
Flink-On-Yarn部署
Flink On Yarn集群部署
1.集群配置
安装Yarn-Flink前置环境需要hadoop集群,至少三台,组件布局如下:
| 组件 | master |
slave1 |
slave2 |
|---|---|---|---|
IP |
192.168.2.21 |
192.168.2.22 |
192.168.2.23 |
HDFS 3.1.1 |
NameNode DataNode |
DataNode |
Secondary NameNode DataNode |
YARN |
NodeManager |
ResourceManager NodeManager |
NodeManager |
Flink-1.13.2 |
JobManager |
TaskManager |
TaskManager |
1.1 安装路径示例
cd /opt/module/hadoop-3.1.1
cd /opt/module/flink-1.13.2
2. 集群启动
注意: 配置完不要忘记分发
2.1 启动Hadoop集群
主节点的执行目录下执行如下命令启动集群
./start-dfs.sh
./start-yarn.sh
2.2 查看进程
执行命令Jps查看集群环境是否正常启动
[hadoop@master ~]$ jps
5190 Jps
5062 NodeManager
4408 NameNode
4589 DataNode
[hadoop@slave1 ~]$ jps
5425 Jps
4680 ResourceManager
5241 NodeManager
4447 DataNode
[hadoop@slave2 ~]$ jps
4731 NodeManager
4333 DataNode
4861 Jps
4478 SecondaryNameNode
3.安装配置(非HA)
3.1 解压安装包
mkdir -p /opt/module
tar -zxvf flink-1.13.2-bin-scala_2.11.tgz
chown -R hadoop:hadoop flink-1.13.2
3.2 配置环境变量
vi /etc/profile
# flink
export FLINK_HOME=/opt/module/flink-1.13.2
export PATH=$PATH:$FLINK_HOME/bin
#hadoop
#保证设置了环境变量 HADOOP_CLASSPATH
HADOOP_HOME=/opt/module/hadoop-3.1.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_CLASSPATH=`hadoop classpath`
3.3 刷新
刷新系统变量环境
source /etc/profile
查看是否配置成功
$FLINK_HOME
3.4 配置用户目录下的环境变量
vi ~/.bashrc
#内容与 profile 中保持一致即可,包括java,hadoop,flink等环境变量
3.5 刷新变量
source ~/.bashrc
3.6 修改配置(flink-conf.yaml)
jobmanager.rpc.address: master #主节点主机名
taskmanager.numberOfTaskSlots: 4
parallelism.default: 4
jobmanager.memory.process.size: 1600m
taskmanager.memory.process.size: 1728m
# 设置检查点
state.backend: filesystem
state.backend.fs.checkpointdir: hdfs://master:9000/flink-checkpoints
state.savepoints.dir: hdfs://master:9000/flink-savepoints
jobmanager.execution.failover-strategy: region
# 开启history
jobmanager.archive.fs.dir: hdfs:///master:9000/flink_completed_jobs
historyserver.web.address: master
historyserver.web.port: 8082
historyserver.archive.fs.dir: hdfs:///master:9000/flink_completed_jobs
historyserver.archive.fs.refresh-interval: 10000
3.7 修改master
master:8081 # jobmanager
3.8 修改work
slave1 # taskmanager
slave2 # taskmanager
3.9 分发
scp -r /opt/module/flink-1.13.2 slave1:/opt/module
scp -r /opt/module/flink-1.13.2 slave2:/opt/module
4.集群启动
4.1 启动集群(master)
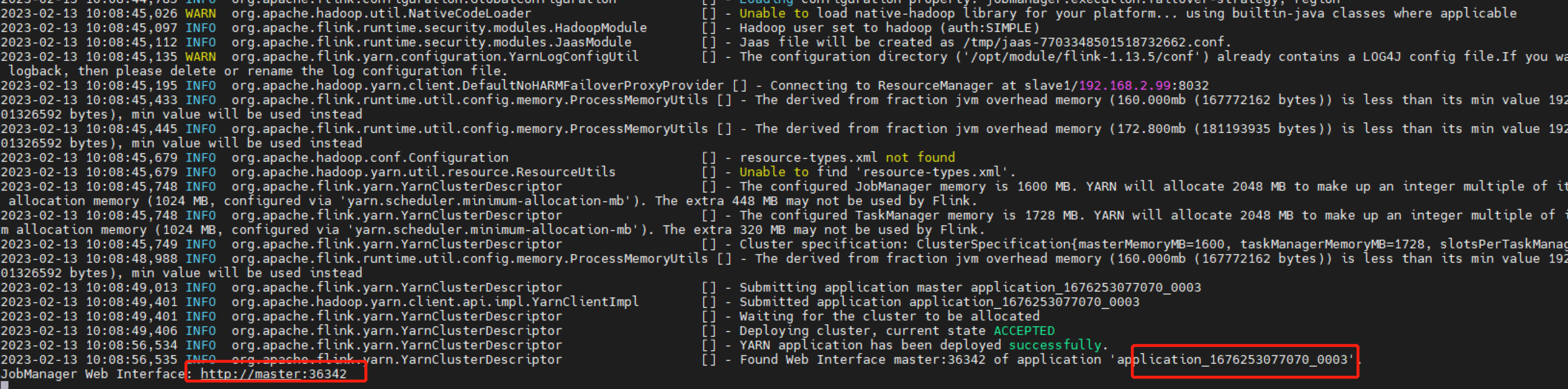
执行脚本命令向 YARN 集群申请资源,开启一个 YARN 会话,启动 Flink 集群
su hadoop
cd /opt/module/flink-1.13.2
bin/yarn-session.sh -nm test -d
YARN Session 启动之后会给出一个 web UI 地址以及一个 YARN application ID,如下所示,
用户可以通过 web UI 或者命令行两种方式提交作业。
4.1 命令行提交测试
① 将打包好的任务运行 JAR 包上传至集群
② 执行以下命令将该任务提交到已经开启的 Yarn-Session 中运行。
$ bin/flink run -c com.atguigu.wc.StreamWordCount FlinkTutorial-1.0-SNAPSHOT.jar

4.2 webUi提交测试
JobManager 的地址,JobManager 的地址在 YARN Session 的启动页面中可以找到。
任务提交成功后,可在 YARN 的 Web UI 界面查看运行情况。

④通过 Flink 的 Web UI 页面查看提交任务的运行情况

4.2 启动History(master)
启动之前创建dfs目录
hdfs dfs -mkdir hdfs://master:9000/flink_completed_jobs
/bin/historyserver.sh start


 浙公网安备 33010602011771号
浙公网安备 33010602011771号