
 昨日回顾:
昨日回顾:
1、面试题(利用赋值的方式)
a,b=[1,2] print(a,b) #1 2 a=1 b=2 a,b=b,a print(a,b) # 2 1
2、知识回顾
# 字典:
dic={"name":"alex"}
(1)增
dic["k"]="v"
有键值对,则覆盖
setdefault 有键值对,不添加
dic={"name":"alex"}
dic.setdefault("k1","v1") 可以
dic.setdefault("name","barry") 不可以
print(dic)
(2)删
pop dic.pop("name") 有返回值,返回得是对应的值
dic.pop("k2",None)
dic popitem() 随机删除
del dic["name"]
del dic
clear 清空
(3)改
1 直接更改dic["name"]="v"
2 使用 update
dic={"name":"alex"}
dic2={"name":"barry","age":"18"}
dic.update(dic2)
print(dic) {'name': 'barry', 'age': '18'}
print(dic2) {'name': 'barry', 'age': '18'}
4、查
print(dic,keys())
print(dic.value())
print(dic.items()) #for k,v in dic.items():
#以上三个 都可以for循环
dic["name"]
dic.get("name")
昨日例题(购物车)


输出商品列表,用户输入序号,显示用户选中的商品 商品 li = ["手机", "电脑", '鼠标垫', '游艇'] 要求:1:页面显示 序号 + 商品名称,如: 1 手机 2 电脑 … 2: 用户输入选择的商品序号,然后打印商品名称 3:如果用户输入的商品序号有误,则提示输入有误,并重新输入。 4:用户输入Q或者q,退出程序。
li=["手机","电脑","鼠标垫","游艇"] while True: for index,name in enumerate(li,1): print(index,name) choice_goods=input("请输入商品序号:").strip() if choice_goods.isdigit(): choice_goods=int(choice_goods) if(choice_goods>0)and (choice_goods<=len(li)): print(li[choice_goods-1]) else:print("请输入有效范围内的序号") elif choice_goods.upper()=="Q": break else:print("请输入数字")
1、enumerate 的应用 (很重要)
li=["手机","电脑","鼠标垫","游艇"] for i in enumerate(li): print(i) for index,name in enumerate(li,1): print(index,name) for index,name in enumerate(li,100): #起始位置默认是0,可以更改 print(index,name)
三、今日新内容:
(1)id() (is==区别)
(2)编码
1、id(内存 地址)
# id(内存地址,地址是不断变化的)
s="alex" print(s,type(s)) #alex <class 'str'> print(s,type(s),id(s)) #alex <class 'str'> 31175376
li=[1,2,3]
print(li,type(li),id(li)) #[1, 2, 3] <class 'list'> 43203656
2、字符串 数字
=j= 比较的是值
is 比较的是内存地址
s1="alex" s2="alex" print(s1==s2) #True print(s1 is s2) #True print(s1,type(s1),id(s1)) #alex <class 'str'> 31175376 print(s2,type(s2),id(s2)) #alex <class 'str'> 31175376
说明:
对于int 小数据池
范围 :-5-------256 创建相同的数字,都指向同一个内存地址
对于字符串:小数据池,如果有空格,那指向两个内存地址,其他应该是一个
3、列表 字典 元组 set
li=[1,] l2=[1,] print(li==l2) #True print(li is l2) #False
4、关于不同的编码方式 unicode占用的内存较大,转换成bytes(utf-8 gbk) 用于硬盘存储以及传输
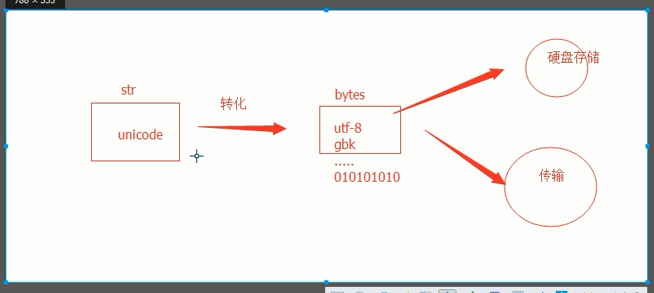
gbk 与utf-8之间的转化需要运用unicode

5、编码
不同的编码之间是不能相互识别的,会产生乱码
bytes 表现形式: s=b"alex" 内部存储是(utf-8,gbk,gb2312...)010101
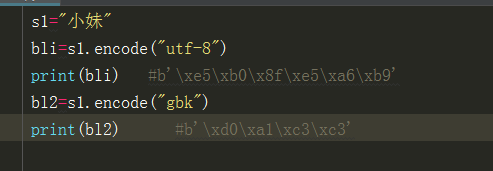
s1="小妹“
bl1=s1.encode("utf-8)
表现形式:bli=b'\xe5\xb0\x8f\xe5\xa6\xb9' (utf-8,gbk ,gb2312......)010101
0000 1000 0000 0000 0000 0001 0000 1001 0000 0000 0001
s2="小妹“
b22=s1.encode("gbk")
表现形式: s=b"\sxcf\xfc\xc3\xb7"(utf-8,gbk ,gb2312......)010101
0000 1000 0000 0000 0000 1001 0000 0000 0001
str 表现形式:a="alex" 内部存储是 unicode 0101010
