深度学习扫盲笔记
第一章:概述
深度学习:机器学习含有多个隐藏层
有监督的:卷积,循环,递归
无监督的:生成式
类别标签:
ground truth:表示直接收集到的数据
使用sklearn进行训练集,测试集的拆分:留出法和k折交叉验证,分层抽样策略
超参数:不变的,调节超参数找到能使模型取得较好性能的超参数
第二章:特征工程
目的是最大限度地从原始数据中提取特征以供算法和模型使用
1:概述
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已;
自然语言处理:自动分词,词性标注,句法分析
Text Process API:情感分析
Jieba:中文语言处理
2:向量空间模型及文本相似度计算
未来便于计算文档之间的相识度,需把文档转换成统一空间的向量;
1:BOW假设(存在模型):为了计算文档之间的相似度,假设可以忽略文档内的单词顺序和语法,句法等要素,将其仅仅看做是若干个词汇的集合;
2:VSM模型(向量空间模型):即向量空间模型,其是指在BOW词袋模型假设下,将每个文档表示成同一个向量空间的向量;
3:文档之间的欧式距离
欧式距离是一个通常采用的距离算法,指在N维空间中两个点之间的真实距离
公式:
4:文档之间的余弦相似度
余弦相似度,是通过计算两个向量的夹角余弦值来评估他们的相识度;
余弦值越接近,表名夹角越接近0度,也就是两个向量越相似,这就叫预先相识度;
公式:
3:特征处理
1:特征缩放
或称无量纲处理。主要是对每个列,即同一特征维度的数值进行规范化处理。
应用背景:
不同特征(列》可能不属于同一量纲,即特征的规格不一样。例如。假设特征向量由两个解释变量构成,第一个变量值范图[0.1]-第二个变量值范图[O,100]
如果某一特征的方差数量级较大,可能会主导目标函数,导致其他特征的影响被忽略
常用方法:
标准化法
区间缩放法
标准化:方程和标准差
2:特征选择
特征值的归一化:或称规范化
归一化是依照特征矩阵的行(样本)处理数据,其目的在于样本向量在点乘运算或计算相似性时,拥有统一的标准,也就是说都转化为单位向量,即使每个样本的范式等于1;
规则为L1 norm的归一化公式如下:
规则为 L2 norm的归一化公式如下:
什么是特征选择?选择对于学习任务(如分类问题)有帮助的若干特征;
为什么要进行特征选择?1)降维以提升模型的效率;2)降低学习任务的难度;3)增加模型的可解释性;
特征选择的角度:
- 特征是否发散:对于不发散的特征,样本在其维度上差异性较小;
- 特征与目标的相关性:应当优先选择与目标相关性高的特征
特征选择的方法:
- 方差选择法
- 皮尔逊相关系数法
- 基于森林的特征选择法
- 递归特征消除法
3:特征降维
特征降维——线性判别分析法(LDA)
降维本质上是从一个维度空间映射到另一个维度空间;
线性判别分析(LDA)是一种监督学习的降维技术,即数据集的每个样本有类别的输出
LDA的基本思想:投影后类内的方差最小,类见方差最大。即将数据在低维度上进行投影,投影后希望同类数据的投影点尽可能接近,而不同类型的类别中心之间的距离尽可能的大;
第三章:回归问题及正则化
1:线性回归
区别:
- 分类:使用训练集推断输出x所对应的离散类别(如+1,-1)
- 回归:使用训练集推断输出x所对应的输出值,为连续实数。
联系:
- 利用回归模型进行分类:可将回归模型的输出离散化以进行分类,即 $y=sign(f(x))$
- 利用分类模型进行回归:也可利用分类模型的特点,输出其连续化的数值;
线性模型:
- 狭义线性模型:通常指自变量与因变量之间按比例,成直线的关系,在数学上可理解为一阶导数为常数的函数 如$y=n^Tx$ ;线性通常表现为一次曲线;
- 广义线性(GLM):是线程模型的扩展,主要通过联结函数$g()$ 使预测值落在响应变量的变幅内,例如逻辑回归
$h(x)=g(nTx)=1/(1+e(-n^Tx))$;括号内为线性函数;


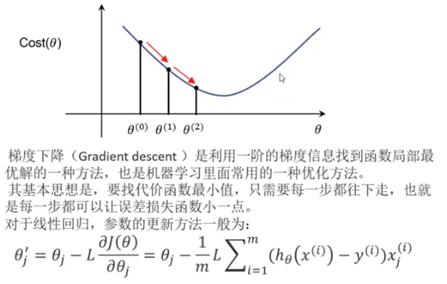
梯度下降法
沿着损失函数梯度下降的方向,寻找损失函数的最小值,得到最优解
2:多元回归
西瓜的价格取决于多种因素
3:损失函数的正则化
抑制过拟合


4:逻辑回归
使用sigmoid函数
垃圾短信分类

第四章:信息熵及梯度计算
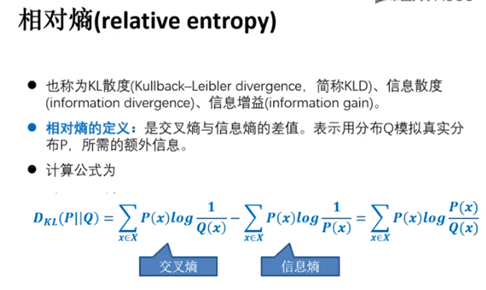
1:熵



2:反向传播(BP)与梯度
从输出节点开始,将误差信号沿着原来的连接通路返回,通过修改各层神经元的连接权值,使误差信号减至最小。

3:感知机
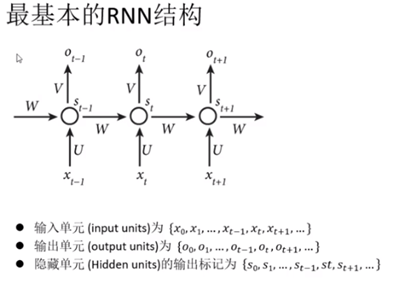
第五章:循环神经网络(RNN)
1:概念
隐藏层节点之间是有连接的,考虑上下文内容

RNN序列处理
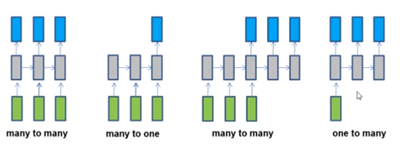

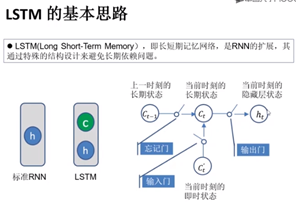
2:长短时记忆网络(LSTM)
标准的无法捕捉长期状态
3:双向RNN,注意力模型
双向RNN
注意力模型:集中到重要
第六章:卷积与卷积网络
卷积使原始信号的特征被增强
对图像和滤波矩阵做内积的操作叫做卷积操作
卷积神经网络:特点
1:局部连接
局部相关性较高
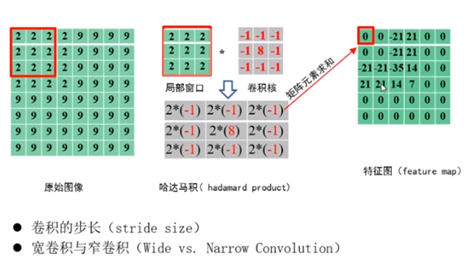
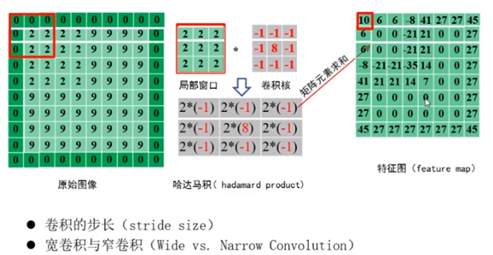
局部连接,参数共享,子采样
2:参数共享
卷积核中是相同的,
3:多卷积核
也可以使用不同大小,不同数值的卷积核
4:池化处理
降采样处理,对不同位置的特征进行聚合统计,通常去对应位置的最大值(最大池化)平均值


LeNet-5
第七章:递归神经网络:
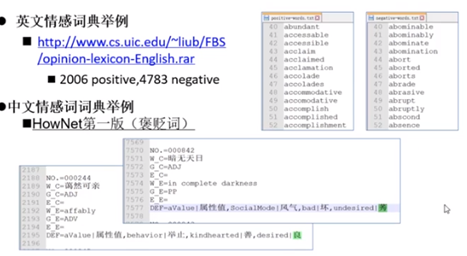
1:情感分析
(意见挖掘,倾向性分析)是对带有情感色彩的主观性文本进行分析,处理
现有的情感词典
生语料
2:词向量
3:递归神经网络

引入了张量层
第八章:生成式神经网络
1:自动编码器
无监督学习:聚类,自动编码器是一种无监督的神经网络模型

2:变分自动编码器
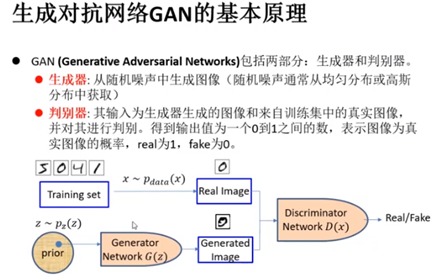
3:生成对抗网络
仿制者与鉴定师对抗,对抗时越来越强

 浙公网安备 33010602011771号
浙公网安备 33010602011771号