
十五、Python 多任务-线程、进程和协程(迭代器、生成器)
1、线程
并发:指的是任务数多余cpu核数,通过操作系统的各种任务调度算法,实现用多任务‘’一起“执行。(实际上总有一些任务不在执行,因为切换速度很快,看似一起执行)
并行:指的是任务数小于等于cpu核数,即任务真的是一起执行的。
创建线程时,除了以下两种方法,还可以使用线程池的方法。
from multiprocessing.dummy import Pool # 实现线程池需要借助于multiprocessing下的dummy模块 def proc_some(args): pass if __name__=="__main__": pool = Pool(2) str_list = list() results = pool.map(proc_some,str_list) print(results)
1.1 创建线程
python通过threading模块实现线程控制
import time import threading def test1(def_name): for i in range(2): print('这是一个线程测试:%s,编号为 %d' % (def_name,i)) time.sleep(1) def test2(def_name): for i in range(2): print('这是一个线程测试:%s,编号为 %d' % (def_name,i)) time.sleep(1) def main(): print('开始 {}'.format(time.ctime())) # 通过threading模块的Thread类创建一个线程对象 # 这个对象接收两个参数,target=目标函数名,args为元组,包含传入函数的所有参数 t1 = threading.Thread(target=test1,args=('test1',)) t2 = threading.Thread(target=test2,args=('test2',)) # 当调用start()时,才会真正的创建线程,并且开始执行 t1.start() t2.start() # 查看线程数 while True: length = len(threading.enumerate()) # print('线程名:{}'.format(threading.enumerate())) print('当前运行的线程数为:{}'.format(length)) if length<=1: break time.sleep(5) # 主线程会等待所有的子线程结束后才结束 print('结束 {}'.format(time.ctime())) if __name__=='__main__': main()
1.2 线程执行代码的封装
使用threading模块时,可以定义一个新的子类class,需要继承threading.Thread,并重写__inti__方法和run方法。
python的threading.Thread类有一个run方法,用于定义线程的功能函数,可以在自己的线程类中覆盖该方法。
创建子类实例后,通过Thread类的start方法,可以启动该线程,交给虚拟机进行调度,当该线程获得执行的机会时,就会调用run方法执行线程。
线程的执行顺序不能确定。
当线程的run()方法结束时该线程完成。
import threading import time class MyThread(threading.Thread): def run(self): for i in range(3): time.sleep(1) # python会自动为线程制定一个名字,通过self.name调用 msg = "I'm "+self.name+' @ '+str(i) print(msg) def test(): for i in range(5): t = MyThread() t.start() if __name__ == '__main__': test()
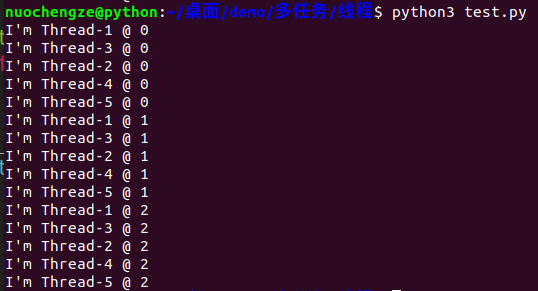
1.3 多线程共享全局变量
在一个进程内的所有线程共享全局变量,很方便在多个线程间共享数据。
缺点是:线程对全局变量随意改动可能造成多线程之间的全局变量混乱,此时线程不安全。
如果多个线程同时对同一个全局变量操作,会出现资源竞争问题,从而数据结果会不正确。
from threading import Thread import time def work1(nums): nums.append(44) print("----in work1---",nums) def work2(nums): #延时一会,保证t1线程中的事情做完 time.sleep(1) print("----in work2---",nums) g_nums = [11,22,33] t1 = Thread(target=work1, args=(g_nums,)) t1.start() t2 = Thread(target=work2, args=(g_nums,)) t2.start()

1.4 同步
当多个线程几乎同时修改某一个共享数据的时候,需要进行同步控制
线程同步能保证多个线程安全访问竞争资源,最简单的同步机制是引入互斥锁。
互斥锁为资源引入一个状态:锁定/非锁定
当某个线程要更改共享数据时,先将其锁上,此时资源的状态为’锁定‘,其他线程不能更改,直到该线程释放资源,将资源的状态变成’非锁定‘,其他的线程才能再次锁定该资源。
互斥锁保证了每次只有一个线程进行写入操作,从而保证了多线程情况下数据的正确性。
对于Lock对象而言,如果一个线程连续两次进行acquire操作,那么由于第一次acquire之后没有release,第二次acquire将挂起线程,这会导致Lock对象永远不会release,使得线程死锁。RLock对象允许一个线程多次对其进程acquire操作,因为在其内部通过一个counter变量维护着线程acquire的次数,而且每一次的acquire操作必须有一个release操作与之对应,在所有的release操作完成之后,别的线程才能申请该RLock对象。
threading模块中定义了Lock类,可以方便的处理锁定:
# 创建锁 mutex = threading.Lock() # 锁定 mutex.acquire() # 释放 mutex.release()
# 使用互斥锁完成2个线程对同一个全局变量各加100万次的操作 import threading import time g_num = 0 def test1(num): global g_num for i in range(num): mutex.acquire() # 上锁 g_num += 1 mutex.release() # 解锁 print("---test1---g_num=%d"%g_num) def test2(num): global g_num for i in range(num): mutex.acquire() # 上锁 g_num += 1 mutex.release() # 解锁 print("---test2---g_num=%d"%g_num) # 创建一个互斥锁 # 默认是未上锁的状态 mutex = threading.Lock() # 创建2个线程,让他们各自对g_num加1000000次 p1 = threading.Thread(target=test1, args=(1000000,)) p1.start() p2 = threading.Thread(target=test2, args=(1000000,)) p2.start() # 等待计算完成 while len(threading.enumerate()) != 1: time.sleep(1) print("2个线程对同一个全局变量操作之后的最终结果是:%s" % g_num)

1.5 案例:多线程聊天器
import threading import socket def recv_message(udp_socket): while True: recv_data = udp_socket.recvfrom(1024) print('接收到的消息:{}'.format(recv_data[0].decode('utf-8'))) def send_message(udp_socket,dest_addr): while True: send_data = input('请输入要发送的消息:') udp_socket.sendto(send_data.encode('utf-8'),dest_addr) def main(): """完成udp聊天器的整体控制""" # 创建套接字 udp_socket = socket.socket(socket.AF_INET,socket.SOCK_DGRAM) # 绑定本地地址 localaddr = ('',8081) udp_socket.bind(localaddr) # 获取对方的地址 dest_ip = input('请输入对方的ip:') dest_port = int(input('请输入对方的port:')) dest_addr = (dest_ip,dest_port) # 创建2个线程,去执行相应的功能 t_recv = threading.Thread(target=recv_message,args=(udp_socket,)) t_send = threading.Thread(target=send_message,args=(udp_socket,dest_addr)) t_recv.start() t_send.start() if __name__=='__main__': main()
2、进程
2.1 概念
进程:一个程序运行起来后,代码+用到的资源称为进程,它是操作系统分配资源的基本单位。
2.2 进程的状态
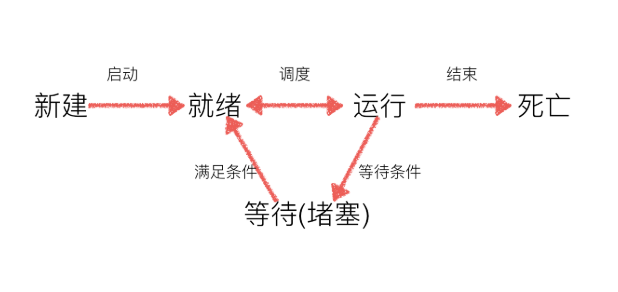
就绪态:运行的条件满足,正在等在cpu执行
执行态:cpu正在执行其功能
等待态:等待某些条件满足
2.3 进程的创建-multiprocessing
multiprocessing模块是多进程模块,提供了一个Process类来代表一个进程对象。
创建子进程时,只需要传入一个执行函数和函数的参数,创建一个Process实例,用start()方式启动。
from multiprocessing import Process import time def run_proc(): """子进程要执行的代码""" while True: print("---2---") time.sleep(1) if __name__=='__main__': p = Process(target=run_proc) p.start() while True: print('---1---') time.sleep(1)
2.4 进程pid
from multiprocessing import Process import os import time def run_proc(): """子进程要执行的代码""" print('子进程运行中,pid=%d...' % os.getpid()) # os.getpid获取当前进程的进程号 print('子进程将要结束...') if __name__ == '__main__': print('父进程pid: %d' % os.getpid()) # os.getpid获取当前进程的进程号 p = Process(target=run_proc) p.start() time.sleep(1) print('--父进程结束--')

2.5 Process语法结构如下:
Process(【group【,target【,name【,args【,kwargs】】】】】)
(1)target:如果传递了函数的引用,这个子进程就执行函数里的代码
(2)args:给target指定的函数传递的参数,以元组的方法传递
(3)kwargs:给target指定的函数传递命名参数
(4)name:给进程设定一个名字,可以不设定
(5)group:指定进程组,大多数情况下用不到
Process创建的实例对象的常用方法:
(1)start():启动子进程实例(创建子进程)
(2)is_alive():判断进程子进程是否还在活着
(3)join([timeout]):是否等待子进程执行结束,或等待多少秒
(4)terminate():不管任务是否完成,立即终止子进程
Process创建的实例对象的常用属性:
(1)name:当前进程的别名,默认为Process-N,N为从1开始递增的整数
(2)pid:当前进程的pid(进程号)
from multiprocessing import Process import os from time import sleep def run_proc(name, age, **kwargs): for i in range(10): print('子进程运行中,name= %s,age=%d ,pid=%d...' % (name, age, os.getpid())) print(kwargs) sleep(0.2) if __name__=='__main__': p = Process(target=run_proc, args=('test',18), kwargs={"m":20}) p.start() sleep(1) # 1秒中之后,立即结束子进程 p.terminate() p.join()
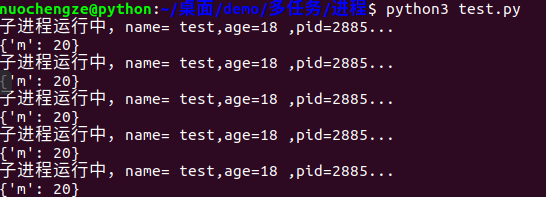
2.6 进程间不共享全局变量
2.7 进程间通信——Queue
2.7.0 Pipe的使用
Pipe常用来在两个进程间进行通信,两个进程分别位于管道的两端。
Pipe方法:`pipe = multiprocessing.Pipe()`,返回(conn1,conn2)代表一个管道的两个端。
Pipe方法有duplex参数,如果duplex参数为True(默认值),那么这个管道是全双工模式,也就是说conn1和conn2均可收发。当duplex为False,conn1只负责接收消息,conn2只负责发送消息。send和recv方法分别是发送和接收消息的方法。
在全双工模式下,可以调用conn1.send发送消息,conn1.recv接收消息。如果没有消息可接收,recv方法会一直阻塞,如果管道已经被关闭,那么recv方法会抛出EOFError。
import multiprocessing import random import time,os def proc_send(pipe,args): for arg_ in args: print("Process (%s) send: (%s)" % (os.getpid(),arg_)) pipe.send(arg_) time.sleep(random.random()) def proc_recv(pipe): while True: print("Process (%s) recv: %s" % (os.getpid(), pipe.recv())) time.sleep(random.random()) if __name__=="__main__": pipe = multiprocessing.Pipe() p1 = multiprocessing.Process(target=proc_send, args=(pipe[0], ["da_da_da{}".format(str(i)) for i in range(10)])) p2 = multiprocessing.Process(target=proc_recv, args=(pipe[1],)) p1.start() p2.start() p1.join() p2.join()
2.7.1 Queue的使用
可以使用multiprocessing模块的Queue实现多进程之间的数据传递,Queue本身是一个消息队列程序。
from multiprocessing import Queue q=Queue(3) #初始化一个Queue对象,最多可接收三条put消息 q.put("消息1") q.put("消息2") print("Queue队列是否已满:",q.full()) #False q.put("消息3") print("Queue队列是否已满:",q.full()) #True # 因为消息列队已满下面的try都会抛出异常,第一个try会等待2秒后再抛出异常, # 第二个Try会立刻抛出异常 try: q.put("消息4",True,2) except: print("消息列队已满,现有消息数量:%s"%q.qsize()) try: q.put_nowait("消息4") except: print("消息列队已满,现有消息数量:%s"%q.qsize()) #推荐的方式,先判断消息列队是否已满,再写入 if not q.full(): q.put_nowait("消息4") #读取消息时,先判断消息列队是否为空,再读取 if not q.empty(): for i in range(q.qsize()): print(q.get_nowait())

初始化Queue对象时(q=Queue()),若括号中没有指定最大可接收的消息数量,或数量为负值,那么就代表可接受的消息数量没有上限
Queue.qsize():返回当前队列包含的消息数量
Queue.empty():如果队列为空,返回True,反之False
Queue.full():如果队列满了,返回True,反之False
Queue.get([block[,timeout]]):获取队列中的一条消息,然后将其从队列中移除,block默认值为True
1)如果block使用默认值,且没有设置timeout(单位秒),消息列队如果为空,此时程序将被阻塞(停在读取状态),直到从消息列队读到消息为止,如果设置了timeout,则会等待timeout秒,若还没读取到任何消息,则抛出"Queue.Empty"异常;
2)如果block值为False,消息列队如果为空,则会立刻抛出"Queue.Empty"异常
Queue.get_nowait():相当于Queue.get(False)
Queue.put(item,[block[,timeout]]):将item消息写入队列,block默认为True
1)如果block使用默认值,且没有设置timeout(单位秒),消息列队如果已经没有空间可写入,此时程序将被阻塞(停在写入状态),直到从消息列队腾出空间为止,如果设置了timeout,则会等待timeout秒,若还没空间,则抛出"Queue.Full"异常
2)如果block值为False,消息列队如果没有空间可写入,则会立刻抛出"Queue.Full"异常
Queue.put_nowait(item):相当于Queue.put(item,False)
# 父进程中创建两个子进程,一个往Queue里写数据,一个从Queue里读数据
from multiprocessing import Process, Queue import os, time, random # 写数据进程执行的代码: def write(q): for value in ['A', 'B', 'C']: print('Put %s to queue...' % value) q.put(value) time.sleep(random.random()) # 读数据进程执行的代码: def read(q): while True: if not q.empty(): value = q.get(True) print('Get %s from queue.' % value) time.sleep(random.random()) else: break if __name__=='__main__': # 父进程创建Queue,并传给各个子进程: q = Queue() pw = Process(target=write, args=(q,)) pr = Process(target=read, args=(q,)) # 启动子进程pw,写入: pw.start() # 等待pw结束: pw.join() # 启动子进程pr,读取: pr.start() pr.join() # pr进程里是死循环,无法等待其结束,只能强行终止: print('') print('所有数据都写入并且读完')

2.8 进程池Pool
通过multiprocessing模块提供的Pool方法创建进程池
from multiprocessing import Pool import os, time, random def worker(msg): t_start = time.time() print("%s开始执行,进程号为%d" % (msg,os.getpid())) # random.random()随机生成0~1之间的浮点数 time.sleep(random.random()*2) t_stop = time.time() print(msg,"执行完毕,耗时%0.2f" % (t_stop-t_start)) print("----start----") po = Pool(3) # 定义一个进程池,最大进程数3 for i in range(0,10): # Pool().apply_async(要调用的目标,(传递给目标的参数元祖,)) # 每次循环将会用空闲出来的子进程去调用目标 po.apply_async(worker,(i,)) po.close() # 关闭进程池,关闭后po不再接收新的请求 po.join() # 等待po中所有子进程执行完成,必须放在close语句之后 print("-----end-----")
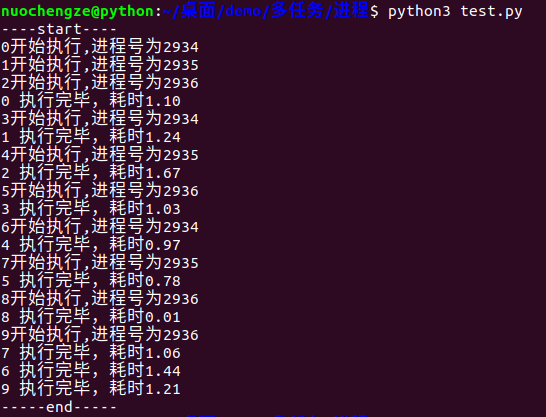
multiporcessing.Pool常用函数解析:
(1)apply_async(func[, args[, kwds]]) :使用非阻塞方式调用func(并行执行,堵塞方式必须等待上一个进程退出才能执行下一个进程),args为传递给func的参数列表,kwds为传递给func的关键字参数列表
(2)close():关闭Pool,使其不再接受新的任务
(3)terminate():不管任务是否完成,立即终止
(4)join():主进程阻塞,等待子进程的退出, 必须在close或terminate之后使用
进程池中的Queue
如果要使用Pool创建进程,就需要使用multiprocessing.Manager()中的Queue(),而不是multiprocessing.Queue(),否则会得到一条如下的错误信息:
RuntimeError: Queue objects should only be shared between processes through inheritance
# 修改import中的Queue为Manager from multiprocessing import Manager,Pool import os,time,random def reader(q): print("reader启动(%s),父进程为(%s)" % (os.getpid(), os.getppid())) for i in range(q.qsize()): print("reader从Queue获取到消息:%s" % q.get(True)) def writer(q): print("writer启动(%s),父进程为(%s)" % (os.getpid(), os.getppid())) for i in "itcast": q.put(i) if __name__=="__main__": print("(%s) start" % os.getpid()) q = Manager().Queue() # 使用Manager中的Queue po = Pool() po.apply_async(writer, (q,)) time.sleep(1) # 先让上面的任务向Queue存入数据,然后再让下面的任务开始从中取数据 po.apply_async(reader, (q,)) po.close() po.join() print("(%s) End" % os.getpid())

2.9 案例:多进程版本的文件夹复制器
https://www.cnblogs.com/nuochengze/p/12639596.html
3、协程
3.1 迭代器
迭代是访问集合元素的一种方式,迭代器是一个可以记住遍历的位置的对象,迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束,迭代器只能往前不会后退
可以通过for...in...这类语句迭代读取一条数据供我们使用的对象称之为可迭代对象(Iterable)。
使用isinstance(item,Iterable)判断一个对象是否是Iterable对象。
可迭代对象的本质:可迭代对象通过__iter__方法向我们提供一个迭代器,我们在迭代一个迭代对象的时候,实际上就是先获取该对象提供的一个迭代器,然后通过这个迭代器来依次获取对象中的每一个数据。
一个具备了__iter__方法的对象,就是一个可迭代对象。
通过iter()函数获取可迭代对象的迭代器,对获取到的迭代器不断使用next()函数来获取下一条数据。
iter()函数实际上就是调用了可迭代对象的__iter__方法。
迭代器用来帮助我们记录每次迭代访问到的位置,当我们对迭代器使用next()函数的时候,迭代器会向我们返回它所记录位置的下一个位置的数据。
next()函数实际上就是调用了迭代器对象的__next__方法。
python要求迭代器本身也是可迭代的,所以我们要为迭代器实现__iter__方法,而__iter__方法要返回一个迭代器,迭代器自身正是一个迭代器,所以迭代器的__iter__方法返回自身即可。
一个实现了__iter__方法和__next__方法的对象,就是一个迭代器。
class MyList(object): """自定义的一个可迭代对象""" def __init__(self): self.items = [] def add(self, val): self.items.append(val) def __iter__(self): myiterator = MyIterator(self) return myiterator class MyIterator(object): """自定义的供上面可迭代对象使用的一个迭代器""" def __init__(self, mylist): self.mylist = mylist # current用来记录当前访问到的位置 self.current = 0 def __next__(self): if self.current < len(self.mylist.items): item = self.mylist.items[self.current] self.current += 1 return item else: raise StopIteration def __iter__(self): return self if __name__ == '__main__': mylist = MyList() mylist.add(1) mylist.add(2) mylist.add(3) mylist.add(4) mylist.add(5) for num in mylist: print(num)
for...in...循环的本质:for item in Iterable 循环的本质就是先通过iter()函数获取可迭代对象Iterable的迭代器,然后对获取到的迭代器不断调用next()方法来获取下一个值并将其赋值给item,当遇到StopIteration的异常后循环结束
除了for循环,list、tuple等也能接收可迭代对象:
li = list(FibIterator(15))
print(li)
tp = tuple(FibIterator(6))
print(tp)3.2 生成器
生成器(generator)是一类特殊的迭代器。
3.2.1 创建生成器的方法
方法1:将列表推导的中括号[]换成圆括号()
方法2:只要函数中有关键字yield就称为生成器。
def fib(n): current = 0 num1,num2 = 0, 1 while current<n: num = num1 num1,num2 = num2,num1+num2 current+=1 yield num return 'done' #在使用生成器实现的方式中,我们将原本在迭代器__next__方法中实现的基本逻辑放到一个#函数中来实现,但是将每次迭代返回数值的return换成了yield,此时新定义的函数便不再是#函数,而是一个生成器了 # 输出 next(fib(5)) # 输出 for n in fib(5): print(n) #但是用for循环调用generator时,发现拿不到generator的return语句的返回值。如果想#要拿到返回值,必须捕获StopIteration错误,返回值包含在StopIteration的value中 g = fib(5) while True: try: x=next(g) print('value:{}'.format(x)) except StopIteration as e: print('生成器返回值:{}'.format(e.value)) break # 总结 使用了yield关键字的函数不再是函数,而是生成器。(使用了yield的函数就是生成器) yield关键字有两点作用: (1)保存当前运行状态(断点),然后暂停执行,即将生成器(函数)挂起 (2)将yield关键字后面表达式的值作为返回值返回,此时可以理解为起到了return的作用 可以使用next()函数让生成器从断点处继续执行,即唤醒生成器(函数) Python3中的生成器可以使用return返回最终运行的返回值,而Python2中的生成器不允许使用return返回一个返回值(即可以使用return从生成器中退出,但return后不能有任何表达式)
3.2.2 使用send唤醒
除了可以使用next()函数来唤醒生成器继续执行外,还可以使用send()函数来唤醒执行。使用send()函数的一个好处是可以在唤醒的同时向断点处传入一个附加数据。
执行到yield时,gen函数作用暂时保存,返回i的值; temp接收下次c.send("python"),send发送过来的值,c.next()等价c.send(None)
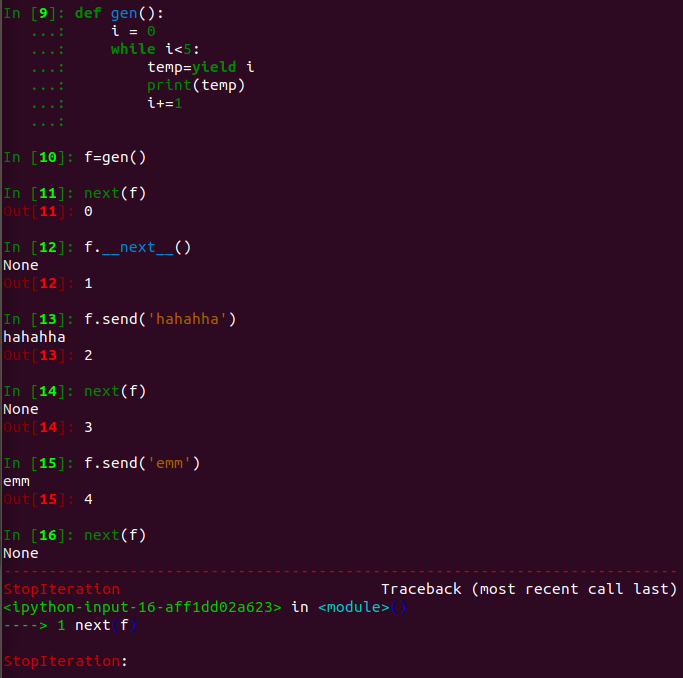
3.3 协程
协程(Coroutine),又称微线程。
协程是python中另外一种实现多任务的方式,它自带CPU上下文,比线程更小占用更小执行单元。
协程和线程差异:在实现多任务时, 线程切换从系统层面远不止保存和恢复 CPU上下文这么简单。 操作系统为了程序运行的高效性每个线程都有自己缓存Cache等等数据,操作系统还会帮你做这些数据的恢复操作。 所以线程的切换非常耗性能。但是协程的切换只是单纯的操作CPU的上下文,所以一秒钟切换个上百万次系统都抗的住。
协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,因此协程能保留上一次调用时的状态,每次过程重入时,就相当于进入上一次调用的状态。
并发编程中,协程和线程类似,每个协程表示一个执行单元,有自己的本地数据,与其他协程共享全局资源。
# 简单实现协程 import time def work1(): while True: print("----work1---") yield time.sleep(0.5) def work2(): while True: print("----work2---") yield time.sleep(0.5) def main(): w1 = work1() w2 = work2() while True: next(w1) next(w2) if __name__ == "__main__": main()
# 运行结果
----work1---
----work2---
----work1---
----work2---
----work1---
----work2---
----work1---
----work2---
----work1---
----work2---
----work1---
----work2---
...省略...
3.4 greenlet
为了更好使用协程来完成多任务,python中的greenlet模块对其封装,从而使得切换任务变的更加简单
from greenlet import greenlet import time def test1(): while True: print "---A--" gr2.switch() time.sleep(0.5) def test2(): while True: print "---B--" gr1.switch() time.sleep(0.5) gr1 = greenlet(test1) gr2 = greenlet(test2) #切换到gr1中运行 gr1.switch()
# 运行结果
---A--
---B--
---A--
---B--
---A--
---B--
---A--
---B--
...省略...3.5 gevent
python有一个比greenlet更强大的并且能够自动切换任务的模块gevent。
gevent是一个基于协程的python网络函数库,使用greenlet在libev(libev是一个事件库)事件循环顶部提供了一个有高级别并发性的API。
gevent的主要特性:(1)基于libev的快速事件循环,Linux上是epoll机制。
(2)基于greenlet的轻量级执行单元
(3)API复用了python标准库里的内容
(4)支持SSL的协作式sockets
(5)可通过线程池或c-ares实现DNS查询
(6)通过monkey patching功能使得第三方模块变成协作式(from gevent import monkey; mokey.patch_all()----类似于补丁)
其原理是当一个greenlet遇到IO(指的是input output 输入输出,比如网络、文件操作等)操作时,比如访问网络,就自动切换到其他的greenlet,等到IO操作完成,再在适当的时候切换回来继续执行。
由于IO操作非常耗时,经常使程序处于等待状态,有了gevent为我们自动切换协程,就保证总有greenlet在运行,而不是等待IO,这就是协程一般比多线程效率高的原因。由于切换是在IO操作时自动完成的,所以gevent需要修改python自带的一些标准库,将一些常见的阻塞,如socket、select等地方实现协程跳转,这一过程在启动时通过monkey.patch_all()完成。
spawn方法可以看成是用来形成协程,joinall方法就是添加这些协程任务并启动运行的。
# gevent同步执行 import gevent def f(n): for i in range(n): print(gevent.getcurrent(), i) g1 = gevent.spawn(f, 5) g2 = gevent.spawn(f, 5) g3 = gevent.spawn(f, 5) g1.join() g2.join() g3.join() # 结果 <Greenlet at 0x10e49f550: f(5)> 0 <Greenlet at 0x10e49f550: f(5)> 1 <Greenlet at 0x10e49f550: f(5)> 2 <Greenlet at 0x10e49f550: f(5)> 3 <Greenlet at 0x10e49f550: f(5)> 4 <Greenlet at 0x10e49f910: f(5)> 0 <Greenlet at 0x10e49f910: f(5)> 1 <Greenlet at 0x10e49f910: f(5)> 2 <Greenlet at 0x10e49f910: f(5)> 3 <Greenlet at 0x10e49f910: f(5)> 4 <Greenlet at 0x10e49f4b0: f(5)> 0 <Greenlet at 0x10e49f4b0: f(5)> 1 <Greenlet at 0x10e49f4b0: f(5)> 2 <Greenlet at 0x10e49f4b0: f(5)> 3 <Greenlet at 0x10e49f4b0: f(5)> 4
# gevent切换执行 import gevent def f(n): for i in range(n): print(gevent.getcurrent(), i) #用来模拟一个耗时操作,注意不是time模块中的sleep gevent.sleep(1) g1 = gevent.spawn(f, 5) g2 = gevent.spawn(f, 5) g3 = gevent.spawn(f, 5) g1.join() g2.join() g3.join() # 结果 <Greenlet at 0x7fa70ffa1c30: f(5)> 0 <Greenlet at 0x7fa70ffa1870: f(5)> 0 <Greenlet at 0x7fa70ffa1eb0: f(5)> 0 <Greenlet at 0x7fa70ffa1c30: f(5)> 1 <Greenlet at 0x7fa70ffa1870: f(5)> 1 <Greenlet at 0x7fa70ffa1eb0: f(5)> 1 <Greenlet at 0x7fa70ffa1c30: f(5)> 2 <Greenlet at 0x7fa70ffa1870: f(5)> 2 <Greenlet at 0x7fa70ffa1eb0: f(5)> 2 <Greenlet at 0x7fa70ffa1c30: f(5)> 3 <Greenlet at 0x7fa70ffa1870: f(5)> 3 <Greenlet at 0x7fa70ffa1eb0: f(5)> 3 <Greenlet at 0x7fa70ffa1c30: f(5)> 4 <Greenlet at 0x7fa70ffa1870: f(5)> 4 <Greenlet at 0x7fa70ffa1eb0: f(5)> 4
# 程序未打补丁 from gevent import monkey import gevent import random import time def coroutine_work(coroutine_name): for i in range(10): print(coroutine_name, i) time.sleep(random.random()) gevent.joinall([ gevent.spawn(coroutine_work, "work1"), gevent.spawn(coroutine_work, "work2") ]) # 结果 work1 0 work1 1 work1 2 work1 3 work1 4 work1 5 work1 6 work1 7 work1 8 work1 9 work2 0 work2 1 work2 2 work2 3 work2 4 work2 5 work2 6 work2 7 work2 8 work2 9
# 程序打了补丁 from gevent import monkey import gevent import random import time # 有耗时操作时需要 monkey.patch_all() # 将程序中用到的耗时操作的代码,换为gevent中自己实现的模块 def coroutine_work(coroutine_name): for i in range(10): print(coroutine_name, i) time.sleep(random.random()) gevent.joinall([ gevent.spawn(coroutine_work, "work1"), gevent.spawn(coroutine_work, "work2") ])
# 结果 work1 0 work2 0 work1 1 work1 2 work1 3 work2 1 work1 4 work2 2 work1 5 work2 3 work1 6 work1 7 work1 8 work2 4 work2 5 work1 9 work2 6 work2 7 work2 8 work2 9
gevent中还提供了对池的支持,当拥有动态数量的greenlet需要进行并发管理(限制并发数)时,就可以使用池,在处理大量的网络和IO操作时时非常需要。
from gevent.pool import Pool from gevent import monkey monkey.patch_all() def proc_some(args): pass if __name__=="__main__": pool = Pool(2) str_list = ["hahah", 'hahahaaaa'] results = pool.map(proc_some,str_list) print(results)
4、总结
- 进程是资源分配的单位
- 线程是操作系统调度的单位
- 进程切换需要的资源很最大,效率很低
- 线程切换需要的资源一般,效率一般(当然了在不考虑GIL的情况下)
- 协程切换任务资源很小,效率高
- 多进程、多线程根据cpu核数不一样可能是并行的,但是协程是在一个线程中 所以是并发

