

上节回顾:
1、time:-------时间:时间戳 、字符串、结构化时间
2、collections-----扩展数据类型的模块:可命名元组、有序字典、默认字典、双端列队、计数器
3、sys-----和python解释器打交道的模块
sys.path:和路径有关,且关系到模块导入相关的路径
sys.argv:[xxx.py.argv1,argv2],python xxx.py argv1 argv2...
今日内容:
常用模块:
#random 随机数相关 ***
#0s 操作系统相关*****
#序列化
#json *****
#pickle****
#shelve***
#异常处理*****
一、random模块
1、生成随机小数(不重要)



import random print(random.random()) #生成0-1之间的小数 print(random.uniform(10,12)) #n,m之间的小数 # 0.055019711378065383 # 10.69662552212382
2、生成随机整数(重要)
randint 头尾都有
randrange 顾头不顾尾
import random print(random.randint(1,2))#必须是两个参数,规定一个范围[1,2] print(random.randrange(100))#一个参数 print(random.randrange(1,2))#两个参数[1,2) print(random.randrange(90,100,2))#三个参数,最后一个是步长
3、从一个序列中随机选择:
一个choice
多个sample
import random print(random.choice("abc")) # b print(random.sample([1,"23",[2,3]],2)) # [1, [2, 3]]
4、打乱排序列表 shuffle
应用实例:洗牌,彩票,抽奖,测试一些排序算法
item=[1,2,3,4,5,5] random.shuffle(item) print(item) # [3, 5, 1, 2, 5, 4]
面试题:
1、生成一个6位数字随机验证码
import random l=[] for i in range(6): rand_num=random.randint(0,9) l.append(str(rand_num)) print("".join(l)) # 197092
import random print(random.sample(range(0,10),6))
重要例子:
生成一个6位数字+字母的验证码
0-9
a-z :65-90
A-Z :97-122
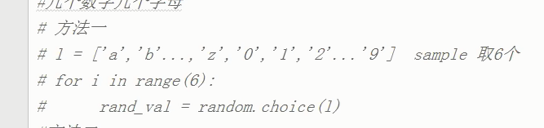
方法二:
import random l=[] for i in range(6): num=str(random.randint(0,9)) alpha_lower=chr(random.randint(65,90)) alpha_upper=chr(random.randint(97,122)) ret=random.choice([num,alpha_lower,alpha_upper]) l.append(ret) print("".join(l))
二、os模块
照着敲写: os模块是与操作系统交互的一个接口
''' os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd os.curdir 返回当前目录: ('.') os.pardir 获取当前目录的父目录字符串名:('..') os.makedirs('dirname1/dirname2') 可生成多层递归目录 os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 os.remove() 删除一个文件 os.rename("oldname","newname") 重命名文件/目录 os.stat('path/filename') 获取文件/目录信息 os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/" os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n" os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为: os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix' os.system("bash command") 运行shell命令,直接显示 os.popen("bash command) 运行shell命令,获取执行结果 os.environ 获取系统环境变量 os.path os.path.abspath(path) 返回path规范化的绝对路径 os.path.split(path) 将path分割成目录和文件名二元组返回 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。 即os.path.split(path)的第二个元素 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) 如果path是绝对路径,返回True os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 os.path.getatime(path) 返回path所指向的文件或者目录的最后访问时间 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间 os.path.getsize(path) 返回path的大小
例子:
查看文件的最后修改时间
import os import time ret=os.path.getmtime(r"C:/Users/Administrator/PycharmProjects/start/练习题/练习11.py") print(time.strftime("%x %X",time.localtime(ret))) # 12/14/17 11:43:07
其余的具体操作查看 有道笔记
三、序列化处理模块
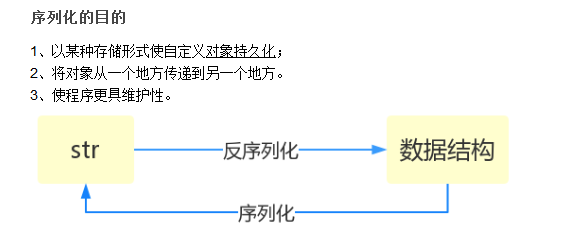
什么叫序列化——将原本的字典、列表等内容转换成一个字符串的过程就叫做序列化。
比如,我们在python代码中计算的一个数据需要给另外一段程序使用,那我们怎么给? 现在我们能想到的方法就是存在文件里,然后另一个python程序再从文件里读出来。 但是我们都知道,对于文件来说是没有字典这个概念的,所以我们只能将数据转换成字典放到文件中。 你一定会问,将字典转换成一个字符串很简单,就是str(dic)就可以办到了,为什么我们还要学习序列化模块呢? 没错序列化的过程就是从dic 变成str(dic)的过程。现在你可以通过str(dic),将一个名为dic的字典转换成一个字符串, 但是你要怎么把一个字符串转换成字典呢? 聪明的你肯定想到了eval(),如果我们将一个字符串类型的字典str_dic传给eval,就会得到一个返回的字典类型了。 eval()函数十分强大,但是eval是做什么的?e官方demo解释为:将字符串str当成有效的表达式来求值并返回计算结果。 BUT!强大的函数有代价。安全性是其最大的缺点。 想象一下,如果我们从文件中读出的不是一个数据结构,而是一句"删除文件"类似的破坏性语句,那么后果实在不堪设设想。 而使用eval就要担这个风险。 所以,我们并不推荐用eval方法来进行反序列化操作(将str转换成python中的数据结构)
序列化的目的
1、在传输过程尽量少使用eval
s_dic=str({"k":"v"})
print(repr(s_dic))
print(repr(eval(s_dic)),type(eval(s_dic)))
# "{'k': 'v'}"
# {'k': 'v'} <class 'dict'>
2、json的优点:所有语言都通用,它能序列化的数据是有限的:字典列表元组
序列化中的内容只能包含:字典、列表、数字、字符串。如果是元组——自动转成列表的样子
json模块提供了四个功能:dumps loads dump load
(1)dumps和loads与字符串打交道
import json ret=json.dumps({"k":[1,2,3]}) print(repr(ret),type(ret)) ret2=json.loads(ret) print(repr(ret2),type(ret2)) # '{"k": [1, 2, 3]}' <class 'str'> # {'k': [1, 2, 3]} <class 'dict'>
(2)dump 与load是与文件打交道的,一次性只能读出来一个列表或者一个字典
解决这个问题是使用for循环读出用loads将字符串转成列表
import json # f=open("json_file","a") # json.dump({"k":"v"},f) # f.close() with open("json_file")as f: ret=json.load(f) print(ret,type(ret)) # 一次只能反序列化一个字典
import json with open("json_file")as f: for line in f: print(json.loads(line)) # {'k': 'v'} # {'k': 'v'}
str=json.dumps(dict) f.write(str+"\n")
3、pickle 是py特有的
dumps loads dump load pickle---序列化任何数据类型
pickle---序列化任何数据类型,python专有的不能和其他语言兼容,结果是bytes
import pickle #用pickle序列化的数据,反序列化也必须用pickle ret=pickle.dumps({1,2,3,4}) print(ret) #序列化的结果是以字节的形式显示出来的,也就是为甚么可以序列化任何数据类型的原因 # b'\x80\x03cbuiltins\nset\nq\x00]q\x01(K\x01K\x02K\x03K\x04e\x85q\x02Rq\x03.'
4、shelve 是python3.6新加入的序列化模块

(1)序列化 写进文件
import shelve f=shelve.open("shelve_file") f["key"]={"int":10,"float":9.5,"string":"sample data"} f.close()
(2)反序列化
#反序列化 f1=shelve.open("shelve_file") existing=f1["key"] f1.close() print(existing) #{'int': 10, 'float': 9.5, 'string': 'sample data'}
(3)这个模块有个限制,它不支持多个应用同一时间往同一个DB进行操作(不支持同一时间向同一个文件中写入)。
所以当我们知道我们的应用如果进行读,操作,我们可以让shelve通过只读的方式打开DB
不支持多个人同时写,支持多个人同时读,如果只是读的话,设置flag=“r”
import shelve f=shelve.open("shelve_file",flag="r") f["key"]={"int":10,"float":9.5,"string":"Sample data"}#直接对文件句柄操作,就可以存入文件 f.close()
正常情况下 shelve打开文件句柄感知不到值的修改,设置writeback=True就可以保存修改内容
import shelve f1=shelve.open("shelve_file",writeback=True) print(f1["key"]) #{'int': 10, 'float': 9.5, 'string': 'Sample data'} f1["key"]["new_value"]="this was not here before" f1.close() f1=shelve.open("shelve_file") exiting=f1["key"] #取出数据的时候也只需要直接用key获取即可,但是key不存在会报错 print(exiting) #{'int': 10, 'float': 9.5, 'string': 'Sample data', 'new_value': 'this was not here before'} f1.close()
writeback方式有优点也有缺点。优点是减少了我们出错的概率,并且让对象的持久化对用户更加的透明了;但这种方式并不是所有的情况下都需要,首先,使用writeback以后,shelf在open()的时候会增加额外的内存消耗,并且当DB在close()的时候会将缓存中的每一个对象都写入到DB,这也会带来额外的等待时间。因为shelve没有办法知道缓存中哪些对象修改了,哪些对象没有修改,因此所有的对象都会被写入
shelve只提供一个open,shelve,open(“文件名”)拿到一个文件句柄,这个文件句柄就可以当做字典的操作
import shelve f1=shelve.open("shelve_file") exiting=f1["key"] #取出数据的时候也只需要直接用key获取即可,但是key不存在会报错 print(exiting) #{'int': 10, 'float': 9.5, 'string': 'Sample data'} f1.close()
总结: json:所有语言通用,只能转换的数据类型有限*****
pickle:只限于Python,能转换所有的数据类型 做游戏的时候使用
shelve:只限于python语言,能转换所有的数据类型,使用方法类似字典
三、异常处理:

什么是异常:异常发生之后的代码就不执行了
什么是异常处理:python解释器检测到错误,触发异常(也允许程序自己触发异常)
程序员编写特定的代码,专门用来捕捉这个异常(这段代码与程序逻辑无关,与异常处理有关)
如果捕捉成功则进入另外一个处理分支,执行你为其定制的逻辑,使程序不会崩溃,这就是异常处理
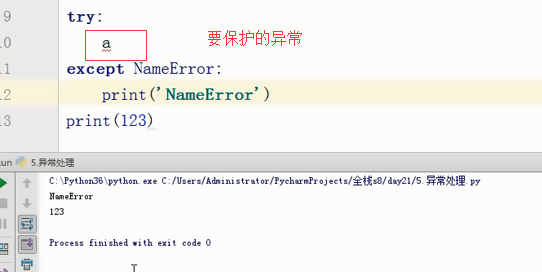
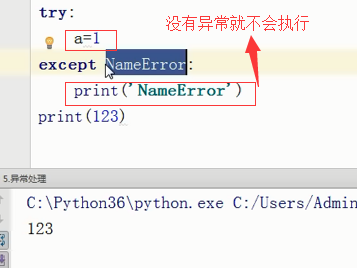
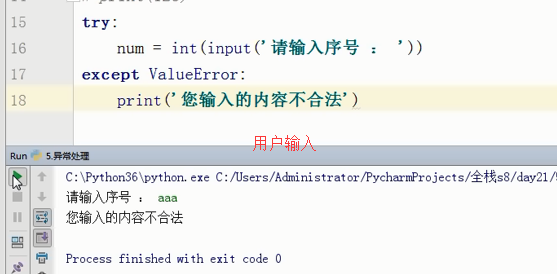
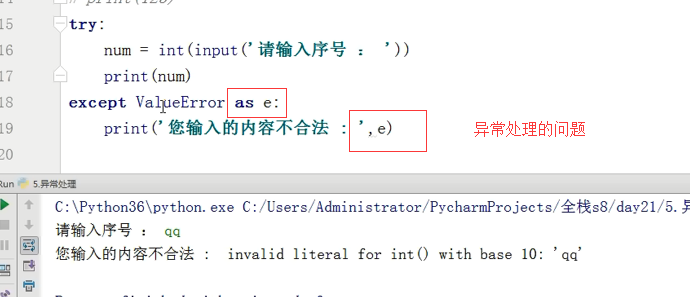
直接跳过了第二个错误的分支
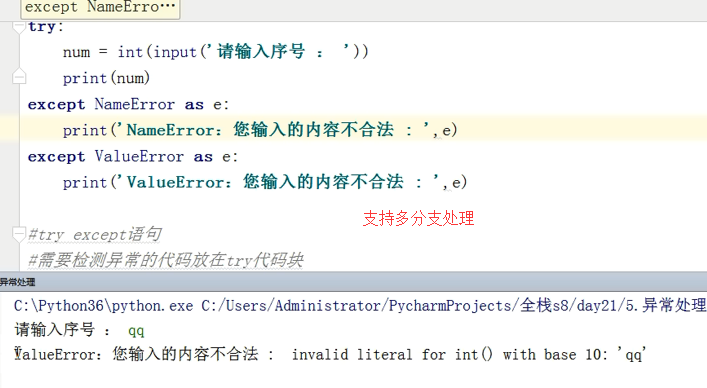
只要有一个except符合条件 下面的就不会执行了
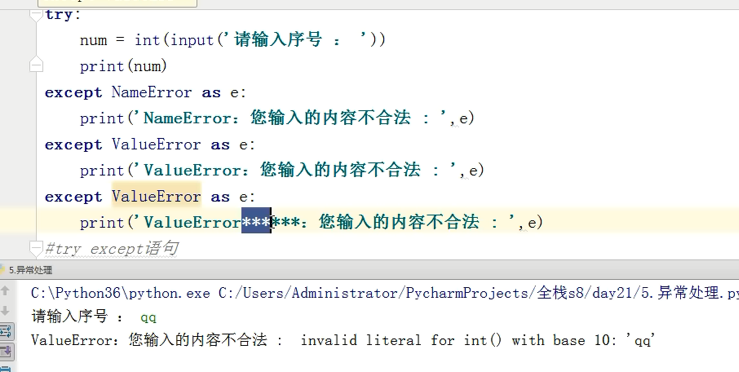
万能异常处理:忌讳使用
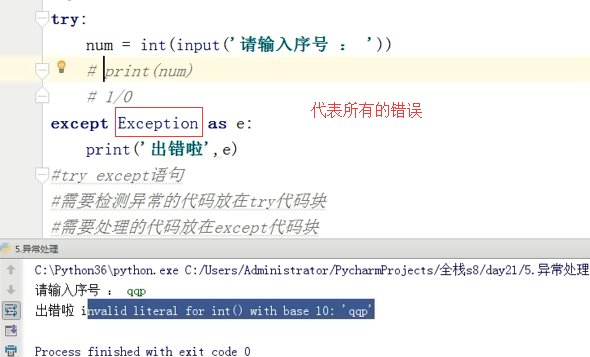
万能异常处理 应该放在其他的之后

总结:

异常处理的补充:
(1)
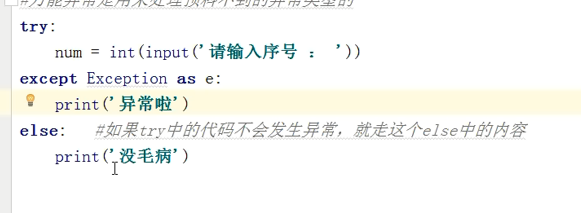
(2)

(4)
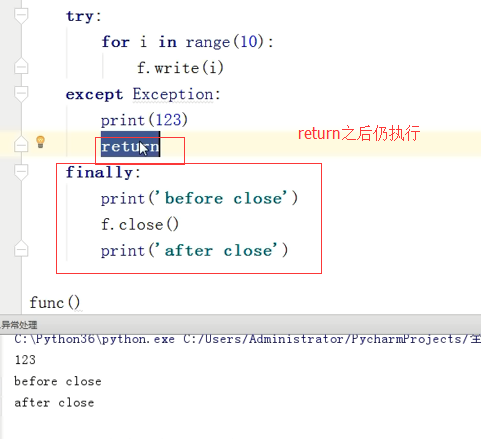
(5)在函数中 return之后仍然执行 finally之后的内容
def func(): f=open("f","w") try: for i in range(10): f.write(i) except Exception: print(123) return finally: print("before close") f.close() print("after close") func() # 123 # before close # after close
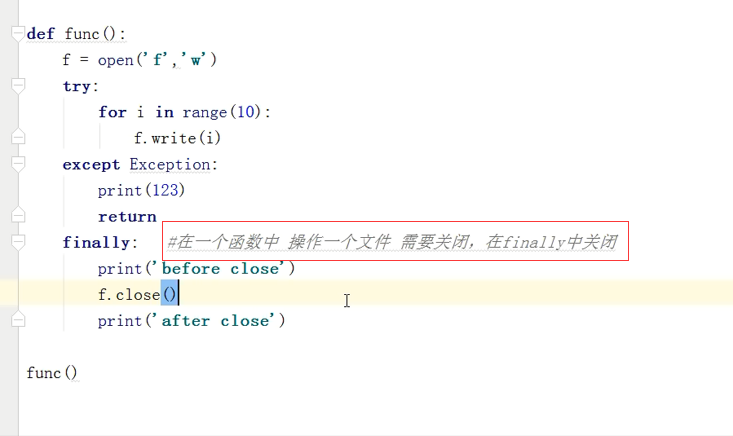
要注意的问题


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步