


1.前提
部署模式
- Local 模式:在本地机器上运行 Spark 应用程序,主要用于开发和测试。
- Standalone 模式:将 Spark 部署到一个独立的集群上,通过启动 Spark Master 和若干个 Spark Worker 节点,来协同执行任务。
- YARN 模式:将 Spark 部署到 Hadoop 集群上,并与 Hadoop 的资源管理器—YARN 进行集成,让 Spark 可以利用 Hadoop 集群中的资源运行任务。
- Mesos 模式:将 Spark 部署到 Mesos 集群上,并与 Mesos 进行集成,让 Spark 可以利用 Mesos 集群中的资源运行任务。
- Kubernetes 模式:将 Spark 部署到 Kubernetes 集群上,并与 Kubernetes 进行集成,让 Spark 可以利用 Kubernetes 集群中的资源运行任务。
环境
使用的环境时Centos7.6,已经安装了jdk1.8、hadoop3.1.1、三台服务区节点master、
slave1、slave2
2.下载安装包
下载地址
- [Spark] https://spark.apache.org/downloads.html https://archive.apache.org/dist/spark/
- [Scala] https://www.scala-lang.org/download/2.12.15.html
版本对应
注意:
- 按照 Hadoop 的版本来选择 Spark 安装包类型。由于这里用的是之前已经安装好的 Hadoop,因此选择的是不带 Hadoop 的 Spark 安装包。
3. Standalone模式
与MapReduce1.0框架类似,Spark框架本身也自带了完整的资源调度管理服务,可以独立部署到一个集群中,而不需要依赖其他系统来为其提供资源管理调度服务。在架构的设计上,Spark与MapReduce1.0完全一致,都是由一个Master和若干个Slave构成,并且以槽(slot)作为资源分配单位。不同的是,Spark中的槽不再像MapReduce1.0那样分为Map 槽和Reduce槽,而是只设计了统一的一种槽提供给各种任务来使用。
安装Scala
spark由scala语言编写,使用需要有scala环境,不论采用哪种方式部署,都需要。
解压安装包
[root@master scala-2.12.17]# pwd
/opt/module/scala-2.12.17
[root@master scala-2.12.17]# ll
total 16
drwxrwxr-x. 2 hadoop hadoop 162 Sep 15 2022 bin
drwxrwxr-x. 4 hadoop hadoop 86 Sep 15 2022 doc
drwxrwxr-x. 2 hadoop hadoop 245 Sep 15 2022 lib
-rw-rw-r--. 1 hadoop hadoop 11357 Sep 15 2022 LICENSE
drwxrwxr-x. 3 hadoop hadoop 18 Sep 15 2022 man
-rw-rw-r--. 1 hadoop hadoop 646 Sep 15 2022 NOTICE
[root@master scala-2.12.17]#
添加环境变量
#scala
export SCALA_HOME=/opt/module/scala-2.12.17
export PATH=$PATH:$SCALA_HOME/bin
刷新环境变量并测试
[root@master scala-2.12.17]# source /etc/profile
[root@master scala-2.12.17]# scala -version
Scala code runner version 2.12.17 -- Copyright 2002-2022, LAMP/EPFL and Lightbend, Inc.
[root@master scala-2.12.17]#
安装Spark
解压安装包
[root@master spark-3.0.1]# pwd
/opt/module/spark-3.0.1
[root@master spark-3.0.1]# ll
total 40
drwxr-xr-x. 2 hadoop hadoop 4096 Nov 25 2020 bin
drwxrwxr-x. 2 hadoop hadoop 257 May 10 17:01 conf
drwxr-xr-x. 5 hadoop hadoop 50 Nov 25 2020 data
drwxrwxr-x. 4 hadoop hadoop 29 Nov 25 2020 examples
drwxrwxr-x. 2 hadoop hadoop 12288 Dec 30 2020 jars
drwxr-xr-x. 2 hadoop hadoop 30 Dec 30 2020 jmx_exporter
drwxrwxr-x. 2 hadoop hadoop 4096 May 10 17:05 logs
drwxr-xr-x. 7 hadoop hadoop 275 Nov 25 2020 python
-rw-r--r--. 1 hadoop hadoop 4488 Nov 25 2020 README.md
-rw-rw-r--. 1 hadoop hadoop 105 Nov 25 2020 RELEASE
drwxr-xr-x. 2 hadoop hadoop 4096 Nov 25 2020 sbin
drwxrwxr-x. 2 hadoop hadoop 6 May 10 16:53 work
drwxrwxr-x. 2 hadoop hadoop 42 Nov 25 2020 yarn
[root@master spark-3.0.1]#
Spark的环境配置
vi /spark-env.sh
export HADOOP_HOME=/opt/module/hadoop-3.1.1 # 指定hadoop安装路径
export JAVA_HOME=/opt/jdk1.8.0_211 # 指定jdk路径
export SCALA_HOME=/opt/module/scala-2.12.17 #指定scala的安装路径
export SPARK_HOME=/opt/module/spark-3.0.1 # 指定 Spark 的安装目录
export JAVA_OPTS="-Xms512m -Xmx1024m" # 指定 Java 程序使用的内存大小
export SPARK_MASTER_IP=master # 指定 Spark Master 节点的 IP 地址
export SPARK_WORKER_MEMORY=1G # 指定每个 Worker 使用的内存大小
export SPARK_EXECUTOR_MEMORY=1G # 指定每个 Executor 使用的内存大小
export SPARK_LOG_DIR=/var/log/spark # 指定 Spark 日志文件的输出目录
export SPARK_DRIVER_MEMORY=1G # 指定 Driver 程序使用的内存大小
export SPARK_MASTER_PORT=7777 # 指定Spark Master 节点的端口号
Spark 的事件日志记录器和历史服务器
生产环境中建议将事件日志文件保存在 HDFS 分布式文件系统中(也可以存在本地,默认路径/tmp/spark-events)
vi /conf/spark-default.conf
spark.ui.port 8080 # Spark 的默认 Web UI 端口,用于提供 Spark Web UI 服务以及监控 Spark 应用的运行情况
spark.eventLog.enabled true # 是否启用事件日志记录器。若需要查看应用程序的事件日志,需将此设置为 true
spark.eventLog.dir hdfs://master:9000/historyserverforSpark # 事件日志记录器将事件日志文件写入到此目录下
spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three" # 通过 GC 日志和系统属性来优化和调试 Spark 应用程序
spark.yarn.historyServer.address master:18080 # Yarn历史服务器地址
spark.history.fs.logDirectory hdfs://master:9000/historyserverforSpark #指定历史服务器从哪个目录读取事件日志文件
hadoop dfs -mkdir /historyserverforSpark创建历史记录目录- 注意,如果集群已经启用了HA模式,那么需要在所有的Spark主节点上启动历史服务器。
Spark节点信息
- 未配置
slaves文件的集群默认会将所有节点都视为 Slave 节点
vi slaves
master
slave1
slave2
分发scala、spark 到多台机器
scp -r /opt/module/spark-3.0.1 slave1:/opt/module/
scp -r /opt/module/spark-3.0.1 slave2:/opt/module/
scp -r /opt/module/scala-2.12.17 slave1:/opt/module
scp -r /opt/module/scala-2.12.17 slave1:/opt/module
scp -r /etc/profile slave1:/etc
scp -r /etc/profile slave2:/etc
启动
-
方式一
/sbin/start-all.sh /sbin/start-history-server.sh -
方式二(分布式执行)
/sbin/start-master.sh # master节点执行 /sbin/start-slave.sh spark://master:8080 # slave节点 8080是webUI端口
测试
WebUi地址
示例
-
./bin/run-example SparkPi./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --conf spark.history.provider=org.apache.spark.deploy.history.yarn.YarnHistoryProvider --conf spark.eventLog.enabled=true --conf spark.eventLog.dir=hdfs://master:9000/historyserverforSpark --conf spark.yarn.historyServer.address=master:19888 --conf spark.history.fs.logDirectory=hdfs://master:9000/historyserverforSpark examples/jars/spark-examples_2.12-3.0.1.jar
4. Standalone-HA模式
方案
Spark Standalone 集群是Master--Slaves架构的集群模式,和大部分的Master--Slaves 结构集群一样,存在着Master单点故障的问题。Spark提供了两种解决方案去解决这个单点故障的问题
-
基于文件系统的单点恢复
主要用于开发或测试环境,spark提供目录保存spark Application 和worker的注册信息,并将他们的恢复状态写入该目录中,这时,一旦Master发生故障,就可以通过重新启动Master进程(sbin/strart--master.sh),恢复已运行的spark Application 和 worker 的注册信息。(简单说就是需要自己亲自再去启动master) -
基于zookeeper的 Standby Masters
主要用于生产模式。其基本原理是通过zookeeper来选举一个Master,其他的Master处于Standby状态。将spark集群连接到同一个zookeeper实例并启动多个Master,利用zookeeper提供的选举和状态保存功能,可以使一个Master被选举成活着的master,而其他Master处于Standby状态。如果现任Master宕机,另一个Master会通过选举产生并恢复到旧的Master状态,然后恢复状态。整个恢复过程可能要1-2分钟
本次采用基于zookeeper的HA部署,安装前保证已经安装好Zookeeper集群
配置信息
export JAVA_HOME=/opt/jdk1.8.0_211
export SCALA_HOME=/opt/module/scala-2.12.17
export HADOOP_HOME=/opt/module/hadoop-3.1.1 # 如果使用hdfs存储历史服务器日志或者需要提交yarn任务
export SPARK_HOME=/opt/module/spark-3.0.1 # Spark 安装目录(YARN 模式下需要进行配置)
export HADOOP_CONF_DIR=/opt/module/hadoop-3.1.1/etc/hadoop # Hadoop 的配置文件路径(YARN 模式下需要进行配置)
export YARN_CONF_DIR=/opt/module/hadoop-3.1.1/etc/hadoop # Hadoop 集群的配置文件路径(YARN 模式下需要进行配置)
export SPARK_DIST_CLASSPATH=$(/opt/module/hadoop-3.1.1/bin/hadoop classpath):$SPARK_DIST_CLASSPATH #不加的话,hive数据插入会报错
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=Master:2181,slave1:2181,slave2:2181 -Dspark.deploy.zookeeper.dir=/spark"
export SPARK_WORKER_MEMORY=2g
export SPARK_EXECUTOR_MEMORY=2g
export SPARK_DRIVER_MEMORY=2g
export SPARK_WORKER_CORES=2
spark.master yarn # 默认使用yarn
spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master:9000/user/applicationHistory
spark.history.fs.logDirectory hdfs://master:9000/user/driverLogs
spark.yarn.historyServer.address master:18080
spark.history.ui.port 18080
对于
spark.history.fs.logDirectory和spark.eventLog.dir这两个配置项来说,它们的 Hadoop 路径需要保持一致,因为它们都指向了 Spark 历史事件日志的存储路径如果配置多个历史服务器,每个节点的配置不一致
在哪台机器提交spark任务,RM 页面点击会进入该节点的历史服务器
启动集群
前提启动了hadoop集群
# master节点执行
./start-master.sh
./start-history-server.sh
# slave1节点
./start-master.sh
测试
Local 模式下执行 Spark 程序
spark-submit --class org.apache.spark.examples.SparkPi \
--master local[2] \
--jars /opt/module/spark-3.0.1/examples/jars/spark-examples_2.12-3.0.1.jar \
100
参数含义解析
--master:master 的地址,表示提交任务到哪里执行,如local[2]为提交到本地执行,spark://host:port为提交到 Spark 集群执行,yarn为提交到 YARN 集群执行(local后的数字表示用本地多少个线程来模拟集群运行,设置为*表示使用本地所有线程数量)--class:应用程序的主类,仅针对 Java 或 Scala 应用--jars:执行的 jar 包,多个的时候用逗号分隔,这些传入的 jar 包将包含在 Driver 和 Executor 的 classpath 下1000:SparkPi 类中可传入的参数,数字越大,结果越准
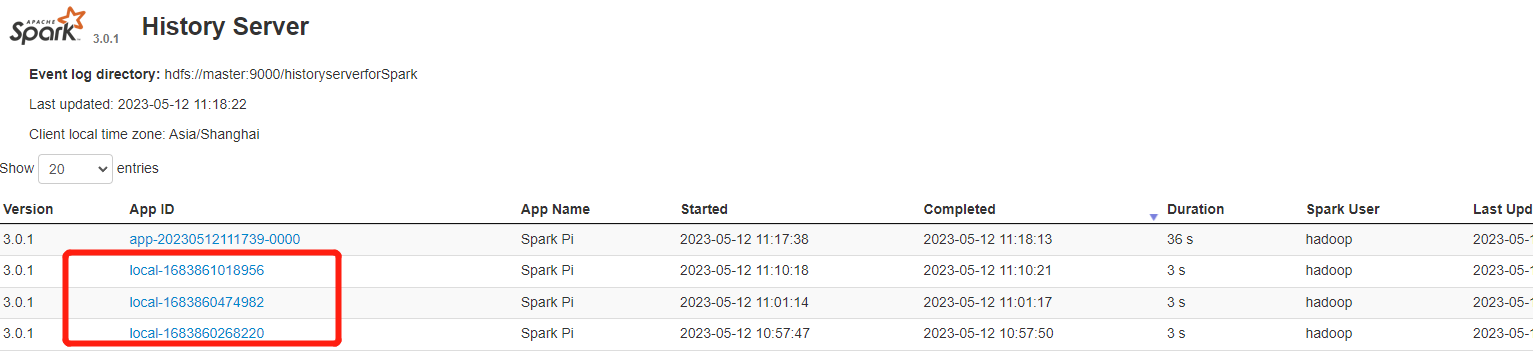
Standalone 模式下执行 Spark 程序
spark-submit --class org.apache.spark.examples.SparkPi \
--master spark://master:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
--jars /opt/module/spark-3.0.1/examples/jars/spark-examples_2.12-3.0.1.jar \
1000
参数含义解析:
--executor-memory:每个 Executor 使用的内存大小上限,默认为 1g--total-executor-cores:所有 Executors 使用的 CPU 总 Cores 数上限,仅在 Standalone 或 Mesos 模式下适用

YARN 模式下执行 Spark 程序
在 Spark on YARN 模式下,您只需要先将 Spark Application 提交到 YARN ResourceManager 进行管理,由 YARN ResourceManager 在集群中分配所需的计算资源,然后启动 Spark Driver,Spark Driver 在 YARN 的某个节点上运行,协调所有 Executor 的任务执行。当 Executor 成功启动后,它们会向 Spark Driver 注册并等待分配任务。
Spark客户端直接连接Yarn,不需要额外构建Spark集群。有yarn-client和yarn-cluster两种模式,主要区别在于:Driver程序的运行节点。
yarn-client:Driver程序运行在客户端,适用于交互、调试,希望立即看到app的输出。
yarn-cluster:Driver程序运行在由RM(ResourceManager)启动的AP(APPMaster)适用于生产环境。
在 master 节点上执行以下命令停止 Spark 集群
$SPARK_HOME/sbin/stop-all.sh
$SPARK_HOME/sbin/stop-history-server.sh
再到 slave1 节点上执行以下命令停止 Master 服务:
$SPARK_HOME/sbin/stop-master.sh
修改Yarn配置文件,并重启Yarn
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
<discription>是否检测任务使用的物理内存,超出将其停掉</discription>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<discription>是否检测任务使用的虚拟内存,超出将其停掉</discription>
</property>
提交任务
spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --driver-memory 2G --executor-memory 2G --num-executors 10 ../examples/jars/spark-examples_2.12-3.0.1.jar
查看,访问Yarn resourcemanager 页面
http://192.168.2.44:8088/cluster
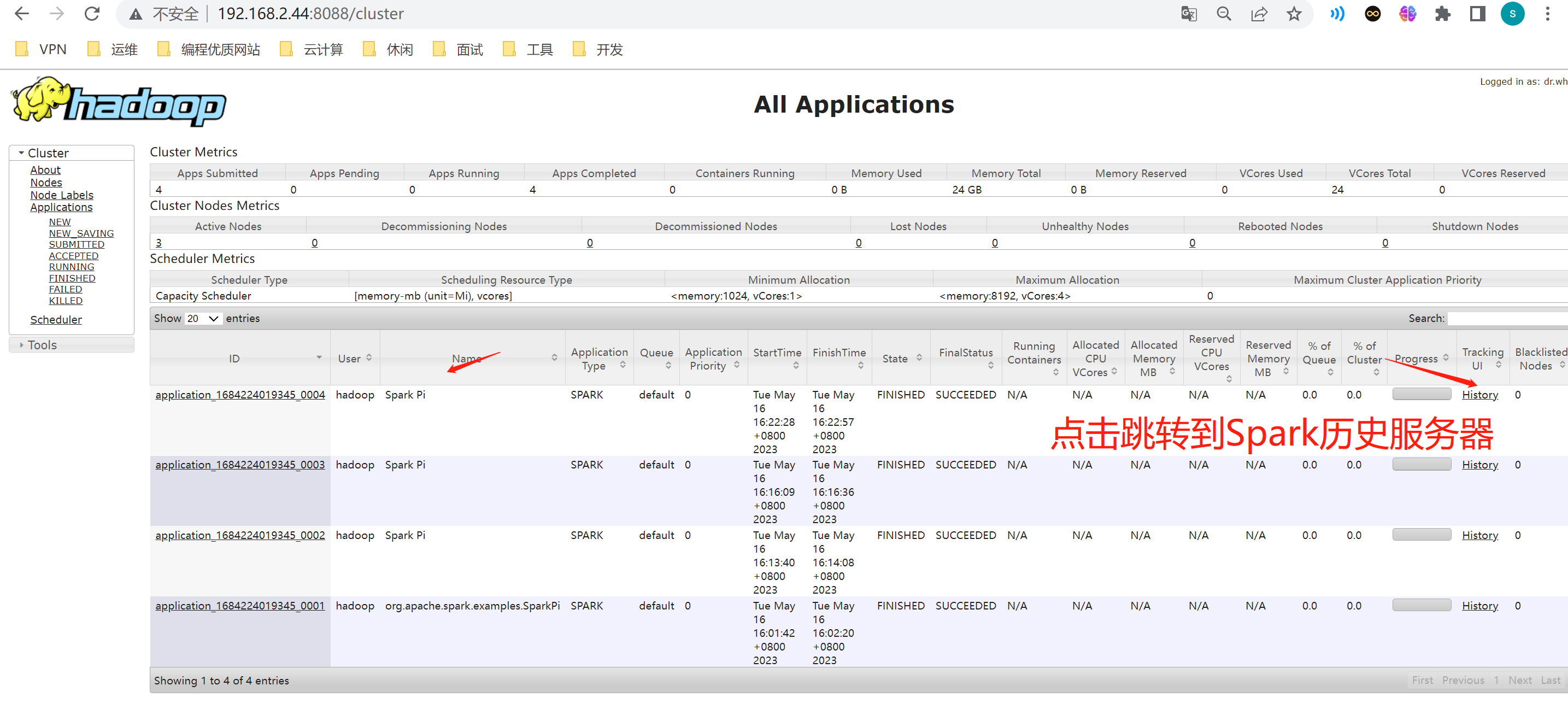
5.Spark on Hive
编译
版本
- Hive3.1.2(需要编译)
- Spark3.0.1
- Scala 2.12.10
修改pom
<guava.version>19.0</guava.version> # 对应hadoop中版本
<spark.version>3.0.1</spark.version>
<scala.binary.version>2.12</scala.binary.version>
<scala.version>2.12.10</scala.version> # 下载的spark-3.0.1-bin-without-hadoop.tgz jars下可以看到版本

编译成功
HIVE相关配置
修改hive-site.xml
https://www.yuque.com/g/nimingzhe-yilmq/dl7558/hc42gfsb7t7ay77u/collaborator/join?token=iArwM8SnsHpDJPs5# 《hive on spark》
vi hive-site.xml
<!--Spark依赖位置,若配置的是HA,value:hdfs://mycluster/spark-jars/*-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://hadoop102:8020/spark-jars/*</value>
</property>
<!--Hive执行引擎-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
<!--Hive和spark连接超时时间-->
<property>
<name>hive.spark.client.connect.timeout</name>
<value>100000ms</value>
</property>
上传spark jar包到Hdfs
由于Spark3.0.1非纯净版默认支持的是hive2.3.7版本,直接使用会和安装的Hive3.1.2出现兼容性问题。所以采用Spark纯净版jar包,不包含hadoop和hive相关依赖,避免冲突
wget https://archive.apache.org/dist/spark/spark-3.0.1/spark-3.0.1-bin-without-hadoop.tgz
tar -zxvf spark-3.0.1-bin-without-hadoop.tgz
hadoop fs -mkdir /spark/spark-jars
hadoop fs -put spark-3.0.0-bin-without-hadoop/jars/* /spark/spark-jars
测试
进入hive终端
# 创建表
create table student(id bigint, name string);
# 插入一条数据
insert into table student values(1,'along');
查看执行结果
hive> insert into table student values(1,'along');
Query ID = hadoop_20230518170821_aee0d8e4-852b-4ede-ab69-4531002d10a1
Total jobs = 1
Launching Job 1 out of 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Running with YARN Application = application_1684287933944_0018
Kill Command = /opt/module/hadoop-3.1.1/bin/yarn application -kill application_1684287933944_0018
Hive on Spark Session Web UI URL: http://slave1:39800
Query Hive on Spark job[0] stages: [0, 1]
Spark job[0] status = RUNNING
--------------------------------------------------------------------------------------
STAGES ATTEMPT STATUS TOTAL COMPLETED RUNNING PENDING FAILED
--------------------------------------------------------------------------------------
Stage-0 ........ 0 FINISHED 1 1 0 0 0
Stage-1 ........ 0 FINISHED 1 1 0 0 0
--------------------------------------------------------------------------------------
STAGES: 02/02 [==========================>>] 100% ELAPSED TIME: 7.10 s
--------------------------------------------------------------------------------------
Spark job[0] finished successfully in 7.10 second(s)
Loading data to table default.student
OK
Time taken: 27.269 seconds
如果报hdfs /目录hive权限不足
hdfs dfs -mkdir -p /user/spark
hdfs dfs -chown hive /user/spark
重试即可
配置优化
Excutor配置说明
- Executor CPU核数配置
单个Executor的CPU核数,由spark.executor..cores参数决定,建议配置为4-6,具体配置为多少,视具体情况而定,原则是尽量充分利用资源。此处单个节点共有l6个核可供Executor使用,则spark.executor.core配置为4最合适。原因是,若配置为5,则单个节点只能启动3个Executor,会剩余1个核未使用;若配置为6,则只能启动2个Executor,会剩余4个核未使用。
- Executor内存配置
Spark在Yarn模式下的Excutor内存模型如下:

Executor相关的参数有:spark.executor.memory和 spark.executor.memoryOverhead。spark.executor.memory用于指定Executor进程的堆内存大小,这部分内存用于任务的计算和存储;spark.executor.memoryOverhead用于指定Executor进程的堆外内存,这部分内存用于JVM的额外开销,操作系统开销等。两者的和才算一个Executor进程所需的总内存大小。默认情况下 spark.executor.memoryOverhead的值等于spark.executor.memory*0.1
-
Excutor个数配置
一个Spark应用的Excutor个数的指定方式有两种。静态配置和动态分配。
-
静态分配
可通过spark.executor.instances指定一个Spark应用启动的Executor个数。这种方式需要自行估计每个Spark应用所需的资源,并为每个应用单独配置Executor个数。
-
动态分配
动态分配可根据一个Spark应用的工作负载,动态的调整其所占用的资源(Executor个数)。这意味着一个Spark应用程序可以在运行的过程中,需要时,申请更多的资源(启动更多的Executor),不用时,便将其释放。在生产集群中,推荐使用动态分配。动态分配相关参数如下:
#启动动态分配 spark.dynamicAllocation.enabled true #启用Spark shuffle服务 spark.shuffle.service.enabled true #Executor个数初始值 spark.dynamicAllocation.initialExecutors 1 #Executor 个数最小值 spark.dynamicAllocation.minExecutors 1 #Executor个数最大值 12spark.dynamicAllocation.maxExecutors 12 #Executor 空闲时长,若某Executor 空闲时间超过此值,则会被关闭 spark.dynamicAllocation.executorIdleTimeout 60s #积压任务等待时长,若有 Task 等待时间超过此值,则申请启动新的Executor 60s spark.dynamicAllocation.schedulerBacklogTimeout 1s
Driver配置说明
Driver主要配置内存即可,相关的参数有spark.driver.memory和 spark.driver.memoryOverhead
-
spark.driver..memory 用于指定Driver进程的堆内存大小
-
spark.driver..memoryOverhead 用于指定Driver进程的堆外内存大小
默认情况下,两者的关系r如下spark.driver..memoryOverhead = spark.driver.memory*0.l 两者的和才算个Driver进程所需的总内存大小。

开启动态分配
vi spark-defaults.conf
增加如下配置
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://myNameService1/spark-history
spark.executor.cores 4
spark.executor.memory 14g
spark.executor.memoryOverhead 2g
spark.driver.memory 10g
spark.driver.memoryOverhead 2g
spark.dynamicAllocation.enabled true
spark.shuffle.service.enabled true
spark.dynamicAllocation.executorIdleTimeout 60s
spark.dynamicAllocation.initialExecutors 1
spark.dynamicAllocation.minExecutors 1
spark.dynamicAllocation.maxExecutors 12
spark.dynamicAllocation.schedulerBacklogTimeout 1s
上传spark-3.0.1-yarn-shuffle.jar到/srv/dstore/1.0.0.0/hdfs/share/hadoop/yarn
scp spark-3.0.1-yarn-shuffle.jar /srv/dstore/1.0.0.0/hdfs/share/hadoop/yarn
修改yarn配置信息
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle,spark_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.spark_shuffle.class</name>
<value>org.apache.spark.network.yarn.YarnShuffleService</value>
</property>
重启yarn测试即可
参考
https://blog.51cto.com/u_15321293/3255709
https://blog.csdn.net/frdevolcqzyxynjds/article/details/126049916
https://blog.csdn.net/zheng911209/article/details/108113490


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· AI与.NET技术实操系列(六):基于图像分类模型对图像进行分类