

软工实践第二次作业
PSP表格
PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) |实际耗时(分钟)
- | :-: | -:
Planning | 计划 |20 |30
· Estimate | · 估计这个任务需要多少时间 |40 |40
Development | 开发 |200 |300
· Analysis | · 需求分析 (包括学习新技术) |60 |40
· Design Spec | · 生成设计文档 |20 |20
· Design Review | · 设计复审|10 |10
· Coding Standard | · 代码规范 (为目前的开发制定合适的规范) |10 |20
· Design | · 具体设计 |30 |30
· Coding| · 具体编码 |60 |80
· Code Review | · 代码复审 |20 |30
· Test | · 测试(自我测试,修改代码,提交修改) |20 |25
Reporting| 报告 |15 |15
· Test Repor | · 测试报告 |10 |10
· Size Measurement | · 计算工作量 |10 |10
· Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 |10 |5
| | 合计 |525 |665
解题思路
看到题目时,就先回想一下以前C++面向对象的知识,之前的面向对象也有在github和博客园写过,所以印象还比较深,但是真正动起手来打代码,真的是发现很多都忘了,于是查了很多资料和询问了一些acm大佬。
统计字符数和行数直接遍历,判断是否是单词也可以模拟一下,重点在于统计单词的次数和输出词频最多的单词。考虑如何统计单词的次数,很明显可以想到利用map,将单词放入map中++,但考虑到map的复杂度非常大,所以用map来统计单词次数不太好,就用了字典树,因为hash不知道开多大,题目并没有说单词数有多少,所以开大开小都有很多缺陷。考虑要记录词频最多的10个单词,可以利用堆来存储,我使用stl的SET加pair来处理,因为SET是一个可以自动排序的容器,插入删除查询时间复杂度都比较低,根据题目要求要排序两个东西,一个是单词词频,还有一个是字符串的字典序,可以将这两个东西放到pair当中,再将pair放入SET中,而SET里我们只需要放10个数据,多的删除即可。
设计实现过程
最初代码
#include "pch.h"
#include <iostream>
#include<cstdio>
#include<cstring>
#include<string>
#include<utility>
#include<set>
#include<map>
#pragma warning(disable:4996)
using namespace std;
const int N = 100007;
#define de(x) cout<<#x<<" = "<<x<<endl
#define rep(i,a,b) for(int i=(a);i<(b);++i)
struct node {
node *next[36];
int gs;
}root;
string line[N];
int num_line,eft_num,eft_char,eft_word;//num_line 为文件总行数 eft_num为有效行数 eft_char为字符数 eft_word为有效单词数
int Atoatoint(char c) { //将大写字符转化为小写字母,在hash到0~25,以及将0~9hash到26~35.
if (c >= 'A'&&c <= 'Z')c += 'A' - 'a';
if(c>='a'&&c<='z') return c-'a';
else return c-'0'+26;
}
char FAtoatoint(int c) { //是上个函数的反函数
if (c >= 0 && c <= 25)return 'a' + c;
else return c-26+'0';
}
void qinsert(string s) { //字典树插入单词
int len = s.size(), tmp;
node *p;
p = &root;
rep(i, 0, len) {
tmp = Atoatoint(s[i]);
if (p->next[tmp]==NULL) {
p->next[tmp] = new node();p->next[tmp]->gs = 0;
}
p = p->next[tmp];
if (i == len - 1) { p->gs++; }
}
}
void MYscanf(char s[]) { // 输入总控制台
freopen(s, "r", stdin);
//freopen("0.in", "r", stdin);
string str;
while ( getline(cin, str) ) {
int len = str.size();
line[num_line++] = str;
if (len == 0)continue;
bool f=0;
rep(i, 0, len) {
if (str[i] != ' ')f = 1;
}
if (f) {eft_num++;}
}
}
int CountChar() {
int ret = 0;
rep(i, 0, num_line) {
int lim = line[i].size();
rep(j, 0, lim) {
if (line[i][j] >= 0 && line[i][j] <= 255)ret++;//统计有效字符
}
ret++;//增加换行符,每行都有,除了最后
}
return ret-1;//最后一行没有换行符,减去之。
}
bool is_efct_char(char c) {
if ((c >= '0'&&c <= '9') || (c >= 'A'&&c <= 'Z') || (c >= 'a'&&c <= 'z'))return true;
return false;
}
int CountWord() {
int ret = 0;
rep(i, 0, num_line) {
bool f = 1;int lim = line[i].size();
rep(j, 0, lim) {
if( is_efct_char(line[i][j]) ){
string str = "";str += line[i][j];
rep(k, j+1, lim) {
if (is_efct_char(line[i][k]))str += line[i][k],j=k;
else { j = k; break; }
}
bool f = 0;;int siz = str.size() - 1;
rep(k, 0, siz) {
if (str[k] >= '0'&&str[k] <= '9' && (str[k + 1]<'0' || str[k + 1]>'9'))f = 1;
}
if (!f) {//判断是否是有效单词
ret++;
qinsert(str);//在字典树中插入这个单词,为计算单词出现次数做准备。字典树节约空间以及为后续统计大幅度缩减时间复杂度
}
}
}
}
return ret;
}
string tmp;
set<pair<int, string> >qur;//利用set排序,单词次数为第一优先级,string字典序为第二优先级
set<pair<int, string> >::iterator it;
void dfs_getword(node u) {
if (u.gs != 0) {
qur.insert(make_pair(-u.gs, tmp));
if (qur.size() > 10) {
it = qur.end();
it--;
qur.erase(it);
}
}
rep(i, 0, 36) {
if (u.next[i] != NULL) {
tmp += FAtoatoint(i);
dfs_getword( *u.next[i] );
tmp.erase(tmp.size() - 1);
}
}
}
void CountMxWord() {
qur.clear();tmp = "";
dfs_getword(root);
}
void MYprint() {
freopen("result.txt", "w", stdout);
cout << "character: " << eft_char << endl;
cout << "words: " << eft_word << endl;
cout << "lines: " << eft_num << endl;
for (it = qur.begin();it != qur.end();it++) {
cout << "<" << it->second << ">: " << -it->first << endl;
}
}
void init() {
root.gs = 0;
}
int main(int argc,char *argv[])
{
init();
MYscanf(argv[1]);
eft_char = CountChar();
eft_word = CountWord();
CountMxWord();
MYprint();
return 0;
}
改进后 头文件把所有功能封装一个大类
#include<string>
#include<utility>
#include<set>
#include<map>
using namespace std;
const int N = 100007;
#pragma warning(disable:4996)
#define de(x) cout<<#x<<" = "<<x<<endl
#define rep(i,a,b) for(int i=(a);i<(b);++i)
class QWE_wordCount {
public:
string line[N];
string tmp;
set<pair<int, string> >qur;//利用set排序,单词次数为第一优先级,string字典序为第二优先级
set<pair<int, string> >::iterator it;
struct node {
node *next[36];
int gs;
}root;
int num_line, eft_num, eft_char, eft_word;//num_line 为文件总行数 eft_num为有效行数 eft_char为字符数 eft_word为有效单词数
int Atoatoint(char c);
char FAtoatoint(int c);
void qinsert(string s);
void MYscanf(char s[]);
int CountChar();
bool is_efct_char(char c);
int CountWord();
void dfs_getword(node u);
void CountMxWord();
void MYprint();
void init();
};
关键功能代码
int QWE_wordCount::Atoatoint(char c) { //将大写字符转化为小写字母,在hash到0~25,以及将0~9hash到26~35.
if (c >= 'A'&&c <= 'Z')c += 'A' - 'a';
if (c >= 'a'&&c <= 'z') return c - 'a';
else return c - '0' + 26;
}
char QWE_wordCount::FAtoatoint(int c) { //是上个函数的反函数
if (c >= 0 && c <= 25)return 'a' + c;
else return c - 26 + '0';
}
void QWE_wordCount::qinsert(string s) { //字典树插入单词
int len = s.size(), tmp;
node *p;
p = &root;
rep(i, 0, len) {
tmp = Atoatoint(s[i]);
if (p->next[tmp] == NULL) {
p->next[tmp] = new node(); p->next[tmp]->gs = 0;
}
p = p->next[tmp];
if (i == len - 1) { p->gs++; }
}
}
void QWE_wordCount::MYscanf(char s[]) { // 输入总控制台
freopen(s, "r", stdin);
//freopen("0.in", "r", stdin);
string str;
while (getline(cin, str)) {
int len = str.size();
line[num_line++] = str;
if (len == 0)continue;
bool f = 0;
rep(i, 0, len) {
if (str[i] != ' ')f = 1;
}
if (f) { eft_num++; }
}
}
int QWE_wordCount::CountChar() {
if (num_line == 0)return 0;
int ret = 0;
rep(i, 0, num_line) {
int lim = line[i].size();
rep(j, 0, lim) {
if (line[i][j] >= 0 && line[i][j] <= 255)ret++;//统计有效字符
}
ret++;//增加换行符,每行都有,除了最后
}
return ret - 1;//最后一行没有换行符,减去之。
}
bool QWE_wordCount::is_efct_char(char c) { //判断是否是属于单词的字符
if ((c >= '0'&&c <= '9') || (c >= 'A'&&c <= 'Z') || (c >= 'a'&&c <= 'z'))return true;
return false;
}
int QWE_wordCount::CountWord() {
int ret = 0;
rep(i, 0, num_line) {
bool f = 1; int lim = line[i].size();
rep(j, 0, lim) {
if (is_efct_char(line[i][j])) {
string str = ""; str += line[i][j];
rep(k, j + 1, lim) {
if (is_efct_char(line[i][k]))str += line[i][k], j = k;
else { j = k; break; }
}
bool f = 0;; int siz = str.size();
if (siz < 4)f = 1;
else {
rep(k, 0, 4) {
if (str[k] >= '0'&&str[k] <= '9')f = 1;
}
}
if (!f&&str.size() >= 4) {//判断是否是有效单词
ret++;
qinsert(str);//在字典树中插入这个单词,为计算单词出现次数做准备。字典树节约空间以及为后续统计大幅度缩减时间复杂度
}
}
}
}
return ret;
单元测试
TEST_METHOD(TestMethod1)
{
A->init();
A->MYscanf("0.in");
A->eft_char = A->CountChar();
Assert::AreEqual(A->eft_char, (int)105);
// 测试字符是否统计正确
}
TEST_METHOD(TestMethod2)
{
A->init();
A->MYscanf("1.in");
Assert::AreEqual(A->eft_num, (int)13);
}
TEST_METHOD(TestMethod3)
{
A->init();
A->MYscanf("2.in");
A->eft_word = A->CountWord();
Assert::AreEqual(A->eft_word, (int)3);
// 测试统计单词数是否正确
}
TEST_METHOD(TestMethod4)
{
A->init();
A->MYscanf("3.in");
A->eft_word = A->CountWord();
A->CountMxWord();
A->it = A->qur.begin();
Assert::AreEqual(-A->it->first, (int)2);
Assert::AreEqual(A->it->second, (string) "qweee");
// 测试第一大词频单词
}
TEST_METHOD(TestMethod5)
{
A->init();
A->MYscanf("4.in");
A->eft_word = A->CountWord();
A->CountMxWord();
A->it = A->qur.begin(); A->it++;
Assert::AreEqual(-A->it->first, (int)1);
Assert::AreEqual(A->it->second, (string) "asdf456");
// 测试第二大词频单词
}
TEST_METHOD(TestMethod6)
{
A->init();
A->MYscanf("5.in");
A->eft_word = A->CountWord();
A->CountMxWord();
A->it = A->qur.begin();
Assert::AreEqual(-A->it->first, (int)4);
Assert::AreEqual(A->it->second, (string) "asdf1");
// 测试词频相同时能否输出字典序最大的那个
}
TEST_METHOD(TestMethod7)
{
A->init();
A->MYscanf("6.in");
A->eft_char = A->CountChar();
Assert::AreEqual(A->eft_char, (int)0);
A->eft_word = A->CountWord();
Assert::AreEqual(A->eft_word, (int)0);
// 传入空文件
}
TEST_METHOD(TestMethod8)
{
A->init();
A->MYscanf("7.in");
A->eft_char = A->CountChar();
Assert::AreEqual(A->eft_char, (int)894787);
A->eft_word = A->CountWord();
Assert::AreEqual(A->eft_word, (int)99814);
// 传入大文件
}
TEST_METHOD(TestMethod9)
{
A->init();
A->MYscanf("8.in");
A->eft_word = A->CountWord();
Assert::AreEqual(A->eft_word, (int)0);
// 测试是否能辨别错误单词
}
TEST_METHOD(TestMethod10)
{
A->init();
A->MYscanf("11.in");
A->eft_char = A->CountChar();
Assert::AreEqual(A->eft_char, (int)1000000);
A->eft_word = A->CountWord();
Assert::AreEqual(A->eft_word, (int)200000);
A->CountMxWord();
A->it = A->qur.begin();
Assert::AreEqual(-A->it->first, (int)2);
Assert::AreEqual(A->it->second, (string) "aaaa");
// 输入一百万个字符,二十万个单词,其中有十万种单词,用于测试性能
}
};
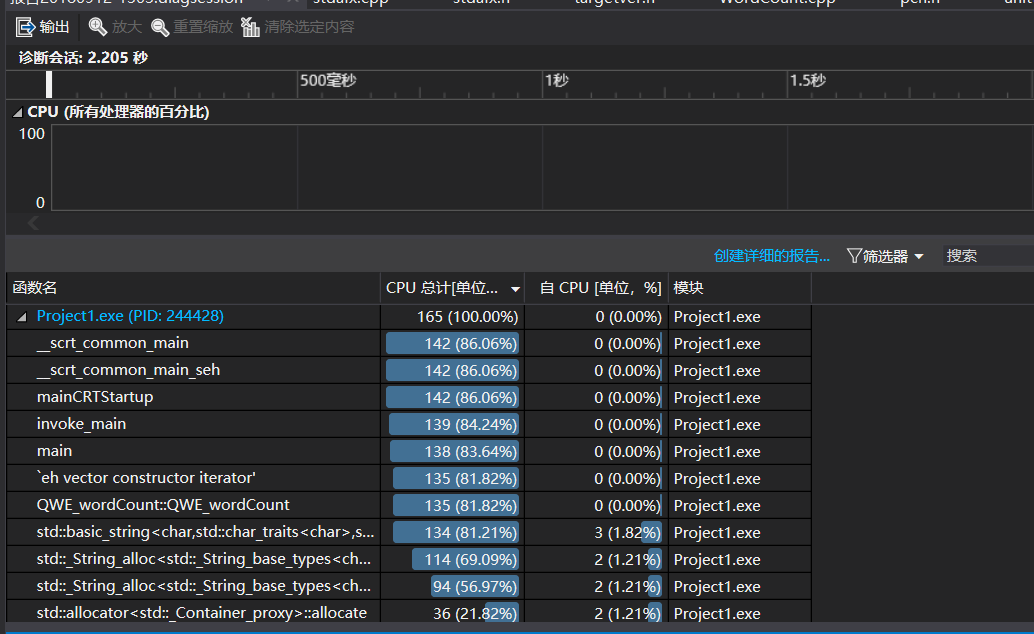
测试结果如下
CPU使用率和代码覆盖率

异常处理
//测试单元
TEST_METHOD(Test4)
{
A->init();
A->MYscanf("6.in");
A->eft_char = A->CountChar();
Assert::AreEqual(A->eft_char, (int)0);
A->eft_word = A->CountWord();
Assert::AreEqual(A->eft_word, (int)0);
// 文件不存在。
}
处理代码:
fp=freopen(s, "r", stdin);
if (fp == NULL) {
cout << "Error:Cannot open the file";
error = 1;
return;
}
感想和收获
之前没有这么完整的做过一个项目,才发现原来一个项目的每个细节都要仔细斟酌,反复推敲,认识到这个行业真的需要认真和勤奋,还有就是自学能力,每天都有新东西在发展,所以要不断学习才能不被淘汰,才能被人需要。坚持每天积累学习也是很重要,不能来了任务才去想起之前忘记的,就会做很多原来没必要做的工作,费时费力。以后要好好努力学习,争取将来能来这个行业做出一些绵薄之力。

