
六、HDFS
1 HDFS的定义
HDFS(Hadoop Distributed File System),是一个分布式的目录树文件系统,适合用一次写入多次读出的场景。
2 HDFS的优缺点
2.1 优点
-
高容错性
数据自动保存多个副本,即通过增加副本的形式,提高容错性。
-
适合处理大数据
- 数据规模:可达PB级别的数据
- 文件规模:能够处理百万规模以上的文件数量
-
可构建在廉价机器上,通过多副本机制,提高可靠性
2.2 缺点
- 不适合低延时数据访问
- 无法高效的对大量小文件进行存储
- 不支持并发写入,文件随机修改
- 一个文件只能有一个写,不允许多个线程同时写
- 仅支持数据append(追加),不支持文件的随机修改
3 HDFS的组成
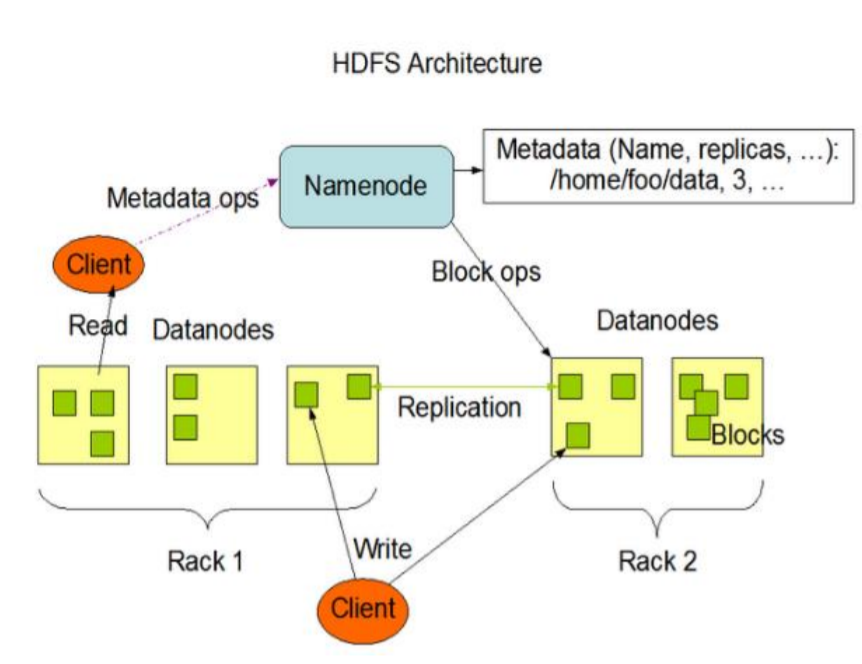
3.1 NameNode(nn)
- 名义上的Master,是一个管理者
- 管理HDFS的名称空间
- 配置副本策略
- 管理数据块(Block)映射信息
- 处理客户端读写请求
3.2 DataNode
- 名义上的Slave,是一个执行者
- 存储实际的数据块
- 执行数据快的读/写操作
3.3 Client
- 客户端
- 文件切分,文件上传HDFS的时候,Client将文件切分成一个一个的Block,然后进行上传,文件块大小常为128MB
- 与NameNode交互,获取文件的位置信息(元信息)
- 与DataNode交互,读取或者写入数据
- Client提供一些命令来管理HDFS,例如对NameNode的格式化
- Client提供一些命令来访问HDFS,例如对HDFS增删改查操作
3.4 Secondary NameNode
- 它不是NameNode的热备份,两者之间存在差异,当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务
- 辅助NameNode,分担其工作量,如定期合并Fsimage和Edits,并推送给NameNode
- 在紧急情况下,可辅助恢复NameNode
3.5 图例
4 HDFS的shell操作
4.1 基本语法
(1)hadoop fs 具体命令
(2)hdfs dfs 具体命令
4.2 使用方式
hadoop fs -help
5 HDFS的API操作
5.1 环境准备
-
需要准备HADOOP_HOME
5.2 Maven环境创建
-
idea激活
-
在idea中创建工程,选择Maven,输入对应的路径信息
-
修改pom.xml文件,增加如下标注内容
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.example</groupId> <artifactId>HdfsClient</artifactId> <version>1.0-SNAPSHOT</version> <properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> </properties> <!--以下内容为增加内容--> <dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.2.2</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.30</version> </dependency> </dependencies>> </project> -
在项目
/src/main/resources目录下创建新文件log4j.properties,文件内容如下log4j.rootLogger=INFO,stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.File=target/spring.log log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
5.3 HdfsClient类创建
-
创建包
com.example.hdfs -
在包
com.example.hdfs中创建Class类HdfsClient说明:(1)客户端去操作HDFS时,需要用户身份,如
rootpackage com.example.hdfs; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.junit.After; import org.junit.Before; import org.junit.Test; import java.io.IOException; import java.net.URI; import java.net.URISyntaxException; /* * 客户端代码常用套路 * 1、获取一个客户端对象 * 2、执行相关的操作命令 * 3、关闭资源 * HDFS zookeeper * */ public class HdfsClient { private FileSystem fs; @Before public void init() throws URISyntaxException, IOException,InterruptedException { // 1 创建连接的集群NameNode地址 URI uri = new URI("hdfs://192.168.117.11:8082"); // 2 创建一个配置文件 Configuration configuration = new Configuration(); // 3 用户 String user = "root"; // 4 获取客户端对象 fs = FileSystem.get(uri,configuration,user); } @After public void close() throws IOException{ fs.close(); } @Test public void TestMkdirs() throws Exception{ // 创建目录 fs.mkdirs(new Path("/xiyou/huaguoshan/")); } @Test public void TestPut() throws Exception{ // 参数一:表示删除原数据 // 参数二:表示是否允许覆盖 // 参数三:原数据路径 // 参数四:目标路径 fs.copyFromLocalFile(false,false,new Path("/home/nuochengze/workstation/test/sunwukong.txt"),new Path("hdfs://192.168.117.11:8082/xiyou/huaguoshan")); } }
6 HDFS的读写流程
6.1 HDFS写数据流程
-
图例
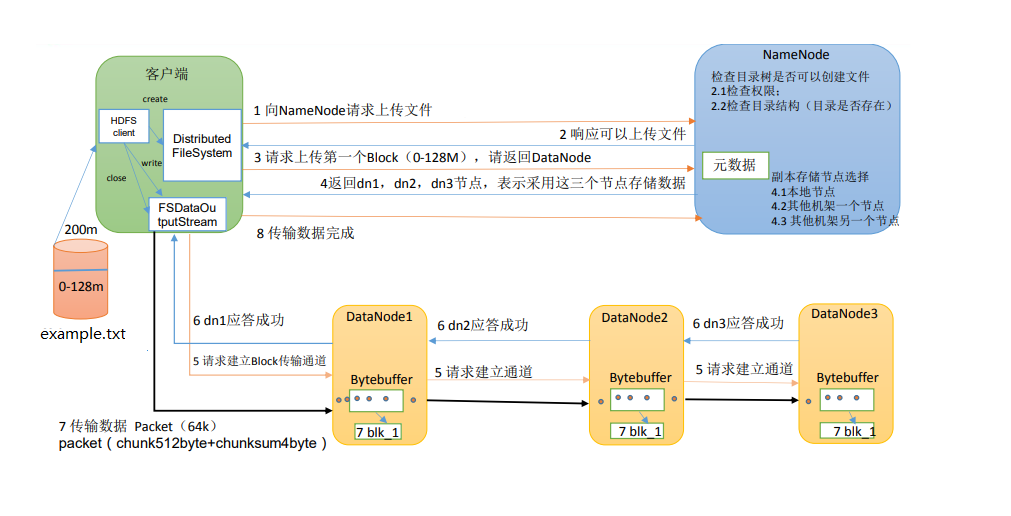
-
图例说明
- Client通过Distributed FileSystem 向 NameNode 请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在
- NameNode返回给Client,告知是否可以上传
- Client向NameNode请求上传第一个Block,此时NameNode按规则检查节点
- NameNode返回Client能够存储数据的DataNode信息
- Client通过FSDataOutputStream 请求DataNode1上传数据,DataNode1成功建立通道后,调用DataNode2建立通道,然后DataNode2调用DataNode3建立通道,依次类推
- DataNode1,DataNode2,DataNode3逐级应答客户端
- Client在收到DataNode1的应答后,生成ack队列(存放下级应答成功的信息),之后开始往DataNode1上传第一个Block(先从磁盘读取数据并放到一个本地内存缓存),以Packet为单位(512Byte的chunk+4Byte的chunk校验,满64KB为止),DataNode1收到一个Packet后,传递给DataNode2,DataNode2依次传递给DataNode3;
- 当一个Packet传输完成,DataNode3返回应答给DataNode2,DataNode2返回应答给DataNode1,DataNode1返回应答给Client,此时从ack应答缓冲队列中删除该Packet备份,否则,DataNode1重新传输该Packet,直到完成Packet的传输
- 当一个Block传输完成之后,客户端再次请求NameNode1上传第二个Block的服务
-
其他说明
- 节点距离:两个节点到达最近的共同祖先的距离总和。
- 在HDFS写数据的过程中,NameNode会选择距离待上传数据最近距离的DataNode接收数据
6.2 HDFS读数据流程
-
图例
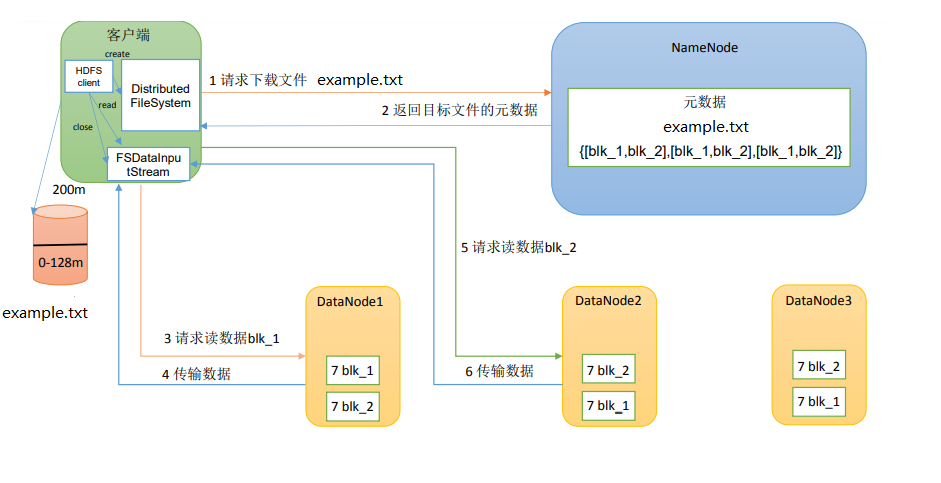
-
图例说明
- Client通过DistributedFileSystem,向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址
- Client按距离优先,负载优先的顺序,请求读取数据
- DataNode开始传输数据给Client(从磁盘里面读取数据输入流,以Packet为单位来做校验)
- Client以Packet为单位接收,现在本地缓存,然后写入目标文件
-
其他说明
- 数据读取时,并行读取后将数据拼接,返回给Client
7 NameNode和SecondaryNameNode
7.1 工作流程
-
图例
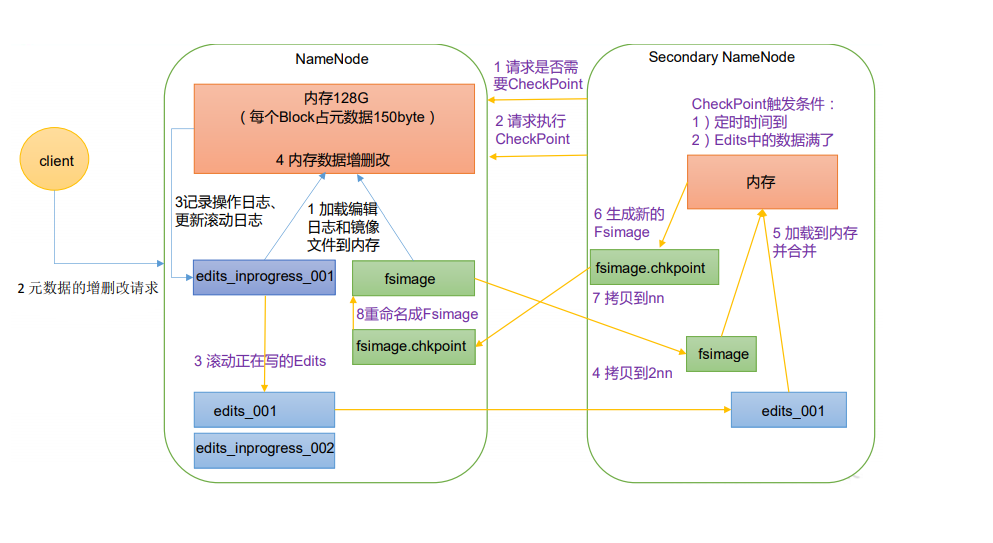
-
图例说明1
- FsImage文件,备份元数据,只存放计算出的结果
- Edits文件,存放操作的步骤
- SecondaryNameNode,专门用于FsImage和Edits的合并
-
图例说明2
- 第一阶段,NameNode启动
- 第一次启动NameNode格式化后,创建FsImage和Edits文件。非第一次启动,直接加载编辑日志和镜像文件到内存
- 客户端对元数据进行增删改请求
- NameNode记录操作日志,更新滚动日志,即往Edits文件中追加数据
- NameNode在内存中对元数据进行增删改
- 第二阶段,SecondaryNameNode工作
- SecondaryNameNode询问NameNode是否需要CheekPoint,直接带回NameNode是否检查结果的应答
- SecondaryNameNode请求执行CheckPoint
- NameNode滚动正在写的Edits日志,即将CheckPoint之后的操作日志记录在新创建的edits_inproress_002文件中,同时edits_inprogress_001文件更名为edits_001
- 将滚动钱的编辑日志edits_001和镜像文件FsImage拷贝到SecondaryNameNode
- 在内存中生成新的fsimage.chkpoint
- 拷贝fsimage.chkpoint到NameNode,并将其命名为fsimage,替代掉旧的fsimage
- 第一阶段,NameNode启动
7.2 Fsimage和Edits解析
-
Fsimage和Edits的概念
NameNode被格式化后,在
$HADOOP_HONE/data/tmp/dfs/name/current目录中产生如下文件: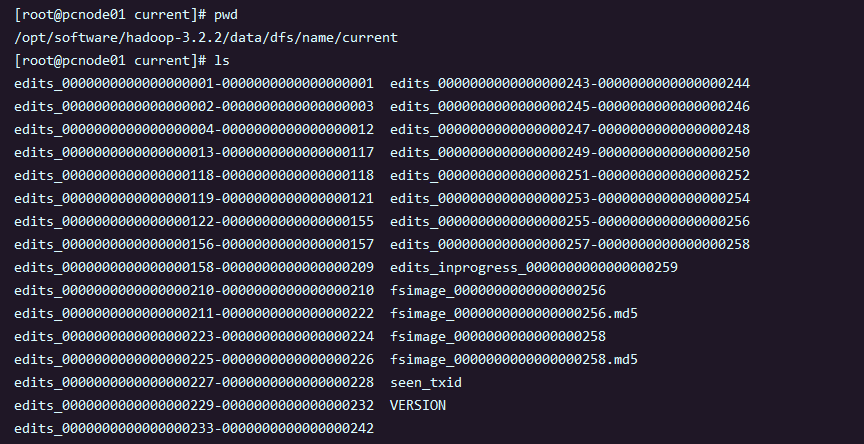
- Fsimage文件:HDFS文件系统元数据的一个永久性的检查点,其中包含HDFS文件系统的所有目录和文件inode的序列化信息
- Edits文件:存放HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到Edits文件中
- seen_txid文件:保存最后一个edits_的数字
- 每次NameNode启动的时候都会将Fsimage文件读入内存中,加载Edits里面的更新操作,保证内存中的元数据信息是最新的、同步的,可以将NameNode启动的时候加载的文件,看成是Fsimage和Edits文件的合并
- 在Fsimage中没有记录块所对应的DataNode,因为在集群启动后,NameNode要求DataNode上报数据块信息,并间隔一段时间后再次上报
-
oiv查看Fsiamge文件
-
基本语法
hdfs oiv -p 文件类型 -i 镜像文件 -o 转换后文件输出路径example:
hfds oiv -p XML -i $HADOOP_HOME/,,,/fsimage_xxx -o /.../fsimage.xml
-
-
oev查看Edits文件
-
基本语法
hdfs oev -p 文件类型 -i 编辑日志 -o 转换后文件输出路径example:
hfds oev -p XML -i $HADOOP_HOME/,,,/edits_xxx -o /.../edits.xml
-
7.3 CheckPoint时间设置
-
通常的情况下,SecondaryNameNode每隔一个小时执行一次
[hdfs-default.xml] <property> <name>dfs.namenode.checkpoint.period</name> <value>3600s</value> </property> -
一分钟检查一次操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次
[hdfs-default.xml] <property> <name>dfs.namenode.checkpoint.txns</name> <value>1000000</value> </property> <property> <name>dfs.namenode.checkpoint.check.period</name> <value>60s</value> </property>
8 DataNode
8.1 DataNode工作机制
-
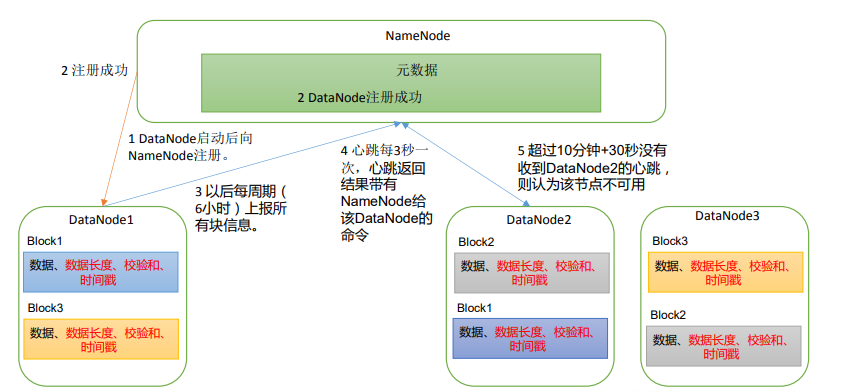
图例
-
图例说明
-
一个数据块在DataNode上以文件形式存储在磁盘上,包括:数据本身,元数据(数据块的长度,数据块的校验和,时间戳等)
-
DataNode启动后向NameNode注册,通过后,周期性(6小时)的向NameNode上报所有的块信息
[hdfs-default.xml] <property> <name>dfs.blockreport.intervalMsec</name> <value>21600000</value> <description>DataNode向NameNode汇报当前解读信息的时间间隔,默认为6小时</description> </property> <property> <name>dfs.datanode.directoryscan.interval</name> <value>21600000</value> <description>DataNode扫描自己节点块信息列表的时间,默认为6小时</description> </property> -
心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令(如复制块数据,或删除块数据)。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用
-
集群运行中可以安全加入和退出一些机器
参考:https://www.cnblogs.com/nuochengze/p/14883874.html#7-集群启动停止方式总结
-
8.2 数据完整性
DataNode节点保证数据完整性的方式:
- 当DataNode读取Block的时候,会计算出文件的CheckSum
- 如果计算传输过来的CheckSum,与Block创建时值不一样,说明Block已经损坏
- 此时Client会读取其他DataNode上的Block,来保证数据传输的完整性
- 常见的校验算法crc(32),md5(128),sal1(160)
- DataNode在其文件创建后周期验证CheckSum
8.3 掉线时限参数设置
-
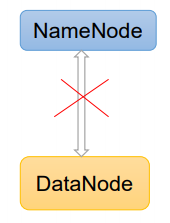
图例
-
图例说明
-
DataNode进行死亡或者网络故障造成DataNode无法与NameNode通信
-
NameNode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长
-
HDFS默认的超时时长为10分钟+30秒
-
如果定义超时时长为TimeOut,则超时时长的计算公式为:
TimeOut = 2 * dfs.namenode.heartbeat.recheck-interval + 10*dfs.heartbeat.interval
- 默认的dfs.namenode.heartbeat.recheck-interval大小为5分钟
- 默认的dfs.heartbeat.interval为3秒
-
hdfs-site.xml配置文件中dfs.namenode.heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒
[hdfs-default.xml] <property> <name>dfs.namenode.heartbeat.recheck-interval</name> <value>300000</value> </property> <property> <name>dfs.heartbeat.interval</name> <value>3</value> </property>
-

