
当当图书信息爬取
效果:
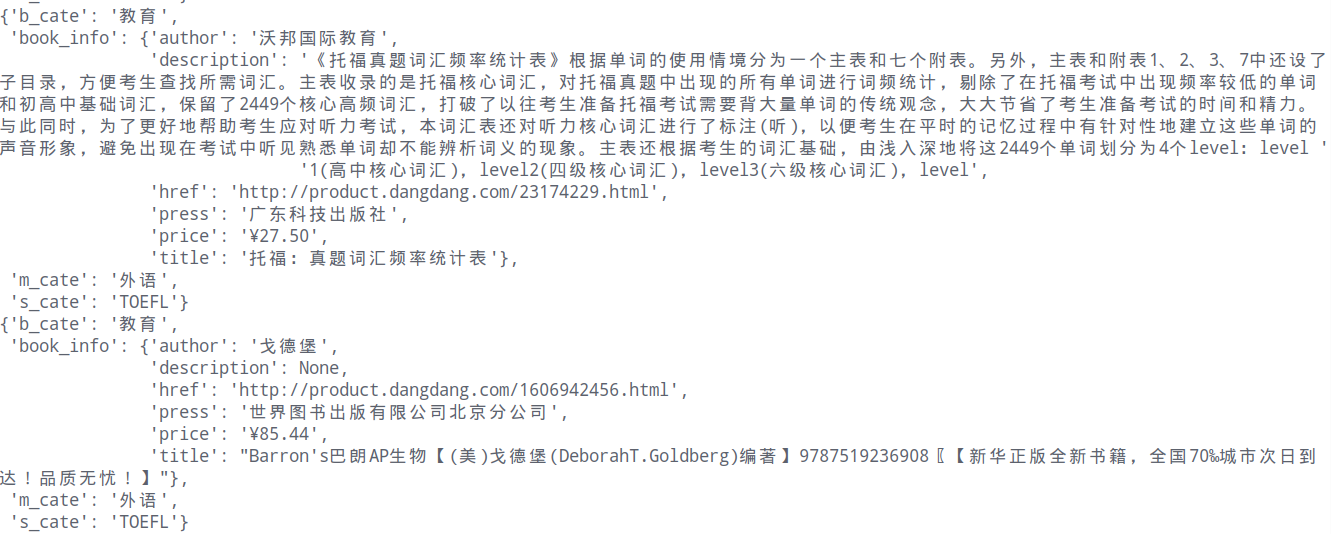
分析:
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
version_0
声明:未经许可,不能作为商业用途
总结:通过//div[@class="xxx"]可能取到的数据是不全面的,这时候不妨考虑使用//div[contains(@calss,'xxx')]的方式来提取
如果通过re模块去提取数据,在首页(book.dangdang.com/index)取获取分类信息的时候,会提示errordecode,
这是因为当当图书在网页中插入了别国字符导致编码不统一的问题。
当当网在获取图书信息,翻页时,未采用任何动态技术,通过价格也是直接嵌入在网页上的,这个就比较容易获取到。
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
源码
# -*- coding: utf-8 -*- import scrapy import re from copy import deepcopy from pprint import pprint from urllib import parse class DdtsSpider(scrapy.Spider): name = 'ddts' allowed_domains = ['dangdang.com'] start_urls = ['http://book.dangdang.com/index'] def process_info(self,con_list): """传入一个列表,处理空字符串并将字段拼接在一起""" con_list = [re.sub(r"\s|\n", '', i).strip() for i in con_list if i] s = str() for a_ in con_list: s += a_ return s def parse(self, response): div_cate_list = response.xpath("//div[@class='con flq_body']//div[contains(@class,'level_one')]") # 去掉空字符串,去掉当当出版 div_cate_list = div_cate_list[2:13]+div_cate_list[14:-4] for div_cate in div_cate_list: item = dict() # 获取大分类标题 # 提取标题部分 item["b_cate"] = div_cate.xpath(".//dl[contains(@class,'primary_dl')]/dt//text()").extract() item["b_cate"] = self.process_info(item["b_cate"]) # 拿到所有弹出层列表 t_list = div_cate.xpath(".//dl[contains(@class,'inner_dl')]") for t in t_list: # 获取中级标题 item["m_cate"] = t.xpath(".//dt//text()").extract() item["m_cate"] = self.process_info(item["m_cate"]) # 获取小分类及地址 a_list = t.xpath(".//dd/a") for a in a_list: item["s_cate"] = a.xpath("./text()").extract() item["s_cate"] = self.process_info(item["s_cate"]) s_href = a.xpath("./@href").extract_first() # 请求小分类的地址 yield scrapy.Request( url = s_href, callback=self.parse_s_cate, meta={"item":deepcopy(item)} ) def parse_s_cate(self,response): item = deepcopy(response.meta["item"]) # 选取图书列表 book_li_list = response.xpath("//div[contains(@id,'search_nature_rg')]/ul[contains(@class,'bigimg')]/li") # 当前请求的url包含该页面下所有的请求,无任何动态加载 for book_li in book_li_list: book_info = dict() book_info["title"] = book_li.xpath(".//p[contains(@class,'name')]//a/@title").extract() book_info["title"] = self.process_info(book_info["title"]) book_info["href"] = book_li.xpath(".//p[contains(@class,'name')]//a/@href").extract_first() book_info["price"] = book_li.xpath(".//p[contains(@class,'price')]//span[contains(@class,'earch_now_price')]/text()").extract_first() book_info["price"] = book_info["price"].split(r";",1)[-1] book_info["author"] = book_li.xpath(".//a[contains(@name,'itemlist-author')]/text()").extract_first() book_info["press"] = book_li.xpath(".//a[contains(@name,'P_cbs')]/text()").extract_first() book_info["description"] = book_li.xpath(".//p[contains(@class,'detail')]//text()").extract_first() item["book_info"] = book_info pprint(item) url = response.xpath("//li[@class='next']/a/@href").extract_first() if url is not None: next_url = parse.urljoin(response.url,url) yield scrapy.Request( url=next_url, callback=self.parse_s_cate, meta={"item":response.meta["item"]} )

