流量录制与回放技术实践
文章导读
本文主要介绍了流量录制与回放技术在压测场景下的应用。通过阅读本篇文章,你将了解到开源的录制工具如何与内部系统集成、如何进行二次开发以支持 Dubbo 流量录制、怎样通过 Java 类加载机制解决 jar 包版本冲突问题、以及流量录制在自动化测试场景下的应用与价值等。文章共约 1.4 万字,配图17张。本篇文章是对我个人过去一年所负责的工作的总结,里面涉及到了很多技术点,个人从中学到了很多东西,也希望这篇文章能让大家有所收获。当然个人能力有限,文中不妥之处也欢迎大家指教。具体章节安排如下:

1. 前言
本篇文章记录和总结了自己过去一年所主导的项目——流量录制与回放,该项目主要用于为业务团队提供压测服务。作为项目负责人,我承担了约 70% 的工作,所以这个项目承载了自己很多的记忆。从需求提出、技术调研、选型验证、问题处置、方案设计、两周内上线最小可用系统、推广使用、支持年中/终全链路压测、迭代优化、支持 dubbo 流量录制、到新场景落地产生价值。这里列举每一项自己都深度参与了,因此也从中学习到了很多东西。包含但不限于 go 语言、网络知识、Dubbo 协议细节,以及 Java 类加载机制等。除此之外,项目所产生的价值也让自己很欣喜。项目上线一年,帮助业务线发现了十几个性能问题,帮助中间件团队发现了基础组件多个严重的问题。总的来说,这个项目对于我个人来说具有非凡意义,受益良多。这里把过去一年的项目经历记录下来,做个总结。本篇文章着重讲实现思路,不会贴太多代码,有兴趣的朋友可以根据思路自己定制一套。好了,下面开始正文吧。
2. 项目背景
项目的出现源自业务团队的一个诉求——使用线上真实的流量进行压测,使压测更为“真实”一些。之所以业务团队觉得使用老的压测平台(基于 Jmeter 实现)不真实,是因为压测数据的多样性不足,对代码的覆盖度不够。常规压测任务通常都是对应用的 TOP 30 接口进行压测,如果人工去完善这些接口的压测数据,成本是会非常高的。基于这个需求,我们调研了一些工具,并最终选择了 Go 语言编写的 GoReplay 作为流量录制和回放工具。至于为什么选择这个工具,接下来聊聊。
3. 技术选型与验证
3.1 技术选型
一开始选型的时候,经验不足,并没有考虑太多因素,只从功能性和知名度两个维度进行了调研。首先功能上一定要能满足我们的需求,比如具备流量过滤功能,这样可以按需录制指定接口。其次,候选项最好有大厂背书,github 上有很多 star。根据这两个要求,选出了如下几个工具:

图1:技术选型
第一个是选型是阿里开源的工具,全称是 jvm-sandbox-repeater,这个工具其实是基于 JVM-Sandbox 实现的。原理上,工具通过字节码增强的形式,对目标接口进行拦截,以获取接口参数和返回值,效果等价于 AOP 中的环绕通知 (Around advice)。
第二个选型是 GoReplay,基于 Go 语言实现。底层依赖 pcap 库提供流量录制能力。著名的 tcpdump 也依赖于 pcap 库,所以可以把 GoReplay 看成极简版的 tcpdump,因为其支持的协议很单一,只支持录制 http 流量。
第三个选型是 Nginx 的流量镜像模块 ngx_http_mirror_module,基于这个模块,可以将流量镜像到一台机器上,实现流量录制。
第四个选型是阿里云云效里的子产品——双引擎回归测试平台,从名字上可以看出来,这个系统是为回归测试开发的。而我们需求是做压测,所以这个服务里的很多功能我们用不到。
经过比较筛选后,我们选择了 GoReplay 作为流量录制工具。在分析 GoReplay 优缺点之前,先来分析下其他几个工具存在的问题。
- jvm-sandbox-repeater 这个插件底层基于 JVM-Sandbox 实现,使用时需要把两个项目的代码都加载到目标应用内,对应用运行时环境有侵入。如果两个项目代码存在问题,造成类似 OOM 这种问题,会对目标应用造成很大大的影响。另外因为方向小众,导致 JVM-Sandbox 应用并不是很广泛,社区活跃度较低。因此我们担心出现问题官方无法及时修复,所以这个选型待定。
- ngx_http_mirror_module 看起来是个不错的选择,出生“名门”。但问题也有一些。首先只能支持 http 流量,而我们以后一定会支持 dubbo 流量录制。其次这个插件要把请求镜像一份出去,势必要消耗机器的 TCP 连接数、网络带宽等资源。考虑到我们的流量录制会持续运行在网关上,所以这些资源消耗一定要考虑。最后,这个模块没法做到对指定接口进行镜像,且镜像功能开关需要修改 nginx 配置实现。线上的配置是不可能,尤其是网关这种核心应用的配置是不能随便改动的。综合这些因素,这个选型也被放弃了。
- 阿里云的引擎回归测试平台在我们调研时,自身的功能也在打磨,用起来挺麻烦的。其次这个产品属于云效的子产品,不单独出售。另外这个产品主要还是用于回归测试的,与我们的场景存在较大偏差,所以也放弃了。
接着来说一下 GoReplay 的优缺点,先说优点:
-
单体程序,除了 pcap 库,没有其他依赖,也无需配置,所以环境准备很简单
-
本身是个可执行程序,可直接运行,很轻量。只要传入合适的参数就能录制,易使用
-
github 上的 star 数较多,知名度较大,且社区活跃
-
支持流量过滤功能、按倍速回放功能、回放时改写接口参数等功能,功能上贴合我们的需求
-
资源消耗小,不侵入业务应用 JVM 运行时环境,对目标应用影响较小
对于以 Java 技术栈为基础的公司来说,GoReplay 由于是 Go 语言开发的,技术栈差异很大,日后的维护和拓展是个大问题。所以单凭这一点,淘汰掉这个选型也是很正常的。但由于其优点也相对突出,综合其他选型的优缺点考虑后,我们最终还是选择了 GoReplay 作为最终的选型。最后大家可能会疑惑,为啥不选择 tcpdump。原因有两点,我们的需求比较少,用 tcpdump 有种大炮打蚊子的感觉。另一方面,tcpdump 给我们的感觉是太复杂了,驾驭不住(流下了没有技术的眼泪😭),因此我们一开始就没怎么考虑过这个选型。
| 选型 | 语言 | 是否开源 | 优点 | 缺点 |
|---|---|---|---|---|
| GoReplay | Go | ✅ | 1. 开源项目,代码简单,方便定制 2. 单体持续,依赖少,无需配置,环境准备简单 3. 工具很轻量,易使用 3. 功能相对丰富,能够满足我们所有的需求 4. 自带回放功能,能够直接使用录制数据,无需单独开发 5. 资源消耗少,且不侵入目标应用的 JVM 运行时环境,影响小 6. 提供了插件机制,且插件实现不限制语言,方便拓展 |
1. 应用不够广泛,无大公司背书,成熟度不够 2. 问题比较多,1.2.0 版本官方直接不推荐使用 3. 接上一条,对使用者的要求较高,出问题情况下要能自己读源码解决,官方响应速度一般 4. 社区版只支持 HTTP 协议,不支持二进制协议,且核心逻辑与 HTTP 协议耦合了,拓展较麻烦 5. 只支持命令行启动,没有内置服务,不好进行集成 |
| JVM-Sandbox jvm-sandbox-repeater |
Java | ✅ | 1. 通过增强的方式,可以直接对 Java 类方法进行录制,十分强大 2. 功能比较丰富,较为符合需求 3. 对业务代码透明无侵入 |
1. 会对应用运行时环境有一定侵入,如果发生问题,对应用可能会造成影响 2. 工具本身仍然偏向测试回归,所以导致一些功能在我们的场景下没法使用,比如不能使用它的回放功能进行高倍速压测 3. 社区活跃度较低,有停止维护的风险 4. 底层实现确实比较复杂,维护成本也比较高。再次留下了没有技术的眼泪😢 5. 需要搭配其他的辅助系统,整合成本不低 |
| ngx_http_mirror_module | C | ✅ | 1. nginx 出品,成熟度可以保证 2. 配置比较简单 |
1. 不方便启停,也不支持过滤 2. 必须和 nginx 搭配只用,因此使用范围也比较受限 |
| 阿里云引擎回归测试平台 | - | ❌ | - | - |
3.2 选型验证
选型完成后,紧接着要进行功能、性能、资源消耗等方面的验证,测试选型是否符合要求。根据我们的需求,做了如下的验证:
- 录制功能验证,验证流量录制的是否完整,包含请求数量完整性和请求数据准确性。以及在流量较大情况下,资源消耗情况验证
- 流量过滤功能验证,验证能否过滤指定接口的流量,以及流量的完整性
- 回放功能验证,验证流量回放是否能如预期工作,回放的请求量是否符合预期
- 倍速回放验证,验证倍速功能是否符合预期,以及高倍速回放下资源消耗情况
以上几个验证当时在线下都通过了,效果很不错,大家也都挺满意的。可是倍速回放这个功能,在生产环境上进行验证时,回放压力死活上不去,只能压到约 600 的 QPS。之后不管再怎么增压,QPS 始终都在这个水位。我们与业务线同事使用不同的录制数据在线上测试了多轮均不行,开始以为是机器资源出现了瓶颈。可是我们看了 CPU 和内存消耗都非常低,TCP 连接数和带宽也是很富余的,因此资源是不存在瓶颈的。这里也凸显了一个问题,早期我们只对工具做了功能测试,没有做性能测试,导致这个问题没有尽早暴露出来。于是我自己在线下用 nginx 和 tomcat 搭建了一个测试服务,进行了一些性能测试,发现随随便便就能压到几千的 QPS。看到这个结果啼笑皆非,脑裂了😭。后来发现是因为线下的服务的 RT 太短了,与线上差异很大导致的。于是让线程随机睡眠几十到上百毫秒,此时效果和线上很接近。到这里基本上能够大致确定问题范围了,应该是 GoReplay 出现了问题。但是 GoReplay 是 Go 语言写的,大家对 Go 语言都没经验。眼看着问题解决唾手可得,可就是无处下手,很窒息。后来大佬们拍板决定投入时间深入 GoReplay 源码,通过分析源码寻找问题,自此我开始了 Go 语言的学习之路。原计划两周给个初步结论,没想到一周就找到了问题。原来是因为 GoReplay v1.1.0 版本的使用文档与代码实现出现了很大的偏差,导致按照文档操作就是达不到预期效果。具体细节如下:

图2:GoReplay 使用说明
先来看看坑爹的文档是怎么说的,--output-http-workers 这个参数表示有多少个协程同时用于发生 http 请求,默认值是0,也就是无限制。再来看看代码(output_http.go)是怎么实现的:

图3:GoRepaly 协程并发数决策逻辑
文档里说默认 http 发送协程数无限制,结果代码里设置了 10,差异太大了。为什么 10 个协程不够用呢,因为协程需要原地等待响应结果,也就是会被阻塞住,所以10个协程能够打出的 QPS 是有限的。原因找到后,我们明确设定 --output-http-workers 参数值,倍速回放的 QPS 最终验证下来能够达到要求。
这个问题发生后,我们对 GoReplay 产生了很大的怀疑,感觉这个问题比较低级。这样的问题都会出现,那后面是否还会出现有其他问题呢,所以用起来心里发毛。当然,由于这个项目维护的人很少,基本可以认定是个人项目。且该项目经过没有大规模的应用,尤其没有大公司的背书,出现这样的问题也能理解,没必要太苛责。因此后面碰到问题只能见招拆招了,反正代码都有了,直接白盒审计吧。
3.3 总结与反思
先说说选型过程中存在的问题吧。从上面的描述上来看,我在选型和验证过程均犯了一些较为严重的错误,被自己生动的上了一课。在选型阶段,对于知名度,居然认为 star 比较多就算比较有名了,现在想想还是太幼稚了。比起知名度,成熟度其实更重要,稳定坑少下班早🤣。另外,可观测性也一定要考虑,否则查问题时你将体验到什么是无助感。
在验证阶段,功能验证没有太大问题。但性能验证只是象征性的搞了一下,最终在与业务线同事一起验证时翻车了。所以验证期间,性能测试是不能马虎的,一旦相关问题上线后才发现,那就很被动了。
根据这次的技术选型经历做个总结,以后搞技术选型时再翻出来看看。选型维度总结如下:
| 维度 | 说明 |
|---|---|
| 功能性 | 1. 选型的功能是否能够满足需求,如果不满足,二次开发的成本是怎样的 |
| 成熟度 | 1. 在相关领域内,选型是否经过大范围使用。比如 Java Web 领域,Spring 技术栈基本人尽皆知 2. 一些小众领域的选型可能应用并不是很广泛,那只能自己多去看看 issue,搜索一些踩坑记录,自行评估了 |
| 可观测性 | 1. 内部状态数据是否有观测手段,比如 GoReplay 会把内部状态数据定时打印出来 2. 方不方便接入公司的监控系统也要考虑,毕竟人肉观察太费劲 |
验证总结如下:
- 根据要求一项一项的去验证选型的功能是否符合预期,可以搞个验证的 checklist 出来,逐项确认
- 从多个可能的方面对选型进行性能测试,在此过程中注意观察各种资源消耗情况。比如 GoReplay 流量录制、过滤和回放功能都是必须要做性能测试的
- 对选型的长时间运行的稳定性要进行验证,对验证期间存在的异常情况注意观测和分析
- 更严格一点,可以做一些故障测试。比如杀进程,断网等
关于选型更详细的实战经验,可以参考李运华大佬的文章:如何正确的使用开源项目。
4. 具体实践
当技术选型和验证都完成后,接下来就是要把想法变为现实的时候了。按照现在小步快跑,快速迭代的模式,启动阶段通常我们仅会规划最核心的功能,保证流程走通。接下来再根据需求的优先级进行迭代,逐步完善。接下来,我将在按照项目的迭代过程来进行介绍。
4.1 最小可用系统
4.1.1 需求介绍
| 序号 | 分类 | 需求点 | 说明 |
|---|---|---|---|
| 1 | 录制 | 流量过滤,按需录制 | 支持按 HTTP 请求路径过滤流量,这样可以录制指定接口的流量 |
| 2 | 录制时长可指定 | 可设定录制时长,一般情况下都是录制10分钟,把流量波峰录制下来 | |
| 3 | 录制任务详情 | 包含录制状态、录制结果统计等信息 | |
| 4 | 回放 | 回放时长可指定 | 支持设定 1 ~ 10 分钟的回放时长 |
| 5 | 回放倍速可指定 | 根据录制时的 QPS,按倍数进行流量放大,最小粒度为 1 倍速 | |
| 6 | 回放过程允许人为终止 | 在发现被压测应用出现问题时,可人为终止回放过程 | |
| 7 | 回放任务详情 | 包含回放状态、回放结果统计 |
以上就是项目启动阶段的需求列表,这些都是最基本需求。只要完成这些需求,一个最小可用的系统就实现了。
4.1.2 技术方案简介
4.1.2.1 架构图
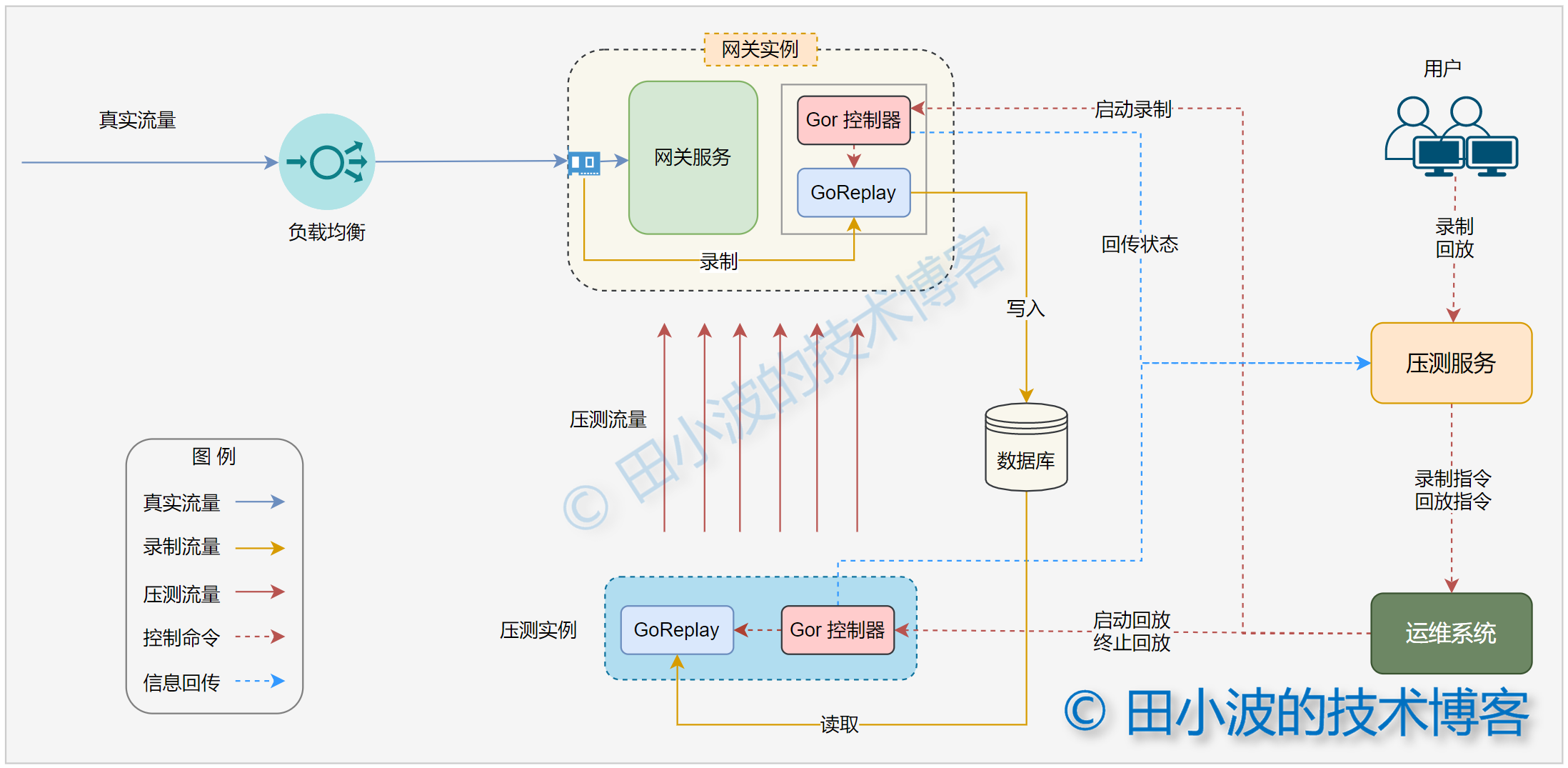
图4:压测系统一期架构图
上面的架构图经过编辑,与实际有一定差异,但不影响讲解。需要说明的是,我们的网关服务、压测机以及压测服务都是分别由多台构成,所有网关和压测实例均部署了 GoRepaly 及其控制器。这里为了简化架构图,只画了一台机器。下面对一些核心流程进行介绍。
4.1.2.2 Gor 控制器
在介绍其他内容之前,先说一下 Gor 控制器的用途。用一句话介绍:引入这个中间层的目的是为了将 GoReplay 这个命令行工具与我们的压测系统进行整合。这个模块是我们自己开发,最早使用 shell 编写的(苦不堪言😭),后来用 Go 语言重写了。Gor 控制器主要负责下面一些事情:
- 掌握 GoRepaly 生杀大权,可以调起和终止 GoReplay 程序
- 屏蔽掉 GoReplay 使用细节,降低复杂度,提高易用性
- 回传状态,在 GoReplay 启动前、结束后、其他标志性事件结束后都会向压测系统回传状态
- 对录制和回放产生数据进行处理与回传
- 打日志,记录 GoRepaly 输出的状态数据,便于后续排查
GoReplay 本身只提供最基本的功能,可以把其想象成一个只有底盘、轮子、方向盘和发动机等基本配件的汽车,虽然能开起来,但是比较费劲。而我们的 Gor 控制器相当于在其基础上提供了一键启停,转向助力、车联网等增强功能,让其变得更好用。当然这里只是一个近似的比喻,不要纠结合理性哈。知晓控制器的用途后,下面介绍启动和回放的执行过程。
4.1.2.3 录制过程介绍
用户的录制命令首先会发送给压测服务,压测服务原本可以通过 SSH 直接将录制命令发送给 Gor 控制器的,但出于安全考虑必须绕道运维系统。Gor 控制器收到录制命令后,参数验证无误,就会调起 GoReplay。录制结束后,Gor 控制器会将状态回传给压测系统,由压测判定录制任务是否结束。详细的流程如下:
- 用户设定录制参数,提交录制请求给压测服务
- 压测服务生成压测任务,并根据用户指定的参数生成录制命令
- 录制命令经由运维系统下发到具体的机器上
- Gor 控制器收到录制命令,回传“录制即将开始”的状态给压测服务,随后调起 GoReplay
- 录制结束,GoReplay 退出,Gor 控制器回传“录制结束”状态给压测服务
- Gor 控制器回传其他信息给压测系统
- 压测服务判定录制任务结束后,通知压测机将录制数据读取到本地文件中
- 录制任务结束
这里说明一下,要想使用 GoReplay 倍速回放功能,必须要将录制数据存储到文件中。然后通过下面的参数设置倍速:
# 三倍速回放
gor --input-file "requests.gor|300%" --output-http "test.com"
4.1.2.4 回放过程介绍
回放过程与录制过程基本相似,只不过回放的命令是固定发送给压测机的,具体过程就不赘述了。下面说几个不同点:
- 给回放流量打上压测标:回放流量要与真实流量区分开,需要一个标记,也就是压测标
- 按需改写参数:比如把 user-agent 改为 goreplay,或者增加测试账号的 token 信息
- GoReplay 运行时状态收集:包含 QPS,任务队列积压情况等,这些信息可以帮助了解 GoReplay 的运行状态
4.1.3 不足之处
这个最小可用系统在线上差不多运行了4个月,没有出现过太大的问题,但仍然有一些不足之处。主要有两点:
- 命令传递的链路略长,增大的出错的概率和排查的难度。比如运维系统的接口偶尔失败,关键还没有日志,一开始根本没法查问题
- Gor 控制器是用 shell 写的,约 300 行。shell 语法和 Java 差异比较大,代码也不好调试。同时对于复杂的逻辑,比如生成 JSON 字符串,写起来很麻烦,后续维护成本较高
这两点不足一直伴随着我们的开发和运维工作,直到后面进行了一些优化,才算是彻底解决掉了这些问题。
4.2 持续优化
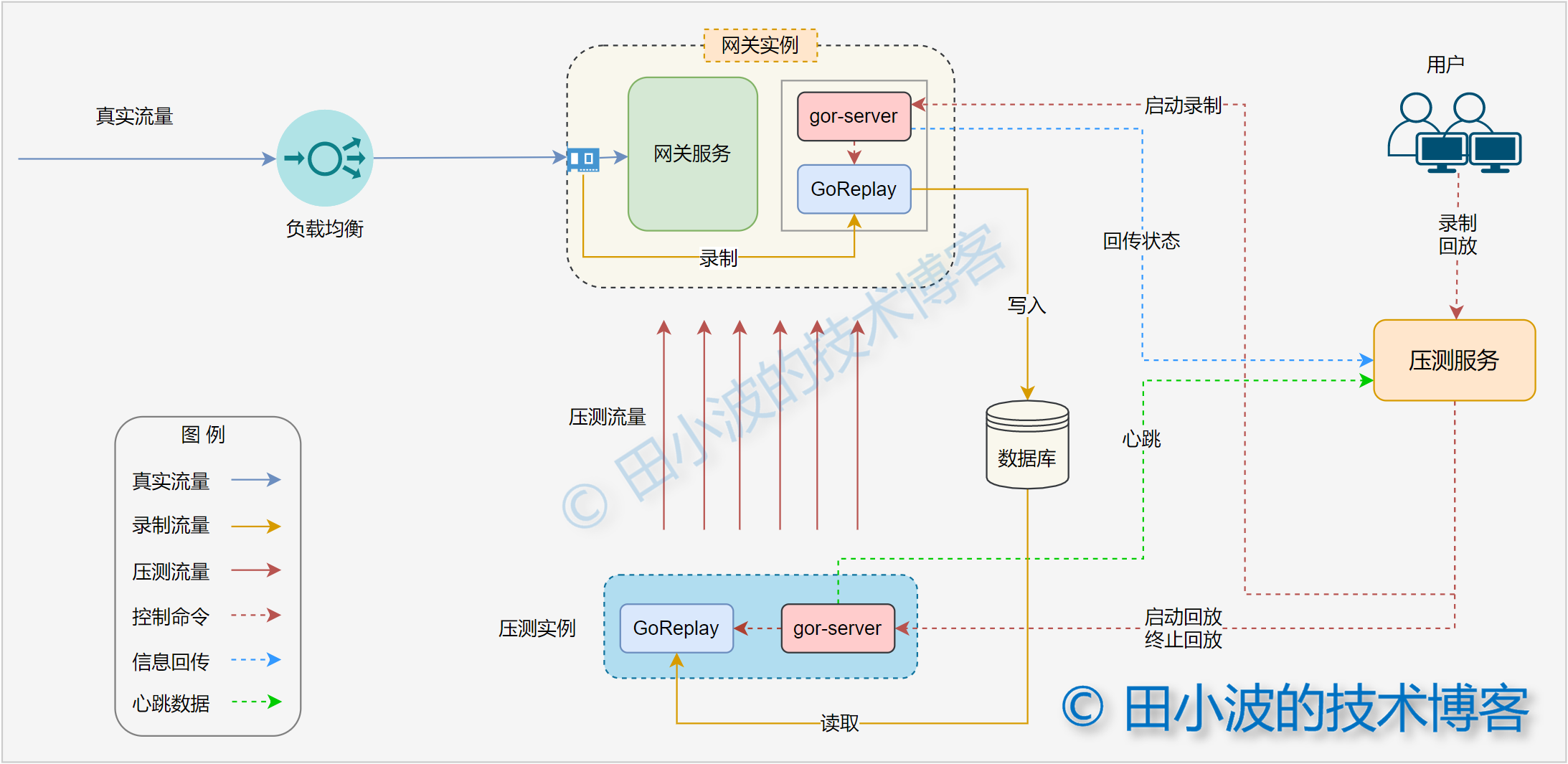
图5:Gor 控制器优化后的架构图
针对前面存在的痛点,我们进行了针对性的改进。重点使用 Go 语言重写了 gor 控制器,新的控制器名称为 gor-server。从名称上可以看出,我们内置了一个 HTTP 服务。基于这个服务,压测服务下发命令终于不用再绕道运维系统了。同时所有的模块都在我们的掌控中,开发和维护的效率明显变高了。
4.3 支持 Dubbo 流量录制
我们内部采用 Dubbo 作为 RPC 框架,应用之间的调用均是通过 Dubbo 来完成的,因此我们对 Dubbo 流量录制也有较大的需求。在针对网关流量录制取得一定成果后,一些负责内部系统的同事也希望通过 GoReplay 来进行压测。为了满足内部的使用需求,我们对 GoReplay 进行了二次开发,以便支持 Dubbo 流量的录制与回放。
4.3.1 Dubbo 协议介绍
要对 Dubbo 录制进行支持,需首先搞懂 Dubbo 协议内容。Dubbo 是一个二进制协议,它的编码规则如下图所示:

图6:Dubbo 协议图示;来源:Dubbo 官方网站
下面简单对协议做个介绍,按照图示顺序依次介绍各字段的含义。
| 字段 | 位数(bit) | 含义 | 说明 |
|---|---|---|---|
| Magic High | 8 | 魔数高位 | 固定为 0xda |
| Magic Low | 8 | 魔数低位 | 固定为 0xbb |
| Req/Res | 1 | 数据包类型 | 0 - Response 1 - Request |
| 2way | 1 | 调用方式 | 0 - 单向调用 1 - 双向调用 |
| Event | 1 | 事件标识 | 比如心跳事件 |
| Serialization ID | 5 | 序列化器编号 | 2 - Hessian2Serialization 3 - JavaSerialization 4 - CompactedJavaSerialization 6 - FastJsonSerialization ...... |
| Status | 8 | 响应状态 | 状态列表如下: 20 - OK 30 - CLIENT_TIMEOUT 31 - SERVER_TIMEOUT 40 - BAD_REQUEST 50 - BAD_RESPONSE ...... |
| Request ID | 64 | 请求 ID | 响应头中也会携带相同的 ID,用于将请求和响应关联起来 |
| Data Length | 32 | 数据长度 | 用于标识 Variable Part 部分的长度 |
| Variable Part(payload) | - | 数据载荷 |
知晓了协议内容后,我们把官方的 demo 跑起来,抓个包研究一下。
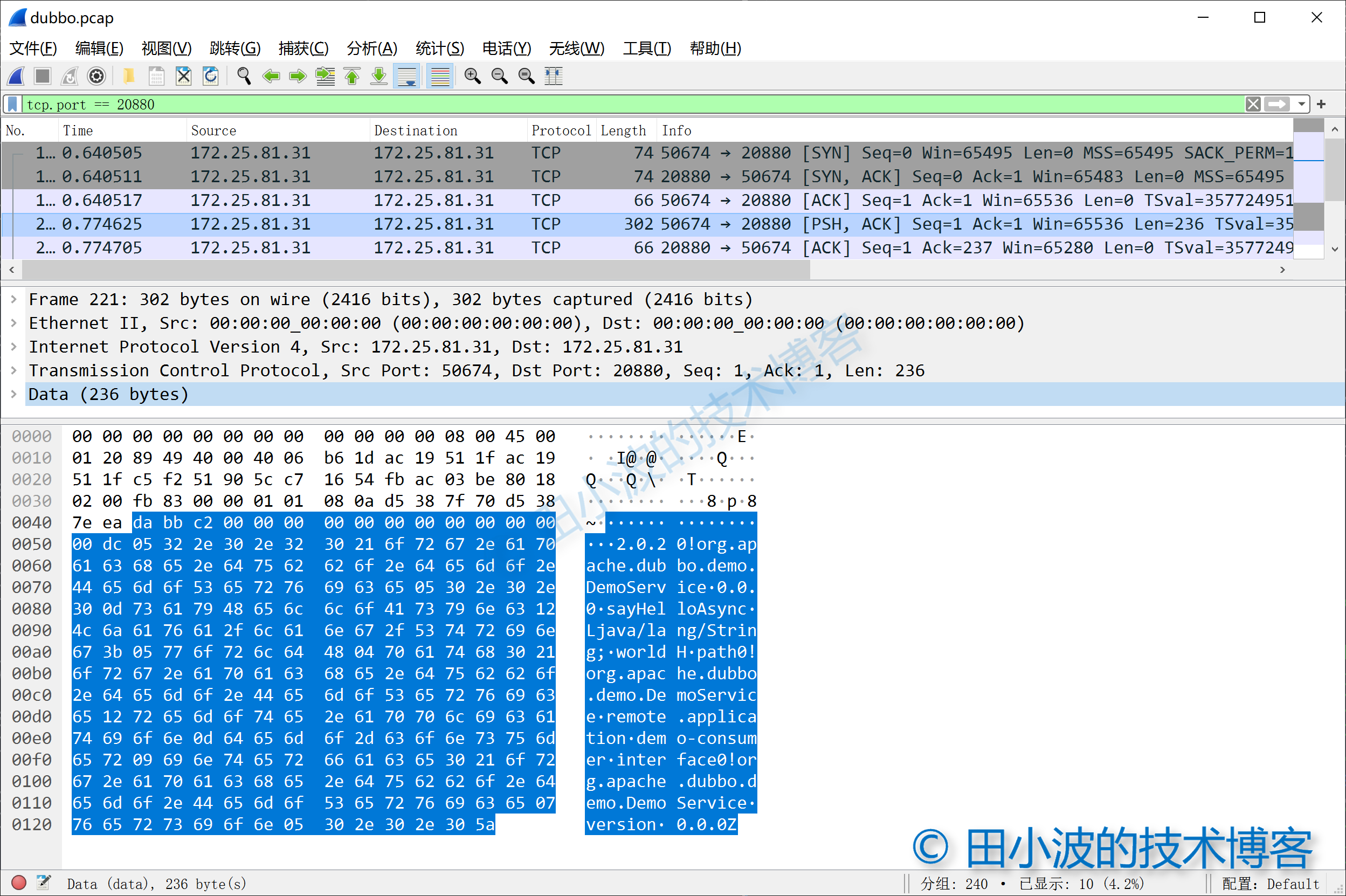
图7:dubbo 请求抓包
首先我们可以看到占用两个字节的魔数 0xdabb,接下来的14个字节是协议头中的其他内容,简单分析一下:

图8:dubbo 请求头数据分析
上面标注的比较清楚了,这里稍微解释一下。从第三个字节可以看出这个数据包是一个 Dubbo 请求,因为是第一个请求,所以请求 ID 是 0。数据的长度是 0xdc,换算成十进制为 220 个字节。加上16个字节的消息头,总长度正好是 236,与抓包结果显示的长度是一致。
4.3.2 Dubbo 协议解析
我们对 Dubbo 流量录制进行支持,首先需要按照 Dubbo 协议对数据包进行解码,以判断录制到的数据是不是 Dubbo 请求。那么问题来了,如何判断所录制到的 TCP 报文段里的数据是 Dubbo 请求呢?答案如下:
- 首先判断数据长度是不是大于等于协议头的长度,即 16 个字节
- 判断数据前两个字节是否为魔数 0xdabb
- 判断第17个比特位是不是 1,不为1可丢弃掉
通过上面的检测可快速判断出数据是否符合 Dubbo 请求格式。如果检测通过,那接下来又如何判断录制到的请求数据是否完整呢?答案是通过比较录制到的数据长度 L1 和 Data Length 字段给出的长度 L2,根据比较结果进行后续操作。有如下几种情况:
- L1 == L2,说明数据接收完整,无需额外的处理逻辑
- L1 < L2,说明还有一部分数据没有接收,继续等待余下数据
- L1 > L2,说明多收到了一些数据,这些数据并不属于当前请求,此时要根据 L2 来切分收到的数据
三种情况示意图如下:
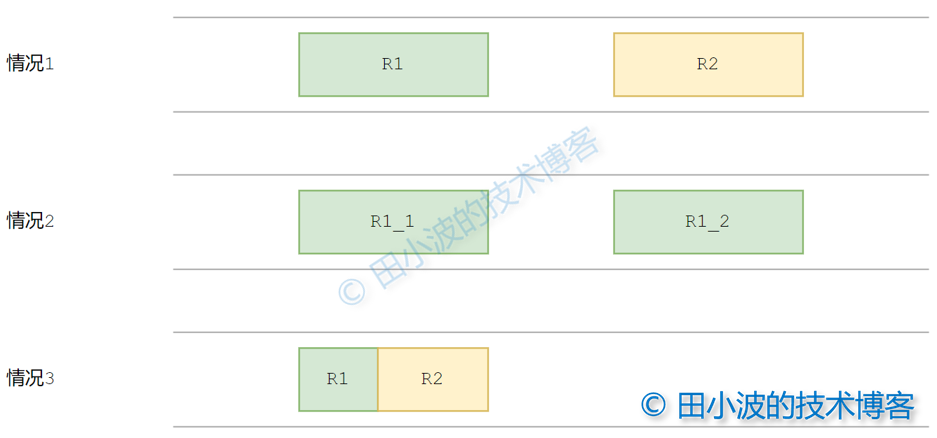
图9:应用层接收端几种情况
看到这里,肯定有同学想说,这不就是典型的 TCP “粘包”和“拆包”问题。不过我并不想用这两个词来说明上述的一些情况。TCP 是一个面向字节流的协议,协议本身并不存在所谓的“粘包”和“拆包”问题。TCP 在传输数据过程中,并不会理会上层数据是如何定义的,在它看来都是一个个的字节罢了,它只负责把这些字节可靠有序的运送到目标进程。至于情况2和情况3,那是应用层应该去处理的事情。因此,我们可以在 Dubbo 的代码中找到相关的处理逻辑,有兴趣的同学可以阅读 NettyCodecAdapter.InternalDecoder#decode 方法代码。
本小节内容就到这里,最后给大家留下一个问题。在 GoReplay 的代码中,并没有对情况3进行处理。为什么录制 HTTP 协议流量不会出错?
4.3.3 GoReplay 改造
4.3.3.1 改造介绍
GoReplay 社区版目前只支持 HTTP 流量录制,其商业版支持部分二进制协议,但不支持 Dubbo。所以为了满足内部使用需求,只能进行二次开发了。但由于社区版代码与 HTTP 协议处理逻辑耦合比较大,因此想要支持一种新的协议录制,还是比较麻烦的。在我们的实现中,对 GoReplay 的改造主要包含 Dubbo 协议识别,Dubbo 流量过滤,数据包完整性判断等。数据包的解码和反序列化则是交给 Java 程序来实现的,序列化结果转成 JSON 进行存储。效果如下:
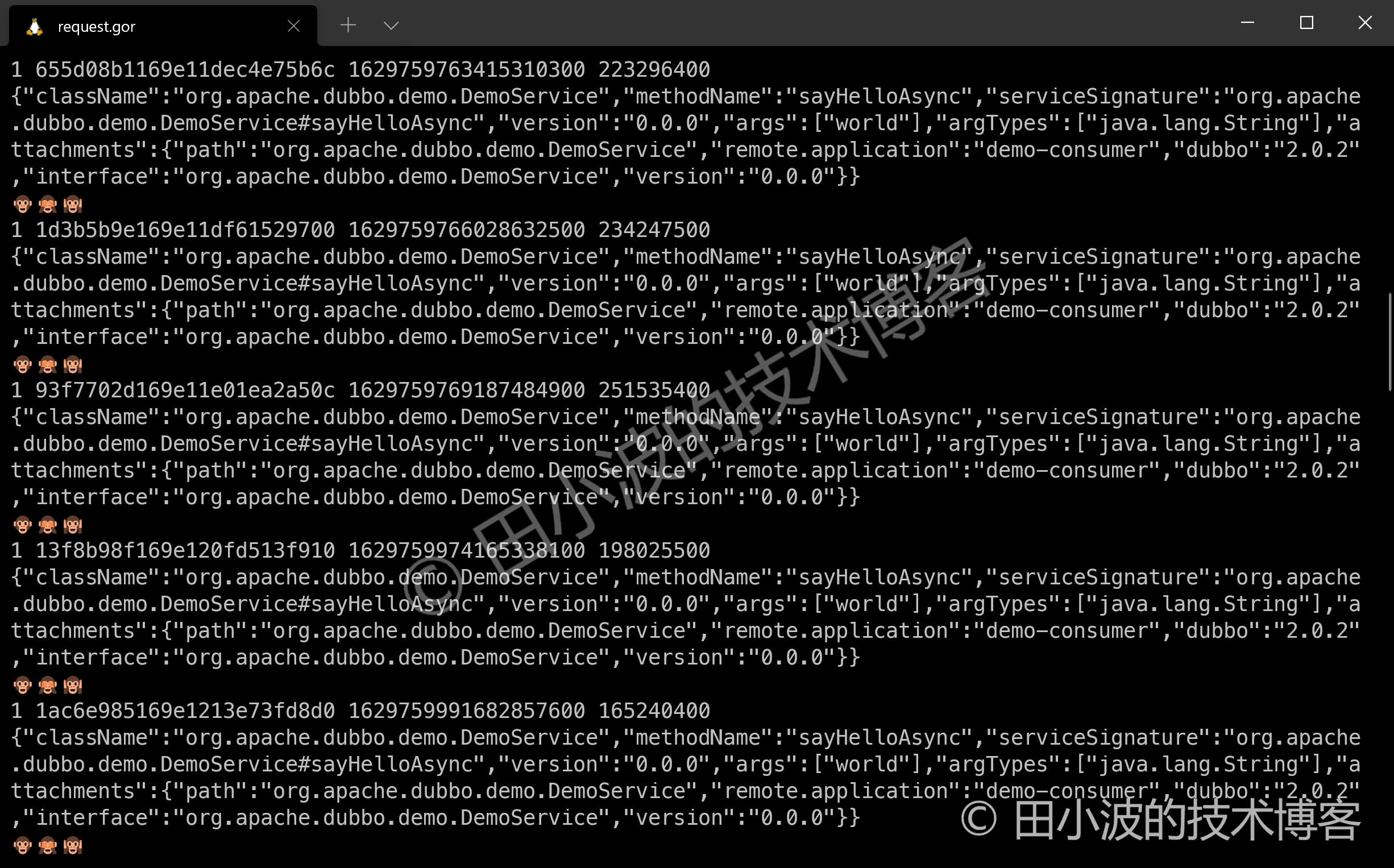
图10:Dubbo 流量录制效果
GoReplay 用三个猴头 🐵🙈🙉 作为请求分隔符,第一眼看到感觉挺搞笑的。
4.3.3.2 GoReplay 插件机制介绍
大家可能很好奇 GoReplay 是怎么和 Java 程序配合工作的,原理倒也是很简单。先看一下怎么开启 GoReplay 的插件模式:
gor --input-raw :80 --middleware "java -jar xxx.jar" --output-file request.gor
通过 middleware 参数可以传递一条命令给 GoRepaly,GoReplay 会拉起一个进程执行这个命令。在录制过程中,GoReplay 通过获取进程的标准输入和输出与插件进程进行通信。数据流向大致如下:
+-------------+ Original request +--------------+ Modified request +-------------+
| Gor input |----------STDIN---------->| Middleware |----------STDOUT---------->| Gor output |
+-------------+ +--------------+ +-------------+
input-raw java -jar xxx.jar output-file
4.3.3.3 Dubbo 解码插件实现思路
Dubbo 协议的解码还是比较容易实现的,毕竟很多代码 Dubbo 框架已经写好了,我们只需要按需对代码进行修改定制即可。协议头的解析逻辑在 DubboCodec#decodeBody 方法中,消息体的解析逻辑在 DecodeableRpcInvocation#decode(Channel, InputStream) 方法中。由于 GoReplay 已经对数数据进行过解析和处理,因此在插件里很多字段就没必要解析了,只要解析出 Serialization ID 即可。这个字段将指导我们进行后续的反序列化操作。
对于消息体的解码稍微麻烦点,我们把 DecodeableRpcInvocation 这个类代码拷贝一份放在插件项目中,并进行了修改。删除了不需要的逻辑,只保留了 decode 方法,将其变成了工具类。考虑到我们的插件不方便引入要录制应用的 jar 包,所以在修改 decode 方法时,还要注意把和类型相关的逻辑移除掉。修改后的代码大致如下:
public class RpcInvocationCodec {
public static MyRpcInvocation decode(byte[] bytes, int serializationId) {
ObjectInput in = CodecSupport.getSerializationById(serializationId).deserialize(null, input);
MyRpcInvocation rpcInvocation = new MyRpcInvocation();
String dubboVersion = in.readUTF();
// ......
rpcInvocation.setMethodName(in.readUTF());
// 原代码:Class<?>[] pts = DubboCodec.EMPTY_CLASS_ARRAY;
// 修改后把 pts 类型改成 String[],泛化调用时需要用到类型列表
String[] pts = desc2className(int.readUTF());
Object[] args = new Object[pts.length];
for (int i = 0; i < args.length; i++) {
// 原代码:args[i] = in.readObject(pts[i]);
// 修改后不在依赖具体类型,直接反序列化成 Map
args[i] = in.readObject();
}
rpcInvocation.setArguments(args);
rpcInvocation.setParameterTypeNames(pts);
return rpcInvocation;
}
}
仅从代码开发的角度来说,难度并不是很大,当然前提是要对 Dubbo 的源码有一定的了解。对我来说,时间主要花在 GoRepaly 的改造上,主要原因是对 Go 语言不熟,边写边查导致效率很低。当功能写好,调试完毕,看到结果正确输出,确实很开心。但是,这种开心也仅维持了很短的时间。不久在与业务同事进行线上验证的时候,插件花样崩溃,场面一度十分尴尬。报错信息看的我一脸懵逼,一时半会解决不了,为了保留点脸面,赶紧终止了验证🤪。事后排查发现,在将一些的特殊的反序列化数据转化成 JSON 格式时,出现了死循环,造成 StackOverflowError 错误发生。由于插件主流程是单线程的,且仅捕获了 Exception,所以造成了插件错误退出。
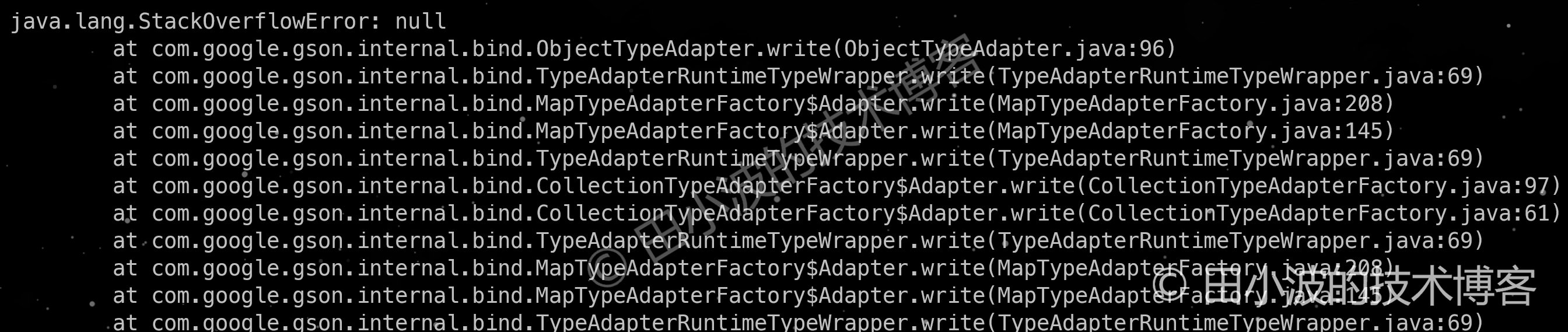
图11:循环依赖导致 Gson 框架报错
这个错误告诉我们,类之间出现了循环引用,我们的插件代码也确实没有对循环引用进行处理,这个错误发生是合理的。但当找到造成这个错误的业务代码时,并没找到循环引用,直到我本地调试时才发现了猫腻。业务代码类似的代码如下:
public class Outer {
private Inner inner;
public class Inner {
private Long xyz;
public class Inner() {
}
}
}
问题出在了内部类上,Inner 会隐式持有 Outer 引用。不出意外,这应该是编译器干的。源码面前了无秘密,我们把内部类的 class 文件反编译一下,一切就明了了。
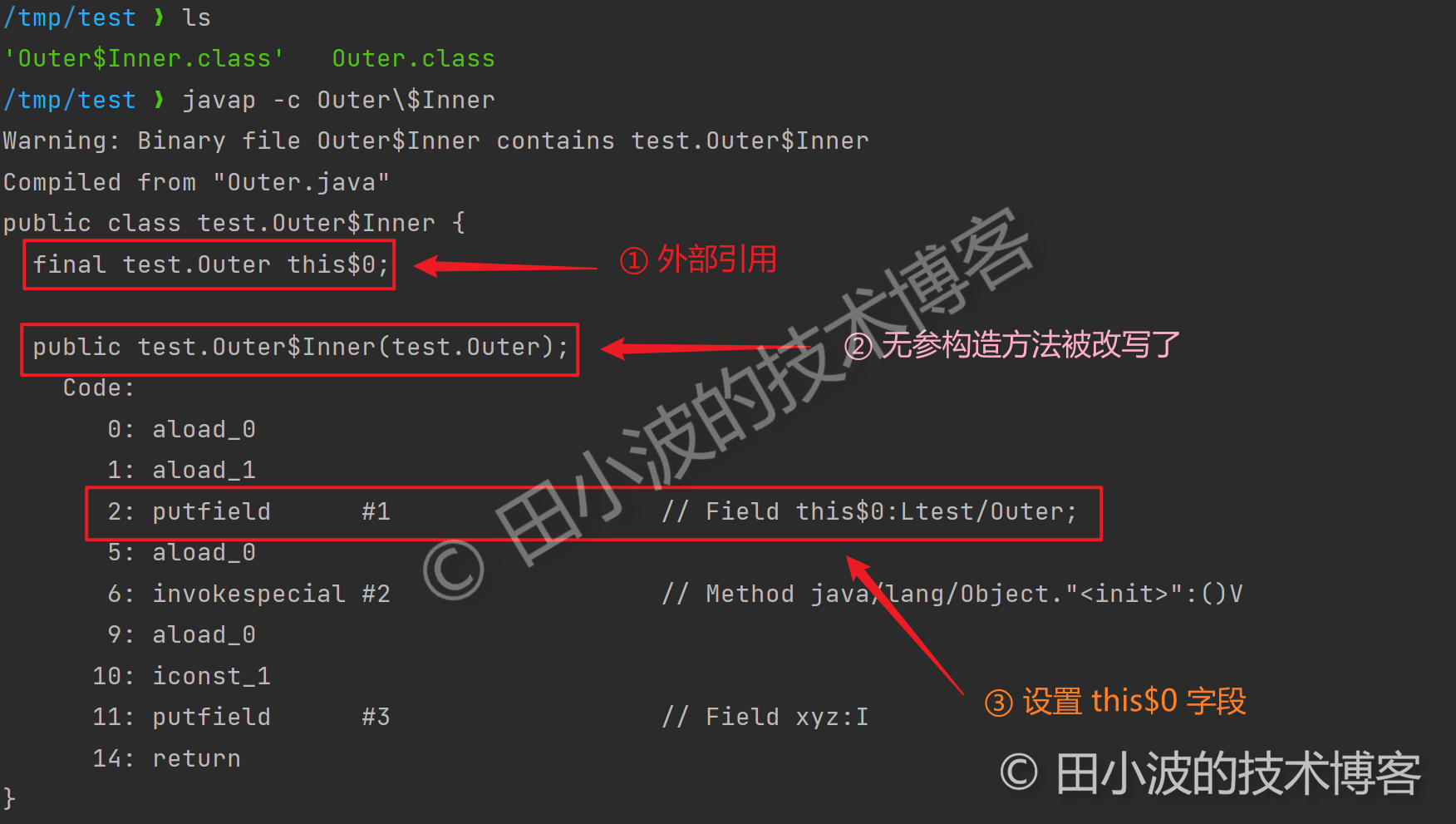
图12:内部类反编译结果
这应该算是 Java 基本知识了,奈何平时用的少,第一眼看到代码时,没看出了隐藏在其中的循环引用。到这里解释很合理,这就结束了么?其实还没有,实际上 Gson 序列化 Outer 时并不会报错,调试发现其会排除掉 this$0 这个字段,排除逻辑如下:
public final class Excluder
public boolean excludeField(Field field, boolean serialize) {
// ......
// 判断字段是否是合成的
if (field.isSynthetic()) {
return true;
}
}
}
那么我们在把录制的流量转成 JSON 时为什么会报错呢?原因是我们的插件反序列化时拿不到接口参数的类型信息,所以我们把参数反序列化成了 Map 对象,这样 this$0 这个字段和值也会作为键值对存储到 Map 中。此时 Gson 的过滤规则就不生效了,没法过滤掉 this$0 这个字段,造成了死循环,最终导致栈溢出。知道原因后,这么问题怎么解决呢?下一小节展开。
4.3.3.4 直击问题
我开始考虑是不是可以人为清洗一下 Map 里的数据,但发现好像很难搞。如果 Map 的数据结构很复杂,比如嵌套了很多层,清洗逻辑可能不好实现。还有我也不清楚这里面会不会有其他的一些弯弯绕,所以放弃了这个思路,这种脏活累活还是丢给反序列化工具去做吧。我们要想办法把拿到接口的参数类型,插件怎么拿到业务应用 api 的参数类型呢?一种方式是在插件启动时,把目标应用的 jar 包下载到本地,然后由单独的类加载器进行加载。但这里会有一个问题,业务应用的 api jar 包里面也存在着一些依赖,这些依赖难道要递归去下载?第二种方式,则简单粗暴点,直接在插件项目中引入业务应用 api 依赖,然后打成 fat jar。这样既不需要搞单独的类加载器,也不用去递归下载其他的依赖。唯一比较明显的缺点就是会在插件项目 pom 中引入一些不相关的依赖,但与收益相比,这个缺点根本算不上什么。为了方便,我们把很多业务应用的 api 都依赖了进来。一番操作后,我们得到了如下的 pom 配置:
<project>
<groupId>com.xxx.middleware</groupId>
<artifactId>DubboParser</artifactId>
<version>1.0</version>
<dependencies>
<dependency>
<groupId>com.xxx</groupId>
<artifactId>app-api-1</artifactId>
<version>1.0</version>
</dependency>
<dependency>
<groupId>com.xxx</groupId>
<artifactId>app-api-2</artifactId>
<version>1.0</version>
</dependency>
......
<dependencies>
</project>
接着要改一下 RpcInvocationCodec#decode 方法,其实就是把代码还原回去😓:
public class RpcInvocationCodec {
public static MyRpcInvocation decode(byte[] bytes, int serializationId) {
ObjectInput in = CodecSupport.getSerializationById(serializationId).deserialize(null, input);
MyRpcInvocation rpcInvocation = new MyRpcInvocation();
String dubboVersion = in.readUTF();
// ......
rpcInvocation.setMethodName(in.readUTF());
// 解析接口参数类型
Class<?>[] pts = ReflectUtils.desc2classArray(desc);
Object args = new Object[pts.length];
for (int i = 0; i < args.length; i++) {
// 根据具体类型进行反序列化
args[i] = in.readObject(pts[i]);
}
rpcInvocation.setArguments(args);
rpcInvocation.setParameterTypeNames(pts);
return rpcInvocation;
}
}
代码调整完毕,择日在上线验证,一切正常,可喜可贺。但不久后,我发现这里面存在着一些隐患。如果哪天在线上发生了,将会给排查工作带来比较大的困难。
4.3.3.5 潜在的问题
考虑这样的情况,业务应用 A 和应用 B 的 api jar 包同时依赖了一些内部的公共包,公共包的版本可能不一致。这时候,我们怎么处理依赖冲突?如果内部的公共包做的不好,存在兼容性问题怎么办。
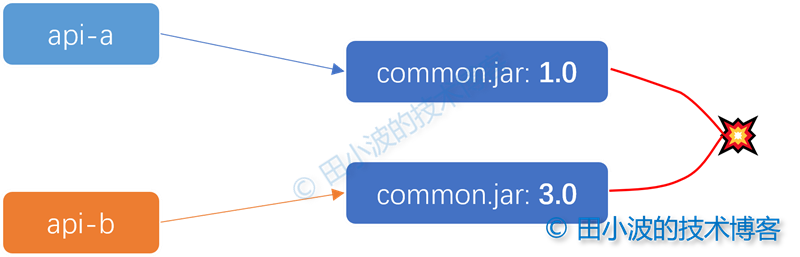
图13:依赖冲突示意图
比如这里的 common 包版本冲突了,而且 3.0 不兼容 1.0,怎么处理呢?
简单点处理,我们就不在插件 pom 里依赖所有的业务应用的 api 包了,而是只依赖一个。但是坏处是,每次都要为不同的应用单独构建插件代码,显然我们不喜欢这样的做法。
再进一步,我们不在插件中依赖业务应用的 api 包,保持插件代码干净,就不用每次都打包了。那怎么获取业务应用的 api jar 包呢?答案是为每个 api jar 专门建个项目,再把项目打成 fat jar,插件代码使用自定义类加载器去加载业务类。插件启动时,根据配置去把 jar 包下载到机器上即可。每次只需要加载一个 jar 包,所以也就不存在依赖冲突问题了。做到这一步,问题就可以解决了。
更进一步,早先在阅读阿里开源的 jvm-sandbox 项目源码时,发现了这个项目实现了一种带有路由功能的类加载器。那我们的插件能否也搞个类似的加载器呢?出于好奇,尝试了一下,发现是可以的。最终的实现如下:
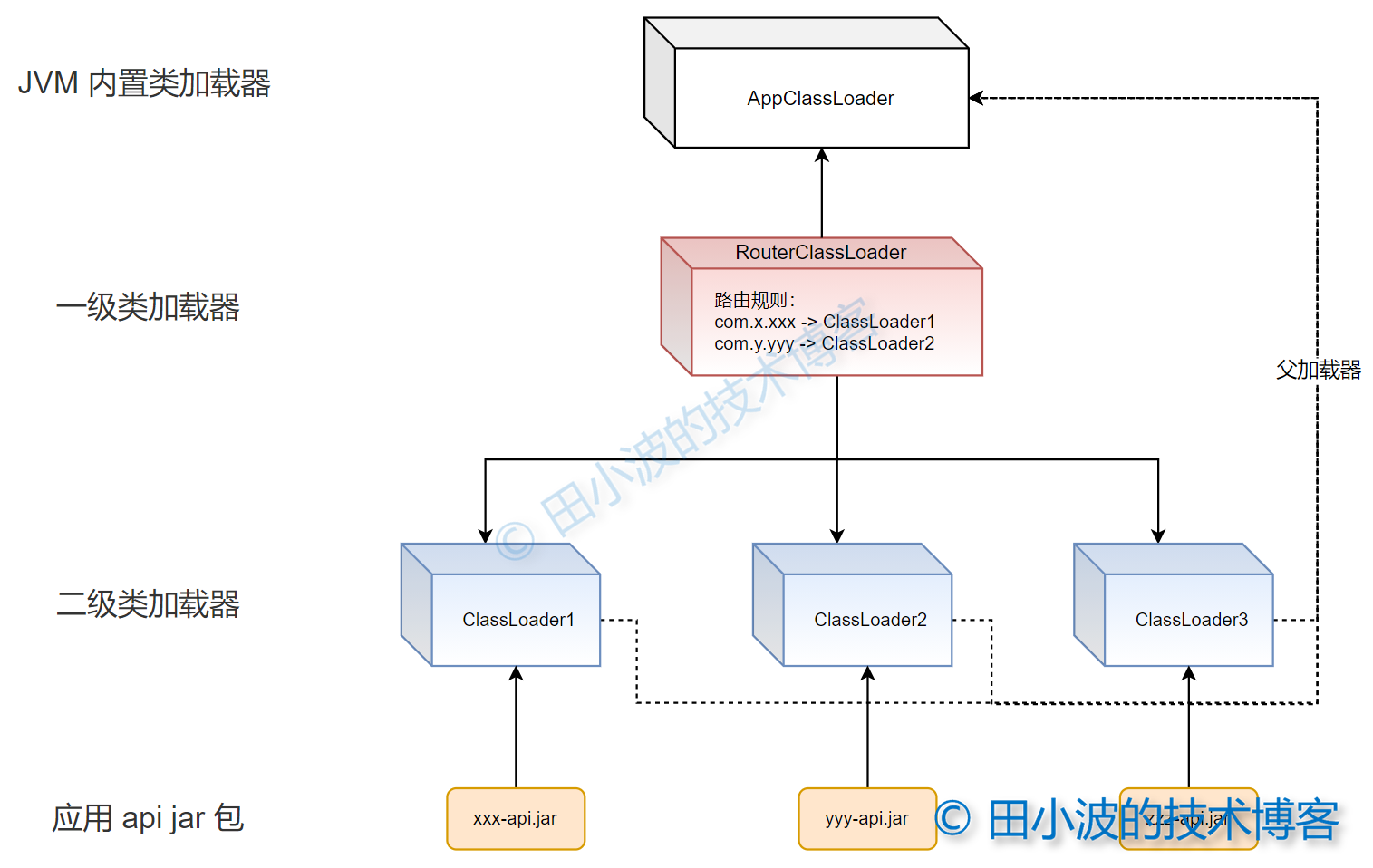
图14:自定义类加载机制示意图
一级类加载器具备根据包名“片段”进行路由的功能,二级类加载器负责具体的加载工作。应用 api jar 包统一放在一个文件夹下,只有二级类加载器可以进行加载。对于 JDK 中的一些类,比如 List,还是要交给 JVM 内置的类加载器进行加载。最后说明一下,搞这个带路由功能的类加载器,主要目的是为了玩。虽然能达到目的,但在实际项目中,还是用上一种方法稳妥点。
4.4 开花结果,落地新场景
我们的流量录制与回放系统主要的,也是当时唯一的使用场景是做压测。系统稳定后,我们也在考虑还有没有其他的场景可以搞。正好在技术选型阶段试用过 jvm-sandbox-repeater,这个工具主要应用场景是做流量对比测试。对于代码重构这种不影响接口返回值结构的改动,可以通过流量对比测试来验证改动是否有问题。由于大佬们觉得 jvm-sandbox-repeater 和底层的 jvm-sandbox 有点重,技术复杂度也比较高。加之没有资源来开发和维护这两个工具,因此希望我们基于流量录制和回放系统来做这个事情,先把流程跑通。
项目由 QA 团队主导,流量重放与 diff 功能由他们开发,我们则提供底层的录制能力。系统的工作示意图如下:

图15:对比测试示意图
我们的录制系统为重放器提供实时的流量数据,重放器拿到数据后立即向预发和线上环境重放。重放后,重放器可以分别拿到两个环境返回的结果,然后再把结果传给比对模块进行后续的比对。最后把比对结果存入到数据库中,比对过程中,用户可以看到哪些请求比对失败了。对于录制模块来说,要注意过滤重放流量。否则会造成接口 QPS 倍增,重放变压测了🤣,喜提故障一枚。
这个项目上线3个月,帮助业务线发现了3个比较严重的 bug,6个一般的问题,价值初现。虽然项目不是我们主导的,但是作为底层服务的提供方,我们也很开心。期望未来能为我们的系统拓展更多的使用场景,让其成长为一棵枝繁叶茂的大树。
5. 项目成果
截止到文章发布时间,项目上线接近一年的时间了。总共有5个应用接入使用,录制和回放次数累计差不多四五百次。使用数据上看起来有点寒碜,主要是因为公司业务是 toB 的,对压测的需求并没那么多。尽管使用数据比较低,但是作为压测系统,还是发挥了相应价值。主要包含两方面:
- 性能问题发现:压测平台共为业务线发现了十几个性能问题,帮助中间件团队发现了6个严重的基础组件问题
- 使用效率提升:新的压测系统功能简单易用,仅需10分钟就能完成一次线上流量录制。相较于以往单人半天才能完成的事情,效率至少提升了 20 倍,用户体验大幅提升。一个佐证就是目前 90% 以上的压测任务都是在新平台上完成的。
可能大家对效率提升数据有所怀疑,大家可以思考一下没有录制工具如何获取线上流量。传统的做法是业务开发修改接口代码,加一些日志,这要注意日志量问题。之后,把改动的代码发布到线上,对于一些比较大的应用,一次发布涉及到几十台机器,还是相当耗时的。接着,把接口参数数据从日志文件中清洗出来。最后,还要把这些数据转换成压测脚本。这就是传统的流程,每个步骤都比较耗时。当然,基建好的公司,可以基于全链路追踪平台拿到接口数据。但对于大多数公司来说,可能还是要使用传统的方式。而在我们的平台上,只需要选择目标应用和接口、录制时长、点击录制按钮就行了,用户操作仅限这些,所以效率提升还是很明显的。
6. 展望未来
项目项目虽然已经上线一年,但由于人手有限,目前基本只有我一个人在开发维护,所以迭代还是比较慢的。针对目前在实践中碰到的一些问题,这里把几个明显的问题,希望未来能够一一解决掉。
1.全链路节点压力图
目前在压测的时候,压测人员需要到监控平台上打开很多个应用的监控页面,压测期间需要在多个应用监控之间进行切换。希望未来可以把全链路上各节点的压力图展示出来,同时可以把节点的报警信息发送给压测人员,降低压测的监视成本。
2.压测工具状态收集与可视化
压测工具自身有一些很有用的状态信息,比如任务队列积压情况,当前的协程数等。这些信息在压测压力上不去时,可以帮助我们排查问题。比如任务队列任务数在增大,协程数也保持高位。这时候能推断出什么原因吗?大概率是被压应用压力太大,导致 RT 变长,进而造成施压协程(数量固定)长时间被阻塞住,最终导致队列出现积压情况。GoReplay 目前这些状态信息输出到控制台上的,查看起来还是很不方便。同时也没有告警功能,只能在出问题时被动去查看。所以期望未来能把这些状态数据放到监控平台上,这样体验会好很多。
3.压力感知与自动调节
目前压测系统更没有对业务应用的压力进行感知,不管压测应用处于什么状态,压测系统都会按照既定的设置进行压测。当然由于 GoReplay 并发模型的限制,这个问题目前不用担心。但未来不排除 GoReplay 的并发模型会发生变化,比如只要任务队列里有任务,就立即起个协程发送请求,此时就会对业务应用造成很大的风险。
还有一些问题,因为重要程度不高,这里就不写了。总的来说,目前我们的压测需求还是比较少,压测的 QPS 也不高,导致很多优化都没法做。比如压测机性能调优,压测机器动态扩缩容。但想想我们就4台压测机,默认配置完全可以满足需求,所以这些问题都懒得去折腾🤪。当然从个人技术能力提升的角度来说,这些优化还是很有价值的,有时间可以玩玩。
7. 个人收获
7.1 技术收获
1. 入门 Go 语言
由于 GoReplay 是 Go 语言开发的,而且我们在使用中确实也遇到了一些问题,不得不深入源码排查。为了更好的掌控工具,方便排查问题和二次开发,所以专门学习了 Go 语言。目前的水平处于入门阶段,菜鸟水平。用 Java 用久了,刚开始学习 Go 语言还是很懵逼的。比如 Go 的方法定义:
type Rectangle struct {
Length uint32
Width uint32
}
// 计算面积
func (r *Rectangle) Area() uint32 {
return r.Length * r.Width
}
当时感觉这个语法非常的奇怪,Area 方法名前面的声明是什么鬼。好在我还有点 C 语言的知识,转念一想,如果让 C 去实现面向对象又该如何做呢?
struct Rectangle {
uint32_t length;
uint32_t width;
// 成员函数声明
uint32_t (*Area) (struct Rectangle *rect);
};
uint32_t Area(struct Rectangle *rect) {
return rect->length * rect->width;
}
struct Rectangle *newRect(uint32_t length, uint32_t width)
{
struct Rectangle *rp = (struct Rectangle *) malloc(sizeof(struct Rectangle));
rp->length = length;
rp->width = width;
// 绑定函数
rp->Area = Area;
return rp;
}
int main()
{
struct Rectangle *rp = newRect(5, 8);
uint32_t area = rp->Area(rectptr);
printf("area: %u\n", area);
free(pr);
return 0;
}
搞懂了上面的代码,就知道 Go 的方法为什么要那么定义了。
随着学习的深入,发现 Go 的语法特性和 C 还真的很像,居然也有指针的概念,21 世纪的 C 语言果然名不虚传。于是在学习过程中,会不由自主的对比两者的特性,按照 C 的经验去学习 Go。所以当我看到下面的代码时,非常的惊恐。
func NewRectangle(length, width uint32) *Rectangle {
var rect Rectangle = Rectangle{length, width}
return &rect
}
func main() {
fmt.Println(NewRectangle(4, 5).Area())
}
当时预期操作系统会无情的抛个 segmentation fault 错误给我,但是编译运行居然没有问题...问..题..。难道是我错了?再看一遍,心想没问题啊,C 语言里不能返回栈空间的指针,Go 语言也不应该这么操作吧。这里就体现出两个语言的区别了,上面的 Rectangle 看起来像是在栈空间里分配到,实际上是在堆空间里分配的,这个和 Java 倒是一样的。
总的来说,Go 语法和 C 比较像,加之 C 语言是我的启蒙编程语言。多以对于 Go 语言,也是感觉非常亲切和喜欢的。其语法简单,标准库丰富易用,使用体验不错。当然,由于我目前还在新手村混,没有用 Go 写过较大的工程,所以对这个语言的认识还比较浅薄。以上有什么不对的地方,也请大家见谅。
2. 较为熟练掌握了 GoReplay 原理
GoReplay 录制和回放核心的逻辑基本都看了一遍,并且在内网也写过文章分享,这里简单和大家聊聊这个工具。GoReplay 在设计上,抽象出了一些概念,比如用输入和输出来表示数据来源与去向,用介于输入和输出模块之间的中间件实现拓展机制。同时,输入和输出可以很灵活的组合使用,甚至可以组成一个集群。
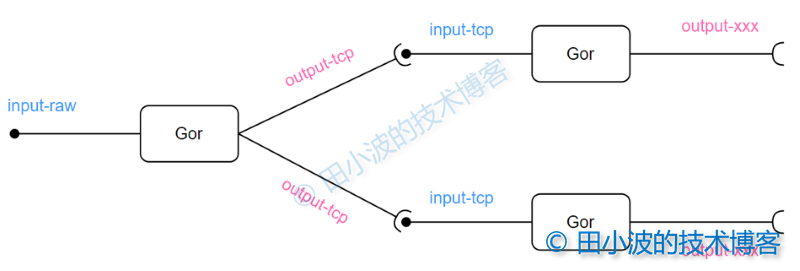
图16:GoReplay 集群示意图
录制阶段,每个 tcp 报文段被抽象为 packet。当数据量较大,需要分拆成多个报文段发送时,收端需要把这些报文段按顺序序组合起来,同时还要处理乱序、重复报文等问题,保证向下一个模块传递的是一个完整无误的 HTTP 数据。这些逻辑统封装在了 tcp_message 中,tcp_message 与 packet 是一对多的关系。后面的逻辑会将 tcp_message 中的数据取出,打上标记,传递给中间件(可选)或者是输出模块。
回放阶段流程相对简单,但仍然会按照 输入 → [中间件] → 输出 流程执行。通常输入模块是 input-file,输出模块是 output-http。回放阶段一个有意思的点是倍速回放的原理,通过按倍数缩短请求间的间隔实现加速功能,实现代码也很简单。
总的来说,这个工具的核心代码并不多,但是功能还是比较丰富的,可以体验一下。
3. 对 Dubbo 框架和类加载机制有了更多的认知
在实现 Dubbo 流量录制时,基本上把解码相关的逻辑看了一遍。当然这块逻辑以前也看过,还写过文章。只不过这次要去定制代码,还是会比单纯的看源码写文章了解的更深入一些,毕竟要去处理一些实际的问题。在此过程中,由于需要自定义类加载器,所以对类加载机制也有了更多的认识,尤其是那个带路由功能的类加载器,还是挺好玩的。当然,学会这些技术也没什么大不了的,重点还是能够发现问题,解决问题。
4. 其他收获
其他的收获都是一些比较小的点,这里就不多说了,以问题的形式留给大家思考吧。
- TCP 协议会保证向上层有序交付数据,为何工作在应用层的 GoReplay 还要处理乱序数据?
- HTTP 1.1 协议通信过程是怎样的?如果在一个 TCP 连接上连续发送两个 HTTP 请求会造成什么问题?
7.2 教训和感想
1. 技术选型要慎重
开始搞选型没什么经验,考察维度很少,不够全面。这就导致了几个问题,首先在验证阶段工具一直达不到预期,耽误了不少时间。其次在后续的迭代期间,发现 GoReplay 的小问题比较多,感觉严谨程度不够。比如 1.1.0 版本使用文档和代码有很多处差异,使用时要小心。再比如使用过程中,发现 1.3.0-RC1 版本中存在资源泄露问题 #926,顺手帮忙修复了一下 #927。当然 RC 版本有问题也很正常,但是这么明显的问题说实话不应该出。不过考虑到这个项目是个人维护的,也不能要求太多。但是对于使用者来说,还是要当心。这种要在生产上运行的程序,不靠谱是很闹心的事情。所以对于我个人而言,以后选型成熟度一定会排在第一位。对于个人维护的项目,尽量不作为靠前的候选项。
2. 技术验证要全面
初期的选型没有进行性能测试和极限测试,这就导致问题在线上验证时才发现。这么明显的问题,拖到这么晚才发现,搞的挺尴尬的。所以对于技术验证,要从不同的角度进行性能测试,极限测试。更严格一点,可以向李运华大佬在 如何正确的使用开源项目 文章中提的那样,搞搞故障测试,比如杀进程,断电等。把前期工作做足,避免后期被动。
3. 磨刀不误砍柴工
这个项目涉及到不同的技术,公司现有的开发平台无法支持这种项目,所以打包和发布是个麻烦事。在开发和测试阶段会频繁的修改代码,如果手动进行打包,然后上传的 FTP 服务器上(无法直接访问线上机器),最后再部署到具体的录制机器上,这是一件十分机械低效的事情。于是我写了一个自动化构建脚本,来提升构建和部署效率,实践证明效果挺好。从此心态稳定多了😀,很少进入暴躁模式了。

图17:自动化构建脚本效果图
十分尴尬的是,我在项目上线后才把脚本写好,前期没有享受到自动化的福利。不过好在后续的迭代中,自动化脚本还是帮了很大的忙。尽早实现编译和打包自动化工具,有助于提高工作效率。尽管我们会觉得写工具也要花不少时间,但如果可以预料到很多事情会重复很多次,那么这些工具带来的收益将会远超付出。
8. 写在最后
非常幸运能够参与并主导这个项目,总的来说,我个人还是从中学到了很多东西。这算是我职业生涯中第一个深度参与和持续迭代的项目,看着它的功能逐渐完善起来,稳定不间断给大家提供服务,发挥出其价值。作为项目负责人,我还是非常开心骄傲的。但同时也有些遗憾的,由于公司的业务是 toB 的,对压测系统的要求并不高。系统目前算是进入了稳定期,没有太多可做的需求或者大的问题。我虽然可以私下做一些技术上的优化,但很难看出效果,毕竟现有的使用需求还没达到系统瓶颈,提早优化并不是一个好主意。期望未来公司的业务能有大的发展,对压测系统提出更高的要求,我也十分乐意继续优化这个系统。另外,要感谢一起参与项目的同事,他们的强力输出得以让项目在紧张的工期内保质保量上线,如期为业务线提供服务。好了,本篇文章到此结束,感谢阅读。
本文在知识共享许可协议 4.0 下发布,转载请注明出处
作者:田小波
原创文章优先发布到个人网站,欢迎访问:https://www.tianxiaobo.com

本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号