六、手写实现KNN算法
语义原理:
k-近邻算法(k-Nearest Neighbor,KNN)。
对于一个样本数据集合,其由特征数据和分类数据组成,特征数据和分类数据间存在对应关系,将其视为训练样本集;对于只存在特征数据的新数据,将其与训练样本集中特征进行比较,然后用算法提取样本集中特征最相似数据(最近邻)的分类标签,作为新数据的标签,以完成分类任务。
数据原理:
计算两个向量点xA和xB之间的距离(欧式距离公式):
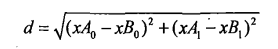
代码实现:
import numpy as np
import operator
"""
实现步骤:
1.计算已知类别数据集中的点与当前点之间的距离
2.按照距离递增次序排序
3.选取与当前点距离最小的k个点
4.确定前k个点所在类别的出现频率
5.返回前k个点出现频率最高的类别作为当前点的预测分类
"""
def classify(inX,dataSet,labels,k):
"""
计算距离最近的一个点,并返回分类值
inX:用于分类的输入向量
dataSet: 训练样本集
labels:标签向量
k:用于选择最近邻居的数目
说明:
1、标签向量labels与训练样本集具有相同的row_num
2、输入向量inX与训练样本集具有相同的col_num
"""
# 1.获取输入训练数据集的 row_num
dataSetSize = dataSet.shape[0]
# 2. np.tile 将 待分类的输入向量 扩展到和 训练数据集一样的维度
# 对扩维后的 待分类的输入向量 与 训练数据集 进行 差运算,获取距离偏差向量
diffMat = np.tile(inX,(dataSetSize,1)) - dataSet
# 3.对获取的 距离偏差向量 进行 2次方计算
sqDiffMat = diffMat**2
# 4.累计 距离偏差向量的2次方值,形成 距离偏差2次方和
sqDistances = sqDiffMat.sum(axis=1)
# 5. 对 距离篇偏差2次方和 进行 2次开方,形成 欧氏距离向量
distances = sqDistances**0.5
# 6.对 计算好的 欧式距离向量 进行排序后,获取 输出排序(从小到大排序后)后的下标
sortedDistIndicies = distances.argsort()
classCount = {}
for i in range(k):
# 由于 dataSet的row维度和labels的row维度相同
# 所以 以 len(k) 为 范围,逐次 获取到 实际分类值
voteIlabel = labels[sortedDistIndicies[i]]
# 对 实际分类值,添加排序值,形成 实际分类值-排序值 key-value对
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
"""
验证 下面句式的排序语法
import numpy as np
import operator
d = dict(
[("a",1),("b",2),("c",3)]
)
print(d)
print("-"*20)
a_sorted = sorted(d.items(),
key=operator.itemgetter(1),reverse=False)
a_sorted[0][0]
===> 'a'
"""
# 对获取到的字典数据,按值进行排序, 即从大到小次序
sortedClassCount = sorted(classCount.items(),
key = operator.itemgetter(1), # 获取对象的第2个元素(下标0开头)
reverse=True) # 逆序
# 返回发生频率最高的元素标签
return sortedClassCount[0][0]
说明:
- KNN算法需要保存全部数据集,如果训练数据集很大,必须使用大量的存储空间。
- KNN算法由于必须对数据集中的每个数据计算距离值,实际使用时可能非常耗时。
- KNN算法无法给出任何数据的基础结构信息。
