PlayWright(十七)- 参数化
今天来讲下参数化,具体是什么意思呢,举个例子
比如我们要测试登录功能,第一步会填写账号,第二步会填写密码,这是一条完整的操作,但是其中会有很多条用例比如账号错误、密码错误、账号为空、密码为空的各种情况,但是在输入账号、密码的操作都是一样的
我们不能一条用例复制很多次,然后再输入不同的情况,所以就用到了我们的参数化,只需要写一个用例操作,然后把全部需要的参数传入用例操作中,只需要不同数据就可以实现不同的情况,所以我们也经常叫这种为数据驱动
1、参数化怎么用
那Pytest使用参数化功能使用的是什么呢?
答:是一个装饰器
@pytest.mark.parametrize(self,argnams,argvalues,indirect=False,ids=None)
分析下参数
- argnams 参数名,是一个字符串,若有多个参数中间用逗号分隔
- argvalue 参数值,是一个列表,列表中有几个元素,便会生成几个用例
- indirect 默认为False,若为True则表示参数名是一个函数
- ids 可以将用例重命名
大概意思就是第一个参数填一个字符串,第二个参数填一个列表,列表里放参数
好,我们还是直接实战。
2、传一个参数
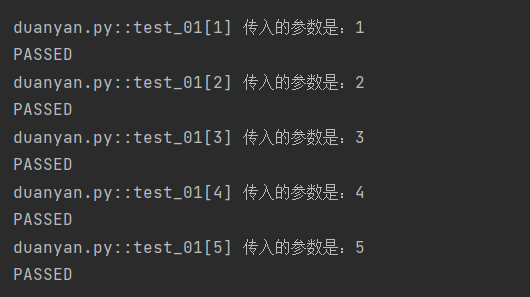
import pytest """ 参数化的使用 """ @pytest.mark.parametrize('num', [1, 2, 3, 4, 5]) def test_01(num): print(f"传入的参数是:{num}")
我们定义函数,这里得主要有参数,所以必须在函数里先传入这个参数,之后才能使用,列表里放我们的参数[1,2,3,4,5],所以结果应该也是分别传入这几个数
运行结果:
2、传多个参数
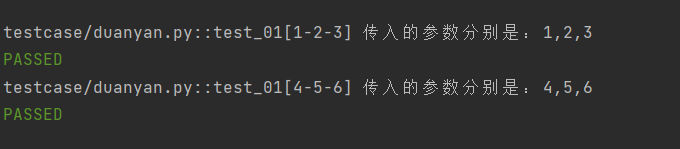
@pytest.mark.parametrize('a,b,c', [(1, 2, 3), (4, 5, 6)]) def test_01(a, b, c): print(f"传入的参数分别是:{a},{b},{c}")
这里我们传入了多个参数,用了列表包着元祖的形式传入参数
运行结果:

那有人会问,列表包着元祖可以,那列表包着字典不能使用吗?我们试一下就知道了
@pytest.mark.parametrize('a,b,c', [{1, 2, 3}, {4, 5, 6}]) def test_01(a, b, c): print(f"传入的参数分别是:{a},{b},{c}")
看结果:
可以看到,是没有问题的,我们之后做数据驱动经常会用到此种数据
3、数据驱动
多个参数也没问题了,那很多很多数据呢,我们在接着放到参数里就会太长了,代码很不优雅,所以我们选用单独文件存储数据,这个文件形式呢?有yaml格式、json格式、excel格式,这些我们都可以用,然后我们选用读取文件数据的方式,然后再放在参数里就可以了
这样代码还更简洁了,如果要更换数据,直接在对应的数据文件里更换数据就可以了
下边直接看例子:
数据放到了JSON文件里
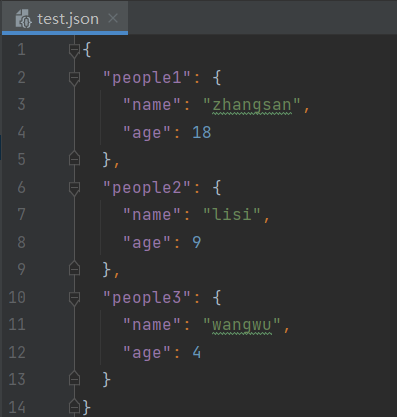
这时候就需要我们读取用例了,这里可以单独写一个函数
json_file = '具体的json文件路径' # 这里我们填写json的绝对路径 def get_data(): """ 封装处理json数据的 """ test_data = [] # 先定义一个数据存储器,读取的数据要往这里填 # 打开文件加载 with open(json_file, encoding="utf-8") as f: # 打开json文件夹 case = json.load(f) # 将JSON字符串转换为字典存放到case中 for case_data in case.values(): # 将数据循环拆开,变成元祖格式在放到我们之前的容器中 test_data.append(tuple(case_data.values())) return test_data
这是我们的数据处理,调用这个函数就返回数据了,我们可以先看结果,数据对不对
执行结果:

好了,我们可以在函数中使用了
import pytest # 导入了处理数据的文件,方便之后调用函数 from tools.get_data import get_data @pytest.mark.parametrize("name,age", get_data()) def test01(name, age): print(f"传入的参数分别是:{name},{age}")
我们直接在第二个参数中放我们的处理数据函数
执行结果:

没有问题,参数化我们基本已经掌握了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号