
数据库故障引发的“血案”
标题听起来很耸人听闻,不过确实没有夸大的意思,对于我们来说确实算得上”血案“了。这个问题最终导致了某个底层的核心应用15分钟内不可用,间接导致上层很多应用也出现了问题,尤其是一些支付相关的业务也出现了不可用情况。由于故障影响较大,该故障在内部定级很高。故障排查过程也算是一波三折,中间的槽点也比较多,特别是对网络比较了解的大佬能一眼看出来问题。这个故障的排查工作我也深度参与了,这里做一下总结,希望能给大家一些参考。
0. 文章导读
本文约 7000 字,配图 26 张。文章相对比较长,因此这里对文章结构做些介绍。本篇文章分为5个章节,各章节内容概括如下:
- 故障现象:本章对故障现象进行了介绍,在阅读后续内容前,需先搞清楚故障现象
- 故障排查过程:本章介绍了故障排查过程,并给出了初步结论。
- 故障复现:本章基于故障排查结论,针对性的进行了故障复现和验证,并给出了故障的处理措施
- 再次探索:重新对故障排查过程进行审视,并针对其中疑点再次进行探索,尝试寻找”真相“
- 总结:本章对故障和排查过程中存在的一些问题进行了回顾与总结
需要说明的是,为了降低图片大小,一些异常栈信息被删除了,但核心调用都在。
1. 故障现象
4月的某个周日下午2点前后,一个核心应用出现大量的报警,但是一小会后又自动恢复了,从监控上看故障持续时间约为15分钟。翻看了业务日志,发现里面有很多 druid 相关的报错,看起来像是 druid 出问题了。
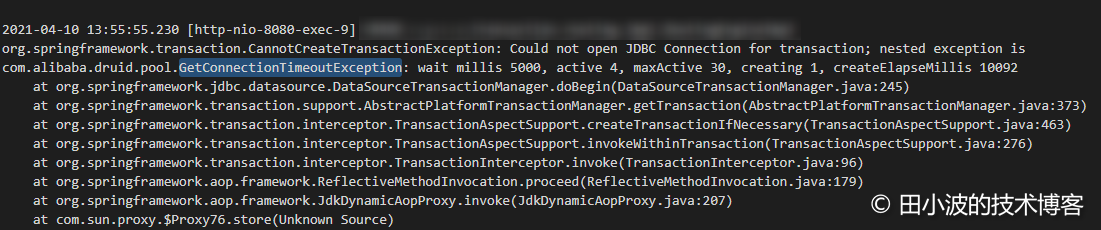
图1:业务线程大量抛出获取连接超时异常

图2:druid 连接生产者线程抛出网络异常
后来从 DBA 那边得知,阿里云 RDS 由于物理机发生故障,在13:57 进行了自动主备切换。由于 RDS 主备切换时间与我们的应用发生故障的时间很接近,因此初步判断该故障和阿里云 RDS 切换有关。从现象上看,阿里云 RDS 执行主备切换后,我们的应用似乎没有切换成功,仍然连接到了故障机上。由于 DBA 之前也做过很多次主备切换演练,一直都没发生过什么事情,所以这个问题在当时看起来还是挺费解的。
以上就是故障的背景和现象,下面开始分析故障原因。
2. 故障排查过程
在展开分析前,先给大家介绍一下 druid 的并发模型,做一些技术铺垫。
2.1 背景知识介绍
druid 数据源使用生产者消费者模型维护连接池,当连接池中没有连接时,消费者线程会通知生产者线程创建连接。生产者创建好连接后,会将连接放到池中,并通知消费者线程取连接。如果消费者线程在设定时间没没取到连接,会抛出一个超时异常。
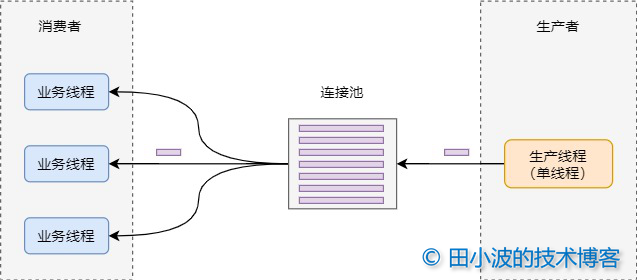
图3:druid 并发模型
注意,生产者线程是单线程,如果这个线程在某些情况下阻塞住,会造成大量的消费者线程无法获取到连接。
2.2 排查过程
2.2.1 初步排查
这个问题最早是我接手排查的,当时很多信息都还没有,只有异常日志。刚开始排查的时候,我翻看了其中一台机器上的日志,发现日志中只有大量的 GetConnectionTimeoutException 异常,没有 druid 生产者线程抛出的异常。

图4:消费者线程抛出异常
在消费者线程抛出的异常信息里,包含了两个与生产者有关的数据,通过这两个数据可以了解到生产者处于的状态。第一个是 creating,表示生产者当前正在创建连接。第二个是 createElapseMillis,表示消费者超时返回时,生产者创建连接所消耗的时间。上图中,createElapseMillis 值约为900秒,这明显是有问题的,说明生产者线程应该是被阻塞住了。因此根据这个信息,我给出了一个初步结论:
生产者线程被卡住,很可能的原因是在创建连接时没有配置超时时间,可以通过在数据库 URL 后面追加一个 connectTimeout 参数解决这个问题。
排查到这里好像也能解释通,但是这里有很多疑问没有解决:到底是在哪个方法上卡住了?配置这个参数是否真的有用,能否复现验证?不回答掉这些问题,这个故障排查结论显然不能说服人。因此后续有更多人参与进来排查,收集到的信息也越来越多。
2.2.2 深入排查
这个时候,我们的 DBA 开始找阿里云技术支持沟通,得到的答复 RDS 物理机出现了故障,触发了自动主备切换机制。另一方面,其他同事详细阅读了更多机器的错误日志,发现了生产者线程也抛出了异常。
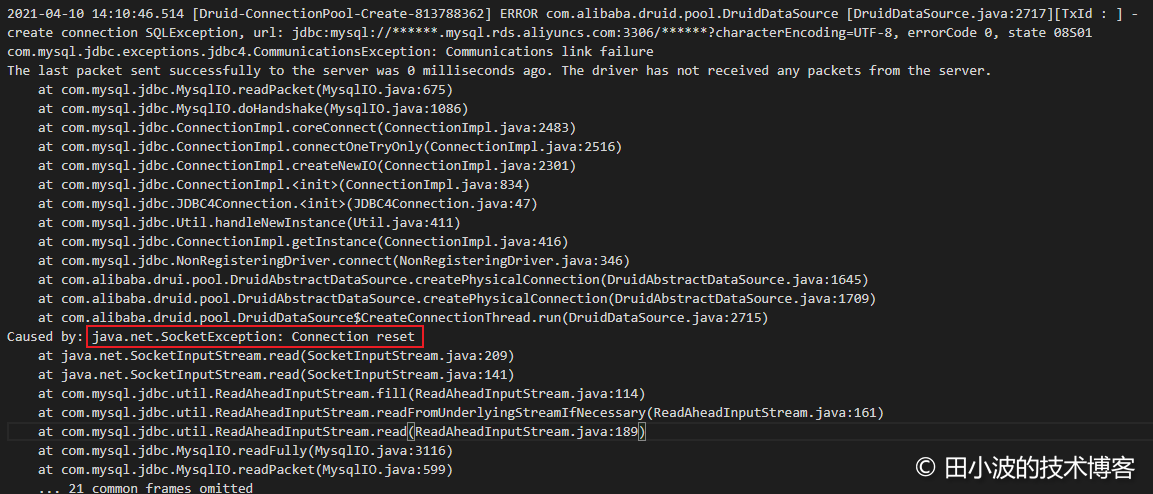
图5:druid 生产线线程抛出网络异常
奇怪的是,其中有两台机器的日志里找不到生产者的异常。后来询问了应用负责人,才了解到他在 14:10 重启过应用,剩余机器还没来得及重启,服务就已经恢复了。不巧的是,我刚开始排查的时候,查看的日志正是被重启过的机器的日志。这里也凸显排查问题时,广泛收集信息的重要性。除了生产者线程抛出了这个异常,部分消费者线程也抛出了同样的异常:
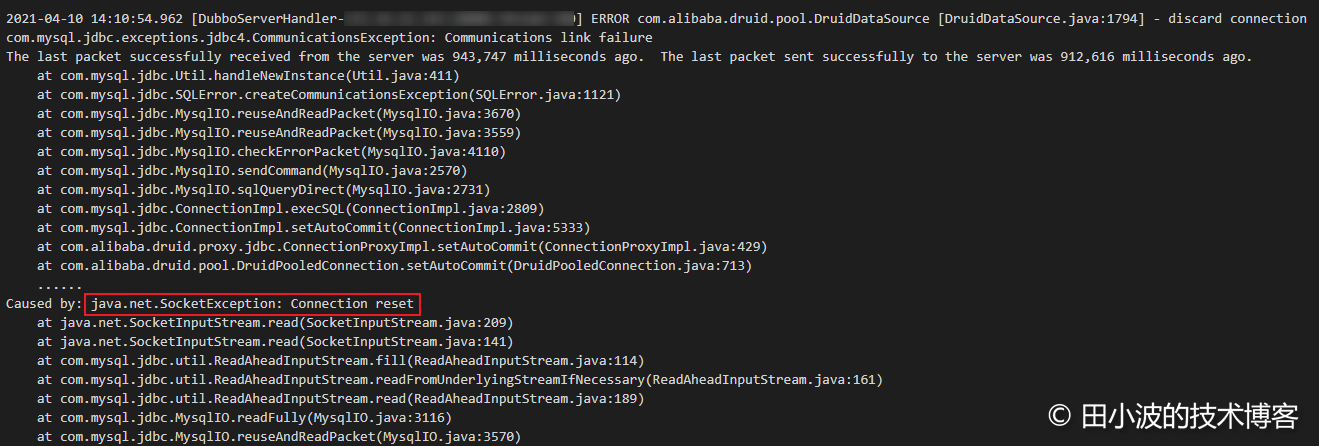
图6:消费者线程抛出网络异常
如上,生产者和部分消费者线程都是在卡住900多秒后抛出异常,通过查阅 TCP 相关的资料,一起排查的同事认为这个时间应该是底层网络最大的超时时间导致的。因此推断 MySQL 物理机发生故障后,不再响应客户端的任何数据包。客户端机器底层网络在经过多次重试后失败后,自己关闭了连接,上层应用抛出 SocketException。通过资料,我们了解到 net.ipv4.tcp_retries2 内核参数用于控制 TCP 的重传。Linux 官方文档有相关说明:
tcp_retries2 - INTEGER
This value influences the timeout of an alive TCP connection,
when RTO retransmissions remain unacknowledged.
Given a value of N, a hypothetical TCP connection following
exponential backoff with an initial RTO of TCP_RTO_MIN would
retransmit N times before killing the connection at the (N+1)th RTO.The default value of 15 yields a hypothetical timeout of 924.6
seconds and is a lower bound for the effective timeout.
TCP will effectively time out at the first RTO which exceeds the
hypothetical timeout.
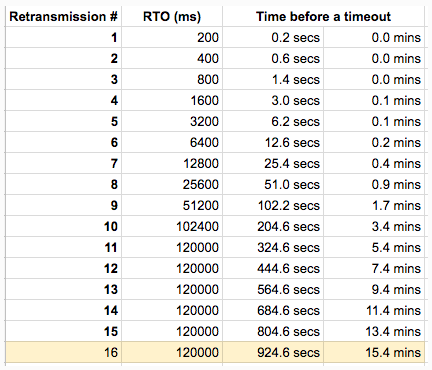
图7:Linux TCP 超时重传情况;图片来源:Marco Pracucci
排查到这里,很多东西都能解释通了,似乎可以“结案”了。可是情况真的如此吗?由于没有当时的抓包数据,大家还是没法确定是不是这个原因。于是接下来,我按照这个排查结论进行了复现。
3. 故障复现
3.1 准备工作
为了进行较为准确的复现,我们在一台与线上配置相同的 ECS 上部署业务应用。在内网的另一台 ECS 上搭建了一个 MySQL 服务,并把线上数据同步到这个数据库中。由于我们没法制造 MySQL 物理机故障,因此我们通过 iptables 配置防火墙策略来模拟因机器故障导致的网络层故障,比如不响应客户端请求。最后我们通过 arthas 对 druid 生产者线程进行监控,观测连接创建耗时情况。
3.2 背景知识介绍
在展开后续内容前,先介绍一下 MySQL 驱动与服务端建立连接的过程。示意图如下:
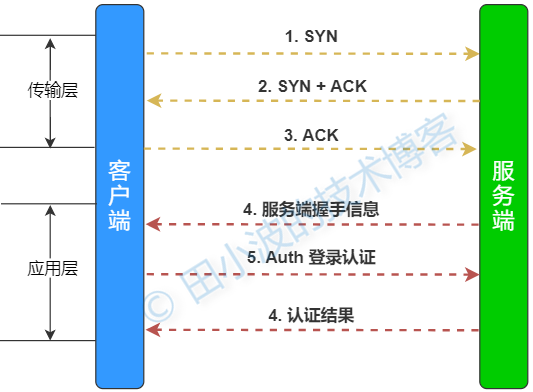
图8:MySQL 客户端与服务端通信过程
这里简单讲解下,业务应用在建立一个 MySQL 数据库连接时,首先要完成 TCP 三次握手,待 TCP 连接建立完毕后,再基于 TCP 连接进行应用层的握手。主要是互换一些信息,以及登录认证。服务端握手信息主要返回的是服务器的版本,服务器接受的登录认证方式,以及其他用于认证的数据。客户端收到数据库的握手信息后,将用户名和密码加密后进行登录认证,随后服务端返回认证结果。下面我们抓包看一下双方的交互过程。
客户端 ip: 172.***.***.141
服务端 ip: 172.***.***.251
在客户端机器上进行抓包,命令如下:
tcpdump -i eth0 host 172.***.***.251 -w mysql.pcap
抓包结果如下:
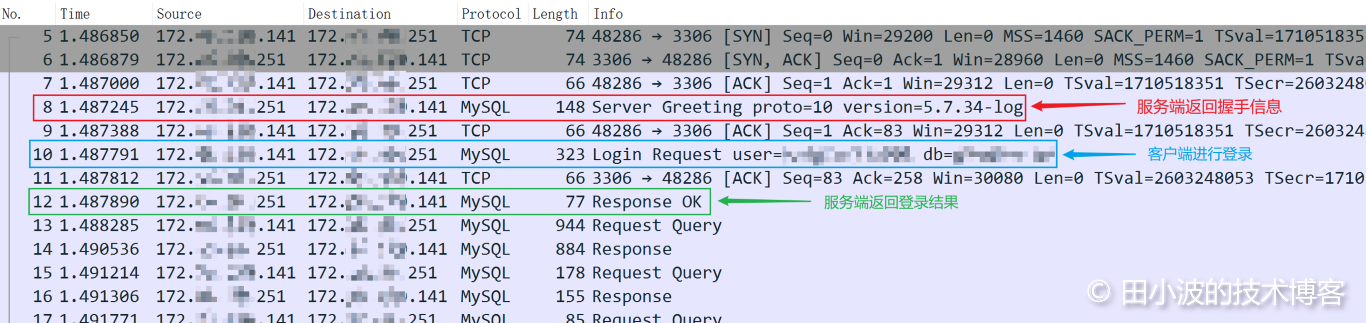
图9:MySQL 连接建立过程抓包结果1
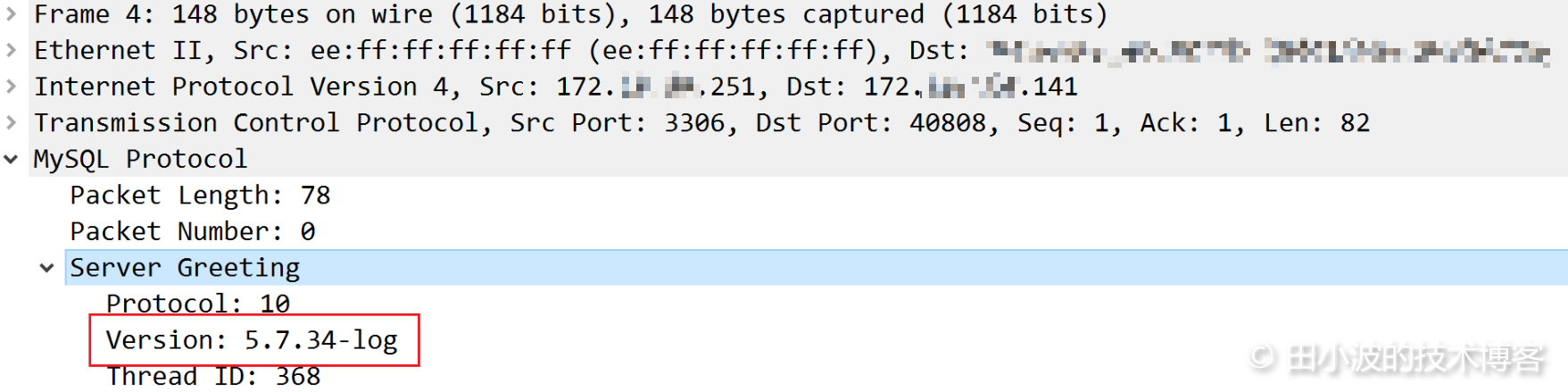
图10:MySQL 连接建立过程抓包结果2
我们后续将使用 Version 作为服务器握手报文段的特征字符串,根据这个特征配置防火墙规则。
3.3 故障复现
本节,我们除了要验证故障出现的可能场景,还要验证我们的解决办法是否有效。在进行复现前,我们要修改一下 druid 的配置,保证 druid 可以快速关闭空闲连接,方便验证连接创建过程。
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">
<!-- 不配置超时时间,与线上配置保持一致 -->
<property name="url" value="jdbc:mysql://172.***.***.251:3306/***db" />
<!-- 最小空闲连接数 -->
<property name="minIdle" value="0"/>
<!-- 初始连接数 -->
<property name="initialSize" value="0"/>
<!-- 每隔1.5秒检测连接是否需要被驱逐 -->
<property name="timeBetweenEvictionRunsMillis" value="1500" />
<!-- 最小驱逐时间,连接空闲时间一旦超过这个时间,就会被关闭 -->
<property name="minEvictableIdleTimeMillis" value="3000" />
</bean>
3.3.1 故障场景推断
根据生产者线程抛出的异常显示,生产者线程是在与 MySQL 服务端进行应用层握手时卡住的,异常日志如下:

图11: druid 生产者线程抛出的异常
根据这个报错日志我们可以判断出问题是出在了 TCP 连接建立后,MySQL 应用层握手期间时。之所以可以这么肯定,是因为代码都到了应用层握手阶段,TCP 层连接的建立肯定是完成了,否则应该会出现类似无法连接的错误。因此我们只需要验证 MySQL 客户端与服务端进行应用层握手失败的场景即可,不过我们可以稍微多验证一些其他场景,增加对底层网络行为的了解。下面我们进行三个场景的模拟:
场景一:服务端不响应客户端 SYN 报文段,TCP 无法完成三次握手
场景二:TCP 连接可以正常建立,但是服务端不与客户端进行应用层握手
场景三:连接池中已经建立好的连接无法与服务端通信,导致消费者线程被阻塞
3.3.2 故障复现与验证
3.3.2.1 故障场景一
预期现象:TCP 数据包被丢弃,客户端不停重试。druid 生产者线程被阻塞住,数据库连接无法建立
步骤一:场景模拟
登录到 MySQL 服务器,设置防火墙规则,丢弃所有来自客户端的数据包
iptables -I INPUT -s 172.***.***.141 -j DROP
步骤二:触发数据库访问,观察现象
登录业务机器,使用 arthas 观察 druid 生产者线程执行情况,命令如下:
trace com.alibaba.druid.pool.DruidAbstractDataSource createPhysicalConnection -n 1000 -j
触发一个数据库访问,由于连接池中没有连接,druid 会去创建一个连接。现象如下:
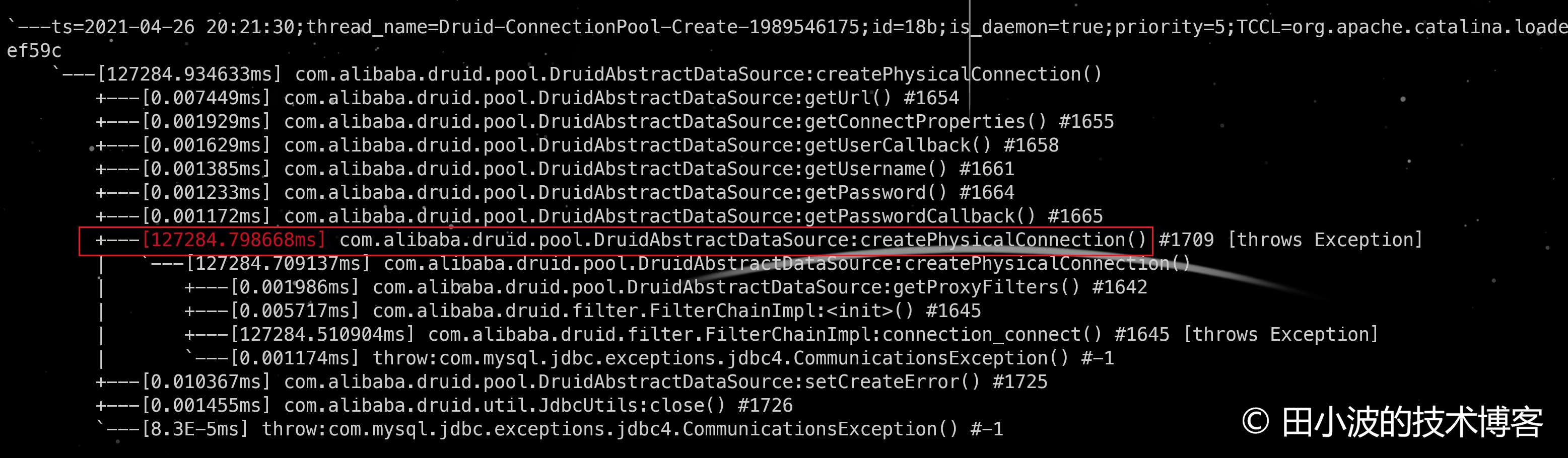
图12:底层网络故障,druid 新建连接耗时情况
可以看出,TCP 连接无法建立时,druid 的 DruidAbstractDataSource#createPhysicalConnection 方法会消耗掉约127秒,且会抛出异常。取消掉服务端的防火墙规则:观察正常情况下,新建连接耗时情况:
iptables -D INPUT -s 172.***.***.141 -j DROP
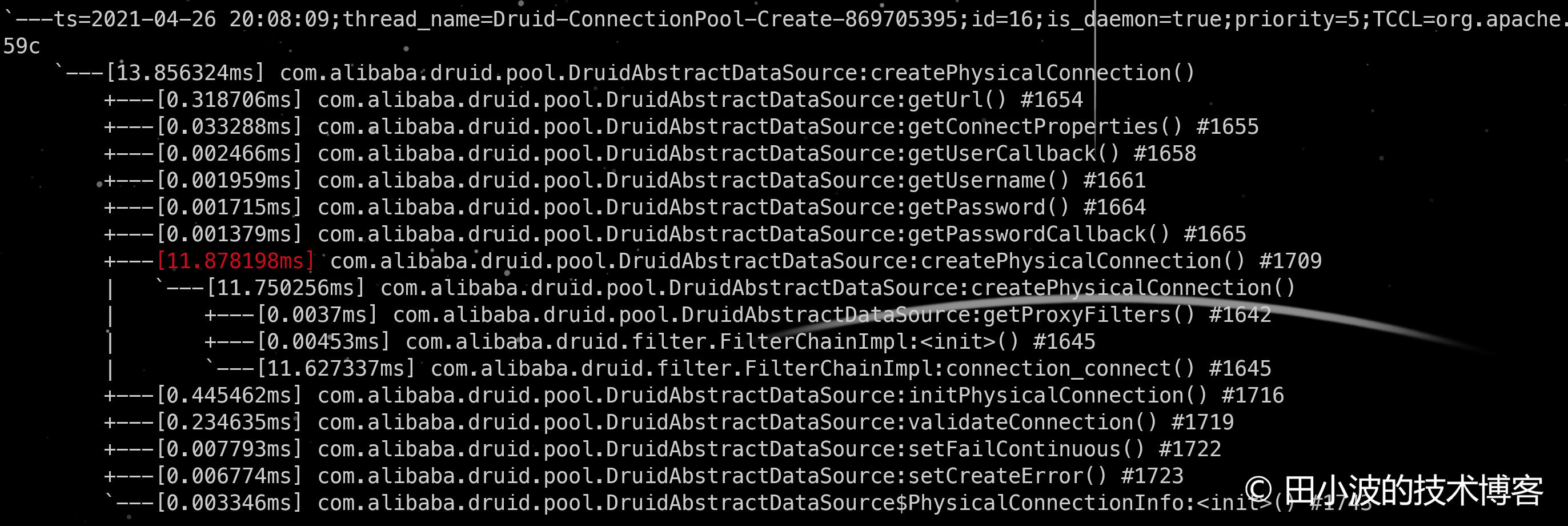
图13:正常情况下,druid 新建连接耗时情况
如上,正常情况和异常情况耗时对比还是很明显的,那这 127 秒耗时是如何来的呢?下面分析一下。
异常情况分析
TCP 在建立连接过程中,如果第一个 SYN 报文段丢失(没收到另一端的 ACK 报文),Linux 系统会进行重试,重试一定次数后终止。初始的 SYN 重试次数受内核参数 tcp_syn_retries,该参数默认值为6。内核参数说明如下:
tcp_syn_retries - INTEGER
Number of times initial SYNs for an active TCP connection attempt
will be retransmitted. Should not be higher than 127. Default value
is 6, which corresponds to 63 seconds till the last retransmission
with the current initial RTO of 1 second. With this the final timeout
for an active TCP connection attempt will happen after 127 seconds.
注意最后一句话,与我们使用 arthas trace 命令得到的结果基本是一致的。下面再抓个包观察一下:

图14:TCP SYN 重传情况
如上,第一个包是客户端初始的握手包,后面6个包都是进行重试。第8个包发出时,时间正好过去了 127 秒,与内核参数说明是一致的。到这里,关于 TCP 连接无法创建成功的问题就说清楚了。由于我们的应用被卡住了 900 多秒,因此显然可以排除 TCP 握手失败的情况了。不过虽然原因不是这个,但如果 druid 生产者线程被卡住 127 秒,那也是相当危险的。如何预防呢?
预防连接超时问题
通过配置 connectTimeout 参数,可以降低 TCP SYN 重试时间,配置如下:
jdbc:mysql://172.***.***.251:3306/***db?connectTimeout=3000
再发起一个数据库请求验证一下配置是否有效。
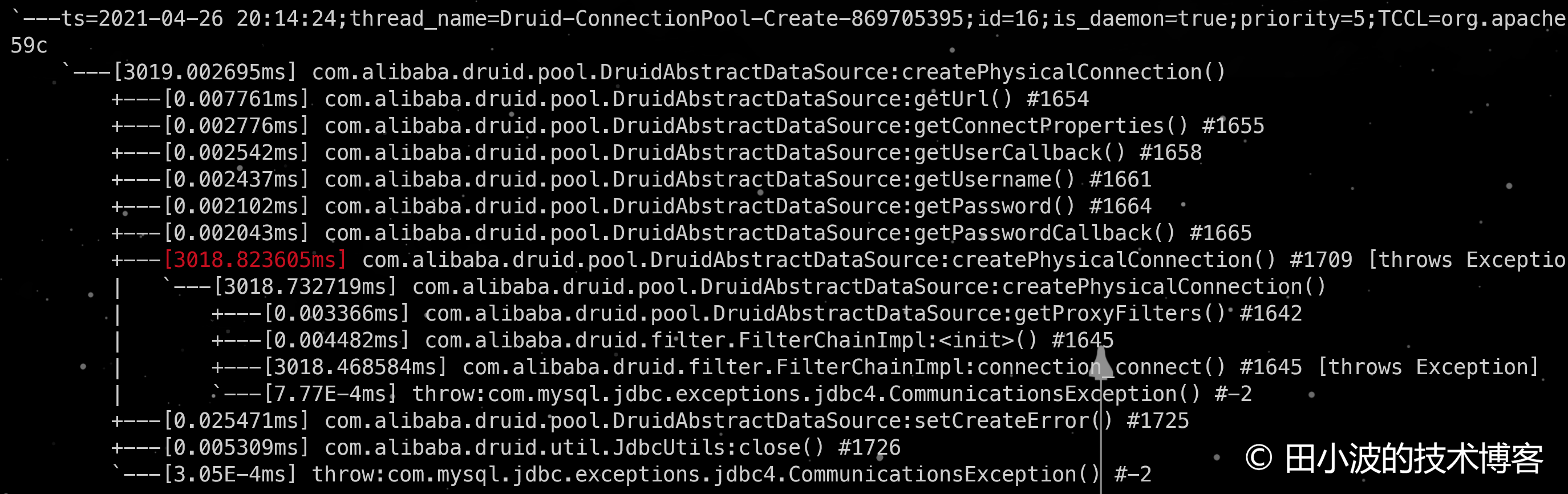
图15:配置 connectTimeout 参数后,druid 生产者线程超时情况
如上图,druid 生产者线程调用 DruidAbstractDataSource#createPhysicalConnection 消耗了 3 秒,符合预期,说明配置有效。客户端会抛出的异常如下:
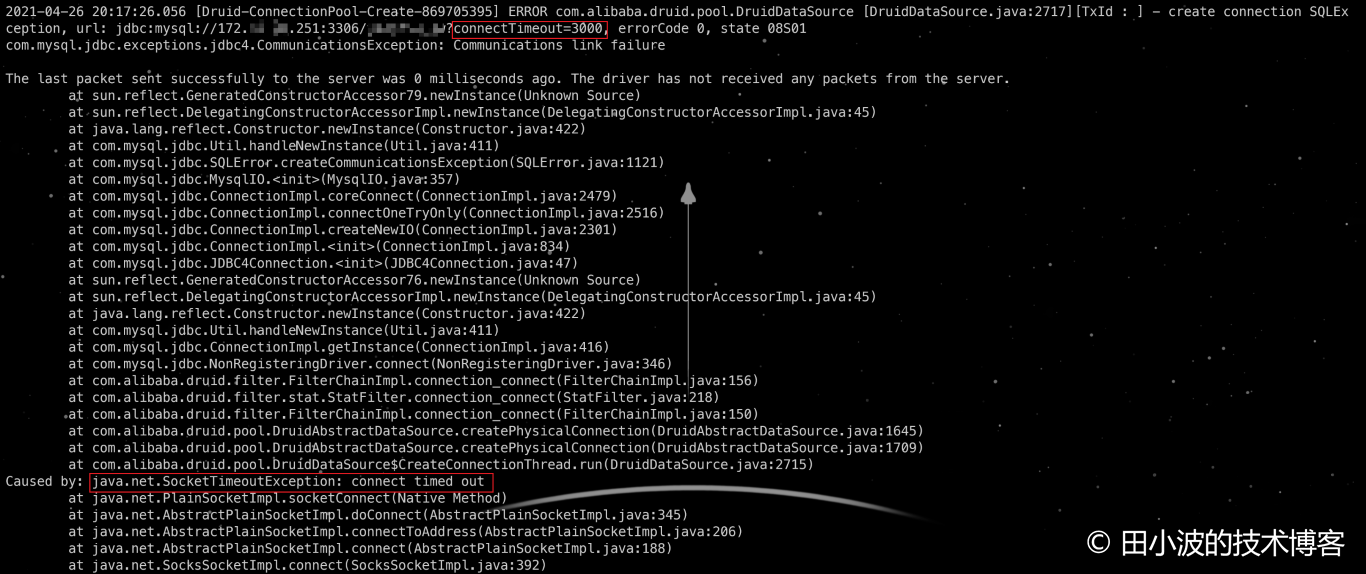
图16:客户端抛出的异常细节
3.3.2.2 故障场景二
这次我们来模拟底层网络正常,但是应用层不正常的情况,即 MySQL 服务器不与客户端进行握手。
预期现象:druid 生产者线程卡住约900秒后报错返回
步骤一:模拟场景
在 MySQL 服务器上配置防火墙规则,禁止 MySQL 握手数据包流出。
# 使用 iptables 的 string 模块进行字符串匹配
iptables -I OUTPUT -m string --algo bm --string "5.7.34-log" -j DROP
查看防火墙规则
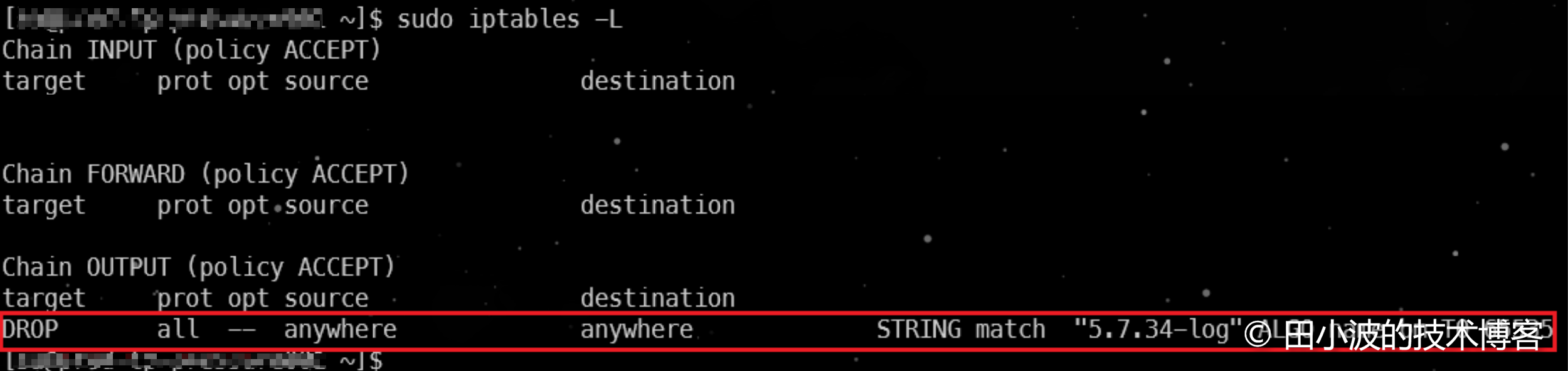
图17:防火墙规则列表
步骤二:观察现象
这次我们通过消费者线程抛出的异常日志来观察 druid 生产者线程的创建时间,异常日志如下:
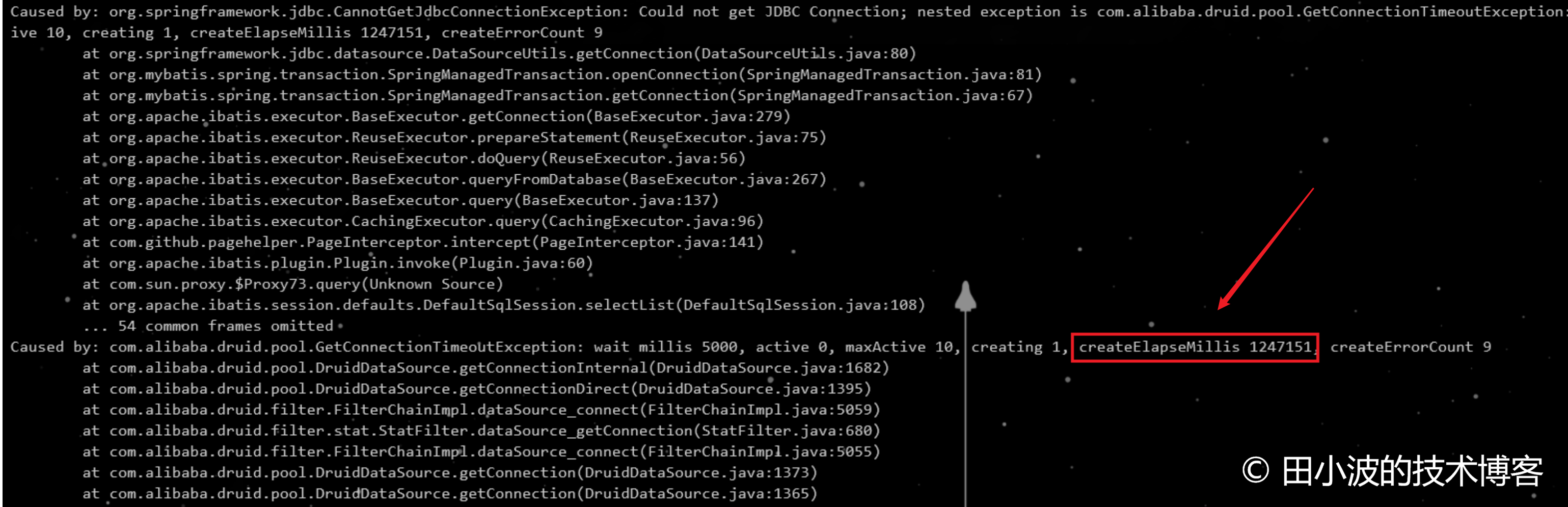
图18:消费者线程异常日志
如上,消费者线程的异常信息里显示生产者线程以及被阻塞了 1247 秒,且这个值随着时间的推移越来越长。远远超过了 900 秒,与预期不符合,原因没有深入探究。不过,我们似乎发现了比原故障更严重的问题,排查到这里好像可以停下脚步了。
预防 MySQL 应用层握手超时
由于 connectTimeout 仅作用在网络层,对应用层的通信无效,所以这次我们要换个参数了。这次我们使用的参数是 socketTimeout,配置如下:
jdbc:mysql://172.***.***.251:3306/***db?connectTimeout=3000&socketTimeout=5000
设定 socketTimeout 参数值为 5000 毫秒,验证服务端不与客户端握手情况下,客户端能否在 5 秒后超时返回。arthas 监控如下:
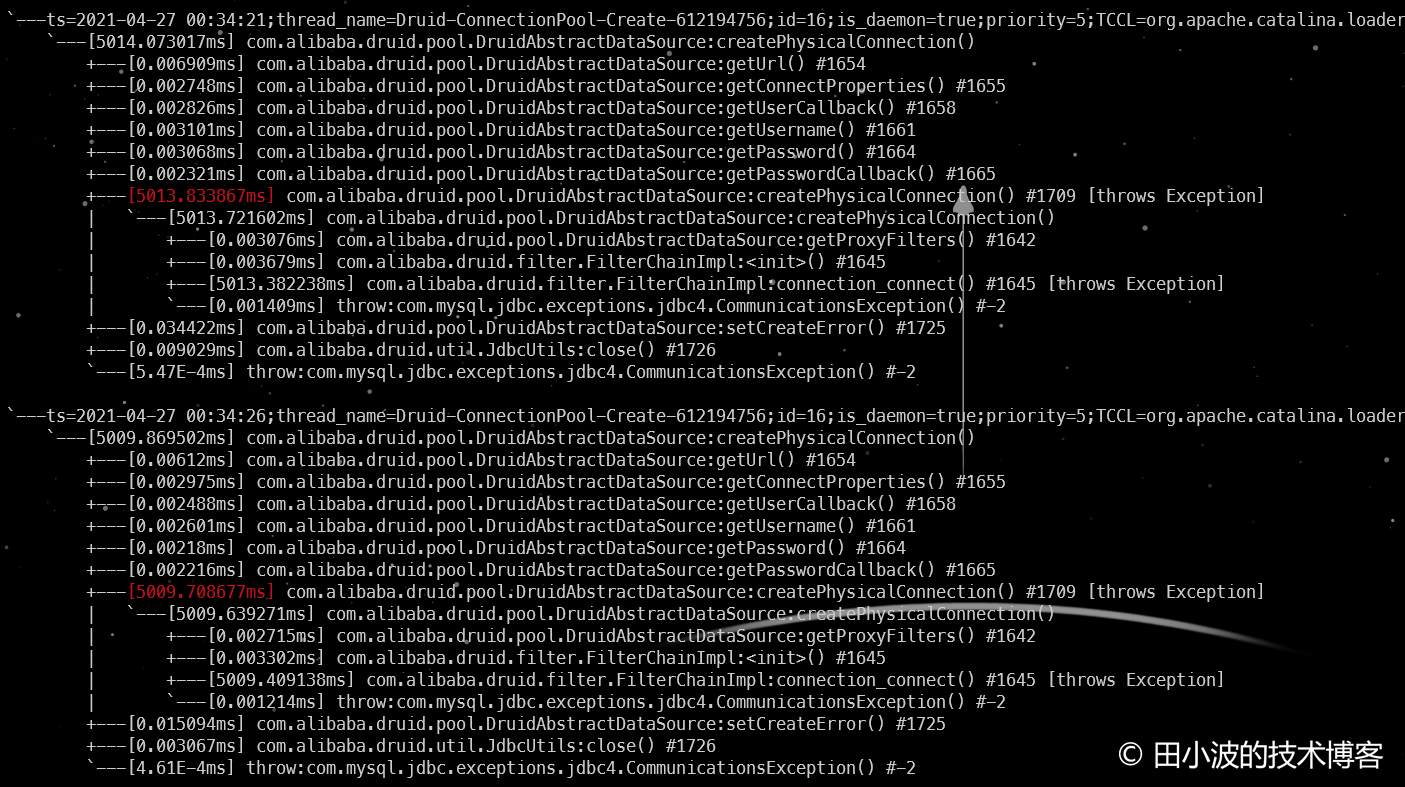
图19:arthas trace 监控
结果符合预期,druid 生产者线程确实在 5 秒后报错返回了,错误信息如下:
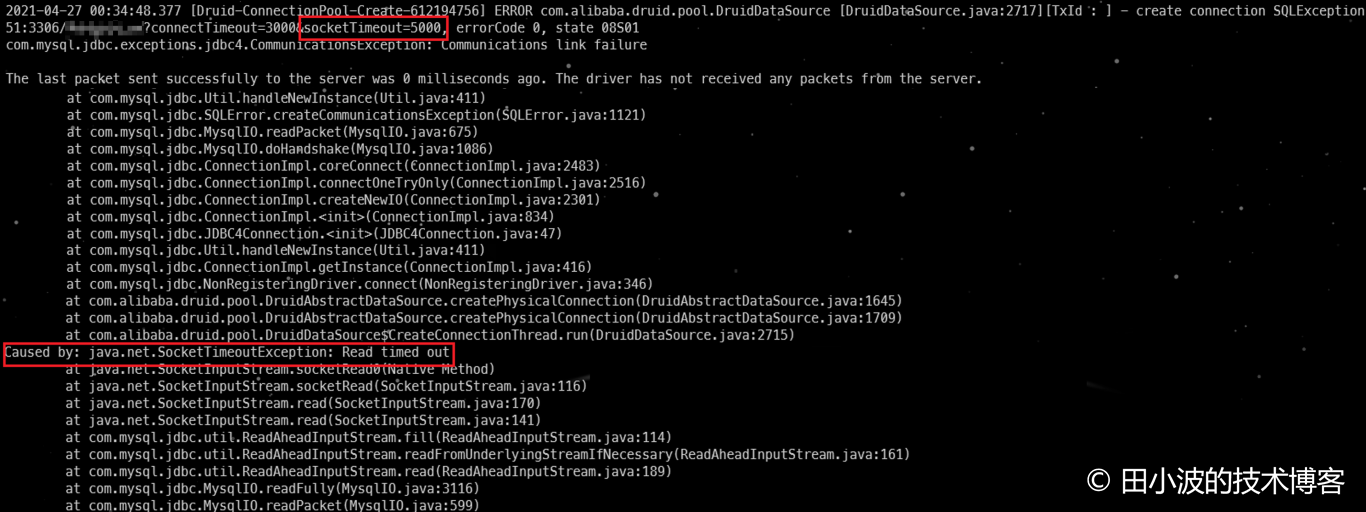
图20:druid 生产者线程超时返回情况
如上,通过配置 socketTimeout 可以保证 druid 在服务端不进行握手的情况下超时返回。
3.3.2.3 故障场景三
最后一个场景用于复现在 MySQL 物理机出故障,不响应客户端的 SQL 请求。
预期现象:客户端不停重试,直至 924 秒后超时返回
要模拟这种场景,可以在 MySQL 服务端丢弃掉来自客户端的所有数据包,防火墙配置参考上面的内容。直接看现象吧。
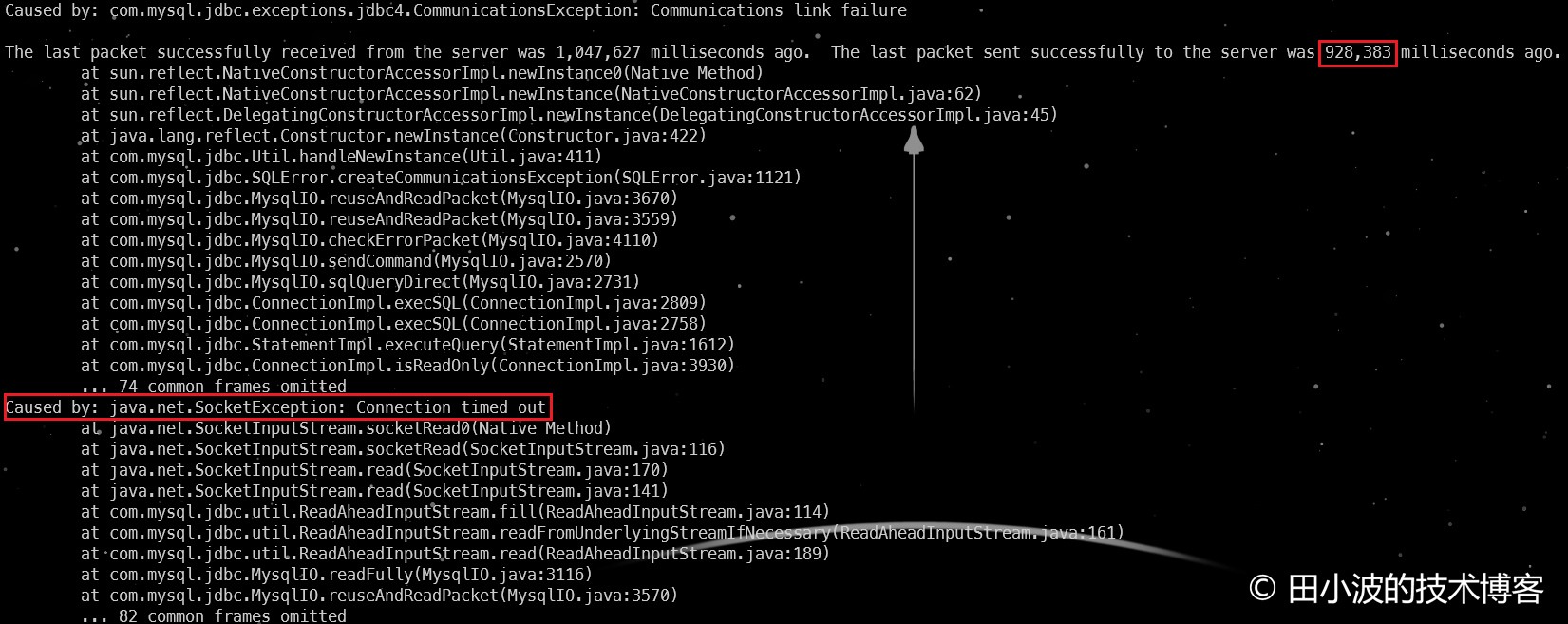
图21:消费者线程超时返回
如上,消费者线程超时返回时间与 924 秒非常接近,基本可以判定多次重试失败后,超时返回了。抓包佐证一下:
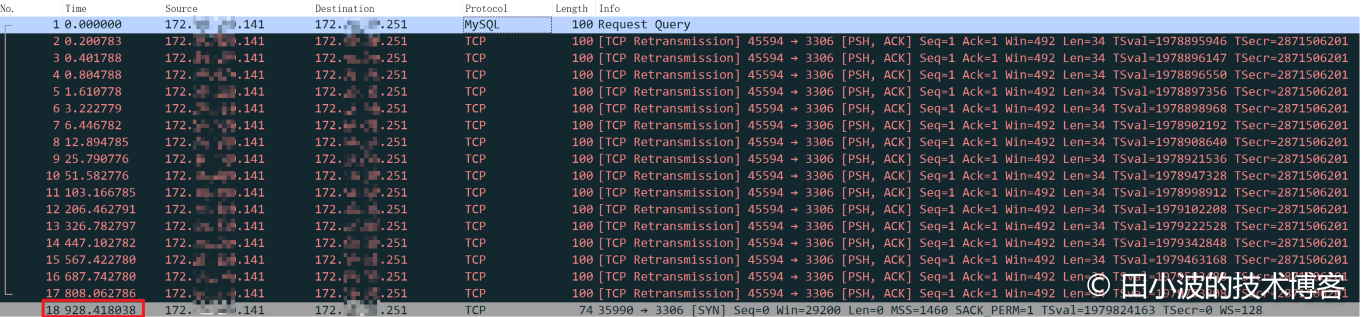
图22:TCP 连接重试情况
最后一个数据包发出的时间证明了我们的判断是对的。从上面的抓包结果可以看出,总共进行了16次重试。前面说过,TCP 非 SYN 重试受内核参数 ipv4.tcp_retries2 影响,该参数值默认为 15,为什么这里进行了 16 次重试呢?这里简单说明一下吧,这里的 15 是用来计算超时总时长的,并不代表重传次数,更详细的解释大家 STFW。
场景三的预防方式与场景二相同,都是通过配置 socketTimeout,就不赘述了。
3.4 小结
到此,整个的复现过程就结束了。通过对故障进行复现,似乎证明了我们之前的排查结果是正确的。与此同时,我们也对 connectTimeout 和 socketTimeout 两个配置的有效性进行了验证,结果也是符合预期的。但是复现过程中,生产者被卡住的时间远远长于 900 秒,不符合预期,还是很让人疑惑的。由于当时大家认为这个看起来比原问题还要严重,且通过 socketTimeout 可以规避掉,所以就没在细究原因。到此,排查工作就结束了,后续由 DBA 推动各应用配置两个超时参数,这个事情告一段落。
4. 再次探索
在我准备写这篇文章前的一周,我花了一些时间重新看了一下之前的排查文档和错误日志,有个问题始终围绕在我的脑海里,不得其解。业务日志里生产者和部分消费者线程抛出的异常信息里均包含 "Connection reset",而非前面复现过程中出现的 "Read timed out"。很显然连接被重置和连接超时不是同一种情况,那么问题出在了哪里呢?是不是我们所复现的环境与阿里云 RDS 有什么一样的地方,导致复现结果与实际不符合。于是我查阅了一些和阿里云 RDS 相关的资料,有一张架构图吸引了我。
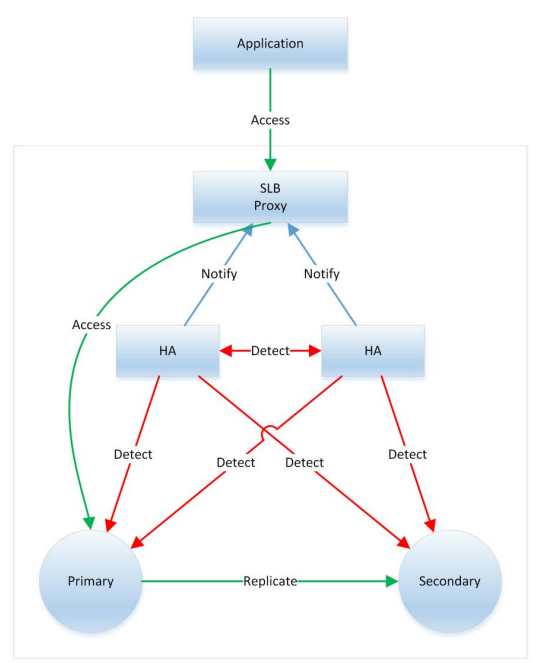
图23:阿里云 RDS 高可用架构;来源:阿里云RDS技术白皮书
从这张图里可以看出,我们搭建的复现环境缺少了 SLB,但 SLB 只是一个负载均衡,难道它会中断连接?答案是,我不知道。于是又去找了一些资料了解在什么情况下会产生 RST 包。情况比较多,部分如下:
- 目标端口未监听
- 通信双方中的一方机器掉电重启,本质上也是目标端口未监听
- 通信路径中存在防火墙,连接被防火墙策略中断
- 服务端监听队列满了,无法再接受新的连接。当然服务端也可以直接丢弃掉 SYN 包,让客户端重试
- TCP 缓冲区溢出
了解了 RST 产生的几种情况,我们再尝试推理一下阿里云 RDS 在发生类似故障后,会执行什么策略。考虑到他们的技术人员也要排查问题,因此最可能的策略是仅将故障机从 SLB 上摘除,故障机器不重启,保留现场。如果是这样,那么故障机器并不会发送 RST 数据包。其他策略,比如杀掉 MySQL 进程或者让故障机关机,都会发送 FIN 数据包正常关闭连接,这个我抓包验证过。排查到到这里,思路又断了,实在想不通哪里会在 900 多秒时发出一个 RST 包出来。目前唯一能怀疑的可能就是 SLB,但是 SLB 毕竟只是个负载均衡,应该会像防火墙那样根据策略阻断连接。由于没有其他思路了,现在只能关注一下 SLB。由于对 SLB 不熟悉,又是一通找资料,这次好像有点眉目了。
一开始通过 Google 搜索 SLB RST,没找到有用的信息。考虑到 SLB 是基于 LVS 实现的,把 SLB 换成 LVS 继续搜索,这次找到了一些有用的信息。通过这篇文章 负载均衡超时时间 了解到阿里云 SLB 在连接空闲超过设定值后,会中断连接。于是又找到 SLB 的官方文档,在一个 FAQ 里找到了期望的信息。

图24:阿里云官方文档关于负载均衡 FAQ
现在考虑这种情况,故障机器底层网络并没问题,但处于应用层的 MySQL 处于僵死状态,不响应客户端请求。当 TCP 连接空闲时间超过 900 秒后,SLB 客户端发送了一个 RST 断开连接。看到这句话时非常开心,于是我在阿里云买了两台 ECS 和一个 SLB 验证了一下,SLB 的超时时间保持默认值 900 秒。使用 nc 工具在一台 ECS 上启动一个 TCP 服务器,在另一台机器上,同样可以使用 nc 命令连接这个服务器。只不过我们不能直连,而是同通过 SLB 连接。示意图如下:
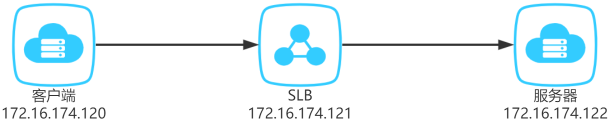
图25:SLB 验证环境
环境搭建好后,抓包验证了一下。

图26:SLB 超时机制验证
到这里我已经拿到了想要的结果,目前似乎可以下结论说我们的应用在卡住900多秒后,被 SLB 发送 RST 断开连接了。但在后续的验证中发现,连接空闲时,RDS 的 TCP 层开启了 keepalive 机制,每隔一分钟发一个数据包做连接保活,此时 SLB 不会主动断开连接。除非故障机器被隔离了,无法与 SLB 通信。排查到这里,基本放弃治疗了。如果 RST 包是 SLB 发出的,连接应该处于真正空闲状态,不存在保活的数据包。由于没有当时的抓包数据,加上对阿里云内部故障机器处理机制不了解,目前没法给出更合理的结论了。姑且先用这个结论”搪塞“一下,也欢大家集思广益,一起交流学习。
5. 总结与思考
本次故障排查耗时非常长,也花费了我很多精力。尽管如此,还是没有找到最终原因,感觉比较遗憾。不过不管结果怎么样,总的来说,这次故障的排查过程让我受益良多。一方面学到了很多知识,另一方面也发现了一些不足。下面简单对这次故障进行总结。
首先,这次的故障偶发性非常大,是公司使用阿里云服务几年来第一次出现这样的情况。其次,MySQL 服务端故障原因也比较复杂,根据阿里云技术的回复,触发主备切换是因为 RDS 所在的物理机文件系统检查有异常。因此对我们来说,复现的成本也非常高。同时,本次故障和网络的关系很密切,但是很遗憾,我们没有当时的抓包数据。加上故障复现成本太高,且未必能 100% 复现,导致这份关键的信息缺失。进而导致我们不清楚底层的通信情况是怎样的,比如有没有发生重传,服务端有没有发送 TCP 保活数据包等。最后,在前面几个因素的作用下,我们只能通过收集各种信息,并结合故障现象进行猜想,然后逐一验证猜想的合理性。当然限于我们的知识边界,可能还有很多情况我们没有考虑到,或者已有的猜想存在明显不合理之处,也欢迎大家指正。
在这次的排查问题过程中,由于个人经验不足,也暴露了很多问题。文章的最后同样做下总结,希望能给大家提供一些参考。
- 排查初期没有广泛收集信息,此时无论是做的猜想还是下的结论都是不可靠的
- 过于关注某些故障现象,导致陷入了细节,没能从整体进行审视。不但做了很多无用功,也没得到结果
- 计算机网络知识深度不足,对一些明显现象视而不见,同时也做了一些错误猜想。后续需要重点补充这方面的知识
- 忽略了一些重要的差异,复现过程中出现的现象是超时,而实际情况是连接被重置,这个差异当时没有深究
- 真相只有一个,如果有些现象无法得到合理解释,就说明问题的根源仍未找到,此时不要强行解释
本篇文章到此结束,感谢阅读。
参考内容
- Linux TCP_RTO_MIN, TCP_RTO_MAX and the tcp_retries2
- ip-sysctl.txt
- 聊一聊重传次数
- 你所需要掌握的问题排查知识
- 阿里云云数据库 RDS 版技术白皮书
- 负载均衡超时问题
- 阿里云负载均衡服务FAQ
- TCP RESET/RST Reasons
本文在知识共享许可协议 4.0 下发布,转载请注明出处
作者:田小波
原创文章优先发布到个人网站,欢迎访问:https://www.tianxiaobo.com

本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。

