day05-字符串
我们在上篇day04-数据类型中简单介绍了一下字符串,以及字符串的下标,今天我们来详细认识下字符串。
字符串(str)可以使用单引号或双引号来创建字符串,并且字符串是不可变的数据类型,字符串也是Python中最常用的数据类型,所以我们一定学会它,学习字符串一定先熟悉概念,知道是怎么回事,然后多练习
1、创建字符串
字符串可以通过单引号
' ',双引号" ",多引号""" """或''' '''来标识print('Hello World!') print("Hello World!") print("""hello world!""") # 输出结果 Hello World! Hello World! hello world!
那为什么会有单引号和双引号呢?
比如这段话,
我的名字是"xiaohua",使用代码打印输出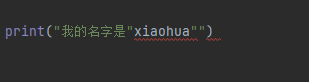
使用两个双引号就会报错,所以我们可以单引号包双引号,或者双引号包着单引号
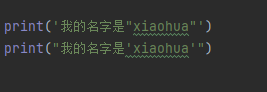
那为什么还会有多引号呢?
来看这段代码
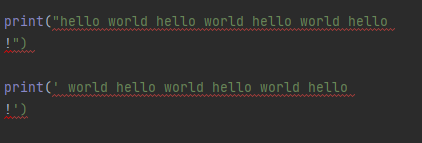
代码出错了,原因就是单引号和双引号的字符串是不支持直接在符号上换行输入的,所以这时候呢,就用到了多引号
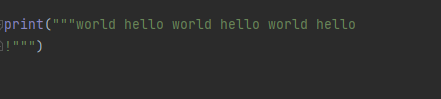
2、拼接字符串
拼接字符串就是把字符串连接起来,这个在上篇中也有讲到,还有没有印象呢?
我们可以使用
+来拼接字符串使用
*来重复字符串# 拼接字符串 name = "John" age = 23 space = " " print(name + space + age) # 输出结果 TypeError: can only concatenate str (not "int") to str
咦?
怎么报错了,报错信息:只能将str拼接,而不能将int拼接
so,使用操作符拼接只能作用在str类型,我们应该怎么修改呢?
str()函数可以将其他数据类型转换为字符串
重新来修改下:
# 拼接字符串 name = "John" age = 23 space = " " print(name + space + str(age)) # 输出结果 John 23
3、字符串切片
字符串切片在上篇中我们也有简单介绍。字符串是一个序列,所以有下标,我们就可以通过下标来获取某个字符
# 字符串切片 str = "Python" # 一共6个字符 print(str[0]) # 取第一个字符 print(str[1]) # 取第二个字符 print(str[5]) # 取第6个字符 print(str[6]) # 取第7个字符 print(str[-1]) # 取倒数第1个元素 print(str[-4]) # 取倒数第4个元素 # 输出结果 P y n IndexError: string index out of range n t
为什么取第7个字符报错了呢,因为字符串命名就只有6个字符,如果取第7个就会报错:索引超出范围
如果是负数的索引,-1就表示倒数第一个元素,-2就表示倒数第二个元素
那如果获取字符串的一段字符,就要用到了切片,切片有语法格式:
str[start : end : step]
- start:闭区间,包含该下标的字符,第一个字符是 0
- end:开区间,不包含该下标的字符(前闭后开)
- step:步长,设为 n,则每隔 n 个元素获取一次
对了,如果我们在切片操作中,如果不指定起始位置,默认为索引0(字符串的开头)。如果不指定终止位置,默认为字符串的长度(字符串的结尾),字符串的长度可以用len(str)来得到
那我们直接看例子吧
my_str = "Hello World" print(my_str[:]) # 取全部字符 print(my_str[0:]) # 取全部字符 print(my_str[:len(my_str)]) # 取全部字符 print(my_str[2:]) # 取第3个字符之后的所有字符 print(my_str[-4:]) # 取倒数第4个字符到结尾的所有字符 print(my_str[1:5]) # 取第2个字符到第4个字符 print(my_str[0:-3]) # 取第1个字符到倒数第3个字符 print(my_str[1:-1]) # 取第2个字符到倒数第2个字符 # 输出结果 Hello World Hello World Hello World llo World orld ello Hello Wo ello Worl
涉及到负数的索引,大家有做错吗?
其实我们可以从中看到规律,我们使用切片取字符不管是负数索引还是正数索引,都是从左到右来进行的。
比如
[1:-1]这个索引,就是字符串的第2个字符也就是e,然后往右进行到倒数第1个字符,由于包前不报后,所以倒数第1个字符不取,也就是取到 l 这个字符,那就是ello Worl那我们在来看点高级的例子
print(my_str[::1]) # 取全部字符 print(my_str[::-1]) # 倒序取所有字符 print(my_str[::2]) # 取所有字符,每两个取一个 print(my_str[1:6:2]) # 取第2个字符到第5个字符,每两个取一个 # 输出结果 Hello World dlroW olleH HloWrd el
[::]表示开头到结尾提取所有字符,[::1]表示开头到结尾提取按照步长为1提取字符。所以两者是同样的的,而我们换成[::-1]就表示了-1(逆序)提取所有字符len函数len()函数用于获取字符串的长度,即字符串中字符的个数。它是Python内置的函数之一
my_str = "Hello World" print(len(my_str)) # 输出结果 11
对于字符串切片我们在做两个小练习:
- 1、有字符串"hello world",提取该字符串的首尾字符组成新字符串,输出打印
- 2、有字符串"hello,python!",如果字符串长度为奇数,则返回中间字符;如果长度为偶数,则返回中间两个字符(可使用判断语句if else)
# 第一题 str = "hello world" print(str[0] + str[-1]) print(str[0] + str[len(str) - 1]) # -1表示最后1个字符, # 还可以使用len函数,长度代表字符个数,而索引是从0开始计算的,所以最后1个元素可以使用字符长度个数-1
注意:str[len(str) - 1]和str[:len(str)]是不同的哦
str[len(str) - 1]返回的是一个字符,而不是字符串。print(str[:len(str)])输出的是完整的字符串。
# 第二题 str = "hello,python" length = len(str) if length % 2 == 0: print(str[length // 2 - 1: length // 2 + 1]) else: print(str[length // 2])
4、字符串常用函数
函数名 |
含义 |
|
len(str)
|
返回字符串的长度(字符的个数)
|
|
str.index(sub)
|
函数用于在字符串中查找子串
sub的第一个匹配位置,并返回其索引值。如果子串未找到,会引发ValueError异常 |
|
str.find(sub)
|
在字符串中查找子串的第一个匹配位置,并返回索引值,如果未找到则返回-1。
|
|
str.count(sub)
|
统计子串在字符串中出现的次数
|
|
str.replace(old, new)
|
将字符串中的指定子串替换为新的子串,返回新字符串
|
|
str.split(sep)
|
使用指定的分隔符将字符串拆分为子字符串列表,返回列表
|
|
str.join(iterable)
|
将可迭代对象中的字符串元素连接为一个字符串。
|
|
str.lower()
|
将字符串转换为小写形式。
|
|
str.upper()
|
将字符串转换为大写形式。
|
|
str.strip()
str.lstrip()
str.rstrip(chars = " ")
|
去除字符串两端的空白字符。
去除字符串头部的空白字符
去除字符串尾部的空白字符
|
|
str.startswith(prefix)
|
检查字符串是否以指定的前缀开头。
|
|
str.endswith(suffix)
|
检查字符串是否以指定的后缀结尾。
|
这个先搞懂每个函数的作用,然后多加练习就可以了
str = 'hello world' # index的用法 print(str.index('o')) # 返回第一次字符'o'的索引 print(str.index('rld')) # 返回'rld'的第一个字符匹配索引 print(str.index('l', 5, 10)) # 返回'l'在5-10 索引之间的第一次匹配索引 print(str.index('g')) # 字符不存在会报错 # 输出结果 4 8 9 ValueError: substring not found ———————————————————————————————————分隔符——————————————————————————————————— # find的用法 print(str.find('o')) print(str.find('rld')) # 返回'rld'的第一个字符匹配索引 print(str.find('l', 5, 10)) # 返回'l'在5-10 索引之间的第一次匹配索引 print(str.find('g')) # 字符不存在返回-1 # 输出结果 4 8 9 -1
find() 和index() 都是用于在字符串中查找子串sub的方法,但是index查找不到的话会报错,而find不会报错,会返回-1。所以我们判断子串是否存在的时候,使用find函数比较好
# count的用法 str = "hello, hello, hello" print(str.count('hello')) # 统计字符串hello出现的次数 print(str.count('hello', 5)) # 统计字符串hello在5之后索引之间的次数 new_str = "hello, hello, Hello" print(new_str.count('hello')) # 统计字符串hello出现的次数,区分大小写 # 输出结果 3 2 2 ———————————————————————————————————分隔符——————————————————————————————————— # replace的用法 str = "hello, hello, hello" print(str.replace("hello", "python")) # 把字符串hello替换为python print(str.replace("hello", "python", 2)) # 把字符串hello替换为python,替换次数为2 # 输出结果 python, python, python python, python, hello
# split的用法 str = "hello" my_str = "hello,world" new_str = "hello,world,python" print(str.split()) # 默认以空格为分隔符进行拆分,返回列表 print(my_str.split(",")) # 指定以逗号进行拆分,返回列表 print(new_str.split(",", 1)) # 指定以逗号进行拆分,返回列表,返回num+1元素 # 输出结果 ['hello'] ['hello', 'world'] ['hello', 'world,python'] # 注意:如果原始字符串不存在分隔符,如果是默认以空格为分隔符来划分,则返回包含整个字符串的列表。 ———————————————————————————————————分隔符——————————————————————————————————— # join的用法 list = ["hello", "world", "python"] tuple = ("hello", "world", "python") new_list = ["hello", "world", 123] print("".join(list)) # 将列表中的元素连接成一个字符串 print("-".join(list)) # 将列表中的元素按照指定字符-连接成一个字符串 print("".join(tuple)) # 将元组中的元素连接成一个字符串 print("".join(new_list)) # 列表中有非字符串元素,会报错 # 输出结果 helloworldpython hello-world-python helloworldpython TypeError: sequence item 2: expected str instance, int found
"".join(lists)是最常见的将列表、元组转成字符串的写法
# lower的用法 ,upper的用法 my_str = "Hello, World!" print(my_str.lower()) # 将字符串全部转换为小写 print(my_str.upper()) # 将字符串全部转换为大写 # 输出结果 hello, world! HELLO, WORLD! ———————————————————————————————————分隔符——————————————————————————————————— my_str = "Hello, World!" print(my_str.startswith("Hello")) # 判断字符串是否以指定字符串'hello'开头 print(my_str.endswith("World!")) # 判断字符串是否以指定字符串'World!'结尾
还有很多函数,我们可以使用dir()函数来查看所有的函数
print(dir(str))5、字符串格式化
格式化需要结合print函数输出,简单意思就是用到
%进行转换,先占个位置,然后把值放在后边替换之前占的位置,可以转换整数、转换浮点数、转换字符串。先了解一下看这篇Python 字符串 | 菜鸟教程中的Python 字符串格式化部分在 Python 中,可以使用字符串格式化来创建具有特定格式的字符串。
Python 提供了几种字符串格式化的方法,其中最常用的是使用百分号(%)和使用字符串的format()方法。
格式化字符串使用的是%s(记住%在前,s在后) ,他就是占位符,然后我们用到%符号进行转换,%后接想使用的实际字符串值
下面是一个%字符串格式化的例子:
print("my name is %s" % "john") # 输出结果 my name is john
多个占位符例子:
name = "小华" age = 25 message = "My name is %s and I am %d years old" % (name, age) print(message) # 输出结果 My name is 小华 and I am 25 years old
使用
%s 和 %d 分别作为字符串和整数的占位符,%后接我们实际填入的值但是在Python3中更新了str.format()方法,这个是怎么使用的呢?在format()方法中,我们使用{}作为占位符
同样,先看个简单format字符串格式化的例子:
print("my name is {}".format("john")) # 输出结果 my name is john
多个占位符例子:
name = "小华" age = 25 message = "My name is {} and I am {} years old.".format(name, age) print(message) # 输出结果 My name is 小华 and I am 25 years old
看着也没什么区别啊,既然Python官方更新了format方法,说明有他的强大之处!
format()其实可以用位置参数和关键字参数
- 位置参数,带数字编号,可调换顺序,即“{1}”、“{2}”
- 带关键字,即“{name}”、“{age}”
下边我们看几个实际例子:
# 不带参数 print("今天是{}的{}岁生日,生日快乐!".format("小华", 18)) # 位置参数 print("今天是{0}的{1}岁生日,生日快乐!".format("小华", 18)) print("今天是{1}的{0}岁生日,生日快乐!".format("小华", 18)) # 关键字参数 print("今天是{name}的{age}岁生日,生日快乐!".format(name="小华", age=18)) print("今天是{name}的{age}岁生日,生日快乐!".format("小华", 18)) # 输出结果 今天是小华的18岁生日,生日快乐! 今天是小华的18岁生日,生日快乐! 今天是18的小华岁生日,生日快乐! 今天是小华的18岁生日,生日快乐! KeyError: 'name'
从中我们知道:
- 当只写了
{}之后,默认按传入的值顺序读取 - 当写了
{0}和{1}的时候,是按数字读取顺序的值,{0}是第一个参数 - 当指定了关键字 {name} ,如果不指定 name=xxx ,则会报错
tips :如果我们想要指定数据类型输出怎么做呢?
print("整数{:d}".format(123)) # 以十进制形式输出 print("浮点数{:f}".format(123.456)) # 以浮点数形式输出 print("字符串{:s}".format("hello")) # 以字符串形式输出 print("百分比{:.2%}".format(0.123456)) # 以百分比形式输出 # 输出结果 整数123 浮点数123.456000 字符串hello 百分比12.35%
day05练习
初级
1.声明一个变量名为
my_str 并初始化值为"We are Family"1) 打印输出字符串
my_str 的值2) 获取字符串
my_str 的长度3) 将字符串
my_str 的值全部转为大写4) 将字符串
my_str 的值全部转为小写5) 查看字符串是否包含指定字符串 'are'(两种方法)
6) 将字符串
my_str中的are字串替换成is7)将字符串
my_str按照空格拆分并输出8)字符串下标为7的字符是什么
9) 字符串最后索引的字符是什么
10)检查字符串是否以子字符'we' 开头
11) 检查字符串是否以子字符'ly' 结尾
2.编写一个程序,接受用户输入的姓名和年龄,并输出类似的句子:"My name is Alice and I am 25 years old."
中级
1.编写一个程序,接受一个字符串,并判断它是否是回文字符串(正着读和倒着读都一样)例如:level
2.有以下字符串
Hello, how are you today?,统计打印输出其中的单词数量3.有子字符串
hello,和字符串hellohellohello,统计子字符串在字符串中出现的次数高级
1.有字符串
Hello, how are you?,将字符串按照单词顺序翻转,如输出:you? are how Hello,2.有如下字符串
Hello, how are you?,将字符串中的空格去除,打印输出3.有如下字符串
hello,统计字符串中每个字符出现的次数,并以字典的形式返回结果
 浙公网安备 33010602011771号
浙公网安备 33010602011771号