
三、正则表达式
描述:正则表达式能够从一段文本中提取有用的信息。
0、使用正则表达式有如下步骤:
(1)寻找规律;
(2)使用正则符号表示规律
(3)提取信息
1、正则表达式的基本符号
1.1 点号“.”
一个点号可以代替除了换行符以外的任何一个字符,包括但不限于英文字母、数字、汉字、英文标点符号和中文标点符号。
1.2 星号“*”
一个星号可以表示它前面的一个子表达式(普通字符、另一个或几个正则表达式符号)0次到无限次。
1.3 问号“?”
问号表示它前面的子表达式0次或者1次。
1.4 反斜杠“\”
配合使用把特殊字符变成普通符号,把普通符号变成特殊字符。
1.5 转义字符表
| 转移字符 | 意义 |
| \n | 换行符 |
| \t | 制表符 |
| \\ | 普通反斜杠 |
| \' | 单引号 |
| \" | 双引号 |
| \d | 匹配数字,即0-9 |
| . | 匹配任意1个字符(除了\n) |
| \D | 匹配非数字,即不是数字 |
| [] | 匹配[]中列举的字符 |
| \s | 匹配空白,即空格,tab键 |
| \S | 匹配非空白 |
| \w | 匹配单词字符,即a-z、A-Z、0-9、_ |
| \W | 匹配非单词字符 |
1.6 小括号
小括号可以把括号里面的内容提取出来。
1.7 加号+
匹配前一个字符出现1次或则无限次,即至少有1次。
2、在python中使用正则表达式
2.1 python自带的正则表达式模块re(regular expression)
2.1.1 导入re
1 import re
2.1.2 findall
findall()方法,它能够以列表的形式返回所有满足要求的字符串
findall()的函数模型为:
1 re.findall(pattern, string, flags=0) #pattern表示正则表达式, string表示原来的字符串, flags表示一些特殊功能的标签
提示:(1)如果包含多个(.*?)返回的仍然是一个列表,但是列表里面的元素变成了元组。
(2)flags参数可以省略,不省略时具有一些辅助功能,如要忽略换行符,就需要使用re.S这个flag。
2.1.3 search
search()方法,只会返回第1个满足要求的字符串,一旦找到符合要求的内容,它就会停止查找。
search()的函数模型为:
1 re.search(pattern, string, flags=0)
提示:(1)如果需要得到匹配到的结果,则需要通过group()这个方法来获取里面的值
(2)只有在.group()里面的参数为1的时候,才会把正则表达式里面的括号中的结果打印出来。
(3).group()的参数最大不能超过正则表达式里面括号的个数。
2.1.4 “.*”和“.*?”的区别
“.*”表示匹配一个能满足要求的最长字符串
“.*?”表示匹配一个能满足要求的最短字符串
2.1.5 sub 将匹配到的数据进行替换
re.sub(r"\d+","996","hahaha 1024,ememem 3409")
sub支持函数的调用
import re def add(temp): str_num = temp.group() num = int(str_num)+1 return str(num) def main(): result_1 = re.sub(r"\d+","996","我的工作时间是1024,并且已经工作了2年") result_2 = re.sub(r"\d+",add,"我有100个苹果") print(result_1) print(result_2) if __name__=='__main__': main()

2.1.6 split 根据匹配进行切割字符串,并返回一个列表
import re ret = re.split(r":| ","info:xiaozhang 33 shangdong") print(ret)

2.2 match
match默认判断开头
re.match(r'测试[a-z]','测试测试a').group() re.match(r'测试\s\w','测试测试 a').group()
2. 3 多个字符
{m} 匹配前一个字符出现m次

{m,n}匹配前一个字符出现从m到n次
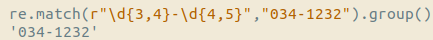
2.4 匹配结尾和开头
^ 匹配字符串开头
$ 匹配字符串结尾
2.5 匹配分组
| 字符 | 功能 |
| | | 匹配左右任意一个表达式 |
| (ab) | 将括号中字符作为一个分组 |
| \num | 引用分组num匹配到的字符串 |
| (?P<name>demo_re) | 分组起别名 |
| (?P=name) | 引用别名为name分组匹配到的字符串 |
2.6 r的作用
说明:python中字符串前面加上r表示原生字符串。
一般而言,在编程语言表示的正则表达式里,要匹配文本中的字符“\”,需要4个反斜杠“\” ,前面两个和后面两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。
里的原生字符串解决了这个问题,通过在字符串前加上r,能够按照使用习惯直接转义需要的字符,以此达到表达式的直观化。
3、正则表达式提取技巧
3.1 不需要compile
3.2 先抓大再抓小
先抓大再抓小的思想会贯穿整个爬虫开发过程。
3.3括号内和括号外
