MySQL InnoDB锁机制
概述:
锁机制在程序中是最常用的机制之一,当一个程序需要多线程并行访问同一资源时,为了避免一致性问题,通常采用锁机制来处理。在数据库的操作中也有相同的问题,当两个线程同时对一条数据进行操作,为了保证数据的一致性,就需要数据库的锁机制。每种数据库的锁机制都自己的实现方式,mysql作为一款工作中经常遇到的数据库,它的锁机制在面试中也经常会被问到。所以本文针对mysql数据库,对其锁机制进行总结。
mysql的锁可以分为服务层实现的锁,例如Lock Tables、全局读锁、命名锁、字符锁,或者存储引擎的锁,例如行级锁。InnoDB作为MySQL中最为常见的存储引擎,本文默认MySQL选择InnoDB作为存储引擎,将MySQL的锁和InnoDB实现的锁同时进行讨论。
锁的分类按照特性有多种分类,常见的比如显式锁和隐式锁;表锁和行锁;共享锁和排他锁;乐观锁和悲观锁等等,后续会在下方补充概念。
服务级别锁:
表锁
表锁可以是显式也可以是隐式的。显示的锁用Lock Table来创建,但要记得Lock Table之后进行操作,需要在操作结束后,使用UnLock来释放锁。Lock Tables有read和write两种,Lock Tables......Read通常被称为共享锁或者读锁,读锁或者共享锁,是互相不阻塞的,多个用户可以同一时间使用共享锁互相不阻塞。Lock Table......write通常被称为排他锁或者写锁,写锁或者排他锁会阻塞其他的读锁或者写锁,确保在给定时间里,只有一个用户执行写入,防止其他用户读取正在写入的同一资源。
为了进行测试,我们先创建两张测试表,顺便加几条数据
CREATE TABLE `test_product` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `code` varchar(255) DEFAULT NULL, `name` varchar(255) DEFAULT NULL, `price` decimal(10,2) DEFAULT NULL, `quantity` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8; CREATE TABLE `test_user` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, `age` int(3) DEFAULT NULL, `gender` int(1) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8; INSERT INTO `test_user` (`id`, `name`, `age`, `gender`) VALUES ('1', '张三', '16', '1'); INSERT INTO `test_user` (`id`, `name`, `age`, `gender`) VALUES ('2', '李四', '18', '1'); INSERT INTO `test_product` (`id`, `code`, `name`, `price`, `quantity`) VALUES ('1', 'S001', '产品1号', '100.00', '200'); INSERT INTO `test_product` (`id`, `code`, `name`, `price`, `quantity`) VALUES ('2', 'S001', '产品2号', '200.00', '200'); INSERT INTO `locktest`.`test_product` (`code`, `name`, `price`, `quantity`) VALUES ('S003', '产品3号', '300.00', 300); INSERT INTO `locktest`.`test_product` (`code`, `name`, `price`, `quantity`) VALUES ('S004', '产品4号', '400.00', 400); INSERT INTO `locktest`.`test_product` (`code`, `name`, `price`, `quantity`) VALUES ('S005', '产品5号', '500.00', 500);
打开两个客户端连接A和B,在A中输入
LOCK TABLES test_product READ;
在B中输入
SELECT * FROM test_product
B能正常查询并获取到结果。Lock Tables....Read不会阻塞其他线程对表数据的读取。

让A继续保留锁,在B中输入
update test_product set price=250 where id=2;
此时B的线程被阻塞,等待A释放锁。
释放A持有的锁,在A中输入
UNLOCK TABLES;
此时B中显示下图,并且数据已经被变更。

Lock Tables....Read会阻塞其他线程对数据变更。
接下来再对Lock Table....write进行测试,在A线程下执行以下语句,用排它锁锁定test_product。
LOCK TABLES test_product WRITE;
在B中输入以下语句,对test_product表进行查询。
SELECT * FROM test_product;
发现B的查询语句阻塞,等待A释放锁。再开启一个新命令窗口C,输入
update test_product set price=250 where id=2;
同样被阻塞。在A中使用UNLOCK释放锁,B、C成功执行。Lock Tables....Write会阻塞其他线程对数据读和写。
假设在A中进行给test_product加读锁后,对test_product进行更新或者对test_user进行读取更新会怎么样呢。
LOCK TABLES test_product READ;
之后在A中进行test_product更新
update test_product set price=250 where id=2; [SQL]update test_product set price=250 where id=2; [Err] 1099 - Table 'test_product' was locked with a READ lock and can't be updated
然后在A中读取test_user
[SQL]SELECT * from test_user [Err] 1100 - Table 'test_user' was not locked with LOCK TABLES
Lock Tables....Read不允许对表进行更新操作(新增、删除也不行),并且不允许访问未被锁住的表。
对Lock Table....WRITE进行相同的实验,代码相似,就不再贴出。
Lock Tables....WRITE允许对被锁住的表进行增删改查,但不允许对其他表进行访问。
总结上面的结论:
- Lock Tables....READ不会阻塞其他线程对表数据的读取,会阻塞其他线程对数据变更
- Lock Tables....WRITE会阻塞其他线程对数据读和写
- Lock Tables....READ不允许对表进行更新操作(新增、删除也不行),并且不允许访问未被锁住的表
- Lock Tables....WRITE允许对被锁住的表进行增删改查,但不允许对其他表进行访问
lock tables主要性质如上所述,当我们要去查询mysql是否存在lock tables锁状态可以用下面语句进行查询。第二条可以直接看到被锁的表。也可以通过show process来查看部分信息。
LOCK TABLES test_product READ,test_user WRITE; show status like "%lock%"; show OPEN TABLES where In_use > 0;


使用LOCK TABLES时候必须小心,《高性能MySQL》中有一段话:
LOCK TABLES和事务之间相互影响的话,情况会变得非常复杂,在某些MySQL版本中甚至会产生无法预料的结果。因此,本书建议,除了事务中禁用了AUTOCOMMIT,可以使用LOCK TABLES之外,其他任何时候都不要显示地执行LOCK TABLES,不管使用什么存储引擎。
所以在大部分时候,我们不需要使用到LOCK TABLE关键字。
全局读锁
全局锁可以通过FLUSH TABLES WITH READ LOCK获取单个全局读锁,与任务表锁都冲突。解锁的方式也是UNLOCK TABLES。同样设置A、B两个命令窗口,我们对全局锁进行测试。
在A中获取全局读锁
FLUSH TABLES WITH READ LOCK;
然后在A窗口依次做以下实验
1 LOCK TABLES test_user READ; 2 3 LOCK TABLES test_user WRITE; 4 5 SELECT * from test_user; 6 7 update test_product set price=250 where id=1;
第1、5行能够执行成功,第2、7行执行会失败
在B中执行
1 FLUSH TABLES WITH READ LOCK; 2 3 LOCK TABLES test_user READ; 4 5 LOCK TABLES test_user WRITE; 6 7 SELECT * FROM test_product; 8 9 update test_product set price=250 where id=2;
B窗口中执行1、3、7成功。执行5、9失败。
全局读锁其实就相当于用读锁同时锁住所有表。如果当前线程拥有某个表的写锁,则获取全局写锁的时候会报错。如果其他线程拥有某张表的写锁,则全局读锁会阻塞等待其他表释放写锁。
该命令是比较重量级的命令,会阻塞一切更新操作(表的增删改和数据的增删改),主要用于数据库备份的时候获取一致性数据。
命名锁
命名锁是一种表锁,服务器创建或者删除表的时候会创建一个命名锁。如果一个线程LOCK TABLES,另一个线程对被锁定的表进行重命名,查询会被挂起,通过show open tables可以看到两个名字(新名字和旧名字都被锁住了)。
字符锁
字符锁是一种自定义锁,通过SELECT GET_LOCK("xxx",60)来加锁 ,通过release_lock()解锁。假设A线程执行get_lock("xxx",60)后执行sql语句返回结果为1表示拿到锁,B线程同样通过get_lock("xxx",60)获取相同的字符锁,则B线程会处理阻塞等待的状况,如果60秒内A线程没有将锁释放,B线程获取锁超时就会返回0,表示未拿到锁。使用get_lock()方法获取锁,如果线程A调用了两次get_lock(),释放锁的时候也需要使用两次release_lock()来进行解锁。
InnoDB锁:
InnoDB存储引擎在也实现了自己的数据库锁。一般谈到InnoDB锁的时候,首先想到的都是行锁,行锁相比表锁有一些优点,行锁比表锁有更小锁粒度,可以更大的支持并发。但是加锁动作也是需要额外开销的,比如获得锁、检查锁、释放锁等操作都是需要耗费系统资源。如果系统在锁操作上浪费了太多时间,系统的性能就会受到比较大的影响。
InnoDB实现的行锁有共享锁(S)和排它锁(X)两种
共享锁:允许事务去读一行,阻止其他事务对该数据进行修改
排它锁:允许事务去读取更新数据,阻止其他事务对数据进行查询或者修改
行锁虽然很赞,但是还有一个问题,如果一个事务对一张表的某条数据进行加锁,这个时候如果有另外一个线程想要用LOCK TABLES进行锁表,这时候数据库要怎么知道哪张表的哪条数据被加了锁,一张张表一条条数据去遍历是不可行的。InnoDB考虑到这种情况,设计出另外一组锁,意向共享锁(IS)和意向排他锁(IX)。
意向共享锁:当一个事务要给一条数据加S锁的时候,会先对数据所在的表先加上IS锁,成功后才能加上S锁
意向排它锁:当一个事务要给一条数据加X锁的时候,会先对数据所在的表先加上IX锁,成功后才能加上X锁
意向锁之间兼容,不会阻塞。但是会跟S锁和X锁冲突,冲突的方式跟读写锁相同。例如当一张表上已经有一个排它锁(X锁),此时如果另外一个线程要对该表加意向锁,不管意向共享锁还是意向排他锁都不会成功。
| 线程 A | 线程 B |
|
BEGIN;
SELECT * FROM test_product for UPDATE; |
|
|
SELECT * FROM test_product LOCK IN SHARE MODE; 结果:线程阻塞
SELECT * FROM test_product for UPDATE; 结果:线程阻塞 |
|
| COMMIT; | 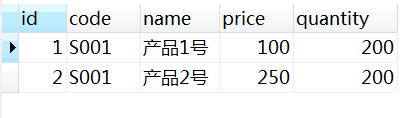 |
上面的例子中,用的两个加锁方式,一个是SELECT........FOR UPDATE,SELECT........LOCK IN SHARE MODE。SELECT FOR UPDATE能为数据添加排他锁,LOCK IN SHARE MODE为数据添加共享锁。这两种锁,在事务中生效,而当事务提交或者回滚的时候,会自动释放锁。遗憾的是,当我们在项目中遇到锁等待的时候,并没有办法知道是哪个线程正在持有锁,也很难确定是哪个事务导致问题。但是我们可以通过这几个表来确认消息Information_schema.processList、Information_schema.innodb_lock_waits、Information_schema.innodb_trx、Information_schema.innodb_locks来获取事务等待的状况,根据片面的锁等待状况来获取具体的数据库信息。
隐式加锁:SELECT FOR UPDATE和LOCK IN SHARE 这种通过编写在mysql里面的方式对需要保护的数据进行加锁的方式称为是显式加锁。还有一种加锁方式是隐式加锁,除了把事务设置成串行时,会对SELECT到的所有数据加锁外,SELECT不会对数据加锁(依赖于MVCC)。当执行update、delete、insert的时候会对数据进行加排它锁。
自增长锁:mysql数据库在很多时候都会设置为主键自增,如果这个时候使用表锁,当事务比较大的时候,会对性能造成比较大的影响。mysql提供了inodb_atuoinc_lock_mode来处理自增长的安全问题。该参数可以设置为0(插入完成之后,即使事务没结束也立即释放锁)、1(在判断出自增长需要使用的数字后就立即释放锁,事务回滚也会造成主键不连续)、2(来一个记录就分配一个值,不使用锁,性能很好,但是可能导致主键不连续)。
外键锁: 当插入和更新子表的时候,首先需要检查父表中的记录,并对附表加一条lock in share mode,而这可能会对两张表的数据检索造成阻塞。所以一般生产数据库上不建议使用外键。
索引和锁:InnoDB在给行添加锁的时候,其实是通过索引来添加锁,如果查询并没有用到索引,就会使用表锁。做个测试
| 线程 A | 线程 B |
|
set autocommit=0; BEGIN;
|
|
|
set autocommit=0;
线程阻塞 |
|
| COMMIT; | 
|

如上所示,如果正常锁行的话,两条线程锁住不同行,不应该有冲突。我们现在给price添加索引再试一次。
ALTER TABLE `test_product` ADD INDEX idx_price ( `price` );
| 线程 A | 线程 B |
|
set autocommit=0; BEGIN;
|
|
|
set autocommit=0;
|
|
|
Select * from test_product where price= 300 for UPDATE; 阻塞 |
添加索引以后会发现,线程A、B查询不同的行的时候,两个线程并没有相互阻塞。但是,即使InnoDB中已经使用了索引,仍然有可能锁住一些不需要的数据。如果不能使用索引查找,InnoDB将会锁住所有行。因为InnoDB中用索引来锁行的方式比较复杂,其中牵涉到InnoDB的锁算法和事务级别,这个后续会讲到。
《高性能MySQL》中有一句话:"InnoDB在二级索引上使用共享锁,但访问主键索引需要排他锁,这消除了覆盖索引的可能性,并且使得SELECT FOR UPDATE 比Lock IN SHARE LOCK 或非锁定查询要慢很多"。除了上面那句话还有一句话有必要斟酌,"select for update,lock in share mode这两个提示会导致某些优化器无法使用,比如覆盖索引,这些锁定经常会被滥用,很容易造成服务器的锁争用问题,实际上应该尽量避免使用这两个提示,通常都有更好的方式可以实现同样的目的。
锁算法和隔离级别:
锁算法:InnoDB的行锁的算法为以下三种
Record Lock:单挑记录上的锁
Gap Lock:间隙锁,锁定一个范围,但不包括记录本身
Next-Key Lock:Record Lock+Gap Lock,锁定一个范围,并且锁定记录本身
InnoDB会根据不同的事务隔离级别来使用不同的算法。网上关于InnoDB不同的事务隔离级别下的锁的观点各不一致,有些甚至和MVCC混淆,这一块有时间再进行整理。可以去官网上详细了解一下,Mysql官网对InnoDB的事务锁的介绍。
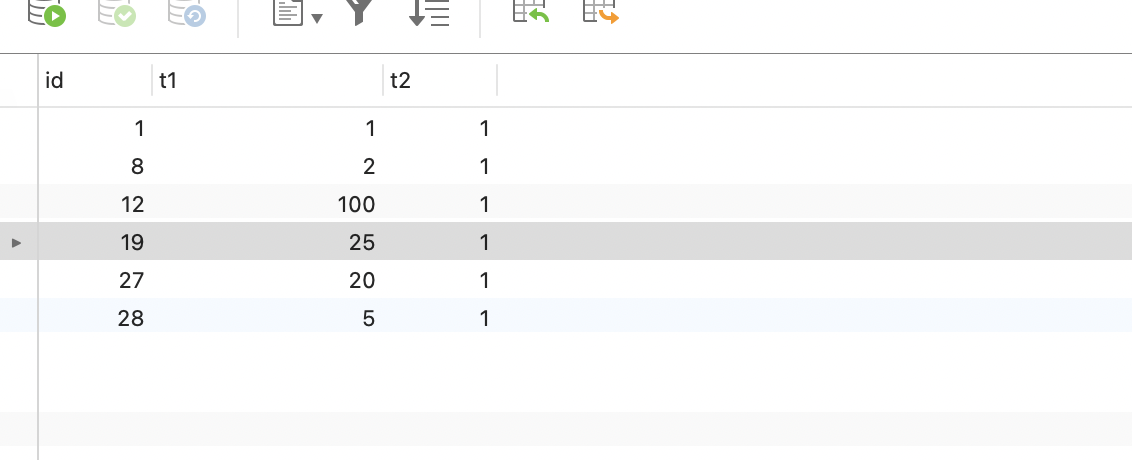
测试了一下GapLock,在隔离级别设置成可重复读的情况下,创建如下图表,t1字段作为普通索引。
CREATE TABLE `test` ( `id` bigint unsigned NOT NULL AUTO_INCREMENT, `t1` bigint NOT NULL, `t2` bigint NOT NULL, PRIMARY KEY (`id`), KEY `uiq_t1` (`t1`) USING BTREE COMMENT '普通索引' ) ENGINE=InnoDB AUTO_INCREMENT=56 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
在表里插入如下等数据
| 线程1 | 线程2 |
|
删除一个不存在数据,触发GAP lock BEGIN; |
|
|
BEGIN; 执行被阻塞 |
查看performance_schema.data_locks表,可以看到此时存在GAP LOCK,锁住了t1字段的(20-25)之间的区间。

如果使用select for update 语句则会直接加上行锁+GAP LOCK,这个大概就是NEXT-KEY吧(不确定😓)
BEGIN; SELECT * from test where t1 = 20 for update;

MVCC:多版本控制,InnoDB实现MVCC是通过在每行记录后面保存两个隐藏的列来实现,一个保存创建的事务版本号,一个保存的是删除的事务版本号。MVCC只有在REPEATABLE READ 和 READ COMMITED两个隔离级别下工作。另外两个隔离级别与MVCC并不兼容,因为READ UNCOMMITED总是读取最新数据,跟事务版本无关,而SERIALIZABLE会对读取的所有行都进行加锁。
乐观锁和悲观锁:
悲观锁:指悲观的认为,需要访问的数据随时可能被其他人访问或者修改。因此在访问数据之前,对要访问的数据加锁,不允许其他其他人对数据进行访问或者修改。上述讲到的服务器锁和InnoDB锁都属于悲观锁。
乐观锁:指乐观的认为要访问的数据不会被人修改。因此不对数据进行加锁,如果操作的时候发现已经失败了,则重新获取数据进行更新(如CAS),或者直接返回操作失败。
电商卖东西的时候,必须解决的是超卖的问题,超卖是指商品的数量比如只有5件,结果卖出去6件的情况。我们用代码来演示一下怎么用乐观锁和悲观锁解决这个问题。假设test_prodcut表中,S001和S002的产品各有100件。
@Service public class ProductService implements IProductService { @Resource private ProductMapper productMapper; private static final String product_code = "S001"; private static final String product_code1 = "S002"; //乐观锁下单成功数 private final AtomicInteger optimisticSuccess = new AtomicInteger(0); //乐观锁下单失败数 private final AtomicInteger optimisticFalse = new AtomicInteger(0); //悲观锁下单成功数 private final AtomicInteger pessimisticSuccess = new AtomicInteger(0); //悲观锁下单失败数 private final AtomicInteger pessimisticFalse = new AtomicInteger(0); //乐观锁下单 @Override @Transactional(rollbackFor = Exception.class) public void orderProductOptimistic() throws TestException { int num = productMapper.queryProductNumByCode(product_code); if (num <= 0) { optimisticFalse.incrementAndGet(); return; } int result = productMapper.updateOrderQuantityOptimistic(product_code); if (result == 0) { optimisticFalse.incrementAndGet(); throw new TestException("商品已经卖完"); } optimisticSuccess.incrementAndGet(); } //获取售卖记录 @Override public String getStatistics() { return "optimisticSuccess:" + optimisticSuccess + ", optimisticFalse:" + optimisticFalse + ",pessimisticSuccess:" + pessimisticSuccess + ", pessimisticFalse:" + pessimisticFalse; } //悲观锁下单 @Override @Transactional(rollbackFor = Exception.class) public void orderProductPessimistic() { int num = productMapper.queryProductNumByCodeForUpdate(product_code1); if (num <= 0) { pessimisticFalse.incrementAndGet(); return; } productMapper.updateOrderQuantityPessimistic(product_code1); pessimisticSuccess.incrementAndGet(); } //获取产品详情 @Override @Transactional public ProductResutl getProductDetail() { Random random = new Random(); String code = random.nextInt() % 2 == 0 ? product_code : product_code1; ProductResutl productResutl = productMapper.selectProductDetail(code); return productResutl; } //清楚记录 @Override public void clearStatistics() { optimisticSuccess.set(0); optimisticFalse.set(0); pessimisticSuccess.set(0); pessimisticFalse.set(0); } }
对应sql如下。
1 <update id="updateOrderQuantityPessimistic"> 2 update test_product set quantity=quantity-1 where code=#{productCode} 3 </update> 4 5 <update id="updateOrderQuantityOptimistic"> 6 update test_product set quantity=quantity-1 where code=#{productCode} and quantity>0; 7 </update> 8 9 <select id="queryProductNumByCode" resultType="java.lang.Integer"> 10 SELECT quantity From test_product WHERE code=#{productCode} 11 </select> 12 13 14 <select id="queryProductNumByCodeForUpdate" resultType="java.lang.Integer"> 15 SELECT quantity From test_product WHERE code=#{productCode} for update 16 </select> 17 18 <select id="selectProductDetail" resultType="com.chinaredstar.jc.crawler.biz.result.product.ProductResutl"> 19 SELECT 20 id as id, 21 code as code, 22 name as name, 23 price as price, 24 quantity as quantity 25 FROM test_product WHERE code=#{productCode} 26 </select>
测试工具使用JMeter,开启200个线程,分别对通过乐观锁和悲观锁进行下单。
悲观锁下单结果:

乐观锁下单结果:

售卖情况如下:
![]()
结果显示乐观锁和悲观锁都能成功的防止产品超卖,上述的数据比较粗糙,不能代表实际生产中的一些情况,但是在很多时候。使用乐观锁因为不需要对数据加锁,防止锁冲突,可能得到更好的性能。但是也不代表乐观锁比悲观锁更好,还是看具体的生产情况,来判断需要的是乐观锁还是悲观锁。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号