苏宁图书信息爬取
效果如下:

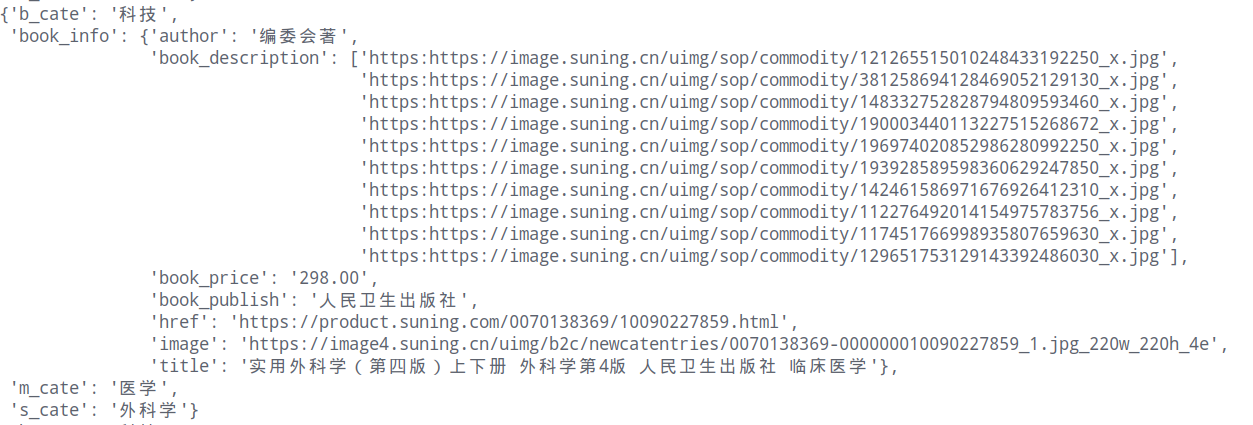
文档说明:
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
version_1
下页完美请求到了,果然世上无难事,只要敢放弃。
下页的构造请求应该请求静态接口,这样既会正确返回数据,而且数据也是完整的
总结:有时候在构造url的时候,不妨多删几个参数,在浏览器中尝试,排除非相关参数
current_page = re.findall(r'param.currentPage = "(.*?)";', response.body.decode(), re.S)
current_page = int(current_page[0]) if current_page else -1
# page_numbers = int(re.findall(r'param.pageNumbers = "(.*?)";', response.body.decode(), re.S)[0])
page_numbers = re.findall(r'param.pageNumbers = "(.*?)";', response.body.decode(), re.S)
page_numbers = int(page_numbers[0]) if page_numbers else -1
print("*"*50)
print("current_page:%s,page_numbers:%s"%(current_page,page_numbers))
print("*"*50)
ci = int(re.findall(r"cateid':\'(.*?)\'",response.body.decode(),re.S)[0])
url = "https://list.suning.com/1-{}-{}.html" # 在浏览器端,后面加上一个页码编号,是可行的,但是当请求第4页时,就会抓不到数据
num = 1
# next_request_url = "https://list.suning.com/emall/showProductList.do?ci={}&pg=03&cp={}&il=0&iy=0&adNumber=0&n=1&ch=4&prune=0&sesab=ACBAABC&id=IDENTIFYING&cc=728"
while num < page_numbers:
yield scrapy.Request(
url = url.format(ci,num),
callback = self.parse_s_cate_href,
meta = {"item":deepcopy(response.meta["item"])}
)
num += 1
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
version_0
https://list.suning.com/1-502687-0.html页面分析
<script type="text/javascript">
if (typeof param != 'undefined') {
param.currentPage = "0";
param.pageNumbers = "100";
param.numFound = "27537";
if ("ssdln_502687" == "{pageType}") {
makeProductName($("#filter-results,#bottom_pager"));
}
param.mutil = false;
记住每个页面都有记录当页currentpage和pagenumbers
class = filter-results productMain clearfix temporary下为有用信息
分别有图书列表,和下一页拦
一定要要请求的url是否Filtered offsite request to 'list.suning.com':
分析价格的请求地址
https://product.suning.com/0071038629/11855521483.html
https://product.suning.com/0071014399/11516769347.html
https://pas.suning.com/nspcsale_0_000000011516769347_000000011516769347_0071014399_
170_728_7280100_502282_1000149_9149_11181_Z001___R9011205_3.0________0___0.0_2_.html
https://product.suning.com/0071038629/11855521483.html
https://pas.suning.com/nspcsale_0_000000011855521483_000000011855521483_0071038629_
170_728_7280100_502282_1000149_9149_11181_Z001___R9011205_10.0________0___0.0_2_.html
https://product.suning.com/0070091633{shopid}/10717510914{prdid}.html
https://pas.suning.com/nspcsale_0_000000010717510914_000000010717510914_0070091633_
170_728_7280100_502282_1000149_9149_11181_Z001___R9011205_1.0________0___1.0_2_.html
# 构造请求价格的url
https://pas.suning.com/nspcsale_0_0000000{prdid}_0000000{prdid}_{shopid}_
170_728.html
小分类的下页分析
第一页 一个小分类下,有一个ci
ci的获取方式
https://list.suning.com/emall/showProductList.do?ci=502675&pg=03&cp=0&il=0&iy=0
&adNumber=0&n=1&ch=4&prune=0&sesab=ACBAABC&id=IDENTIFYING&paging=1&sub=0
第二页
第一次
https://list.suning.com/emall/showProductList.do?ci=502675&pg=03&cp=1&il=0&iy=0
&adNumber=0&n=1&ch=4&prune=0&sesab=ACBAABC&id=IDENTIFYING&cc=728
第二次
https://list.suning.com/emall/showProductList.do?ci=502675&pg=03&cp=1&il=0&iy=0
&adNumber=0&n=1&ch=4&prune=0&sesab=ACBAABC&id=IDENTIFYING&cc=728&paging=1&sub=0
第三页
第一次
https://list.suning.com/emall/showProductList.do?ci=502675&pg=03&cp=2&il=0&iy=0
&adNumber=0&n=1&ch=4&prune=0&sesab=ACBAABC&id=IDENTIFYING&cc=728
第二次
https://list.suning.com/emall/showProductList.do?ci=502675&pg=03&cp=2&il=0&iy=0
&adNumber=0&n=1&ch=4&prune=0&sesab=ACBAABC&id=IDENTIFYING&cc=728&paging=1&sub=0
翻页功能未实现,构造下页请求失败。
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
源码如下:
# -*- coding: utf-8 -*- import scrapy from copy import deepcopy import re from pprint import pprint import json class SntsSpider(scrapy.Spider): name = 'snts' allowed_domains = ['book.suning.com','list.suning.com','product.suning.com','pas.suning.com'] start_urls = ['https://book.suning.com/'] def parse(self, response): # with open("test.txt",'w',encoding='utf8') as f: # f.write(response.body.decode()) item = dict() # 获取大分类 b_cate_list = response.xpath("//div[@class='menu-list']//div[@class='menu-item']//h3/a") num = 1 # 计数 for b_cate in b_cate_list: item["b_cate"] = b_cate.xpath("./text()").extract_first() # 取大分类名字 # 获取中分类 # 每个大分类对应一个右边的展开,一一对应 menu_sub_one = response.xpath("//div[@class='menu-list']//div[@class='menu-sub'][{}]".format(num)) # 获取展开的左边 submenu_left = menu_sub_one.xpath(".//div[@class='submenu-left']") # 获取p_list p_list = submenu_left.xpath("./p[@class='submenu-item']") # num_计数 num_ = 1 for p in p_list: item["m_cate"] = p.xpath("./a/text()").extract_first() # 获取中标题 # 获取中标题下的小标题分类 s_cate_list = submenu_left.xpath("./ul[@class='book-name-list clearfix'][{}]/li".format(num_)) for s_cate in s_cate_list: item["s_cate"] = s_cate.xpath("./a/text()").extract_first() s_cate_href = s_cate.xpath("./a/@href").extract_first() yield scrapy.Request( url=s_cate_href, callback=self.parse_s_cate_href, meta={"item":deepcopy(item)} ) num_ += 1 num += 1 def parse_s_cate_href(self, response): item = deepcopy(response.meta["item"]) item["book_info"] = dict() # 获取有用信息,分别包含图书图书列表和下一页地址,当前页信息currentPage和总页数信息pageNumbers可通过re提取 useful_info = response.xpath("//div[@class='filter-results productMain clearfix temporary']") # print(useful_info) # 定位图书列表 book_li_list = useful_info.xpath(".//ul[@class='clearfix']/li") # 拿到图书标题,图片信息和地址 for book_li in book_li_list: item["book_info"]["title"] = book_li.xpath(".//div[@class='res-img']/div[@class='img-block']/a/img/@alt").extract_first() item["book_info"]["image"] = book_li.xpath(".//div[@class='res-img']/div[@class='img-block']/a/img/@src2").extract_first() item["book_info"]["image"] = "https:"+item["book_info"]["image"] if item["book_info"]["image"] else None item["book_info"]["href"] = book_li.xpath(".//div[@class='res-img']/div[@class='img-block']/a/@href").extract_first() item["book_info"]["href"] = "https:"+item["book_info"]["href"] yield scrapy.Request( url = item["book_info"]["href"], callback = self.parse_book_href, meta = {"item":deepcopy(item)} ) # 以下内容未成功,再接再厉 # 构造下一页的请求 # 说明,如果请求showProductList.do?ci=502675*只能拿到前段或后断的数据 # 但是通过https://list.suning.com/1-502675-4-0-0-0-0-0-0-4.html这种方式,可以拿到全部的数据,但是构造困难 # pageNumbers = re.findall(r'param.pageNumbers = "(.*?)";',response.body.decode(),re.S) # pageNumbers = int(pageNumbers[0]) if pageNumbers else -1 # nextPage = re.findall(r'param.currentPage = "(.*?)";', response.body.decode(), re.S) # nextPage = int(nextPage[0]) + 1 if nextPage else 1 # print("nextPage:",nextPage) # print("pageNumbers:",pageNumbers) # # url = re.findall(r"") # next_url = "https://list.suning.com/1-502697-{}-0-0-0-0-0-0-4.html" # while nextPage<pageNumbers: # yield scrapy.Request( # url = next_url.format(nextPage), # callback = self.parse_s_cate_href, # meta = {"item":deepcopy(item)} # ) # pageNumbers = int(re.findall(r'param.pageNumbers = "(.*?)";',response.body.decode(),re.S)[0]) # # pageNumbers = int(pageNumbers[0]) if pageNumbers else -1 # nextPage = int(re.findall(r'param.currentPage = "(.*?)";', response.body.decode(), re.S)[0])+1 # # nextPage = int(nextPage[0]) + 1 if nextPage else 1 # print("nextPage:",nextPage) # print("pageNumbers:",pageNumbers) # # 拿到ci # ci = re.findall(r"cateid':\'(.*?)\'",response.body.decode(),re.S)[0] # print(ci) # # # 请求上半部分数据,cp即当前的页数 # body ={ # "Referer":response.url # } next_url_up = "https://list.suning.com/emall/showProductList.do?ci=502687&pg=03&cp=0&il=0&iy=0&adNumber=0&n=1&ch=4&prune=0&sesab=ACBAABC&id=IDENTIFYING&cc=728&paging=1&sub=0" # while nextPage<pageNumbers: # yield scrapy.Request( # url = next_url_up.format(ci,nextPage), # callback = self.parse_s_cate_href, # meta = {"item":deepcopy(item)} # ) # while nextPage<pageNumbers: # yield scrapy.Request( # url = next_url_up.format(nextPage), # callback = self.parse_s_cate_href, # body = json.dumps(body), # meta = {"item":deepcopy(item)} # ) # # 请求上半部分数据 # next_url_down = "" # while nextPage<pageNumbers: # yield scrapy.Request( # url = next_url_down.format(ci,nextPage), # callback = self.parse_s_cate_href, # meta = {"item":deepcopy(item)} # ) def parse_book_href(self,response): item = response.meta["item"] item["book_info"]["author"] = response.xpath("//ul[@class='bk-publish clearfix']/li[1]/text()").extract_first() item["book_info"]["author"] = re.sub(r'\r+|\t+|\n+|\|', "", item["book_info"]["author"].strip()) if item["book_info"]["author"] else None item["book_info"]["book_publish"] = response.xpath("//ul[@class='bk-publish clearfix']/li[2]/text()").extract_first() item["book_info"]["book_publish"] = item["book_info"]["book_publish"].strip() if item["book_info"]["book_publish"] else None item["book_info"]["book_description"] = response.xpath("//img[@onload='if(this.width>750){this.height=this.height*(750.0/this.width); this.width = 750;}']/@src2").extract() item["book_info"]["book_description"] = ["https:"+i for i in item["book_info"]["book_description"]] if item["book_info"]["book_description"] else None shopid, prdid = zip(re.findall(r'com/(.*?)/(.*?)\.html',response.url,re.S)[0]) price_url = 'https://pas.suning.com/nspcsale_0_0000000{}_0000000{}_{}_170_728.html'.format(prdid[0],prdid[0],shopid[0]) yield scrapy.Request( url = price_url, callback = self.parse_price, meta = {"item":deepcopy(item)} ) def parse_price(self,response): item = response.meta["item"] item["book_info"]["book_price"] = re.findall(r'"promotionPrice":"(.*?)"', response.body.decode(), re.S)[0] pprint(item)

