
定义:
d = {key1:value1,key2:value2}
访问字典的值
tinydict= {'name':'zhangsan','age':12,'class':'math'}
print(tinydict['name'])
修改:
向字典添加新的键值对,修改或者删除已有的键值对
tinydict= {'name':'zhangsan','age':12,'class':'math'}
tinydict['name']='lisi'
tinydict['score']=99
删除字典元素
del tinydict #清空字典
del tinydict['name'] #删除元素
字典的特效
key 唯一,否则取最后一个
键必须不可变,所以可以用数字、字符串或元组充当,用列表不行,(列表的元素可变)
d = {['name']:'zhangsan'} #key为列表 错误
d = {('name'):'zhangsan'} #key为元组
d['naem']
字典内置函数&方法
| 1 | cmp(dict1, dict2) 比较两个字典元素。 |
|---|---|
| 2 | len(dict) 计算字典元素个数,即键的总数。 |
| 3 | str(dict) 输出字典可打印的字符串表示。 |
| 4 | type(variable) 返回输入的变量类型,如果变量是字典就返回字典类型。 |
dict.clear() 清空字典所有元素
dict.copy() 返回一个字典的浅复制
浅拷贝 :相当于做了一个引用
深拷贝:深拷贝父对象(一级目录),子对象(二级目录)不拷贝,还是引用
- dict.items() 返回可遍历的元组数组
13).Python 日期和时间
Python 提供了一个 time 和 calendar 模块可以用于格式化日期和时间
例子:
import time
ticks = time.time()
print('当前时间戳:',ticks)
时间元组
很多Python函数用一个元组装起来的9组数字处理时间:
上述也就是struct_time元组。这种结构具有如下属性:
| 0 | tm_year | 2008 |
|---|---|---|
| 1 | tm_mon | 1 到 12 |
| 2 | tm_mday | 1 到 31 |
| 3 | tm_hour | 0 到 23 |
| 4 | tm_min | 0 到 59 |
| 5 | tm_sec | 0 到 61 (60或61 是闰秒) |
| 6 | tm_wday | 0到6 (0是周一) |
| 7 | tm_yday | 1 到 366(儒略历) |
| 8 | tm_isdst | -1, 0, 1, -1是决定是否为夏令时的旗帜 |
获取当前时间
import time
localtime=time.localtime(time.time()) # localtime(‘时间’) 传入一个时间戳
localtime=time.localtime() #获取当前的时间
print(localtime)
格式化时间
我们可以使用 time 模块的 strftime 方法来格式化日期
time.strftime(format[,t])
import time
time1 = time.strftime('%Y-%m-%d %H:%M:%S',time.localtime())
'2022-05-28 18:21:16'
获取某月日历 calendar模块
import calendar
cal = calender.month(2016,1)
14).Python函数
函数的定义:
def 函数名(参数):
内容
return [表达式]
- return [表达式]** 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
函数调用
# 定义函数
def printme( str ):
"打印任何传入的字符串"
print str
return
# 调用函数
printme("我要调用用户自定义函数!")
printme("再次调用同一函数")
参数传递
在 python 中,类型属于对象,变量是没有类型的
a=[1,2,3]
a="Runoob"
以上代码中,[1,2,3] 是 List 类型,"Runoob" 是 String 类型,而变量 a 是没有类型,她仅仅是一个对象的引用(一个指针),可以是 List 类型对象,也可以指向 String 类型对象
可更改(mutable)与不可更改(immutable)对象
在 python 中,strings, tuples, 和 numbers 是不可更改的对象,而 list,dict 等则是可以修改的对象
不可变类型:数字、strin、元组
a = 5
a = 10
这里实际是新生成一个 int 值对象 10,再让 a 指向它,而 5 被丢弃,不是改变a的值,相当于新生成了a
str = [1,2,3]
可变类型:列表、字典
将列表的第二个元素更改为2.2
str = [1,2,3]
str[1]=2.2
修改年龄为90
dit = {'name':'zhangsan','age':16}
dit['age']=90
python函数的参数传递:
- 不可变类型:类似 c++ 的值传递,如 整数、字符串、元组。如fun(a),传递的只是a的值,没有影响a对象本身。比如在 fun(a)内部修改 a 的值,只是修改另一个复制的对象,不会影响 a 本身。
def fun(a):
a=10
b=2
fun(b)
print(b) #结果为2
- 可变类型:类似 c++ 的引用传递,如 列表,字典。如 fun(la),则是将 la 真正的传过去,修改后fun外部的la也会受影响
def fun(a):
a.append([1,2,3])
print(a) #函数内 [12, 13, 14, [1, 2, 3]]
b = [12,13,14]
fun(b)
print(b) #函数外 [12, 13, 14, [1, 2, 3]]
必备参数:函数定义需要传参数时,调用时必须填写
def fun(str):
print(str)
fun(str)
关键字参数:
def fun(name):
print(name)
fun(name='zhangsan')
默认参数:
def fun(name,age=12):
print(name,age)
fun(name='zhangsan',age=30) # zhangsan 30
fun(name='zhangsan') #zhangsan 12
不定长参数:
加了星号(*)的变量名会存放所有未命名的变量参数
def fun(name,*techang):
print(name)
for x in techang:
print(x)
return
#调用
fun('张三','乒乓球','羽毛球','篮球')
匿名函数:
python 使用 lambda 来创建匿名函数。
sum = lambda x,y:x+y
print(sum(1,2))
变量作用域
局部变量
全局变量
15).Python模块
模块的定义:(类似Java的类文件,但是Java除了定义Package,需要创建对象来使用,Python直接import导入)
support.py
def qiuhe(a,b):
return a + b
模块的使用:import语句
import support
c = qiuhe(1,2)
print(c) #3
from…import 语句
Python 的 from 语句让你从模块中导入一个指定的部分到当前命名空间中。语法如下
from fib import fibonacci
from…import* 语句
把一个模块的所有内容全都导入到当前的命名空间也是可行的,只需使用如下声明
from modname import *
模块的搜索路径
- 1、当前目录
- 2、如果不在当前目录,Python 则搜索在 shell 变量 PYTHONPATH 下的每个目录。
- 3、如果都找不到,Python会察看默认路径。UNIX下,默认路径一般为/usr/local/lib/python/。
命令空间和作用域
一个 Python 表达式可以访问局部命名空间和全局命名空间里的变量。如果一个局部变量和一个全局变量重名,则局部变量会覆盖全局变量。
每个函数都有自己的命名空间。类的方法的作用域规则和通常函数的一样
global VarName 的表达式会告诉 Python, VarName 是一个全局变量,这样 Python 就不会在局部命名空间里寻找这个变量了。
Money = 2000
def AddMoney():
# 想改正代码就取消以下注释:
# global Money
Money = Money + 1
print Money
AddMoney()
print Money
dir()函数
dir() 函数一个排好序的字符串列表,内容是一个模块里定义过的名字
#导入内置的math模块
import math
content = dir(math)
print content
reload()函数
当一个模块被导入到一个脚本,模块顶部的代码只会被执行一个
如果想重新执行模块顶部的代码,可以用reload()函数
reload(module_name)
Python中的包
包就是文件夹,该文件夹下必须存在__init__.py文件,可以为空,用于标识当前文件为包
test.py
package_runoob
|-- __init__.py
|-- runoob1.py
|-- runoob2.py
如何调用,在 package_runoob 同级目录下创建 test.py 来调用 package_runoob 包
from package_ruuoob.runppb1 import runoob1
from package_runoob.runoob2 import runoob2
runoob1()
runoob2()
16).Python文件IO
读取键盘输入
raw_input
input
打开和关闭
file.open(file_name,access_mode,buffering)
- file_name:file_name变量是一个包含了你要访问的文件名称的字符串值。
- access_mode:access_mode决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。
- buffering:如果buffering的值被设为0,就不会有寄存。如果buffering的值取1,访问文件时会寄存行。如果将buffering的值设为大于1的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。
| 模式 | r | r+ | w | w+ | a | a+ |
|---|---|---|---|---|---|---|
| 读 | + | + | + | + | ||
| 写 | + | + | + | + | + | |
| 创建 | + | + | + | + | ||
| 覆盖 | + | + | ||||
| 指针在开始 | + | + | + | + | ||
| 指针在结尾 | + | + |
File对象的属性
| 属性 | 描述 |
|---|---|
| file.closed | 返回true如果文件已被关闭,否则返回false。 |
| file.mode | 返回被打开文件的访问模式。 |
| file.name | 返回文件的名称。 |
| file.softspace | 如果用print输出后,必须跟一个空格符,则返回false。否则返回true。 |
close()方法
File 对象的 close()方法刷新缓冲区里任何还没写入的信息,并关闭该文件,这之后便不能再进行写入。
当一个文件对象的引用被重新指定给另一个文件时,Python 会关闭之前的文件。用 close()方法关闭文件是一个很好的习惯。
write()方法
write()方法可将任何字符串写入一个打开的文件。需要重点注意的是,Python字符串可以是二进制数据,而不是仅仅是文字。
write()方法不会在字符串的结尾添加换行符('\n'):
read()方法
read()方法从一个打开的文件中读取一个字符串。需要重点注意的是,Python字符串可以是二进制数据,而不是仅仅是文字。
语法:
fileObject.read([count])
在这里,被传递的参数是要从已打开文件中读取的字节计数。该方法从文件的开头开始读入,如果没有传入count,它会尝试尽可能多地读取更多的内容,很可能是直到文件的末尾。
文件定位
file.tell() 当前读取的文件位置
file.seek(offset,from) offset 要移动的字节数 from 从那个位置开始
1 :当前位置
0:从头开始
2: 从末尾开始
重命名和删除文件 os模块
os.rename(current_file_name, new_file_name)
import os
os.rename('test1.txt','test2.txt')
remove()方法
os.remove(file_name)
Python里的目录
os,mkdir('newdir') #创建目录
os.chdir('newdir') #改变当前目录
os.rmdir() #删除目录 ,删除钱,内容应该被清除
文件、目录相关的方法
os 提供了处理文件及目录的一系列方法
file 对象提供了操作文件的一系列方法
17).Python File(文件) 方法
open() 方法
Python open() 方法用于打开一个文件,并返回文件对象,在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError。
注意:使用 open() 方法一定要保证关闭文件对象,即调用 close() 方法。
open() 函数常用形式是接收两个参数:文件名(file)和模式(mode)。
open(file,mode='r')
完整的语法格式为
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
参数说明:
- file: 必需,文件路径(相对或者绝对路径)。
- mode: 可选,文件打开模式
- buffering: 设置缓冲
- encoding: 一般使用utf8
- errors: 报错级别
- newline: 区分换行符
- closefd: 传入的file参数类型
- opener: 设置自定义开启器,开启器的返回值必须是一个打开的文件描述符
mode 参数有:
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(不推荐)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
默认为文本模式,如果要以二进制模式打开,加上 b
file 对象
file 对象使用 open 函数来创建,下表列出了 file 对象常用的函数:
| 序号 | 方法及描述 |
|---|---|
| 1 | file.close()关闭文件。关闭后文件不能再进行读写操作。 |
| 2 | file.flush()刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入。 |
| 3 | file.fileno()返回一个整型的文件描述符(file descriptor FD 整型), 可以用在如os模块的read方法等一些底层操作上。 |
| 4 | file.isatty()如果文件连接到一个终端设备返回 True,否则返回 False。 |
| 5 | file.next()返回文件下一行。 |
| 6 | [file.read(size])从文件读取指定的字节数,如果未给定或为负则读取所有。 |
| 7 | [file.readline(size])读取整行,包括 "\n" 字符。 |
| 8 | [file.readlines(sizeint])读取所有行并返回列表,若给定sizeint>0,则是设置一次读多少字节,这是为了减轻读取压力。 |
| 9 | [file.seek(offset, whence])设置文件当前位置 |
| 10 | file.tell()返回文件当前位置。 |
| 11 | [file.truncate(size])截取文件,截取的字节通过size指定,默认为当前文件位置。 |
| 12 | file.write(str)将字符串写入文件,返回的是写入的字符长度。 |
| 13 | file.writelines(sequence)向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。 |
18).Python异常处理
异常处理
断言
python标准异常
| 异常名称 | 描述 |
|---|---|
| BaseException | 所有异常的基类 |
| SystemExit | 解释器请求退出 |
| KeyboardInterrupt | 用户中断执行(通常是输入^C) |
| Exception | 常规错误的基类 |
| StopIteration | 迭代器没有更多的值 |
| GeneratorExit | 生成器(generator)发生异常来通知退出 |
| StandardError | 所有的内建标准异常的基类 |
| ArithmeticError | 所有数值计算错误的基类 |
异常处理
try:
<语句> #运行别的代码
except <名字>:
<语句> #如果在try部份引发了'name'异常
except <名字>,<数据>:
<语句> #如果引发了'name'异常,获得附加的数据
else:
<语句> #如果没有异常发生
例子:
try:
fh = open("testfile", "w")
fh.write("这是一个测试文件,用于测试异常!!")
except IOError:
print "Error: 没有找到文件或读取文件失败"
else:
print "内容写入文件成功"
fh.close()
使用except而不带任何异常类型
你可以不带任何异常类型使用except,如下实例:
try:
正常的操作
......................
except:
发生异常,执行这块代码
......................
else:
如果没有异常执行这块代码
以上方式try-except语句捕获所有发生的异常。但这不是一个很好的方式,我们不能通过该程序识别出具体的异常信息。因为它捕获所有的异常。
使用except而带多种异常类型
try:
正常的操作
......................
except(Exception1[, Exception2[,...ExceptionN]]):
发生以上多个异常中的一个,执行这块代码
......................
else:
如果没有异常执行这块代码
try-finally 语句
try-finally 语句无论是否发生异常都将执行最后的代码。
try:
<语句>
finally:
<语句> #退出try时总会执行
raise
异常的参数
一个异常可以带上参数,可作为输出的异常信息参数。
你可以通过except语句来捕获异常的参数,如下所示:
try:
正常的操作
......................
except ExceptionType, Argument:
你可以在这输出 Argument 的值...
触发异常
可以使用raise语句自己触发异常
格式如下:
raise [exception,args]
例子
def fun(level):
if level < 1:
raise Exception("Invaild level!",level)
#触发异常后,后面的代码就不会执行了
注意:为了能够捕获异常,"except"语句必须有用相同的异常来抛出类对象或者字符串
try:
正常逻辑
except Exception,err:
触发自定义异常
else:
其余代码
例子:
# 定义函数
def mye( level ):
if level < 1:
raise Exception,"Invalid level!"
# 触发异常后,后面的代码就不会再执行
try:
mye(0) # 触发异常
except Exception,err:
print 1,err
else:
print 2
用户自定义异常
通过创建一个新的异常类,程序可以命名它们自己的异常。异常应该是典型的继承自Exception类,通过直接或间接的方式。
以下为与RuntimeError相关的实例,实例中创建了一个类,基类为RuntimeError,用于在异常触发时输出更多的信息。
在try语句块中,用户自定义的异常后执行except块语句,变量 e 是用于创建Networkerror类的实例。
class Networkerror(RuntimeError):
def __init__(self, arg):
self.args = arg
在你定义以上类后,你可以触发该异常,如下所示:
try:
raise Networkerror("Bad hostname")
except Networkerror,e:
print e.args
19).Python OS 文件/目录方法
os 模块提供了非常丰富的方法用来处理文件和目录。常用的方法如下表所示:
例子
os.access(path,mode)
path:检测是否有访问权限的路径
mode:
- os.F_OK: 作为access()的mode参数,测试path是否存在。
- os.R_OK: 包含在access()的mode参数中 , 测试path是否可读。
- os.W_OK 包含在access()的mode参数中 , 测试path是否可写。
- os.X_OK 包含在access()的mode参数中 ,测试path是否可执行。
返回值
如果允许访问返回 True , 否则返回False。
| 序号 | 方法及描述 |
|---|---|
| 1 | os.access(path, mode) 检验权限模式 |
| 2 | os.chdir(path) 改变当前工作目录 |
| 3 | os.chflags(path, flags) 设置路径的标记为数字标记。 |
| 4 | os.chmod(path, mode) 更改权限 |
| 5 | os.chown(path, uid, gid) 更改文件所有者 |
20).Python 内置函数
21).Python面向对象
- 类(Class): 用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。
- 类变量:类变量在整个实例化的对象中是公用的。类变量定义在类中且在函数体之外。类变量通常不作为实例变量使用。
- 数据成员:类变量或者实例变量, 用于处理类及其实例对象的相关的数据。
- 方法重写:如果从父类继承的方法不能满足子类的需求,可以对其进行改写,这个过程叫方法的覆盖(override),也称为方法的重写。
- 局部变量:定义在方法中的变量,只作用于当前实例的类。
- 实例变量:在类的声明中,属性是用变量来表示的。这种变量就称为实例变量,是在类声明的内部但是在类的其他成员方法之外声明的。
- 继承:即一个派生类(derived class)继承基类(base class)的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待。例如,有这样一个设计:一个Dog类型的对象派生自Animal类,这是模拟"是一个(is-a)"关系(例图,Dog是一个Animal)。
- 实例化:创建一个类的实例,类的具体对象。
- 方法:类中定义的函数。
- 对象:通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法。
创建类
使用class语句创建一个新类
class ClassName:
'类的帮助信息'
class_suite #类体
实例:
class Employee:
empCount=0
def __init__(self,name,age):
self.name=name
self.age=age
Employee.empCount+=1
def displayCount(self):
print "Total Employee %d" % Employee.empCount
def displayEmployee(self):
print "Name : ", self.name, ", Salary: ", self.salary
- empCount 变量是一个类变量,它的值将在这个类的所有实例之间共享。你可以在内部类或外部类使用 Employee.empCount 访问。
- 第一种方法__init__()方法是一种特殊的方法,被称为类的构造函数或初始化方法,当创建了这个类的实例时就会调用该方法
- self 代表类的实例,self 在定义类的方法时是必须有的,虽然在调用时不必传入相应的参数。
self代表类的实例,而非类
class Test:
def prt(self):
print(self)
print(self.__class__)
t = Test()
t.prt()
以上输出:
<__main__.Test instance at 0x10d066878>
__main__.Test
self 代表的是类的实例,代表当前对象的地址,而 self.class 则指向类。
self 不是 python 关键字,我们把他换成 runoob 也是可以正常执行的
创建实例对象
没有Java类似的new关键字
采用函数调用的方式创建实例
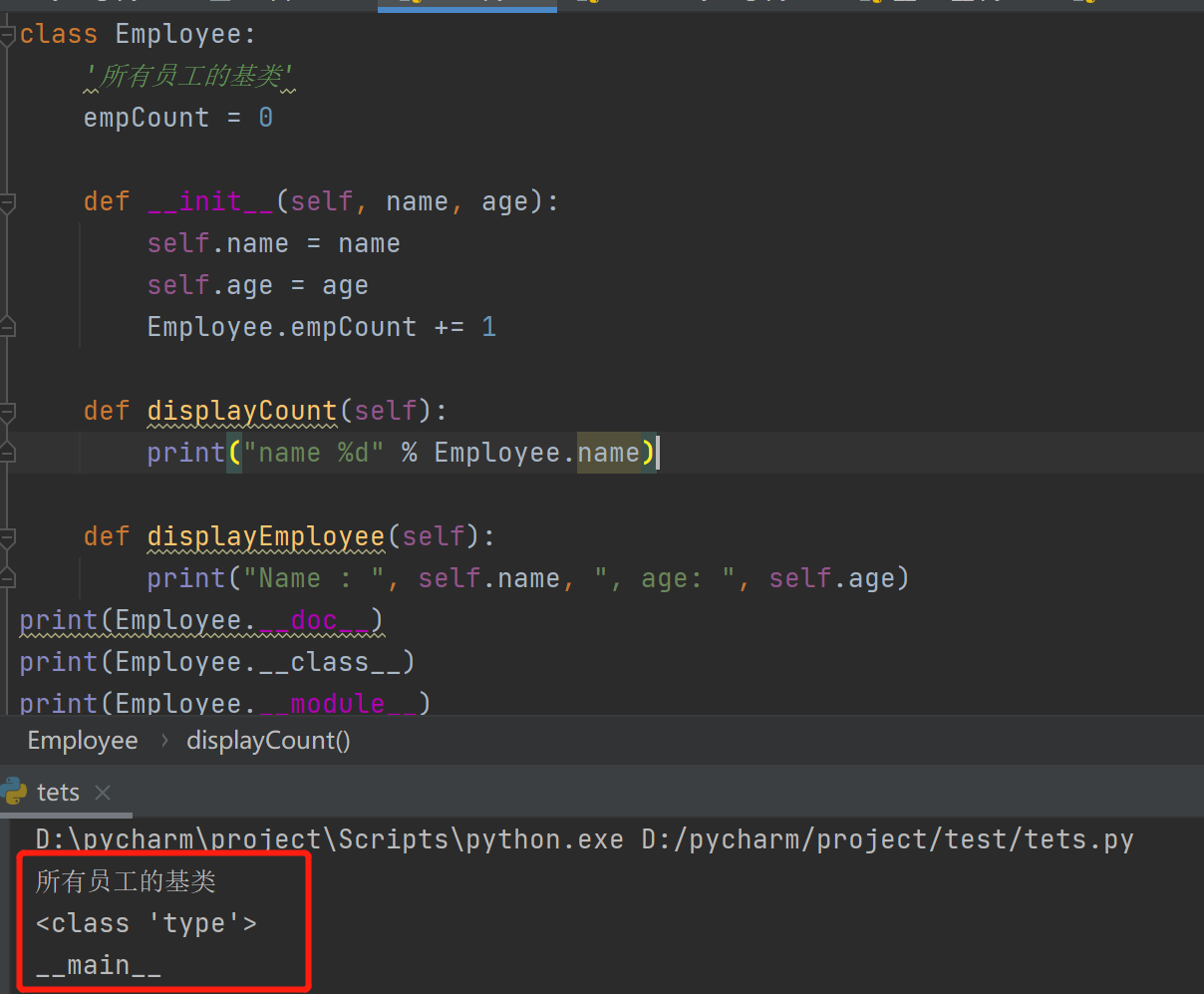
class Employee:
empCount = 0
def __init__(self, name, age):
self.name = name
self.age = age
Employee.empCount += 1
def displayCount(self):
print("name %d" % Employee.name)
def displayEmployee(self):
print("Name : ", self.name, ", age: ", self.age)
e = Employee('zhangsan',18)
e.displayEmployee()
print(e.empCount)
可以添加、删除、修改类的属性
e.name='李四'
e.age=99
del e.age
还可以使用一下函数的方式来访问属性
hasattr(emp1, 'age') # 如果存在 'age' 属性返回 True。
getattr(emp1, 'age') # 返回 'age' 属性的值
setattr(emp1, 'age', 8) # 添加属性 'age' 值为 8
delattr(emp1, 'age') # 删除属性 'age'
Python内置类属性
- dict_ : 类的属性(包含一个字典,由类的数据属性组成)
- doc :类的文档字符串
- name: 类名
- module: 类定义所在的模块(类的全名是'main.className',如果类位于一个导入模块mymod中,那么className.module 等于 mymod)
- bases : 类的所有父类构成元素(包含了一个由所有父类组成的元组)
python对象销毁(垃圾回收)
引用计数器 :通过记录所有使用的对象各有多少引用,当某个对象引用数为0时,回收
循环引用
两个对象相互引用,但是没有其他变量引用
析构函数 del ,__del__在对象销毁的时候被调用,当对象不再被使用时,__del__方法运行
class Employee:
'所有员工的基类'
empCount = 0
def __init__(self, name, age):
self.name = name
self.age = age
Employee.empCount += 1
def displayEmployee(self):
print("Name : ", self.name, ", age: ", self.age)
def __del__(self):
claName=self.__class__.__name__
print('销毁对象',claName)
e = Employee('张三',19)
print(e.displayEmployee())
输出
Name : 张三 , age: 19
None
销毁对象 Employee
类的继承
通过继承创建的新类称为子类或派生类,被继承的类称为基类、父类或超类。
class Father
class Son(Father)
多继承
class A: # 定义类 A
.....
class B: # 定义类 B
.....
class C(A, B): # 继承类 A 和 B
重写父类的方法
lass Parent: # 定义父类
def myMethod(self):
print '调用父类方法'
class Child(Parent): # 定义子类
def myMethod(self):
print '调用子类方法'
c = Child() # 子类实例
c.myMethod() # 子类调用重写方法
基础重载方法
下表列出了一些通用的功能,你可以在自己的类重写:
| 序号 | 方法, 描述 & 简单的调用 |
|---|---|
| 1 | init ( self [,args...] ) 构造函数 简单的调用方法: obj = className(args) |
| 2 | del( self ) 析构方法, 删除一个对象 简单的调用方法 : del obj |
| 3 | repr( self ) 转化为供解释器读取的形式 简单的调用方法 : repr(obj) |
| 4 | str( self ) 用于将值转化为适于人阅读的形式 简单的调用方法 : str(obj) |
| 5 | cmp ( self, x ) 对象比较 简单的调用方法 : cmp(obj, x) |
类属性与方法
类的私有属性
__private_attrs:两个下划线开头,声明该属性为私有,不能在类的外部被使用或直接访问。在类内部的方法中使用时 self.__private_attrs。
类的方法
在类的内部,使用 def 关键字可以为类定义一个方法,与一般函数定义不同,类方法必须包含参数 self,且为第一个参数
类的私有方法
__private_method:两个下划线开头,声明该方法为私有方法,不能在类的外部调用。在类的内部调用 self.__private_methods
单下划线、双下划线、头尾双下划线说明:
- foo: 定义的是特殊方法,一般是系统定义名字 ,类似 init() 之类的。
- _foo: 以单下划线开头的表示的是 protected 类型的变量,即保护类型只能允许其本身与子类进行访问,不能用于 from module import *
- __foo: 双下划线的表示的是私有类型(private)的变量, 只能是允许这个类本身进行访问了。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)