Python - 字符串
字符串认识
字符串是 Python 中最常用的数据类型。我们可以使用引号( ' 或 " )来创建字符串。
创建字符串很简单,只要为变量分配一个值即可。例如:
print("hello world") print('hello world') print("""hello world""")
小知识:为什么需要单引号,又需要双引号
因为可以在单引号中包含双引号,或者在双引号中包含单引号
字符串 - 转义符
在字符前加 \ 就行
常见的有
-
\n:换行
-
\t:缩进
-
\r:回车
小知识:\ 只想当普通字符处理
print(r"D:\python\python.txt") # 输出结果 D:\python\python.txt
字符串-运算符
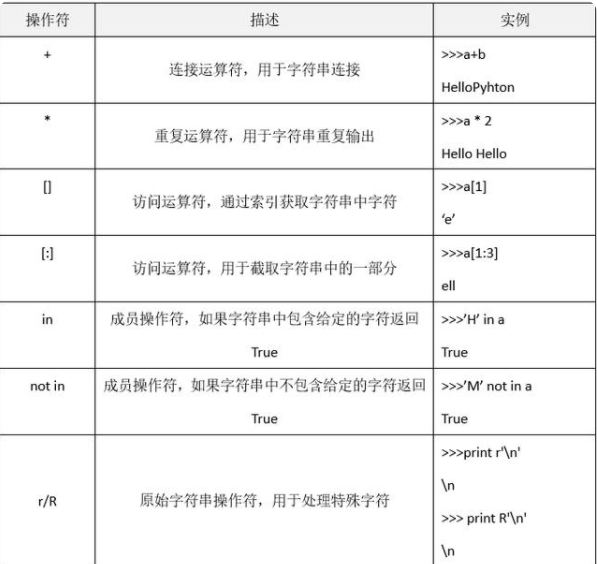
字符串-运算:下标和切片
获取字符串中某个字符
字符串是一个序列,所以可以通过下标来获取某个字符
# 获取字符串某个字符str = "hello world"print(str[0]) print(str[1]) print(str[6]) print(str[-1]) print(str[-5]) # 输出结果 h e w d l
如果是负数,那么是倒数,比如 -1 就是倒数第一个元素,-5 就是倒数第五个元素
获取字符串中一段字符
Python 中,可以直接通过切片的方式取一段字符
切片的语法格式
str[start : end : step]
-
获取列表 列表 中在 [start, end) 范围的子字符串
-
start:闭区间,包含该下标的字符,第一个字符是 0
-
end:开区间,不包含该下标的字符
-
step:步长,设为 n,则每隔 n 个元素获取一次
栗子
print("hello world'[:] ", 'hello world'[:]) # 取全部字符 print("hello world'[0:] ", 'hello world'[0:]) # 取全部字符 print("hello world'[6:] ", 'hello world'[6:]) # 取第 7 个字符到最后一个字符 print("hello world'[-5:] ", 'hello world'[-5:]) # 取倒数第 5 个字符到最后一个字符 print("hello world'[0:5] ", 'hello world'[0:5]) # 取第 1 个字符到第 5 个字符 print("hello world'[0:-5] ", 'hello world'[0:-5]) # 取第 1 个字符直到倒数第 6 个字符 print("hello world'[6:10] ", 'hello world'[6:10]) # 取第 7 个字符到第 10 个字符 print("hello world'[6:-1] ", 'hello world'[6:-1]) # 取第 7 个字符到倒数第 2 个字符 print("hello world'[-5:-1] ", 'hello world'[-5:-1]) # 取倒数第 5 个字符到倒数第 2 个字符 print("hello world'[::-1] ", 'hello world'[::-1]) # 倒序取所有字符 print("hello world'[::2] ", 'hello world'[::2]) # 步长=2,每两个字符取一次 print("hello world'[1:7:2] ", 'hello world'[1:7:2]) # 步长=2,取第 2 个字符到第 7 个字符,每两个字符取一次 # 输出结果hello world'[:] hello world hello world'[0:] hello world hello world'[6:] world hello world'[-5:] world hello world'[0:5] hello hello world'[0:-5] hello hello world'[6:10] worl hello world'[6:-1] worl hello world'[-5:-1] worl hello world'[::-1] dlrow olleh hello world'[::2] hlowrd hello world'[1:7:2] el
获取字符串长度
print(len("123")) # 输出结果3
字符串-函数:
str.index
作用:查看sub是否在字符串中,在的话返回索引,且只返回第一次匹配到的索引;若找不到则报错;可以指定统计的范围,[start,end) 左闭区间右开区间
str = "helloworldhhh"print(str.index("h")) print(str.index("hhh")) # print(str.index("test")) 直接报语法错误:ValueError: substring not found 执行结果 0 10
str.find(sub, start=None, end=None)
作用:和index()一样,只是找不到不会报错,而是返回-1
str = "helloworldhhh"print(str.find("h")) print(str.find("hhh")) print(str.find("test")) 执行结果 0 10 -1
str.count( sub, start=None, end=None)
作用:统计子字符串的数量;可以指定统计的范围,[start,end) 左闭区间右开区间
str = "hello world !!! hhh" print(str.count(" ")) print(str.count(" ", 5, 10)) 执行结果 3 1
str.split(str="", num=string.count(str))
作用:将字符串按照str分割成列表,如果参数 num 有指定值,则分隔 num+1 个子字符串
str = "hello world !!! hhh" print(str.split(" ")) print(str.split(" ", 1)) 执行结果 ['hello', 'world', '!!!', 'hhh'] ['hello', 'world !!! hhh']
str.strip(chars = " ")
作用:移除字符串头尾指定的字符序列chars,默认为空格
str.lstrip(chars = " ")
作用:移除字符串头部指定的字符序列chars,默认为空格
str.rstrip(chars = " ")
作用:移除字符串尾部指定的字符序列chars,默认为空格
str = " hello every " print("1", str.strip(), "1") print(str.lstrip(), "1") print("1", str.rstrip()) str = "!!! cool !!!" print(str.strip("!")) 执行结果 1 hello every 1 hello every 11 hello every cool
str.replace(old,new,count= -1)
作用:把字符串中的 old(旧字符串) 替换成 new(新字符串),count代表最多替换多少次,默认-1代表全部替换
str = "hello world !!! hhh" print(str.replace(" ", "-")) print(str.replace(" ", "-", 1)) 执行结果 hello-world-!!!-hhh hello-world !!! hhh
str.join(sequence)
作用:将序列中的元素以指定的字符连接生成一个新的字符串
lists = ["1", "2", "3"] tuples = ("1", "2", "3") print("".join(lists)) print("".join(tuples)) print("-".join(lists)) 执行结果 1231231-2-3
知识点
-
"".join(lists) 这是最常见的将列表、元组转成字符串的写法
-
列表里面只能存放字符串元素,有其他类型的元素会报错
-
元组也能传进去
str.upper()
作用:将字符串都变成大写字母
str.lower()
作用:将字符串都变成小写字母
str = "hello world !!! hhh" print(str.upper()) print(str.lower()) 执行结果 HELLO WORLD !!! HHH hello world !!! hhh
str.startswith(prefix, start=None, end=None)
作用:检查字符串是否是以指定子字符串开头,如果是则返回 True,否则返回 False;可以指定统计的范围,[start,end) 左闭区间右开区间
str.endswith(self, suffix, start=None, end=None)
作用:相反这是结尾
str = "hello world !!! hhh" print(str.startswith("h")) print(str.startswith("hh")) print(str.endswith("h")) print(str.endswith("hhhh")) 执行结果 TrueFalseTrueFalse
str.isdigit()
作用:检查字符串是否只由数字组成
str = "123134123" print(str.isdigit()) 执行结果 true
str.isalpha()
作用:检查字符串是否只由字母组成
str = "abc" print(str.isalpha()) 执行结果 true
str.splitlines([keepends])
作用:将字符串按照行 ('\r', '\r\n', \n') 分隔
str = """ 123 456 789 """ print(str.splitlines()) with open("./file1.txt", encoding="utf-8") as f: lists = f.read().splitlines() print(lists) 执行结果 ['', '123', '456', '789'] ['name: Jack ; salary: 12000', ' name :Mike ; salary: 12300', 'name: Luk ; salary: 10030', ' name :Tim ; salary: 9000', 'name: John ; salary: 12000', 'name: Lisa ; salary: 11000']
