2023数据采集与融合第三次作业
作业①:
实验内容
题目:
- 要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。 - 输出信息:将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
spider1.py
import scrapy
from ex3.items import GetImageItem
class GetImgSpider(scrapy.Spider):
# 102102118
name = "GetImgSpider"
num = 0
page = 0
def start_requests(self):
url = input("请输入网址:")
# url = "http://www.weather.com.cn"
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
try:
print(response.url)
image_list = response.xpath("//img/@src").extract()
url_list = response.xpath("//a/@href").extract()
for image in image_list:
if image == "": # 有些图片在网页上看是有值的,但直接爬取出来的是空值,就排除了
continue
if self.num >= 118:
return
item = GetImageItem()
item["image"] = image
self.num += 1
item["num"] = self.num
# print("!",self.num, image,response.url)
# print(response.xpath("//img/@src").extract())
yield item
for url in url_list:
if url == "javascript:void(0)": # 排除死链接
continue
if self.page >= 18:
return
self.page += 1
# print("?",self.page,url)
yield scrapy.Request(url=url, callback=self.parse)
except Exception as err:
print(err, response.url)
items.py
import scrapy
class GetImageItem(scrapy.Item):
num = scrapy.Field() # 计数
image = scrapy.Field() # 图片路径
url = scrapy.Field() # 网址
pipelines.py
import os
import requests
class GetImagePipeline:
def process_item(self, item, spider):
if not os.path.exists('./images'):
os.mkdir('./images')
try:
path = "images/"+str(item["num"]) + ".jpg" # .png改.jpg影响不大
data = requests.get(url=item["image"]).content
with open(path, 'wb') as fp:
fp.write(data)
except Exception as err:
print(err)
print(item["num"], item["image"])
return item
运行结果:
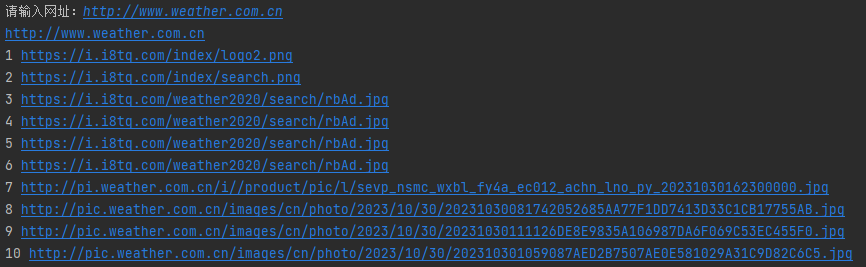
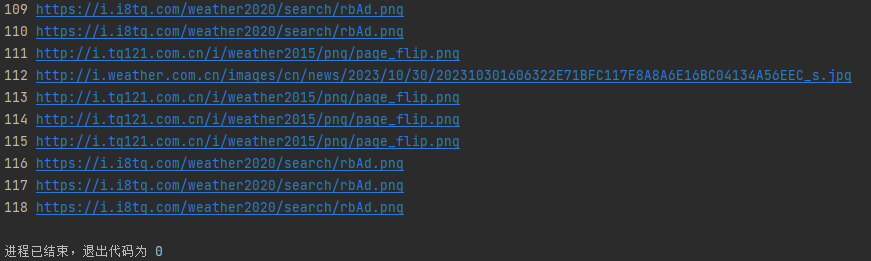
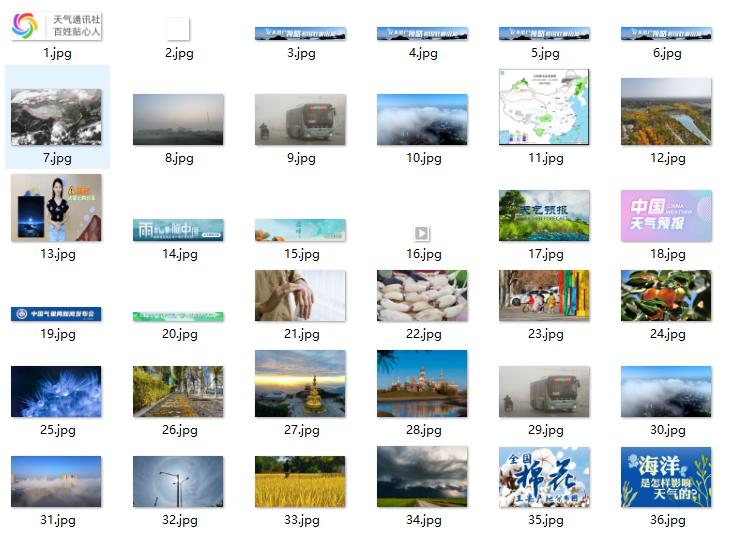
心得体会
有些网址会用javascript:void(0),作用是阻止链接跳转,URL不会有任何变化。
有些图片在网页f12上有路径,但实际爬到的是空值,猜测是动态的,不会保存,就不存了。
若要改用多线程,则把setting文件中的concurrent_request改为32即可。
作业②:
实验内容
题目:
- 要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
- 候选网站:东方财富网:https://www.eastmoney.com/
- 输出信息:MySQL数据库存储和输出格式如下:
表头英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计
spider2.py
import scrapy
from ex3.items import GetStockItem
import json
class GetStockSpider(scrapy.Spider):
name = "GetStockSpider"
start_urls=["http://79.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112409084454540191573_1697982071063&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1697982071072"]
page = 0
def parse(self, response):
print(response.url)
json_str = response.text[len('jQuery112409594985484135052_1697702833397('):-2]
json_data = json.loads(json_str)
items = json_data['data']['diff']
for i in items:
try:
item = GetStockItem()
item["code"] = i["f12"] # 股票代码
item["name"] = i["f14"] # 股票名称
item["lastTrade"] = i["f2"] # 最新报价
item["chg"] = i["f3"] # 涨跌幅
item["change"] = i["f4"] # 涨跌额
item["volume"] = i["f6"] # 成交量
item["amp"] = i["f7"] # 振幅
item["highest"] = i["f15"] # 最高
item["lowest"] = i["f16"] # 最低
item["open"] = i["f17"] # 今开
item["prevClose"] = i["f18"] # 昨收
yield item
except Exception as err:
print(err)
self.page += 1
if self.page < 3: # 爬3页
url = response.url
l = url.find("pn=")
r = url.find("&pz=")
pn = int(url[l+3:r]) + 1
next_url = url[:l+3] + str(pn) + url[r:]
yield scrapy.Request(url=next_url, callback=self.parse)
items.py
import scrapy
class GetStockItem(scrapy.Item):
code = scrapy.Field() # 股票代码
name = scrapy.Field() # 股票名称
lastTrade = scrapy.Field() # 最新报价
chg = scrapy.Field() # 涨跌幅
change = scrapy.Field() # 涨跌额
volume = scrapy.Field() # 成交量
amp = scrapy.Field() # 振幅
highest = scrapy.Field() # 最高
lowest = scrapy.Field() # 最低
open = scrapy.Field() # 今开
prevClose = scrapy.Field() # 昨收
pipelines.py
import pymysql
class GetStockPipeline(object):
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", database="stocks", charset="utf8")
self.cursor = self.con.cursor()
self.cursor.execute("DROP TABLE IF EXISTS stocks")
self.cursor.execute("create table stocks(id int,code varchar(10),name varchar(20),lastTrade varchar(10),chg varchar(10),change_ varchar(10),volume varchar(10),amp varchar(10),highest varchar(10),lowest varchar(10),open varchar(10),prevClose varchar(10),primary key (id))")
self.opened = True
self.count = 0 # 初始化count属性
except Exception as err:
print(err)
self.opened = False
self.con.commit()
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
def process_item(self, item, spider):
try:
self.cursor.execute(
"insert into stocks (id, code, name, lastTrade, chg, change_, volume, amp, highest, lowest, open, prevClose) values(%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)",
(self.count+1, item["code"], item["name"], item["lastTrade"], item["chg"], item["change"], item["volume"],item["amp"], item["highest"], item["lowest"], item["open"], item["prevClose"]))
self.count += 1
except Exception as err:
print(err)
return item
运行结果:

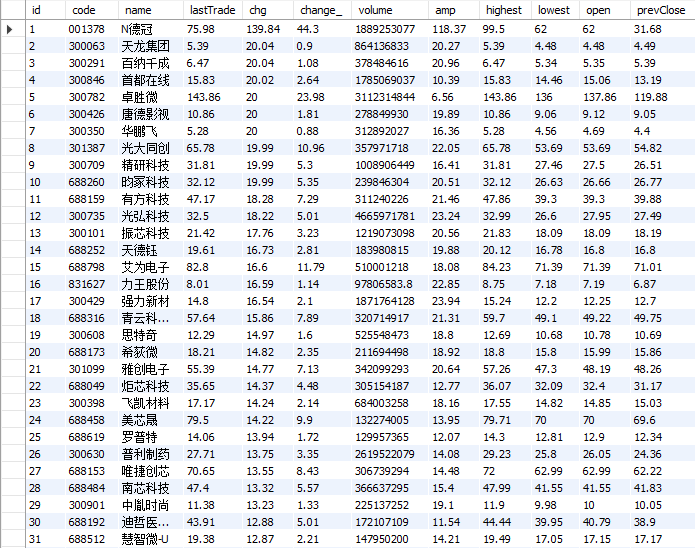
心得体会
对于动态加载的数据,在不会scrapy和selenium结合的情况下,可以抓包。对抓包得到的数据处理即可。
命名很乱,可能是错的,别管。数据库表中列名不能用index和change,会报错,因为这是关键字。
pipelines.py中open_spider和close_spider会在开始和结束各自执行一次,正好用来打开和关闭数据库。
作业③
实验内容
题目:
- 要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
- 候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
spider3.py
import scrapy
from ex3.items import GetCurrencyItem
class GetCurrencySpider(scrapy.Spider):
name = "GetCurrencySpider"
start_urls = ["https://www.boc.cn/sourcedb/whpj/"]
base_url = "https://www.boc.cn/sourcedb/whpj/"
p = 0
def parse(self, response):
try:
print(response.url)
data = response.body.decode()
selectors = scrapy.Selector(text=data)
trs = selectors.xpath("//table[@align='left']/tr[position()>1]") # 第一个是标题,不要
for tr in trs:
item = GetCurrencyItem()
item["Name"] = tr.xpath("./td[position()=1]/text()").extract_first()
item["TBP"] = tr.xpath("./td[position()=2]/text()").extract_first()
item["CBP"] = tr.xpath("./td[position()=3]/text()").extract_first()
item["TSP"] = tr.xpath("./td[position()=4]/text()").extract_first()
item["CSP"] = tr.xpath("./td[position()=5]/text()").extract_first()
item["Time"] = tr.xpath("./td[position()=8]/text()").extract_first()
yield item
except Exception as err:
print(err)
self.p += 1
if self.p < 3: # 爬3页
next_url = self.base_url + "index_{}.html".format(self.p)
yield scrapy.Request(url=next_url, callback=self.parse)
items.py
import scrapy
class GetCurrencyItem(scrapy.Item):
Name = scrapy.Field() # 货币名称
TBP = scrapy.Field() # 现汇买入价
CBP = scrapy.Field() # 现钞买入价
TSP = scrapy.Field() # 现汇卖出价
CSP = scrapy.Field() # 现钞卖出价
Time = scrapy.Field() # 发布时间
pipelines.py
import pymysql
class GetCurrencyPipeline(object):
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", database="currency",
charset="utf8")
self.cursor = self.con.cursor()
self.cursor.execute("DROP TABLE IF EXISTS currency")
self.cursor.execute(
"create table currency(id int,Name varchar(20),TBP float,CBP float,TSP float,CSP float,Time varchar(20),primary key (id))")
self.opened = True
self.count = 0 # 初始化count属性
except Exception as err:
print(err)
self.opened = False
self.con.commit()
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
def process_item(self, item, spider):
try:
self.cursor.execute(
"insert into currency (id, Name, TBP, CBP, TSP, CSP, Time) values(%s, %s, %s, %s, %s, %s, %s)",
(self.count + 1, item["Name"], item["TBP"], item["CBP"], item["TSP"], item["CSP"], item["Time"]))
self.count += 1
print(item["Name"], item["TBP"], item["CBP"], item["TSP"], item["CSP"], item["Time"])
except Exception as err:
print(err)
return item
运行结果:
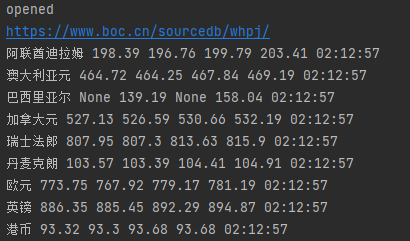
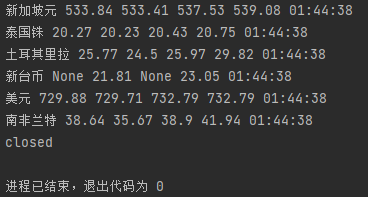
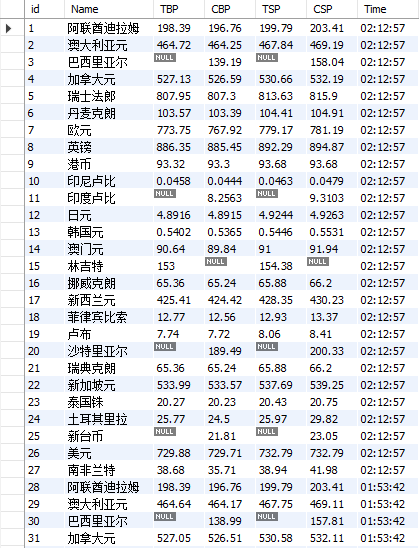
心得体会
在网页看的数据是在tbody下的tr中,但以"//tbody/tr"爬出的是空集,输出爬到的文本发现数据在table下的tr中。文本总共有两个table元素,所需的table中有align='left'可以用来区分。之后正常写xpath爬数据即可。
码云链接
https://gitee.com/chenglong-xu/crawl_project/tree/master/作业3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号