一、HBase简明笔记
1、HBase概述
1.1 Hbase定义
HBase是一种分布式、可扩展、支持海量数据存储的NoSQL数据库
1.2 HBase数据模型
逻辑上,HBase的数据模型通关系型数据库类似,数据存储在一张表中,有行有列,但HBase的底层物理存储结构为k-v。
-
HBase逻辑结构
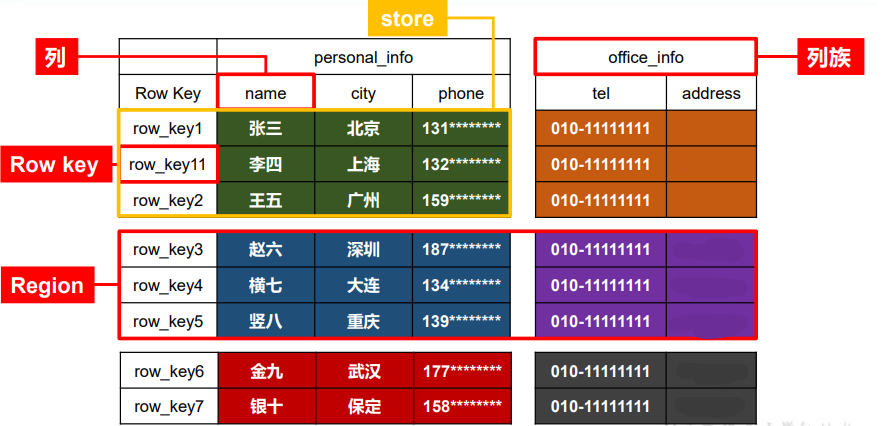
- row key有序排列,具有唯一性
- Region相当于表名,将数据按条件进行行切分
- 列族可以指定,切分宽表,作为一个整体,其内的列明不需要明确指定,可随意增删改
- store指实际的物理存储
-
HBase物理存储结构

- 每一个storeFile文件中,row key——column family——column qualifier——timestamp——type,标识唯一数据
-
数据模型
-
Name Space
命名空间,类比于关系型数据库的DataBase概念,每个命名空间下有多个表。HBase有两个自带的命名空间,分别是hbase和default,hbase中存放的是HBase内置的表,default表是用户默认使用的命名空间。
-
Region
类比于关系型数据库的表概念。不同的是,HBase 定义表时只需要声明列族即可,不需 要声明具体的列。这意味着,往 HBase 写入数据时,字段可以动态、按需指定。因此,和关系型数据库相比,HBase 能够轻松应对字段变更的场景。
-
Row
HBase 表中的每行数据都由一个 RowKey 和多个 Column(列)组成,数据是按照 RowKey 的字典顺序存储的,并且查询数据时只能根据 RowKey 进行检索,所以 RowKey 的设计十分重要。
-
Column
HBase 中的每个列都由 Column Family(列族)和 Column Qualifier(列限定符)进行限定,例如 info:name,info:age。建表时,只需指明列族,而列限定符无需预先定义。
-
TimeStamp
用于标识数据的不同版本(version),每条数据写入时,如果不指定时间戳,系统会 自动为其加上该字段,其值为写入 HBase 的时间。
-
Cell
由{rowkey, column Family:column Qualifier, time Stamp} 唯一确定的单元。cell 中的数 据是没有类型的,全部是字节码形式存贮。
-
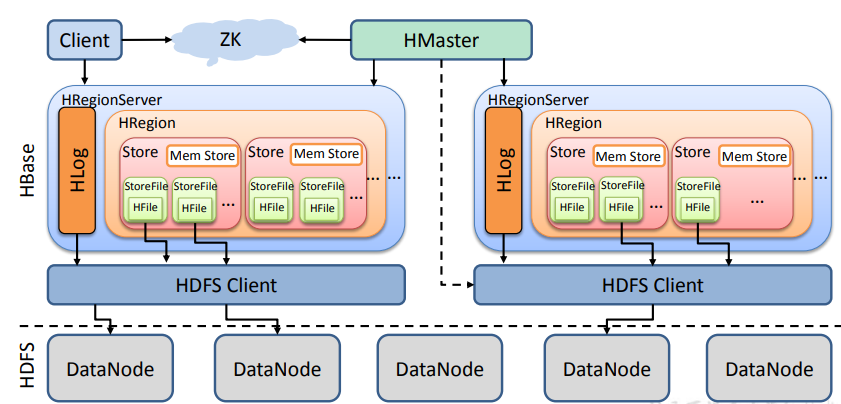
1.3 HBase基础架构

-
Region Server
Region Server 为 Region 的管理者,其实现类为 HRegionServer,主要作用如下:
- 对于数据的操作:get, put, delete;
- 对于 Region 的操作:splitRegion、compactRegion。
-
Master
Master 是所有 Region Server 的管理者,其实现类为 HMaster,主要作用如下:
- 对于表的操作:create, delete, alter
- 对于 RegionServer的操作:分配 regions到每个RegionServer,监控每个 RegionServer 的状态,负载均衡和故障转移。
-
Zookeeper
HBase 通过 Zookeeper 来做 Master 的高可用、RegionServer 的监控、元数据的入口以及 集群配置的维护等工作。
-
HDFS
HDFS 为 HBase 提供最终的底层数据存储服务,同时为 HBase 提供高可用的支持。
2、HBase安装部署
-
Zookeeper正常部署,并启动
-
Hadoop正常部署,并启动
-
Hbase下载
-
HBase的配置文件
-
修改文件$HBASE_HOME/conf/hbase-env.sh
export JAVA_HOME=/opt/software/jdk1.8.0_201 export HBASE_MANAGES_ZK=false # Configure PermSize. Only needed in JDK7. You can safely remove it for JDK8+的说明下export注释掉 export HBASE_LOG_DIR=${HBASE_HOME}/logs -
修改文件$HBASE_HOME/conf/hbase-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- 每个regionServer的共享目录,用来持久化Hbase,默认情况下在/tmp/hbase下面,注意地址为hadoop的hdfs地址--> <property> <name>hbase.rootdir</name> <value>hdfs://pc001:8082/HBase</value> </property> <!-- hbase集群模式,false表示hbase的单机,true表示是分布式模式 --> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <!-- hbase master节点的端口 --> <property> <name>hbase.master.port</name> <value>16000</value> </property> <!-- hbase 依赖的zookeeper集群节点--> <property> <name>hbase.zookeeper.quorum</name> <value>pc001,pc002,pc003</value> </property> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/opt/software/zookeeper-3.4.10/zkData</value> </property> <!-- hbase master的web ui页面的端口 --> <property> <name>hbase.master.info.port</name> <value>16010</value> </property> <property> <name>hbase.master.maxclockskew</name> <value>180000</value> </property> </configuration> -
修改文件$HBASE_HOME/conf/regionservers
pc001 pc002 pc003 -
软连接hadoop配置文件到HBase
ln -s /opt/software/hadoop-3.1.3/etc/hadoop/core-site.xml /opt/software/hbase-1.3.1/conf/core-site.xml ln -s /opt/software/hadoop-3.1.3/etc/hadoop/hdfs-site.xml /opt/software/hbase-1.3.1/conf/hdfs-site.xml -
HBase 远程发送到其他集群
-
HBase启动
提示:如果集群之间的节点时间不同步,会导致 regionserver 无法启动,抛出 ClockOutOfSyncException 异常。
启动方式一:
hbase-daemon.sh start master hbase-daemon.sh start regionserver启动方式二:
start-hbase.sh #启动 stop-hbase.sh #停止 -
查看HBase页面
启动成功后,可以通过“host:port”的方式来访问 HBase 管理页面
-
3、HBase shell操作
3.1 基本操作
-
进入HBase客户端命令行
[nuochengze@pc001 ~]$ hbase shell -
查看帮助命令
hbase(main):001:0> help -
查看当前数据库中有哪些表
hbase(main):001:0> list
3.2 表的操作
-
说明:
- 直接输入命令,可以显示帮助信息
- 大小写敏感
- 单引号,双引号不区分
- 命令结尾没有end符号
-
创建表
hbase(main):001:0> create 'student','info' -
插入数据到表
hbase(main):001:0> put 'student','1001','info:age','18' hbase(main):001:0> put 'student','1001','info:name','wonder' hbase(main):001:0> put 'student','1001','info:sex','male' hbase(main):001:0> put 'student','1002','info:sex','female' hbase(main):001:0> put 'student','1002','info:age','20' hbase(main):001:0> put 'student','1002','info:name','Kin' hbase(main):001:0> put 'student','1003','info:name','Anle' -
扫描查看表数据
hbase(main):001:0> scan 'student' hbase(main):001:0> scan 'student',{STARTROW => '1001', STOPROW => '1003'} #结果集左闭右开 hbase(main):001:0> scan 'student',{STARTROW =>'1002'} #STARTROW,STOPROW可以单独使用 -
查看表结构
hbase(main):001:0> describe 'student' -
更新指定字段的数据
hbase(main):001:0> put 'student','1001','info:name','Nick' hbase(main):001:0> put 'student','1001','info:age','100' -
查看“指定行"或"指定列族:列"的数据
hbase(main):001:0> get 'student','1001' hbase(main):001:0> get 'student','1001','info:name' -
统计表数据行数
hbase(main):001:0> count 'student' -
删除数据
-
删除某rowkey的某一列数据
hbase(main):001:0> delete 'student','1003','info:name' -
删除某rowkey的全部数据
hbase(main):001:0> deleteall 'student','1002'
-
-
清空表
hbase(main):001:0> truncate 'student'提示:清空表的操作顺序为先 disable,然后再 truncate。
-
变更表信息
hbase(main):001:0> alter 'student',{NAME => 'info',VERSIONS => 3} // 变更信息 hbase(main):001:0> get 'student','1001',{COLUMN=>'info:name',VERSIONS=>3} //查看信息 -
删除表
提示:如果直接 drop 表,会报错:ERROR: Table student is enabled. Disable it first.
删除表,首先需要让该表处于disable状态:
hbase(main):001:0> disable 'student'然后才能drop掉这个表:
hbase(main):001:0> drop 'student'
4、HBase进阶
4.1 架构原理
-
StoreFile
保存实际数据的物理文件,StoreFile以HFile的形式存储在HDFS上。
每个Store会有一个或多个StoreFile(HFile),数据在每个StoreFile中都是有序的。
-
MemStore
写缓存,由于HFile中的数据要求是有序的,所以数据是先存储在MemStore中,排好序后,等到达flush时机才会刷写到HFile,每次刷写都会形成一个新的HFile。
-
WAL
由于数据要经过MemStore排序后才能刷写到HFile,但把数据保存在内存中会有很高的概率数据丢失,为了解决这个问题,数据会先写在一个叫做Write-Ahead logfile的文件中,然后再写入MemStore中。
所以在系统出现故障时,数据可以通过这个日志文件重建。
4.2 写流程
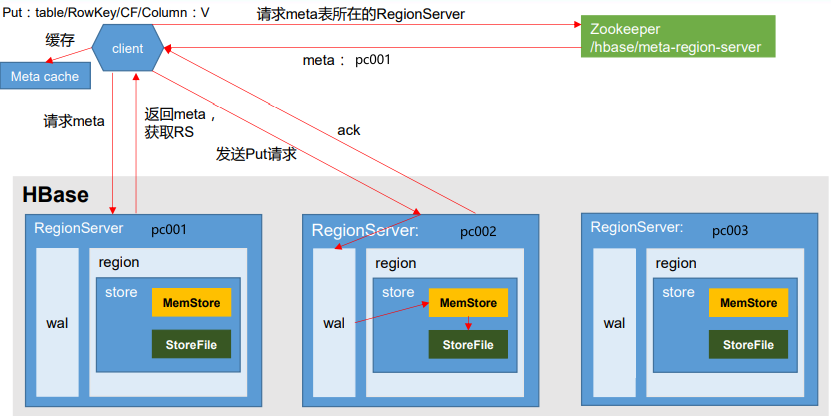
写的步骤:
-
Client先访问zookeeper,获取hbase:meta表位于哪个RegionServer
-
访问对应的RegionServer,获取hbase:meta表,根据写请求的namespace:table/rowkey,查询出目标数据位于哪个RegionServer中的哪个Region中。
并将该table的Region信息以及meta表的位置信息缓存在客户端的meta cache中,方便下次访问。
-
与目标RegionServer进行通讯,发送put请求
-
将数据顺序写入(追加)到WAL,直到完成数据写入返回Ack给client
-
等到达MemStore的刷写时机后,将数据刷写到HFile
4.3 MemStore Flush

MemStore刷写时机:
-
当某个MemStore的大小达到了hbase.hregion.memstore.flush.size(默认值 128M),其所在Region的所有MemStore都会刷写。
当MemStore的大小达到了 hbase.hregion.memstore.flush.size(默认值 128M) hbase.hregion.memstore.block.multiplier(默认值 4)*时,会阻止继续往MemStore中写数据,防止内存崩溃。
-
当RegionServer中MemStore的总大小达到了 java_heapsize * hbase.regionserver.global.memstore.size(默认值 0.4) hbase.regionserver.global.memstore.size.lower.limit(默认值 0.95)*时,Region会按照其所有MemStore的大小顺序(由大到小)依次进行刷写,直到RegionServer中所有MemStore的总大小减小到上述限制值以下。
当RegionServer中MemStore的总大小达到java_heapsize * hbase.regionserver.global.memstore.size(默认值 0.4)时,会阻止继续往所有的MemStore中写数据,防止内存崩溃。
-
到达自动刷写的时间,也会触发MemStore刷写。
自动刷写的时间间隔由该属性进行配置:hbase.regionserver.optionalcacheflushinterval(默认 1 小时)
-
当WAL文件的数量超过hbase.regionserver.max.logs,Region会按照时间顺序依次进行刷写,直到WAL文件数量减小到hbase.regionserver.max.log以下(该属性名已经废弃, 现无需手动设置,最大值为 32)
4.4 读流程
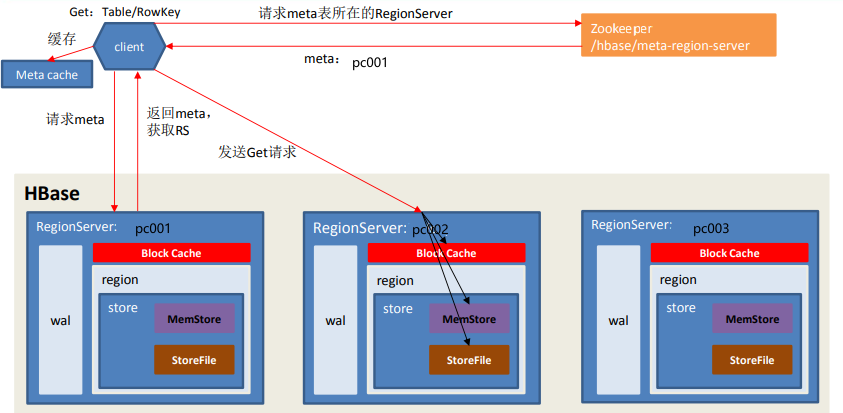
读的步骤:
- Client先访问Zookeeper,获取hbase:meta表位于哪个RegionServer
- 访问对应的RegionServer,获取hbase:meta表,根据读请求的 namespace:table/rowkey,查询出目标数据位于哪个RegionServer中的哪个Region中。并将该table的Region信息以及meta表的位置信息缓存在客户端的meta cache,方便下次访问
- 与目标RegionServer进行通讯
- 分别在Block Cache(读缓存),MemStore和StoreFile(HFile)中查询目标数据,并将查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(timeStamp)或者不同的类型(put/Delete)。
- 将从文件中查询到的数据块(Block,HFile数据存储单元,默认大小为64kb)缓存到Block Cache中。
- 将合并后的最终结果返回给客户端
3.5 StoreFIle Compaction
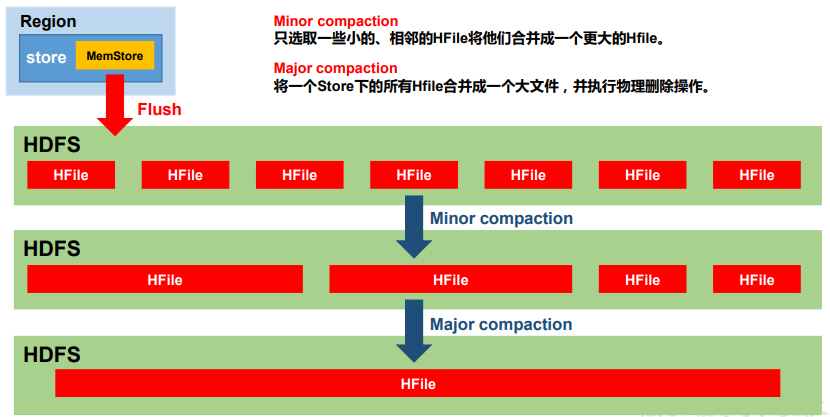
-
进行StoreFile Compaction的目的
由于MemStore每次刷写都会生成一个新的HFile,且同一个字段的不同版本(TimeStamp)和不同类型(Put/Delete)有可能会分布在不同的HFile中,因此查询时需要遍历所有的HFile。为了减少HFile的个数,以及清理掉过期和删除的数据,会进行StoreFIle Compaction。
-
Compaction的类型
-
Minor Compaction
Minor Compaction会将临近的若干较小的HFile合并成一个较大的HFile,但不会清理过期和删除的数据。
-
Major Compaction
Major Compaction会将一个Store下的所有的HFile合并成一个大HFile,并且会清理掉过期和删除的数据。
-
3.6 Region Split

默认情况下,每个 Table 起初只有一个 Region,随着数据的不断写入,Region 会自动进 行拆分。刚拆分时,两个子 Region 都位于当前的 Region Server,但处于负载均衡的考虑, HMaster 有可能会将某个 Region 转移给其他的 Region Server。
Region Split 时机:
- 当1个region中的某个Store下所有StoreFile的总大小超过hbase.hregion.max.filesize, 该 Region 就会进行拆分(0.94 版本之前)。
- 当 1 个 region 中 的 某 个 Store 下所有 StoreFile 的 总 大 小 超 过 Min(R^2 * "hbase.hregion.memstore.flush.size",hbase.hregion.max.filesize"),该 Region 就会进行拆分,其 中 R 为当前 Region Server 中属于该 Table 的个数(0.94 版本之后)。
5、HBaseAPI
-
环境准备
<dependencies> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-client</artifactId> <version>1.3.1</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-server</artifactId> <version>1.3.1</version> </dependency> </dependencies>
5.1 DDL
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.protobuf.generated.HBaseProtos;
import java.io.IOException;
public class HbaseTestApi {
private static Connection connection = null;
private static Admin admin = null;
static {
try {
// 获取配置信息
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum", "pc001,pc002,pc003");
// 创建连接对象
connection = ConnectionFactory.createConnection(configuration);
// 创建admin对象
admin = connection.getAdmin();
} catch (IOException e) {
e.printStackTrace();
}
}
// 关闭资源
public static void close() {
if (admin != null) {
try {
admin.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (connection != null) {
try {
connection.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
// 1.判断表是否存在
public static boolean isTableExists(String tableName) throws IOException {
boolean exists = admin.tableExists(TableName.valueOf(tableName));
return exists;
}
// 2,创建表
public static void createTable(String tableName, String... cfs) throws IOException {
// 判断是否存在列族信息
if (cfs.length <= 0) {
System.out.println("需要设置列族信息!");
return;
}
// 判断要创建的表是否存在
if (isTableExists(tableName)) {
System.out.println(tableName + " 表已存在!");
return;
}
// 创建表描述器
HTableDescriptor hTableDescriptor = new HTableDescriptor(TableName.valueOf(tableName));
// 循环添加列族信息
for (String cf : cfs) {
// 创建列族描述器
HColumnDescriptor hColumnDescriptor = new HColumnDescriptor(cf);
// 添加具体的列族信息
hTableDescriptor.addFamily(hColumnDescriptor);
}
// 创建表
admin.createTable(hTableDescriptor);
}
// 3.删除表
public static void dropTable(String tableName) throws IOException {
// 判断要创建的表是否存在
if (!isTableExists(tableName)) {
System.out.println(tableName + " 表已存在!");
return;
}
// 使表下线
admin.disableTable(TableName.valueOf(tableName));
// 删除表
admin.deleteTable(TableName.valueOf(tableName));
}
// 4.创建命名空间
public static void createNameSpace(String ns) {
// 创建命名空间描述器
NamespaceDescriptor namespaceDescriptor = NamespaceDescriptor.create(ns).build();
// 创建命名空间
try {
admin.createNamespace(namespaceDescriptor);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws IOException {
// 判断表是否存在
System.out.println("student表是否存在:"+isTableExists("student"));
System.out.println("************************************");
// 创建表
System.out.println("studnet1 是否存在:"+ isTableExists("student1"));
createTable("student1","info");
System.out.println("创建后,studnet1 是否存在:"+ isTableExists("student1"));
System.out.println("************************************");
// 删除表
dropTable("student1");
System.out.println("删除后,studnet1 是否存在:"+ isTableExists("student1"));
System.out.println("************************************");
// 创建命名空间
createNameSpace("test_nameSpace");
close();
}
}
5.2 DML
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.protobuf.generated.HBaseProtos;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class HbaseTestApi {
private static Connection connection = null;
private static Admin admin = null;
static {
try {
// 获取配置信息
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum", "pc001,pc002,pc003");
// 创建连接对象
connection = ConnectionFactory.createConnection(configuration);
// 创建admin对象
admin = connection.getAdmin();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void close() {
if (admin != null) {
try {
admin.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (connection != null) {
try {
connection.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
// 插入数据
public static void putData(String tableName, String rowKey, String cf, String cn, String value) throws IOException {
// 获取表对象
Table table = connection.getTable(TableName.valueOf(tableName));
// 获取Put对象
Put put = new Put(Bytes.toBytes(rowKey));
// 添加列族信息
put.addColumn(Bytes.toBytes(cf), Bytes.toBytes(cn), Bytes.toBytes(value));
// 插入数据
table.put(put);
// 关闭表连接
table.close();
}
// 获取数据
public static void getData(String tableName, String rowKey, String cf, String cn) throws IOException {
// 获取表对象
Table table = connection.getTable(TableName.valueOf(tableName));
// 创建get对象
Get get = new Get(Bytes.toBytes(rowKey));
// 指定列族和列明
get.addColumn(Bytes.toBytes(cf), Bytes.toBytes(cn));
// 指定获取到的版本
get.setMaxVersions();
// 获取result
Result result = table.get(get);
// 解析result
for (Cell cell : result.rawCells()) {
System.out.println(Bytes.toString(CellUtil.cloneValue(cell)));
System.out.println(cell.toString());
}
// 关闭表连接
table.close();
}
// 扫描数据
public static void scanData(String tableName) throws IOException {
// 获取表对象
Table table = connection.getTable(TableName.valueOf(tableName));
//构建Scan对象
Scan scan = new Scan();
ResultScanner resultScanner = table.getScanner(scan);
for (Result result : resultScanner) {
for (Cell cell : result.rawCells()) {
System.out.println(Bytes.toString(CellUtil.cloneValue(cell)));
System.out.println(cell.toString());
}
}
// 关闭表连接
table.close();
}
// 删除数据
public static void deleteData(String tableName, String rowKey, String cf, String cn) throws IOException {
// 获取表对象
Table table = connection.getTable(TableName.valueOf(tableName));
// 构建Delete对象
Delete delete = new Delete(Bytes.toBytes(rowKey));
// 指定列族和列名
delete.addColumns(Bytes.toBytes(cf), Bytes.toBytes(cn));
// 删除操作
table.delete(delete);
// 关闭连接
table.close();
}
public static void main(String[] args) throws IOException {
// putData("student","1001","info","name","hello world");
deleteData("student", "1001", "info", "name");
close();
}
}
5.3 MapReduce
通过 HBase 的相关 JavaAPI,可以实现伴随 HBase 操作的 MapReduce 过程,比如使用 MapReduce 将数据从本地文件系统导入到 HBase 的表中,比如从 HBase 中读取一些原 始数据后使用 MapReduce 做数据分析。
5.3.1 环境准备
-
查看 HBase 的 MapReduce 任务的执行
[nuochengze@pc001 ~]$ hbase mapredcp
-
环境变量的导入
-
临时(在命令行中执行)
export HBASE_HOME=/opt/software/hbase-1.3.1 export HADOOP_HOME=/opt/software/hadoop-3.1.3 export HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase mapredcp` -
永久生效
vim编辑
$HADOOP_HOME/etc/hadoophadoop-env.sh注意,HADOOP_CLASSPATH,需要在for循环之后配置
export HBASE_HOME=/opt/software/hbase-1.3.1 export HADOOP_HOME=/opt/software/hadoop-3.1.3 export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/opt/software/hbase-1.3.1/lib/*修改完成后,注意分发到其他集群中
-
-
测试一:rowcounter
-
hbase数据准备

-
rowcounter测试
$HADOOP_HOME/bin/yarn jar $HBASE_HOME/lib/hbase-server-1.3.1.jar rowcounter student
-
-
测试二:使用 MapReduce 将本地数据导入到 HBase
-
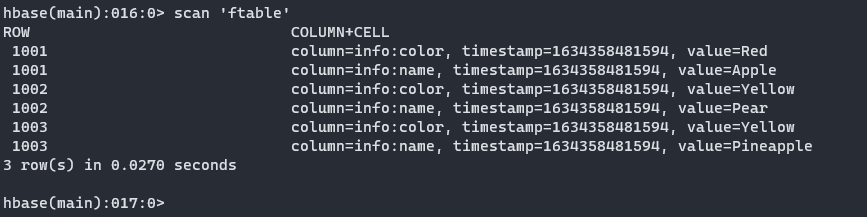
ftable.tsv数据准备,上传到hdfs
1001 Apple Red 1002 Pear Yellow 1003 Pineapple Yellowhdfs dfs -put ftable.tsv / -
hbase需要提前创建好表
hbase(main):001:0> create 'ftable','info' -
执行 MapReduce 将数据导入到 HBase 的 fruit 表中
yarn jar $HBASE_HOME/lib/hbase-server-1.3.1.jar importtsv \ -Dimporttsv.columns=HBASE_ROW_KEY,info:name,info:color \ ftable \ hdfs://pc001:8082/ftable.tsv
-
5.3.2 从HDFS读取数据到HBase
-
Mapper
package customize_mr1; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.util.Bytes; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class ReadTableMapper extends Mapper<LongWritable, Text, ImmutableBytesWritable, Put>{ @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, ImmutableBytesWritable, Put>.Context context) throws IOException, InterruptedException { // 从HDFS中读取数据 String[] splits = value.toString().split("\t"); // 1001,Apple,Red String rowKey = splits[0]; String name = splits[1]; String color = splits[2]; // 初始化rowKey ImmutableBytesWritable immutableBytesWritable = new ImmutableBytesWritable(Bytes.toBytes(rowKey)); // 初始化Put对象 Put put = new Put(Bytes.toBytes(rowKey)); // 给put对象赋值 put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("name"),Bytes.toBytes(name)); put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("color"),Bytes.toBytes(color)); // 写出 context.write(immutableBytesWritable,put); } } -
Reducer
package customize_mr1; import org.apache.commons.lang.ObjectUtils; import org.apache.hadoop.hbase.client.Mutation; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.mapreduce.TableReducer; import org.apache.hadoop.hbase.util.Bytes; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class WriteTableReducer extends TableReducer<ImmutableBytesWritable, Put, NullWritable> { @Override protected void reduce(ImmutableBytesWritable key, Iterable<Put> values, Reducer<ImmutableBytesWritable, Put, NullWritable, Mutation>.Context context) throws IOException, InterruptedException { // 将读出来的每一行数据写入到表中 for (Put value : values) { context.write(NullWritable.get(),value); } } } -
Driver
package customize_mr1; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; public class TableRunner implements Tool { // 定义一个configuration private Configuration configuration = null; @Override public int run(String[] args) throws Exception { // 获取job对象 Job job = Job.getInstance(configuration); // 设置驱动类路径 job.setJarByClass(TableRunner.class); // 设置Mapper&Mapper输出的kv类型 job.setMapperClass(ReadTableMapper.class); job.setMapOutputKeyClass(ImmutableBytesWritable.class); job.setMapOutputValueClass(Put.class); // 设置Reducer类 TableMapReduceUtil.initTableReducerJob(args[1], WriteTableReducer.class, job); // 设置输入参数 FileInputFormat.setInputPaths(job, new Path(args[0])); // 提交任务 return job.waitForCompletion(true) ? 0 : 1; } @Override public void setConf(Configuration conf) { configuration = conf; } @Override public Configuration getConf() { return configuration; } public static void main(String[] args) { try { Configuration configuration = new Configuration(); int run = ToolRunner.run(configuration, new TableRunner(), args); System.exit(run); } catch (Exception e) { e.printStackTrace(); } } }
5.3.3 从HBase读数据后写入到HBase
-
Mapper
package customize_mr1; import org.apache.hadoop.hbase.Cell; import org.apache.hadoop.hbase.CellUtil; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.client.Result; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.mapreduce.TableMapper; import org.apache.hadoop.hbase.util.Bytes; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class RTableMapper extends TableMapper<ImmutableBytesWritable, Put> { @Override protected void map(ImmutableBytesWritable key, Result value, Mapper<ImmutableBytesWritable, Result, ImmutableBytesWritable, Put>.Context context) throws IOException, InterruptedException { // 创建Put对象 Put put = new Put(key.get()); // 获取数据 for (Cell cell : value.rawCells()) { if("info".equals(Bytes.toString(CellUtil.cloneFamily(cell)))){ // 判断当前的cell是否为name列 if("name".equals(Bytes.toString(CellUtil.cloneQualifier(cell)))){ // 给Put对象赋值 put.add(cell); } } } context.write(key,put); } } -
Reducer
package customize_mr1; import org.apache.hadoop.hbase.client.Mutation; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.mapreduce.TableReducer; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class RTableReducer extends TableReducer<ImmutableBytesWritable, Put, NullWritable> { @Override protected void reduce(ImmutableBytesWritable key, Iterable<Put> values, Reducer<ImmutableBytesWritable, Put, NullWritable, Mutation>.Context context) throws IOException, InterruptedException { for (Put value : values) { context.write(NullWritable.get(),value); } } } -
Driver
package customize_mr1; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.client.Scan; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; public class RTableDriver implements Tool { private Configuration configuration = null; @Override public int run(String[] args) throws Exception { Job job = Job.getInstance(configuration); job.setJarByClass(RTableDriver.class); TableMapReduceUtil.initTableMapperJob(args[0], //数据源的表名 new Scan(), //scan 扫描控制器 RTableMapper.class, //设置 Mapper 类 ImmutableBytesWritable.class, //设置 Mapper 输出 key 类型 Put.class, //设置 Mapper 输出 value 值类型 job); //设置给哪个 JOB TableMapReduceUtil.initTableReducerJob(args[1], RTableReducer.class, job); return job.waitForCompletion(true) ? 0 : 1; } @Override public void setConf(Configuration conf) { configuration = conf; } @Override public Configuration getConf() { return configuration; } public static void main(String[] args) { try { Configuration configuration = new Configuration(); int run = ToolRunner.run(configuration, new RTableDriver(), args); System.exit(run); } catch (Exception e) { e.printStackTrace(); } } }
6、HBase优化
6.1 高可用
在 HBase 中 HMaster 负责监控 HRegionServer 的生命周期,均衡 RegionServer 的负载, 如果 HMaster 挂掉了,那么整个 HBase 集群将陷入不健康的状态,并且此时的工作状态并 不会维持太久。所以 HBase 支持对 HMaster 的高可用配置。
-
关闭HBase集群
stop-hbase.sh -
在$HBASE_HOME/conf目录下创建
backup-masters文件# 添加以下内容 pc002 pc003 -
分发
backup-masters文件到其他节点
6.2 预分区
每一个 region 维护着 StartRow 与 EndRow,如果加入的数据符合某个 Region 维护的 RowKey 范围,则该数据交给这个 Region 维护。那么依照这个原则,我们可以将数据所要 投放的分区提前大致的规划好,以提高 HBase 性能。
-
手动设置与分区
hbase(main):003:0> create "stu','info',"partition1',SPLITS=>['1000','2000','3000','4000']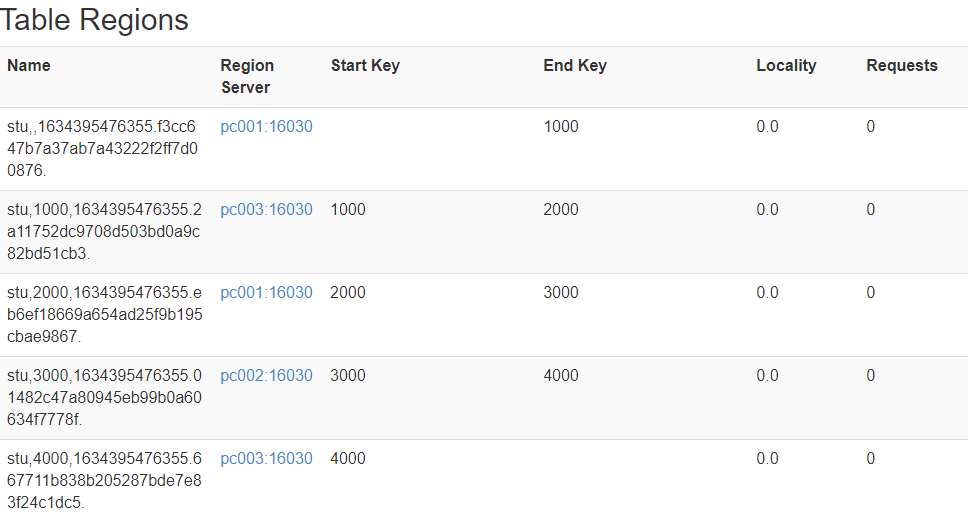
-
生成16进制序列预分区
hbase(main):009:0> create 'stu1','info',{NUMREGIONS=>15,SPLITALGO=>'HexStringSplit'} -
按照文件中设置的规则预分区
# splits.txt aaa bbb ccc dddhbase(main):011:0> create 'sut2','info',SPLITS_FILE=>'/home/nuochengze/splits.txt' -
使用JavaAPI创建预分区
//自定义算法,产生一系列 hash 散列值存储在二维数组中 byte[][] splitKeys = 某个散列值函数 //创建 HbaseAdmin 实例 HBaseAdmin hAdmin = new HBaseAdmin(HbaseConfiguration.create()); //创建 HTableDescriptor 实例 HTableDescriptor tableDesc = new HTableDescriptor(tableName); //通过 HTableDescriptor 实例和散列值二维数组创建带有预分区的 Hbase 表 hAdmin.createTable(tableDesc, splitKeys);
6.3 RowKey设计
一条数据的唯一标识就是 RowKey,那么这条数据存储于哪个分区,取决于 RowKey 处 于哪个一个预分区的区间内,设计 RowKey 的主要目的 ,就是让数据均匀的分布于所有的 region 中,在一定程度上防止数据倾斜。
- 要考虑的关键因素
- 散列性
- 唯一性
- 长度原则
- 常用的方式
- 生成随机数、hash、散列值
- 字符串反转
- 字符串拼接
6.4 内存优化
HBase 操作过程中需要大量的内存开销,毕竟 Table 是可以缓存在内存中的,一般会分 配整个可用内存的 70%给 HBase 的 Java 堆。但是不建议分配非常大的堆内存,因为 GC 过 程持续太久会导致 RegionServer 处于长期不可用状态,一般 16~48G 内存就可以了,如果因 为框架占用内存过高导致系统内存不足,框架一样会被系统服务拖死。
6.5 基础优化
-
允许在 HDFS 的文件中追加内容
hdfs-site.xml、hbase-site.xml 属性:dfs.support.append 解释:开启 HDFS 追加同步,可以优秀的配合 HBase 的数据同步和持久化。默认值为 true。 -
优化 DataNode 允许的最大文件打开数
hdfs-site.xml 属性:dfs.datanode.max.transfer.threads 解释:HBase 一般都会同一时间操作大量的文件,根据集群的数量和规模以及数据动作,设置为 4096 或者更高。默认值:4096 -
优化延迟高的数据操作的等待时间
hdfs-site.xml 属性:dfs.image.transfer.timeout 解释:如果对于某一次数据操作来讲,延迟非常高,socket 需要等待更长的时间,建议把该值设置为更大的值(默认 60000 毫秒),以确保 socket 不会被 timeout 掉。 -
优化数据的写入效率
mapred-site.xml 属性:mapreduce.map.output.compress mapreduce.map.output.compress.codec 解释:开启这两个数据可以大大提高文件的写入效率,减少写入时间。第一个属性值修改为true,第二个属性值修改为:org.apache.hadoop.io.compress.GzipCodec 或者其他压缩方式。 -
设置 RPC 监听数量
hbase-site.xml 属性:Hbase.regionserver.handler.count 解释:默认值为 30,用于指定 RPC 监听的数量,可以根据客户端的请求数进行调整,读写请求较多时,增加此值。 -
优化 HStore 文件大小
hbase-site.xml 属性:hbase.hregion.max.filesize 解释:默认值 10737418240(10GB),如果需要运行 HBase 的 MR 任务,可以减小此值,因为一个 region 对应一个 map 任务,如果单个 region 过大,会导致 map 任务执行时间过长。该值的意思就是,如果 HFile 的大小达到这个数值,则这个 region 会被切分为两 个 Hfile。 -
优化 HBase 客户端缓存
hbase-site.xml 属性:hbase.client.write.buffer 解释:用于指定 Hbase 客户端缓存,增大该值可以减少 RPC 调用次数,但是会消耗更多内存,反之则反之。一般我们需要设定一定的缓存大小,以达到减少 RPC 次数的目的。 -
指定 scan.next 扫描 HBase 所获取的行数
hbase-site.xml 属性:hbase.client.scanner.caching 解释:用于指定 scan.next 方法获取的默认行数,值越大,消耗内存越大。 -
flush、compact、split 机制
当 MemStore 达到阈值,将 Memstore 中的数据 Flush 进 Storefile;compact 机制则是把 flush 出来的小文件合并成大的 Storefile 文件。split 则是当 Region 达到阈值,会把过大的 Region 一分为二。
hbase-site.xml 属性:hbase.hregion.memstore.flush.size:134217728 128M 就是 Memstore 的默认阈值 hbase.regionserver.global.memstore.upperLimit:0.4 hbase.regionserver.global.memstore.lowerLimit:0.38
7、案例
一个依托hbase的web案例,实现了发布消息,关注,取消关注,展示的功能。
7.1 表规划
分为三张表:内容表,关系表,收件箱表
-
内容表

-
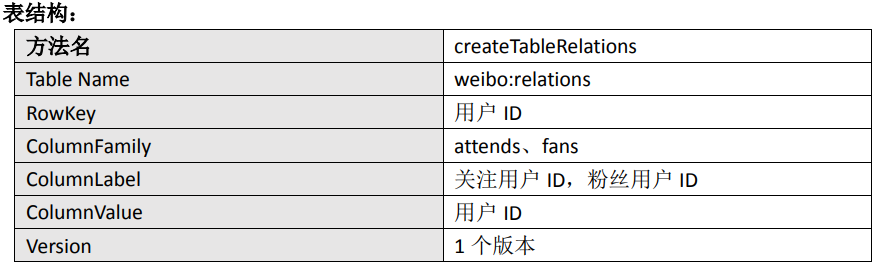
关系表
-
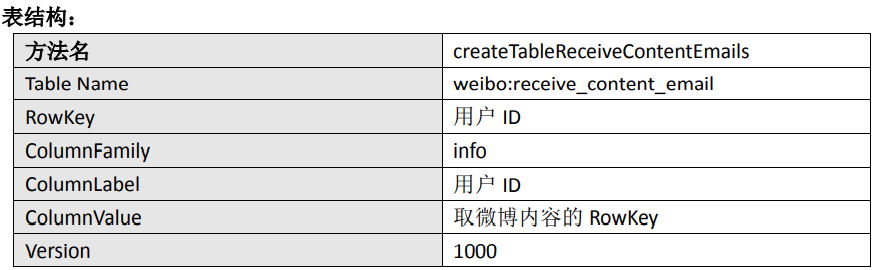
收件箱表
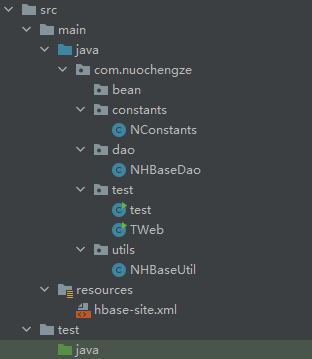
7.2 Project文件规划
7.3 源代码
7.3.1 Utils
-
NHBaseUtil.java
package com.nuochengze.utils; import com.nuochengze.constants.NConstants; import org.apache.hadoop.hbase.*; import org.apache.hadoop.hbase.client.Admin; import org.apache.hadoop.hbase.client.Connection; import org.apache.hadoop.hbase.client.ConnectionFactory; import java.io.IOException; /* * 1.创建命名空间 * 2.判断表是否存在 * 3.创建表(三张表) * */ public class NHBaseUtil { // 1.创建命名空间 public static void createNameSpace(String ns) throws IOException { // 获取Connection对象 Connection connection = ConnectionFactory.createConnection(NConstants.CONFIGURATION); // 获取admin对象 Admin admin = connection.getAdmin(); // 创建命名空间描述器 NamespaceDescriptor namespaceDescriptor = NamespaceDescriptor.create(ns).build(); // 创建命名空间 admin.createNamespace(namespaceDescriptor); // 关闭资源 admin.close(); connection.close(); } // 2.判断表是否存在 private static boolean isTableExists(String tableName) throws IOException { // 获取Connection对象 Connection connection = ConnectionFactory.createConnection(NConstants.CONFIGURATION); // 获取admin对象 Admin admin = connection.getAdmin(); // 判断表是否存在 boolean exists = admin.tableExists(TableName.valueOf(tableName)); // 关闭资源 admin.close(); connection.close(); // 返回结果 return exists; } // 3.创建表 public static void createTable(String tableName,int versions,String...cfs) throws IOException { // 判断是否存在列族信息 if(cfs.length<=0) { System.out.println("列族信息不全!"); return; } // 判断要创建的表是否存在 if(isTableExists(tableName)){ System.out.println("表已存在"); return; } try { // 获取connection,admin Connection connection = ConnectionFactory.createConnection(NConstants.CONFIGURATION); Admin admin = connection.getAdmin(); //创建表描述器 HTableDescriptor hTableDescriptor = new HTableDescriptor(TableName.valueOf(tableName)); // 添加列族信息 for (String cf : cfs) { // 创建列族描述器 HColumnDescriptor hColumnDescriptor = new HColumnDescriptor(cf); // 设置版本 hColumnDescriptor.setMaxVersions(versions); // 添加具体的列族信息 hTableDescriptor.addFamily(hColumnDescriptor); } // 创建表 admin.createTable(hTableDescriptor); // 关闭资源 admin.close(); connection.close(); } catch (IOException e) { e.printStackTrace(); } } }
7.3.2 Constants
-
NConstants
package com.nuochengze.constants; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.HBaseConfiguration; public class NConstants { // HBase的配置信息 public static final Configuration CONFIGURATION = HBaseConfiguration.create(); // 命名空间 public static final String NAMESPACE="web"; // web内容表 public static final String CONTENT_TABLE="web:content"; public static final String CONTENT_TABLE_CF="info"; public static final int CONTENT_TABLE_VERSIONS=1; // 用户关系表 public static final String RELATION_TABLE="web:relation"; public static final String RELATION_TABLE_CF1="attends"; public static final String RELATION_TABLE_CF2="fans"; public static final int RELATION_TABLE_VERSIONS=1; // 收件箱表 public static final String INBOX_TABLE="web:inbox"; public static final String INBOX_TABLE_CF="info"; public static final int INBOX_TABLE_VERSIONS=2; }
7.3.3 Dao
-
NHBaseDao
package com.nuochengze.dao; import com.nuochengze.constants.NConstants; import org.apache.hadoop.hbase.Cell; import org.apache.hadoop.hbase.CellUtil; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.*; import org.apache.hadoop.hbase.filter.CompareFilter; import org.apache.hadoop.hbase.filter.RowFilter; import org.apache.hadoop.hbase.filter.SubstringComparator; import org.apache.hadoop.hbase.util.Bytes; import java.io.IOException; import java.util.ArrayList; /* * 1.发布微博 * 2.删除微博 * 3.关注用户 * 4.取关用户 * 5.获取用户web详情 * 6.获取用户的初始化页面 * */ public class NHBaseDao { // 1.发布微博 public static void publishWeb(String uid,String content) throws IOException { Connection connection = ConnectionFactory.createConnection(NConstants.CONFIGURATION); // 第一部分:写入微博内容 Table contentTable = connection.getTable(TableName.valueOf(NConstants.CONTENT_TABLE)); long ts = System.currentTimeMillis(); String rowKey = uid + "_" + ts; Put put = new Put(Bytes.toBytes(rowKey)); put.addColumn(Bytes.toBytes(NConstants.CONTENT_TABLE_CF),Bytes.toBytes("content"),ts,Bytes.toBytes(content)); contentTable.put(put); // 第二部分:操作微博收件箱表 // 创建关系表对象 Table relationTable = connection.getTable(TableName.valueOf(NConstants.RELATION_TABLE)); // 获取当前发布微博人的fans列族数据 Get relation_get = new Get(Bytes.toBytes(rowKey)); // 指定为fans列族 relation_get.addFamily(Bytes.toBytes(NConstants.RELATION_TABLE_CF2)); Result result = relationTable.get(relation_get); // 创建发送给粉丝的内容的集合 ArrayList<Put> inboxPuts = new ArrayList<>(); // 遍历粉丝,发送消息 for (Cell cell : result.rawCells()) { // web收件箱表的Put对象 Put inboxPut = new Put(CellUtil.cloneQualifier(cell)); // 给web收件箱表的Put对象赋值 inboxPut.addColumn(Bytes.toBytes(NConstants.INBOX_TABLE_CF),Bytes.toBytes(uid),Bytes.toBytes(rowKey)); // 将收件箱表的Put对象存入集合 inboxPuts.add(inboxPut); } // 判断是否有粉丝 if(inboxPuts.size()>0){ // 获取收件箱表对象 Table inboxTable = connection.getTable(TableName.valueOf(NConstants.INBOX_TABLE)); // 执行收件箱表数据插入操作 inboxTable.put(inboxPuts); // 关闭收件箱表 inboxTable.close(); } // 关闭资源 relationTable.close(); contentTable.close(); connection.close(); } // 2.关注用户 public static void addAttends(String uid,String...attends) throws IOException { // 校验是否添加了待关注的人 if(attends.length<=0){ System.out.println("请选择待关注的人"); return; } // 第一部分:写入关系表 // 获取Connection对象,relation对象 Connection connection = ConnectionFactory.createConnection(NConstants.CONFIGURATION); Table relationTable = connection.getTable(TableName.valueOf(NConstants.RELATION_TABLE)); // 创建收集操作者Put对象的集合 ArrayList<Put> relationPuts = new ArrayList<>(); // 创建操作者Put对象 Put uidPut = new Put(Bytes.toBytes(uid)); for (String attend : attends) { // 给操作者put对象赋值 uidPut.addColumn(Bytes.toBytes(NConstants.RELATION_TABLE_CF1),Bytes.toBytes(attend),Bytes.toBytes(attend)); // 创建被关注者的Put对象 Put attendPut = new Put(Bytes.toBytes(attend)); // 给被关注者的put对象赋值 attendPut.addColumn(Bytes.toBytes(NConstants.RELATION_TABLE_CF2),Bytes.toBytes(uid),Bytes.toBytes(uid)); // 将被关注者的Put对象放入集合 relationPuts.add(attendPut); } // 将操作者的Put对象放入集合 relationPuts.add(uidPut); // 将数据插入数据库 relationTable.put(relationPuts); // 第二部分:操作收件箱 // 获取微博内容表对象 Table contentTable = connection.getTable(TableName.valueOf(NConstants.CONTENT_TABLE)); // 创建收件箱表的Put对象 Put inboxReceivePut = new Put(Bytes.toBytes(uid)); for (String attend : attends) { // 获取当前被关注者的近期微博 Scan attendContentScan = new Scan(Bytes.toBytes(attend + "_"), Bytes.toBytes(attend + "|")); ResultScanner resultScanner = contentTable.getScanner(attendContentScan); // 定义时间戳,防止数据被覆盖 long ts = System.currentTimeMillis(); for (Result result : resultScanner) { // 给收件箱表的put对象赋值 inboxReceivePut.addColumn(Bytes.toBytes(NConstants.INBOX_TABLE_CF),Bytes.toBytes(attend),ts,result.getRow()); } } if(!inboxReceivePut.isEmpty()){ // 获取收件箱表对象 Table inboxTable = connection.getTable(TableName.valueOf(NConstants.INBOX_TABLE)); // 插入数据 inboxTable.put(inboxReceivePut); // 关闭资源 inboxTable.close(); } // 关闭资源 contentTable.close(); relationTable.close(); connection.close(); } // 3.取关 public static void deleteAttends(String uid,String...dels) throws IOException{ if (dels.length<0){ System.out.println("请添加待取消关注对象"); return; } // 获取Connection对象 Connection connection = ConnectionFactory.createConnection(NConstants.CONFIGURATION); // 第一部分:操作用户关系表 Table relation_Table = connection.getTable(TableName.valueOf(NConstants.RELATION_TABLE)); // 创建集合,存放用户关系表的Delete对象 ArrayList<Delete> delete_ArrayList = new ArrayList<>(); // 创建操作者的Delete对象 Delete uid_Relation_Delete = new Delete(Bytes.toBytes(uid)); for (String del : dels) { // 给操作者的delete对象赋值 uid_Relation_Delete.addColumns(Bytes.toBytes(NConstants.RELATION_TABLE_CF1),Bytes.toBytes(del)); // 创建被取关者的Delete对象 Delete del_Relation_Delete = new Delete(Bytes.toBytes(del)); del_Relation_Delete.addColumns(Bytes.toBytes(NConstants.RELATION_TABLE_CF2),Bytes.toBytes(uid)); // 将被取关者的Delete的对象放入集合 delete_ArrayList.add(del_Relation_Delete); } // 将操作者的Delete对象添加至集合 delete_ArrayList.add(uid_Relation_Delete); // 执行删除操作 relation_Table.delete(delete_ArrayList); // 第二部分:操作收件箱表 Table inbox_Table = connection.getTable(TableName.valueOf(NConstants.INBOX_TABLE)); Delete uid_Inbox_Delete = new Delete(Bytes.toBytes(uid)); for (String del : dels) { uid_Inbox_Delete.addColumns(Bytes.toBytes(NConstants.INBOX_TABLE_CF),Bytes.toBytes(del)); } inbox_Table.delete(uid_Inbox_Delete); inbox_Table.close(); relation_Table.close(); connection.close(); } // 4.获取初始化界面 public static void getInit(String uid) throws IOException { // 获取Connection对象 Connection connection = ConnectionFactory.createConnection(NConstants.CONFIGURATION); // 获取收件箱对象,内容对象 Table inbox_table = connection.getTable(TableName.valueOf(NConstants.INBOX_TABLE)); Table content_table = connection.getTable(TableName.valueOf(NConstants.CONTENT_TABLE)); // 创建收件箱Get对象,并设置版本 Get uid_get = new Get(Bytes.toBytes(uid)); uid_get.setMaxVersions(NConstants.INBOX_TABLE_VERSIONS); // 获取收件箱内容 Result uid_inbox_results = inbox_table.get(uid_get); for (Cell cell : uid_inbox_results.rawCells()) { // 构建微博内容表的对象 Get content_result = new Get(CellUtil.cloneValue(cell)); Result ct_result = content_table.get(content_result); // 解析并打印内容 for (Cell ctCell : ct_result.rawCells()) { System.out.println("RK:"+Bytes.toString(CellUtil.cloneRow(ctCell))+"\t"+ "CF:"+Bytes.toString(CellUtil.cloneFamily(ctCell))+"\t"+ "CN:"+Bytes.toString(CellUtil.cloneQualifier(ctCell))+"\t"+ "Value:"+Bytes.toString(CellUtil.cloneValue(ctCell))+"\t"); } } content_table.close(); inbox_table.close(); connection.close(); } // 5.获取某个人的所有web详情 public static void getWebDetails(String uid) throws IOException { Connection connection = ConnectionFactory.createConnection(NConstants.CONFIGURATION); Table content_table = connection.getTable(TableName.valueOf(NConstants.CONTENT_TABLE)); // 构建Scan对象 Scan scan = new Scan(); // 构建过滤器 RowFilter rowFilter = new RowFilter(CompareFilter.CompareOp.EQUAL, new SubstringComparator(uid + "_")); scan.setFilter(rowFilter); // 获取内容 ResultScanner resultScanner = content_table.getScanner(scan); for (Result results : resultScanner) { for (Cell cell : results.rawCells()) { System.out.println("RK:"+Bytes.toString(CellUtil.cloneRow(cell))+"\t"+ "CF:"+Bytes.toString(CellUtil.cloneFamily(cell))+"\t"+ "CN:"+Bytes.toString(CellUtil.cloneQualifier(cell))+"\t"+ "Value:"+Bytes.toString(CellUtil.cloneValue(cell))+"\t"); } } // 关闭资源 content_table.close(); connection.close(); } }
7.3.4 Test
-
TWeb
package com.nuochengze.test; import com.nuochengze.constants.NConstants; import com.nuochengze.dao.NHBaseDao; import com.nuochengze.utils.NHBaseUtil; import java.io.IOException; public class TWeb { public static void init() { try { // 创建命名空间 NHBaseUtil.createNameSpace(NConstants.NAMESPACE); // 创建微博内容表 NHBaseUtil.createTable(NConstants.CONTENT_TABLE, NConstants.CONTENT_TABLE_VERSIONS, NConstants.CONTENT_TABLE_CF); // 创建用户关系表 NHBaseUtil.createTable(NConstants.RELATION_TABLE, NConstants.RELATION_TABLE_VERSIONS, NConstants.RELATION_TABLE_CF1, NConstants.RELATION_TABLE_CF2); // 创建收件箱表 NHBaseUtil.createTable(NConstants.INBOX_TABLE, NConstants.INBOX_TABLE_VERSIONS, NConstants.INBOX_TABLE_CF); } catch (IOException e) { e.printStackTrace(); } } public static void main(String[] args) throws IOException, InterruptedException { // 初始化 init(); // 1001发布微博 NHBaseDao.publishWeb("1001","这是1001发布的第一条微博"); // 1002关注1001和1003 NHBaseDao.addAttends("1002","1001","1003"); // 1002页面初始化 System.out.println("****** 1002页面初始化 [1] ******"); NHBaseDao.getInit("1002"); // 1003发布3条微博,同时1001发布2条微博 NHBaseDao.publishWeb("1003","这是1003发布的第一条微博"); Thread.sleep(10); NHBaseDao.publishWeb("1003","这是1003发布的第二条微博"); Thread.sleep(10); NHBaseDao.publishWeb("1003","这是1003发布的第三条微博"); Thread.sleep(10); NHBaseDao.publishWeb("1002","这是1002发布的第一条微博"); Thread.sleep(10); NHBaseDao.publishWeb("1002","这是1002发布的第二条微博"); Thread.sleep(10); // 1002页面初始化 System.out.println("****** 1002页面初始化 [2] ******"); NHBaseDao.getInit("1002"); // 1002取关1003 NHBaseDao.deleteAttends("1002","1003"); // 1002页面初始化 System.out.println("****** 1002页面初始化 [3] ******"); NHBaseDao.getInit("1002"); // 1002再次关注1003 NHBaseDao.addAttends("1002","1003"); // 1002页面初始化 System.out.println("****** 1002页面初始化 [4] ******"); NHBaseDao.getInit("1002"); // 获取1001微博详情 System.out.println("****** 获取1001微博详情 [1] ******"); NHBaseDao.getWebDetails("1001"); } }
