


爬虫优化设计
该随笔是在原随笔上进行的优化,原随笔地址:http://www.cnblogs.com/null-qige/p/8028832.html
一、原设计
基于原先设计,当一个任务启动,添加多个spider,每个spider负责一个业务。通过子spider持有父spider的引用来进行业务关联,比如子spider关闭之前必须确认父spider的状态是否已经关闭。
二、问题:
在业务拓展的时候出现了一个问题,当需要暂停一个任务的时候怎么处理?之前的spider并没有统一管理入口;通过自spider持有父spider引用的方式,加大了相互之间的耦合,在多线程的情况下容易造成时序的混乱,可否将状态管理抽离出来,统一管理。
三、优化思路:
可以新建一个类,类里包含单个任务下的所有spider,统一管理spider的状态。并对外提供接口,管理任务的暂停,重启和爬取页面的数量统计等动作。
设计图如下:
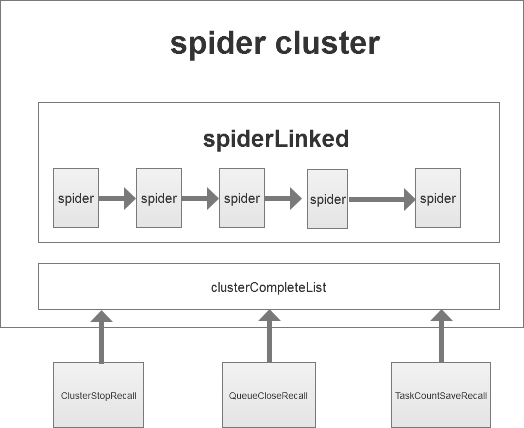
图中的spiderLinked,是一个LinkedList(LinkedList是双向链表,与上图表示有偏差),每个spider的下一个节点是其子spider。每一个spider是一个可观察者,spiderCluster是其观察者,当spider状态变更时通知spiderCluter,让spiderCluter去处理状态变更引起的变化。
代码示例如下:
/** * * 观察者 * @author zhuangj * @date 2017/12/26 */ public interface Observer { /** * 观察的对象发生变化 * @param observable */ void update(Observable observable); }
/** * 可观察的对象 * @author zhuangj * @date 2017/12/26 */ public interface Observable { /** * 观察者队列 */ Set<Observer> obs = new HashSet<>(); /** * 添加观察者 * @param observer */ default void addObserver(Observer observer){ obs.add(observer); } /** * 移除观察者 * @param observer */ default void removeObserver(Observer observer){ obs.remove(observer); } /** * 通知观察者 * @param */ default void notifyAllObserver(){ obs.forEach(observer -> observer.update(this)); } }
public class JcSpider extends SpiderNew implements Observable { @Override protected Boolean statCompareAndSet(int compare, int set){ Boolean result=stat.compareAndSet(compare, set); this.notifyAllObserver(); return result; } }
public class SpiderCluster implements Observer{ @Override public void update(Observable observable) { JcSpider jcSpider=(JcSpider)observable; spiderCloseRecall(jcSpider); } /** * 单个爬虫结束时回调 * @param jcSpider */ public void spiderCloseRecall(JcSpider jcSpider){ Iterator<JcSpider> iter = spiderLinked.iterator(); //一个spider节点完成,设置下一个spider节点的parentStatus while (iter.hasNext()){ if(iter.next().getUUID().equals(jcSpider.getUUID())&&iter.hasNext()){ iter.next().setParentStatus(jcSpider.getStatus()); return; } } //整个爬虫已经执行完毕 if(this.getUnCrawlingCount()==0&&CollectionUtils.isNotEmpty(this.clusterCompleteList)){ clusterCompleteList.forEach(clusterCompleteEvent -> clusterCompleteEvent.event(jcSpider.getTaskName())); } } }
通过这种方式实现了状态的统一管理。
其中clusterCompleteList是 ClusterCompleteRecall接口的集合,ClusterCompleteRecall接口有个event方法,会在任务完全结束时候触发。如上图所示,当一个任务完全爬取结束时候,ClusterStopRecall会关闭整个爬虫簇,QueueCloseRecall会删除MQ的消息队列,TaskCountSaveRecall会统计已经爬取的页面数和未爬取的页面进行统计。如此设计便于后期业务拓展。
业务要求任务可以进行暂停和重启。我的做法是暂时时关闭所有爬虫簇下的爬虫和MQ消费者,当任务重启时,与新增任务一样添加爬虫簇,但是不添加rootUrl,所以爬虫只能从MQ中读取之前未爬取完毕的网站。至于统计已爬取和尚未爬取的网站数量,只要获取到spiderCluster,就可以读取每个spider的数据。示意代码就不贴出来了。


