谈谈Golang中goroutine的调度问题
goroutine的调度问题,同样也是我之前面试的问题,不过这个问题我当时并不是很清楚,回来以后立马查阅资料,现整理出来备忘。
有一些预备知识需要说明,就是操作系统中的线程。操作系统中的线程分为两种:内核线程和用户线程。用户平时使用的线程并不是内核线程,而是存在于用户态的用户线程。用户线程并不一定在操作系统内核中对用同等数量的内核线程。这里有三个模型:
1.一对一模型(1:1)
2. 多对一模型(N:1)
3. 多对多模型(N:M)
下面就先来谈谈这三种线程模型。
1.一对一模型(1:1)
对于支持线程的操作系统来说,一对一模型是最简单的一种线程模型了,一个用户线程唯一对应一个内核线程,但反过来却不一定,一个内核线程并不一定有对应的用户线程存在。这样一来,由于一个内核线程至多只对应一个用户线程,线程之间可以做到最大程度的并发,不同线程之间不会相互影响,比如一个线程阻塞了也不会影响到其他线程的执行。对于多处理器,一对一的线程模型效率更高。但是很多操作系统限制了内核线程的数量,如果采用一对一模型,用户线程的数量也会受到比较大的限制。而且很多操作系统的内核线程在调度时开销较大,这也会影响用户线程的效率。
2. 多对一模型(N:1)
多对一模型意味着多个用户线程对应一个内核线程,用户线程间的切换由代码控制,因为线程间切换的效率比较高(不用陷入内核区去切换)。不过如果其中一个用户线程阻塞了,则和它对应相同内核线程的那些用户线程也都会阻塞,因为内核线程是被共用的(且是绑定的),此时它无法抽身出来。而且增加处理器个数对于多对一线程模型帮助也不大,毕竟在这种情况下,一个线程阻塞,相关线程也跟着遭殃的事实和处理器个数关系不大。这种模型的好处是线程间切换开销低,且线程数量可以很多。
3. 多对多模型(N:M)
多对多线程模型可以说是上面两种模型的结合,也是最复杂的,它把多个用户线程对应到多个内核线程上,且很多时候不是唯一绑定的。因此一个内核线程在一个时间点可以对应0到多个用户线程。且在运行期间,系统可以根据线程执行情况做合理分配。比如用户线程1、用户线程2和用户线程3对应到一个内核线程1,如果用户线程1阻塞了,系统可以调度用户线程2和用户线程3到其他内核线程上去,这是个动态的过程。多对多线程模型的优势是可以让系统资源得到比较均衡的使用,用户线程之间互相影响比较小,且在多处理器上表现不错(虽然增加处理器个数对它性能提升可能不如一对一模型那么高),关键是它很灵活。
Golang的goroutine调度和多对多模型密切相关,Golang自己有自己的调度器scheduler。Golang的调度器内部有三个重要结构:M、P和G。
M: 代表内核线程。
G: 代表一个goroutine,它有自己的栈,指令指针和一些基本信息,用于被调度。
P: 代表调度的上下文,是Golang内部的调度器,负责让多个goroutine在一个内核线程上运行,它实现了N:1到N:M。
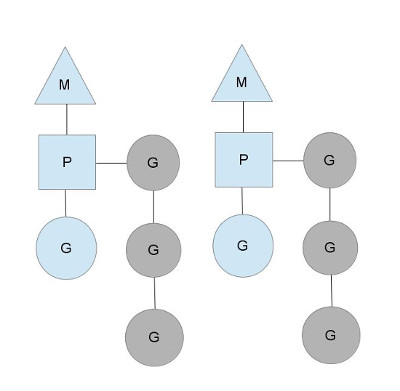
可以看到在某个时刻,一个M对应到一个P,一个P上有一个正在运行的G(蓝色的G),且这个P上可能还有多个G等待被调度(灰色的G),P维护着这个调度队列(runqueue)。P的数量可以通过GOMAXPROCS()来设置,它其实也就代表了真正的并发度,即有多少个goroutine可以同时运行。不过需要注意,GOMAXPROCS()的最大值是256。当要启动一个goroutine时,只需要用go function(args)即可,一但我们启动了一个goroutine,就会在runqueue队尾加入这个goroutine,P会负责调度这些goroutine。
那么如果在某个M被阻塞了呢?这时候就是N:M模型的关键之处了,此时P可以被安排到其他M上去执行,由于P内部维护着一些G的信息,这些G都有独立的栈和指令指针这些基本信息,所以可以很方便地直接换到另一个未被阻塞的M下。
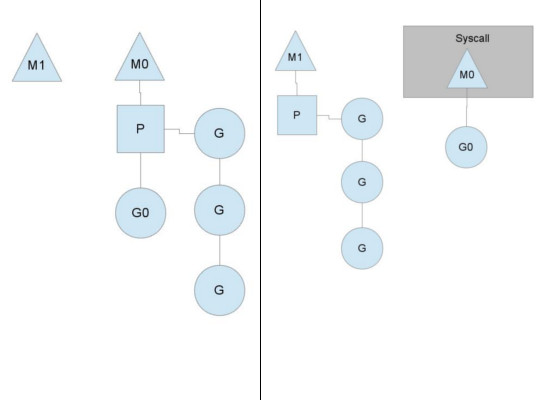
上图描述了这种情况,在左边,G0正在运行,当G0由于系统调用被阻塞时,调度器会创建或者从线程缓存中取得一个线程M1,转投M1。当G0返回时,它必须获得一个P来执行,此时一般是先查看系统中有没有空闲的P,如果有,就获得一个P,用这个P来执行,如果没能获得一个P,这个G0只能暂时放置到一个全局的执行队列(global runqueue)中,它所处的线程M0也就sleep了。系统中的P们会周期性地检查这个队列,取出里面的G来运行。
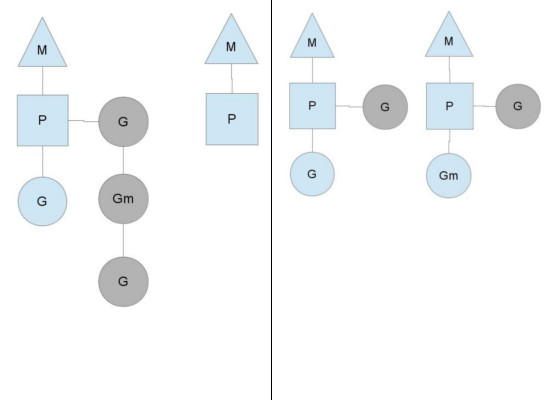
注:以上部分信息和图片来自The Go scheduler。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号