


docker容器间跨宿主机通信-基于overlay
overlay网络解析
内置跨主机的网络通信一直是Docker备受期待的功能,在1.9版本之前,社区中就已经有许多第三方的工具或方法尝试解决这个问题,例如Macvlan、Pipework、Flannel、Weave等。
虽然这些方案在实现细节上存在很多差异,但其思路无非分为两种: 二层VLAN网络和Overlay网络
简单来说,二层VLAN网络解决跨主机通信的思路是把原先的网络架构改造为互通的大二层网络,通过特定网络设备直接路由,实现容器点到点的之间通信。这种方案在传输效率上比Overlay网络占优,然而它也存在一些固有的问题。
这种方法需要二层网络设备支持,通用性和灵活性不如后者。
由于通常交换机可用的VLAN数量都在4000个左右,这会对容器集群规模造成限制,远远不能满足公有云或大型私有云的部署需求; 大型数据中心部署VLAN,会导致任何一个VLAN的广播数据会在整个数据中心内泛滥,大量消耗网络带宽,带来维护的困难。
相比之下,Overlay网络是指在不改变现有网络基础设施的前提下,通过某种约定通信协议,把二层报文封装在IP报文之上的新的数据格式。这样不但能够充分利用成熟的IP路由协议进程数据分发;而且在Overlay技术中采用扩展的隔离标识位数,能够突破VLAN的4000数量限制支持高达16M的用户,并在必要时可将广播流量转化为组播流量,避免广播数据泛滥。
因此,Overlay网络实际上是目前最主流的容器跨节点数据传输和路由方案。
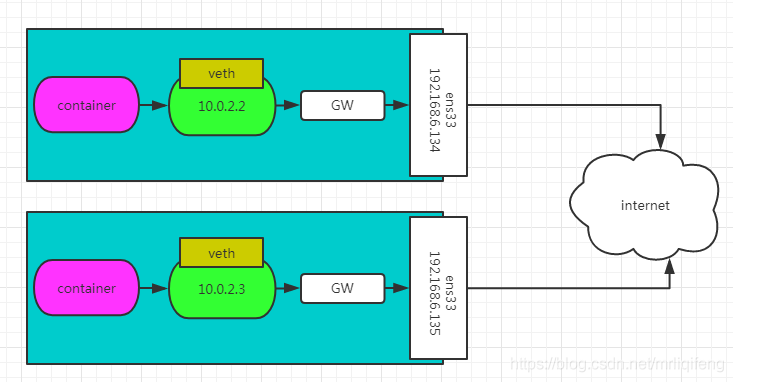
容器在两个跨主机进行通信的时候,是使用overlay network这个网络模式进行通信;如果使用host也可以实现跨主机进行通信,直接使用这个物理的ip地址就可以进行通信。overlay它会虚拟出一个网络比如10.0.2.3这个ip地址。在这个overlay网络模式里面,有类似于服务网关的地址,然后把这个包转发到物理服务器这个地址,最终通过路由和交换,到达另一个服务器的ip地址。
环境介绍
| hostname | ip | 系统版本 |
|---|---|---|
| node1 | 192.168.201.169 | centos7 |
| node2 | 10.30.10.112 | centos7 |
consul安装配置
要实现overlay网络,我们会有一个服务发现。比如说consul,会定义一个ip地址池,比如10.0.2.0/24之类的。上面会有容器,容器的ip地址会从上面去获取。获取完了后,会通过ens33来进行通信,这样就可以实现跨主机的通信。 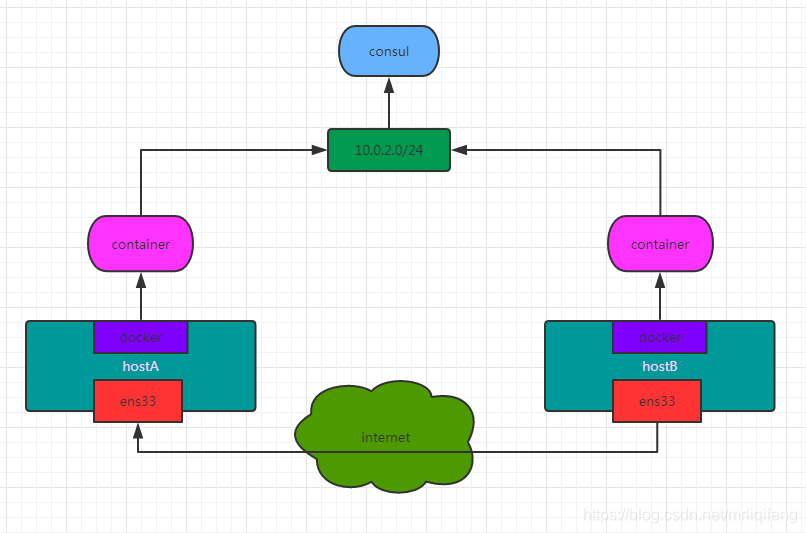
consul通过docker部署在node1,首先需要修改node1中的docker配置并重启
vim /etc/docker/daemon.json
{
"live-restore":true, //添加以下配置
"registry-mirrors": ["https://b9pmyelo.mirror.aliyuncs.com"]
}
“live-restore”:true 此配置的作用为在docker守护程序停止或重启的时候,容器依然可以保持运行
在node1下载consul镜像并启动
[root@node1 /]# docker pull consul
[root@node1 /]# docker run -d -p 8500:8500 -h consul --name consul consul
修改node1中的docker配置并重启
[root@node1 /]# vim /etc/docker/daemon.json
# 添加以下两行配置
"cluster-store": "consul://192.168.201.169:8500"
"cluster-advertise": "192.168.201.169:2375"
[root@node1 /]# systemctl restart docker
修改node2中的docker配置并重启
[root@node2 /]# vim /etc/docker/daemon.json
# 添加以下两行配置
"cluster-store": "consul://192.168.201.169:8500"
"cluster-advertise": "192.168.201.170:2375"
[root@node2 /]# systemctl restart docker
cluster-store指定的是consul服务地址,因为consul服务运行在node1的8500端口,所以两台机器的cluster-store值均为consul://192.168.201.169:8500 cluster-advertise指定本机与consul的通信端口,所以指定为本机的2375端口
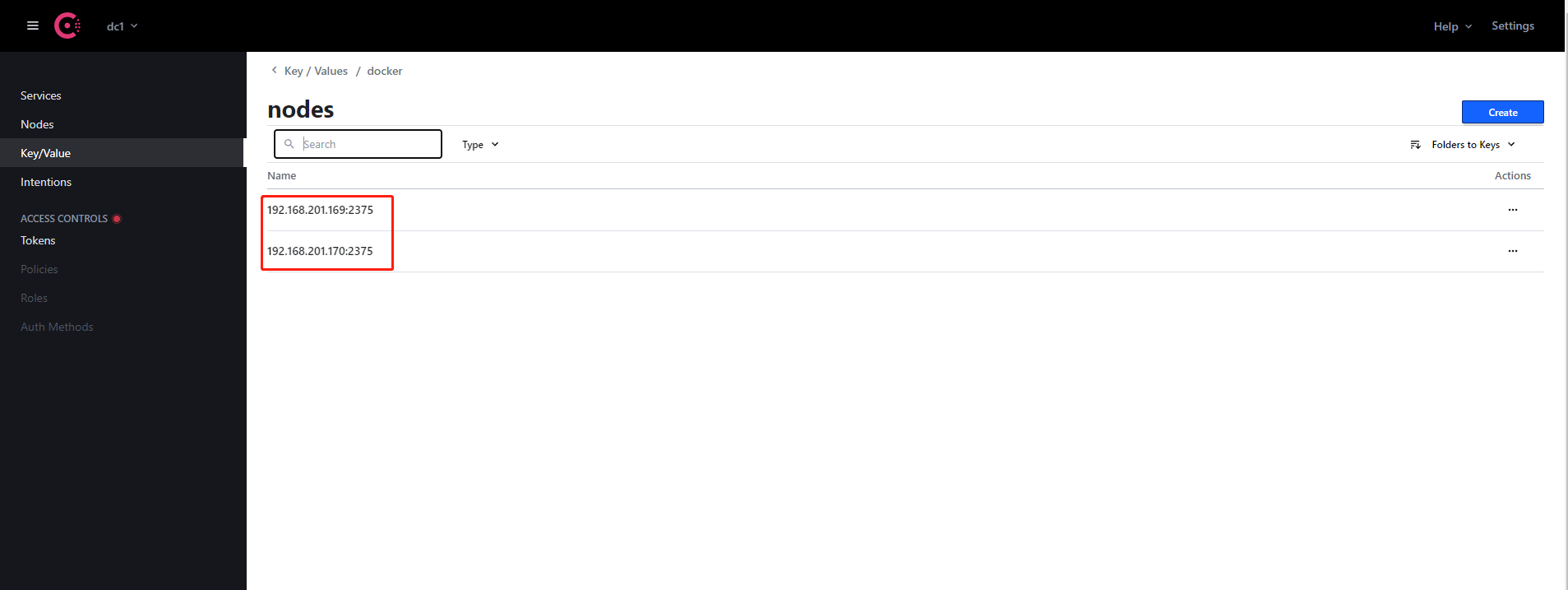
此时可以通过http://192.168.201.169:8500/访问consul地址 在Key/Value菜单中的docker-nodes目录中可以看到node1和node2两个docker节点,代表consul配置成功。
创建overlay网络
此时我们可以创建overlay网络,首先查看目前节点中已有的网络类型
[root@node1 /]# docker network ls
NETWORK ID NAME DRIVER SCOPE
ab0f335423a1 bridge bridge local
b12e70a8c4e3 host host local
0dd357f3ecae none null local
然后在node1的docker节点创建overlay网络,因为此时consul服务发现已经正常运行,且node1和node2的docker服务已经接入,所以此时overlay网络是全局创建的,在任何一台宿主机创建一次即可。
[root@node1 /]# docker network create -d overlay my_overlay
cafa97c5cf9d30dd6cef08a5e9710074c828cea3fdd72edb45315fb4b1bfd84c
[root@node1 /]# docker network ls
NETWORK ID NAME DRIVER SCOPE
ab0f335423a1 bridge bridge local
b12e70a8c4e3 host host local
cafa97c5cf9d my_overlay overlay global
0dd357f3ecae none null local
此时可以看到,创建的overlay网络,标识为golbal。我们可以查看node2的网络,可以发现overlay网络也已经创建完毕。
[root@node2 ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
90d99658ee8f bridge bridge local
19f844200737 host host local
cafa97c5cf9d my_overlay overlay global
3986fe51b271 none null local
网络测试
创建完成后,我们可以在node1和node2中指定overlay网络创建docker容器,并进行测试,查看是否可以跨宿主机通信。
在node1中创建名称为master的容器,并查看其IP
[root@node1 /]# docker run -itd -h master --network=my_overlay centos /bin/bash
[root@node1 /]# docker inspect -f "{{ .NetworkSettings.Networks.my_overlay.IPAddress}}" 983ca199d0a3
10.0.0.2
在node1中创建名称为slaver的容器,并查看其IP
[root@node2 ~]# docker run -itd -h slave --network=my_overlay centos /bin/bash
[root@node2 ~]# docker inspect -f "{{ .NetworkSettings.Networks.my_overlay.IPAddress}}" a2b9586314a0
10.0.0.3
此时进入两台容器中,互相ping对方的IP,查看是否成功通信
[root@node1 ~]# docker exec -it master /bin/bash
[root@master /]# ping 10.0.0.3
PING 10.0.0.3 (10.0.0.3) 56(84) bytes of data.
64 bytes from 10.0.0.3: icmp_seq=1 ttl=64 time=0.587 ms
64 bytes from 10.0.0.3: icmp_seq=2 ttl=64 time=0.511 ms
64 bytes from 10.0.0.3: icmp_seq=3 ttl=64 time=0.431 ms
64 bytes from 10.0.0.3: icmp_seq=4 ttl=64 time=0.551 ms
64 bytes from 10.0.0.3: icmp_seq=5 ttl=64 time=0.424 ms
^C
--- 10.0.0.3 ping statistics ---
5 packets transmitted, 5 received, 0% packet loss, time 4000ms
rtt min/avg/max/mdev = 0.424/0.500/0.587/0.070 ms
[root@node2 ~]# docker exec -it slaver /bin/bash
[root@slaver /]# ping 10.0.0.2
PING 10.0.0.2 (10.0.0.2) 56(84) bytes of data.
64 bytes from 10.0.0.2: icmp_seq=1 ttl=64 time=0.499 ms
64 bytes from 10.0.0.2: icmp_seq=2 ttl=64 time=0.500 ms
64 bytes from 10.0.0.2: icmp_seq=3 ttl=64 time=0.410 ms
64 bytes from 10.0.0.2: icmp_seq=4 ttl=64 time=0.370 ms
^C
--- 10.0.0.2 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3000ms
rtt min/avg/max/mdev = 0.370/0.444/0.500/0.062 ms
成功通信!
查看网络情况
[root@node1 ~]# docker network list
NETWORK ID NAME DRIVER SCOPE
55d1b68c29b9 bridge bridge local
dfb7a6b63df4 docker_gwbridge bridge local
e9672ab90317 host host local
b68a278aa63d my_overlay overlay global
33d7865778dd none null local
[root@node1 ~]#
[root@node2 ~]# docker network list
NETWORK ID NAME DRIVER SCOPE
55d1b68c29b9 bridge bridge local
dfb7a6b63df4 docker_gwbridge bridge local
e9672ab90317 host host local
b68a278aa63d my_overlay overlay global
33d7865778dd none null local
[root@node2 ~]#
node2 上也能看到 my_overlay。这是因为创建 my_overlay 时 node1 将 overlay 网络信息存入了 consul,node2 从 consul 读取到了新网络的数据。之后 my_overlay 的任何变化都会同步到 node1 和 node2。
查看node1的ip
[root@node1 ~]# docker exec 983ca199d0a3 ip r
default via 172.18.0.1 dev eth1
10.0.0.0/24 dev eth0 proto kernel scope link src 10.0.0.2
172.18.0.0/16 dev eth1 proto kernel scope link src 172.18.0.2
[root@node1 ~]#
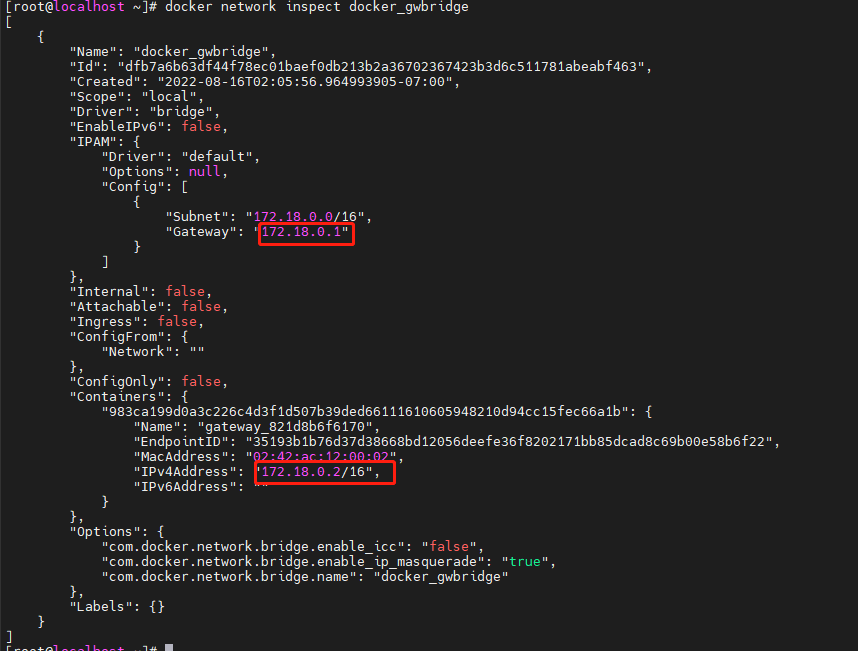
有两个网络接口eth0 和 eth1。eth0 IP为10.0.0.2,连接的是 overlay 网络ov_net1。eth1 IP 172.18.0.2,容器的默认路由是走 eth1,eth1是哪儿来的呢?
其实,docker会创建一个bridge网络 “docker_gwbridge”,为所有连接到 overlay 网络的容器提供访问外网的能力。

从docker network inspect docker_gwbridge输出可确认 docker_gwbridge的 IP 地址范围是 172.18.0.0/16,当前连接的容器就是centos(172.18.0.2)。
而且此网络的网关就是网桥 docker_gwbridge 的IP 172.17.0.1。
原理
docker会为每个overlay网络创建一个独立的network namespace,其中会有一个linux bridge br0,endpoint 还是由veth pair 实现,一端连接到容器中(即 eth0),另一端连接到 namespace的br0上。
br0除了连接所有的 endpoint,还会连接一个 vxlan 设备,用于与其他 host建立 vxlan tunnel。容器之间的数据就是通过这个tunnel通信的。逻辑网络拓扑结构如图所示:
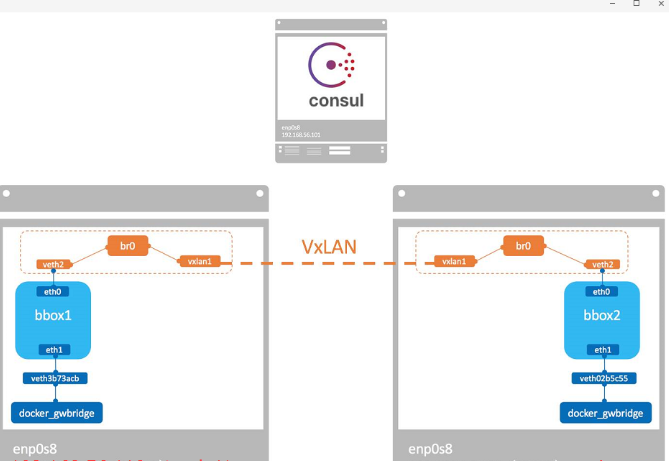
docker默认为 overlay网络分配 24 位掩码的子网(10.0.X.0/24),所有主机共享这个 subnet,容器启动时会顺序从此空间分配 IP。当然我们也可以通过--subnet 指定 IP 空间


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· AI与.NET技术实操系列(六):基于图像分类模型对图像进行分类