PlayWright(五)- 元素定位
上文我们已经掌握好怎么启动playwright了,我们就可以开启playwright的正式学习之路了?
首先得认识元素定位,元素定位是最基础也是最重要的,我们连元素都定位不到,怎么做相关的操作呢?
selenium的八大元素定位:
| selenium中各定位方式 | 对应的Python方法 |
| id | find_element_by_id() |
| name | find_element_by_name() |
| class name | find_element_by_class_name() |
| tag name | find_element_by_tag_name() |
| link text | find_element_by_link_text() |
| partial link text | find_element_by_partial_link_text() |
| xpath | find_element_by_xpath() |
| css selector | find_element_by_css_selector() |
但在我们playwright中我们支持xpath,css ,还有一个text文本定位
我们定位元素后,操作用一个点击click()来查看效果
page.click(selector,**kwargs)
selector是选择器,意思就是我们定位到的元素
1、XPath定位
问题:打开百度网页,点击导航-新闻
page.click('xpath=//*[@id="s-top-left"]/a[1]')
playwright更智能化,我们还可以再优化代码只保留表达式
page.click('//*[@id="s-top-left"]/a[1]')
2、CSS定位
可以先看看元素选择器
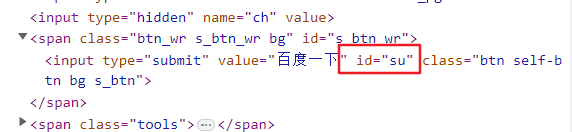
问题:打开百度网页,点击百度一下
page.click('#su')
看看后台再定位:
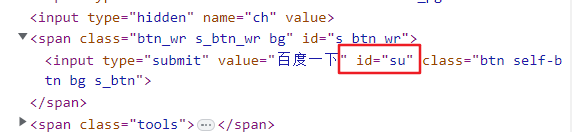
通过后台看到id是su,我们用#su
3、定位器函数locator()
我们可以使用locator()函数来定位到具体的元素
问题:打开百度网页,打印定位到百度一下的元素
print(page.locator('#su'))
看看打印的结果:

说明我们已经定位到了
4、text文本定位
文本定位是非常好用的一个定位方式
问题:打开百度网页,定位导航-新闻
文本定位有两种方式:
第一种:print(page.locator("text=新闻"))
第二种:print(page.locator("text='新闻'"))
第一个没有对新闻加引号,表示模糊匹配,对大小写不敏感
第二个对新闻加了引号,精确匹配,对大小写敏感
作业:打开微博网页,点击热门榜单
看看下边解答和你的一样吗?
page.locator("text='热门榜单'").click()
我们可以简化
page.click("text=热门榜单")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号