
上节回顾:
1、collections 模块 :基础数据类型的扩展
2、时间模块 :和时间相关的模块——三种格式时间戳、格式化字符串、结构化时间
3、random 模块 :生成随机数。从一个数据结构中随机抽取数据、打乱序列的顺序
4、os模块 :操作系统:文件与文件夹的创建和删除、路径相关的操作、执行系统命令
5、sys模块 :python解释器,sys.argv python文件的执行,sys.pathon 模块导入的
6、序列化模块 :序列化,将数据结构转换成字符串序列,jison、pickle、shelve
7、re模块 :和正则表达式相关的,正则表达式,是一种匹配字符串的规则
补充:
1、pickle模块提供了四个功能:dumps、dump(序列化、存)、load(反序列化、读)、load(不仅可以序列化字典、
列表。。。可以把python中任意的数据类型序列化)
2、程序中难免出现错误,而错误分成两种:
(1)语法错误(这种错误,根本过不了python解释器的语法检测,必须在程序执行前改正)
(2)逻辑错误
3、什么是异常:
异常就是程序运行时发生的错误信号,在python中,错误触发的异常如下(排除错误的方法:就是从下往上排除)
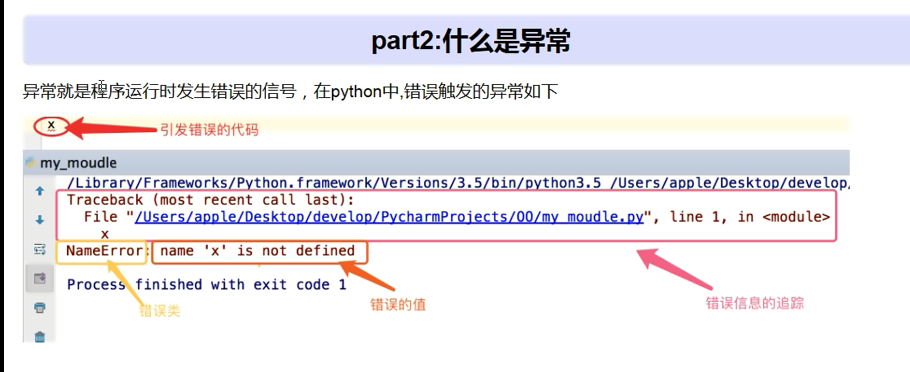
4、python中的异常种类
在python中不同的异常可以用不同的类型(python中统一了类和类型,类型即类)去标识。不同的类对象标识不同的异常,一个异常标识一个错误
1、触发IndexError
2、触发KeError
3、触发ValueError
5、什么是异常处理
python解释器检测到错误,触发异常(也允许程序员自己触发异常))
程序员编写特定的代码,专门用来捕捉这个异常(这段代码与程序逻辑无关,与异常处理有关)
如果捕捉成功则进入另外一个处理分支,执行你为其定制的逻辑,使程序不会崩溃,这就是异常处理
6、为什么要进行异常处理
python解释器去执行程序,检测到了一个错误时,触发异常,异常出发后且没有被处理的情况下,程序就在当前异常处终止
后面的代码就不会运行,谁会用一个运行着突然就崩溃的软件。
所以你必须提供一种异常处理机制来增强你程序的健壮性和容错性
7、如何进行异常处理:
首先须知,异常是由程序的错误引起的,语法上的错误跟异常处理无关,必须在程序运行前修正
(1)使用if判断式 (异常发生之前的处理)


num1=input(">>>:") if num1.isdigit(): print(int(num1),type(int(num1))) elif num1.isspace(): print("1如果输入的是空格,就执行这里的逻辑") elif len(num1)==0: print("2如果输入的是空,就执行这里的逻辑") else: print("3如果是其他情况就执行这里") ''' 问题一: 使用if的方式我们只为第一段代码加上了异常处理,但这些if,跟你的代码逻辑并无关系,这样你的代码会因为可读性差而不容易被看懂 问题二: 这只是我们代码中的一个小逻辑,如果类似的逻辑多,那么每一次都需要判断这些内容,就会倒置我们的代码特别冗长。 '''
def test(): print("test running") choice_dic={ "1":test } while True: choice=input(">>>:").strip() if not choice or choice not in choice_dic: #这便是一种异常处理机制啊 continue choice_dic[choice]()
8、python为每一种异常定制了一个类型,然后提供了一种特定的语法结构用来处理异常
(1)基本语法(异常发生之后的处理)
try: 被检测的代码块 except 异常类型: try中一旦检测到异常,就执行这个位置的逻辑
try: f=open("函数作业",encoding="utf-8") g=(line.strip() for line in f) print(next(g)) print(next(g)) print(next(g)) except StopIteration: f.close() ''' next(g)会触发迭代f,依次next(g)就可以读取文件的一行行内容,无论文件a.txt有多大,同一时刻内存中只有一行内容。 提示:g是基于文件句柄f而存在的,因而只能在next(g)抛出异常StopIteration后才可以执行f.close() '''
(2)异常只能用来处理指定的异常情况,如果非指定异常则无法处理
#未捕捉到异常,则直接报错 s1 = 'hello' try: int(s1) except IndexError as e: print(e)
(3)多分支处理
s1 = 'hello' try: int(s1) except IndexError as e: print("1:",e) except KeyboardInterrupt as e: print("2",e) except ValueError as e: print("3",e) # 3 invalid literal for int() with base 10: 'hello'
(4)万能异常在python的异常中,有一个万能异常:Exception,他可以捕捉任意异常
s1 = 'hello' try: int(s1) except Exception as e: print("异常原因",e) # 异常原因 invalid literal for int() with base 10: 'hello'
(5)异常的其他机构
s1 = '1' try: int(s1) except IndexError as e: print(1,e) except KeyError as e: print(2,e) except ValueError as e: print(3,e) except Exception as e: print(4,e) else: print('try内代码块没有异常则执行我') finally: print('无论异常与否,都会执行该模块,通常是进行清理工作') #try内代码块没有异常则执行我 #无论异常与否,都会执行该模块,通常是进行清理工作
(6)主动触发异常 (raise+一个错误类型) 后面面向对象会讲到
try: raise TypeError("类型错误") except Exception as e: print(1,e) #爆出异常内容,如果没有上面括号的内容则是空白 # 1类型错误
(7)自定义异常(写框架,学面向对象的时候会用到)
class EvaException(BaseException): def __init__(self,msg): self.msg=msg def __str__(self): return self.msg try: raise EvaException("类型错误") except EvaException as e : print(1,e) #1 类型错误
(8)断言(assert+ 条件)

(9)try ...except 比较 if方式有什么好处
try ...excep这种异常处理机制就是取代if 那种方式,让你的程序在不牺牲可读性的前提下增强健壮性和容错性
异常处理中为每一个异常定制了异常类型(Python中统一了类与类型,类型即类),对于同一种异常,一个except就可以捕捉到
可以同时处理多段代码的异常(无需写多个if判断式)减少了代码,增强了可读性
使用try...except 的方式
1:把错误处理和真正的工作分开来
2:代码更容易组织,更清晰,复杂的工作任务更容易实现;
3:毫无疑问,更安全了,不至于由于一些小的疏忽而使程序意外崩溃了
最常用的:try……except
finally
什么时候用异常处理
有的同学会这么想,学完了异常处理后,好强大,我要为我的每一段程序都加上try...except,干毛线去思考它会不会有逻辑错误啊,这样就很好啊,多省脑细胞===》2B青年欢乐多
try...except应该尽量少用,因为它本身就是你附加给你的程序的一种异常处理的逻辑,与你的主要的工作是没有关系的
这种东西加的多了,会导致你的代码可读性变差,只有在有些异常无法预知的情况下,才应该加上try...except,其他的逻辑错误应该尽量修正
一、模块:
1、什么是模块?
常见的场景:一个模块就是一个包含了python定义和声明的文件,文件名就是让模块名字加上。py的后缀
但其实impo加载的模块氛围四个通用类别:
(1)使用python编写的代码(.py文件)
(2)已经被编译为共享库或DLL的c或c++扩展
(3)包好一组模块的包
(4)使用c编写并链接到python解释的内置模块
2、为什么要使用模块

3、定义模块,调用函数,查看变量
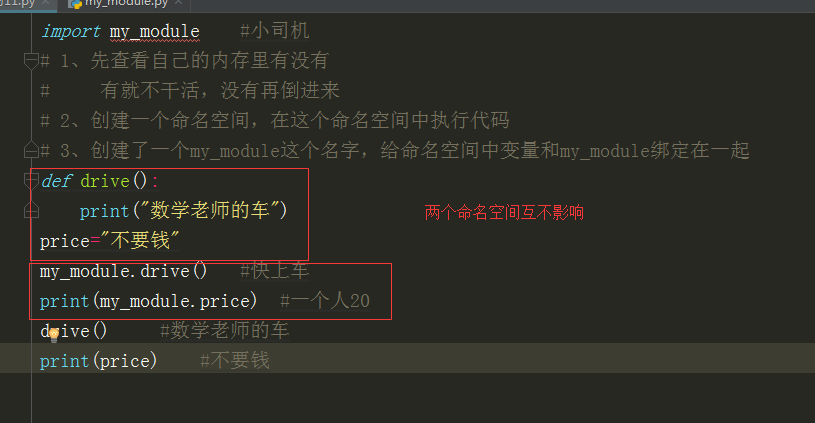
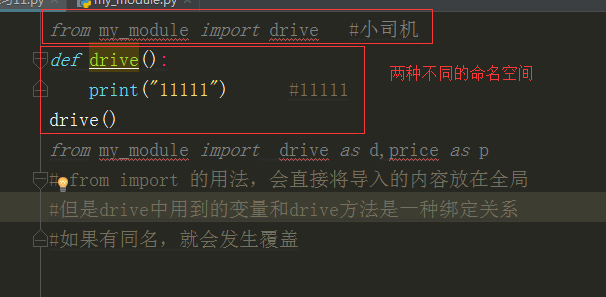
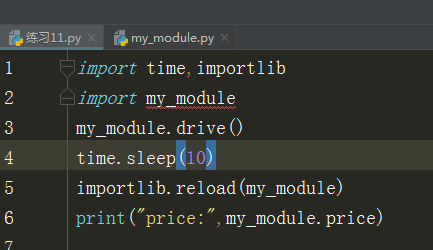
import my_module #小司机 # 1、先查看自己的内存里有没有 # 有就不干活,没有再倒进来 # 2、创建一个命名空间,在这个命名空间中执行代码 # 3、创建了一个my_module这个名字,给命名空间中变量和my_module绑定在一起 def drive(): print("数学老师的车") price="不要钱" my_module.drive() #快上车 print(my_module.price) #一个人20 drive() #数学老师的车 print(price) #不要钱
4、开发的六大原则之二:不能相互引用
二、import...as
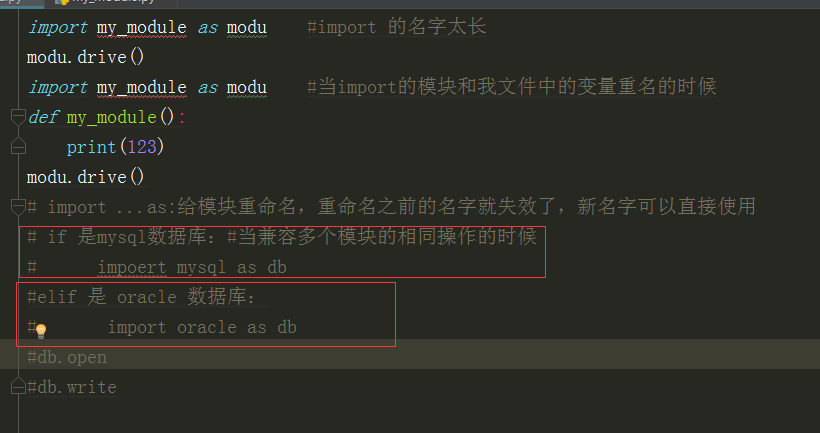
1、给模块起别名:一个变量的名字只能指向一个内存地址

2、数据库中会用到重命名,写的代码能够兼容两个不同的数据库
例子:
(1)有两中sql模块mysql和oracle,根据用户的输入,选择不同的sql功能
# mysql.py def sqlparse(): print("from mysql sqlparse") # oracle.py def sqlparse(): print("from oracle sqlparese") # test.py db_type=input(">>>:") if db_type=="mysql": import mysql as db elif db_type=="oracle": import oracle as db db.sqlparse()
(2)为已经导入的模块起别名的方式对编写可扩展的代码很有用,假设有两个模块xmlreader.py和csvreader.py,它们都定义了函数read_data(filename):用来从文件中读取一些数据,但采用不同的输入格式。可以编写代码来选择性地挑选读取模块,例如
if file_format == 'xml': import xmlreader as reader elif file_format == 'csv': import csvreader as reader data = reader.read_date(filename)
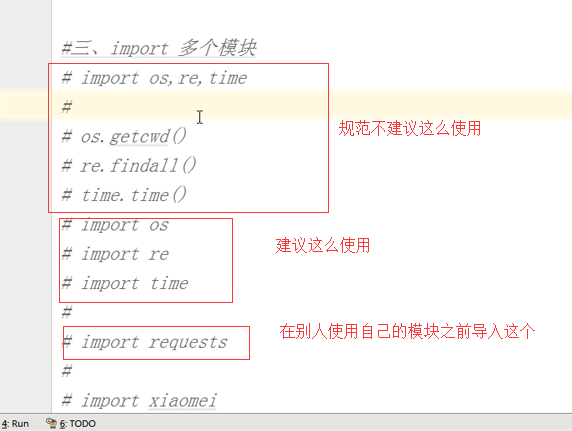
3、import多个模块
(1)先导入内置模块
(2)再导入扩展模块
(3)最后导入自定义模块
三、from....import
1、
对比import my_module,会将源文件的名称空间'my_module'带到当前名称空间中,使用时必须是my_module.名字的方式
而from 语句相当于import,也会创建新的名称空间,但是将my_module中的名字直接导入到当前的名称空间中,在当前名称空间中,直接使用名字就可以了、
这样在当前位置直接使用read1和read2就好了,执行时,仍然以my_module.py文件全局名称空间
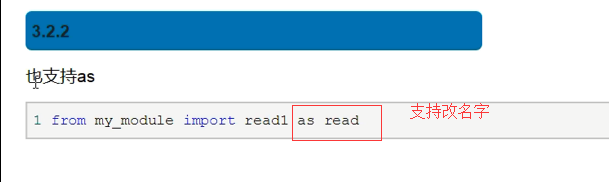
#测试一:导入的函数read1,执行时仍然回到my_module.py中寻找全局变量money #demo.py from my_module import read1 money=1000 read1() ''' 执行结果: from the my_module.py spam->read1->money 1000 ''' #测试二:导入的函数read2,执行时需要调用read1(),仍然回到my_module.py中找read1() #demo.py from my_module import read2 def read1(): print('==========') read2() ''' 执行结果: from the my_module.py my_module->read2 calling read1 my_module->read1->money 1000
2、

3、
4、三种使用方法
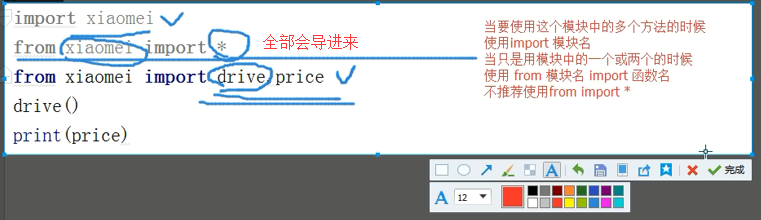
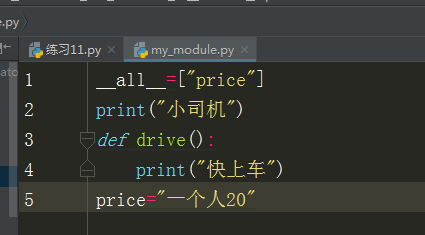
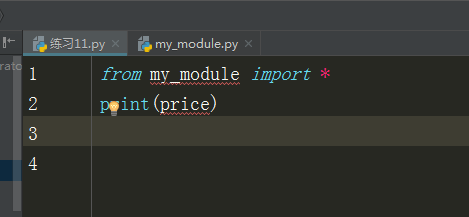
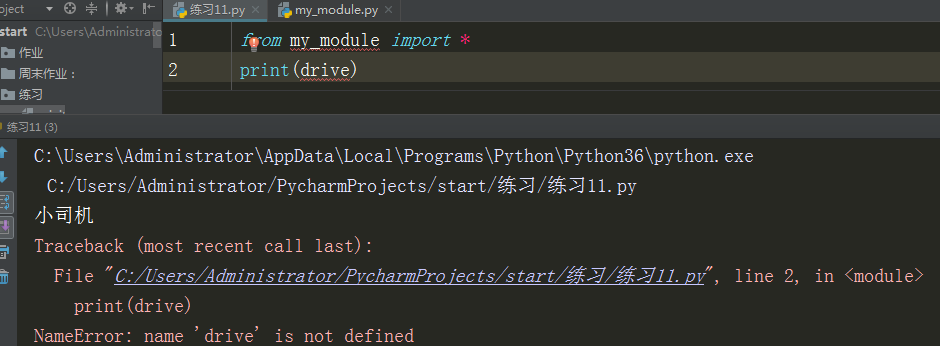
5、from...import*
受到__all__的限制,如果不定义__all__就默认引入所有
如果定义了,那么列表中有什么,就能引入什么
如果引入其他则会报错
6、测试使用:(不重要)
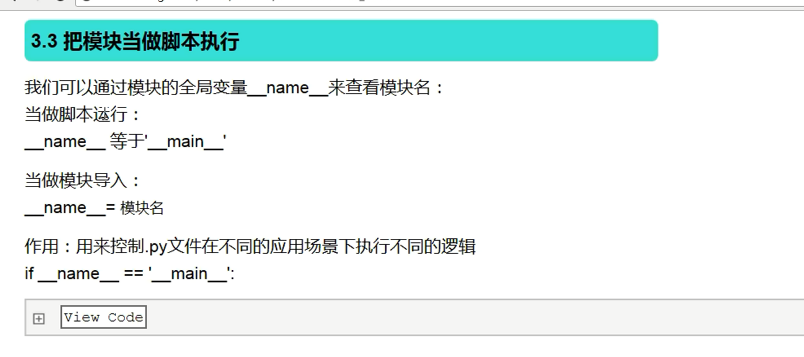
四、把模块当做脚本执行
1、把模块当作脚本运行
def fib(n): a, b = 0, 1 while b < n: print(b, end=' ') a, b = b, a+b print() if __name__ == "__main__": print(__name__) num = input('num :') fib(int(num))
2、执行python解释器,已经在内存中加载了一些内置的模块了
导入模块的时候,如果模块不存在sys.modules,才从sys.path给的路径中依次去查找
sys.path完全可以决定某个模块能不能被找到(除了已经在内存中加载一些内置的模块)
3、当py文件被当做一个模块导入的时候,会自动生成一个pyc文件
pyc文件是这个代码编译之后的文件,节省了每一次导入代码之后还要编译的时间
pyc是存在硬盘上的和内存没有关系
4、查看内置的所有方法:
import my_module print(dir(my_module))
5、软件开发规范
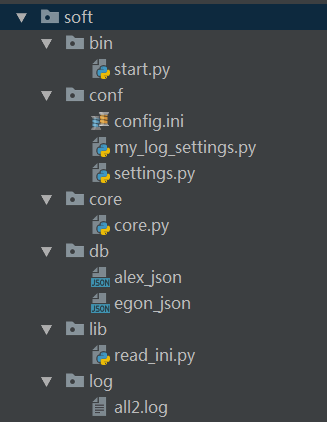
#=============>bin目录:存放执行脚本
#=============>conf目录:存放配置文件
#=============>core目录:存放核心逻辑
#=============>db目录:存放数据库文件
#=============>lib目录:存放自定义的模块与包
#=============>log目录:存放日志
