
一、内置函数的复习
1、三种从迭代器中取值的方法
#1、 print(list(ret)) #2、 next,__next__ #3、 for
2、相关内置函数
(1)reversed和reverse的区别
l=[1,2,3,54,6,3] ret=reversed(l) print(ret) print(list(ret)) #两者的区别,reversed返回迭代器,不返回原来的列表, # 不改变原来的列表,生成一个新的序列迭代器 # (一个一个取值的时候节省内存) l.reverse() print(l) #reverse 返回None 是在原本的基础上修改的
(2)slice 切片
l=[1,2,3,54,6,3,5,6,3] l1=slice(3,6,2) #l[3:6:2] 语法糖 print(l[l1]) #[54, 3]
3、字符串
(1)format
print(format("test","<20")) #左对齐 print(format("test",">20")) #右对齐 print(format("test","^20")) #居中对齐
整型数字可以提供的参数

浮点数可以提供的参数

计数方法


(2)bytes
#网络编程的时候,能在网络上传递的必须是字节 ret=bytes("你好",encoding="utf-8") #中间是网络传输过程 print(ret.decode(encoding="utf-8"))
(3)bytearrary
ret=bytearray("alex",encoding="utf-8") # 对比较长的字符串做修改是,指定某一处进行修改,不会改变这个bytearray的内部地址 print(id(ret)) #35639960 print(ret[0]) #97 ret[0]=65 print(ret) #bytearray(b'Alex') print(id(ret)) #35639960
(4)menmoryview
# menmoryview 只能对bytes切片 ret=memoryview(bytes("你好",encoding="utf-8")) print(ret) # print(len(ret)) #6 print(ret[:3]) # print(bytes(ret[:3]).decode("utf-8")) #你 print(bytes(ret[3:]).decode("utf-8")) #好
(5)ord 字符按照Unicode转数字
chr 数字按照Unicode转字符
print(ord("a")) #97 print(chr(97)) #a
(6)ascii 只要是ascii码中的内容,就打印出来,不是就转换成\u
print(ascii("a")) #'a' print(ascii(34)) #34
(6)reper 做字符串拼接的时候使用
print(repr("1")) #'1' print(repr("name:%r"%("金老板"))) #"name:'金老板'
4、数据集合
(1)dict 字典
(2)set
(3) frozenset 转变成可哈希的(不可变的类型)
5、相关内置函数
(1)len
(2)enumerate 枚举
l=["笔记本","phone","apple","banana"] for j,i in enumerate(l,1): print(j,i)
(3)all
print(all([1,2,3,4,0])) #False print(all([1,2,3,4])) #True print(all([1,2,3,None])) #False print(all([1,2,3," "])) #True
(4)any
与开始的数据有关系 print(any([True,None,False])) #True print(any([False,None,False])) #False
(5)zip
print(list(zip([1,2,3,4],[2,3,4,5]))) # [(1, 2), (2, 3), (3, 4), (4, 5)]
(6)filter 过滤函数,例子求列表中大于10的元素


def is_odd(x): if x>10: return True ret=filter(is_odd,[1,2,3,4,23,45,6,123]) print(list(ret)) #[23, 45, 123]
# filter 就是一个可迭代对象,想要有一个新的内容集,是从原可迭代对象中筛选出来的 def is_not_empty(s): return s and s.strip() ret=filter(is_not_empty,["1sad"," sdsf"," ","sfdsgf"]) print(list(ret))
import math def is_sqr(x): return math.sqrt(x)%1==0 ret=filter(is_sqr,range(1,101)) print(list(ret))
(7)map
fliter和map
参数很相:都是一个函数名+可迭代对象
返回值页很相近,都是返回可迭代对象
区别:
filter 是做筛选的,结果还是原来在可迭代对象中的项
map 是对可迭代对象中的每一项做操作的,结果不一定是原来在可迭代对象中的项
# 返回绝值,新内容等于原内容的个数 ret=map(abs,[-1,-3,-6,3,54,6]) print(list(ret)) # [1, 3, 6, 3, 54, 6]
def func(x): return x**2 ret=map(func,[1,2,3,4]) print(list(ret)) # [1, 4, 9, 16]
(8)sorted
sort一个直接修改原列表的顺序,节省内存
sorted 是生成一个新的列表,不改变原来的列表
key=func
print(sorted([-2,-3,2,3],reverse=True)) #[3, 2, -2, -3] print(sorted([1,2,3,-4,-23,34],key=abs)) #[1, 2, 3, -4, -23, 34] print(sorted(([1,322,34,23],"ssd"),key=len)) #['ssd', [1, 322, 34, 23]]
新内容:匿名函数
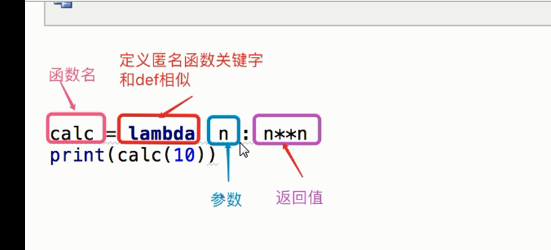
例子:
# 第一种 def add1(x,y):return x+y ret=add1(3,2) print(ret) # 第二种 add=lambda x,y:x+y print(add(1,2))
dic={"k1":10,"k2":100,"k3":30}
print(max(dic.values())) #100
print(max(dic)) #k3
print(max(dic,key=lambda k:dic[k])) #k2
def func(x): return x**2 ret=map(lambda x:x**2,[1,2,3,4,5]) print(list(ret))
def func(num): return num>99and num<1000 ret=filter(func,[124,3,5456,456,12]) print(list(ret)) # [124, 456] ret2=filter(lambda num:(num>99 and num<1000),[124,3,5456,456,12,243]) print(list(ret2)) # [124, 456, 243] def func(num1): if num1>10: return True ret=filter(lambda num1:num1>10,[1,23,34,12,2]) print(list(ret)) # [23, 34, 12] ret1=filter(lambda num:True if num>10 else False,[1,2243,354,4,5,34]) print(list(ret1)) # [2243, 354, 34]
比较常用的max min map filter
面试题:
1、
d=lambda p:p*2 t=lambda p:p*3 x=2 x=d(x) x=t(x) x=d(x) print(x)
2、现有两元组是((“a”),(“b”)),(("c'),("d")),
请使用python中匿名函数生成列表[{'a': 'c'}, {'b': 'd'}]
t1=(("a"),("b")) t2=(("c"),("d")) #t3=zip(t1,t2) print(list(map(lambda t:{t[0]:t[1]},zip(t1,t2)))) # [{'a': 'c'}, {'b': 'd'}]

3、

def multipliers(): return (lambda x:i*x for i in range(4)) print([m(2) for m in multipliers()]) # [0, 2, 4, 6]

