
webMagic+RabbitMQ+ES爬取京东建材数据
本次爬虫所要爬取的数据为京东建材数据,在爬取京东的过程中,发现京东并没有做反爬虫动作,所以爬取的过程还是比较顺利的。
为什么要用WebMagic:
- WebMagic作为一款轻量级的Java爬虫框架,可以极大的减少爬虫的开发时间
为什么要使用MQ(本项目用的RabbitMq,其他的MQ也可以):
- 解耦各个模块,实现各个爬虫之间相互独立
- 项目健壮性,不管是主动还是被动原因(断电等状况)停下了项目,只需要重新读取MQ中的数据就能继续工作
- 拆分了业务逻辑,使每个模块更加简单。代码易于编写
为什么要用ES:
- 方便后期搜索
- 业务需求
项目大体架构图:
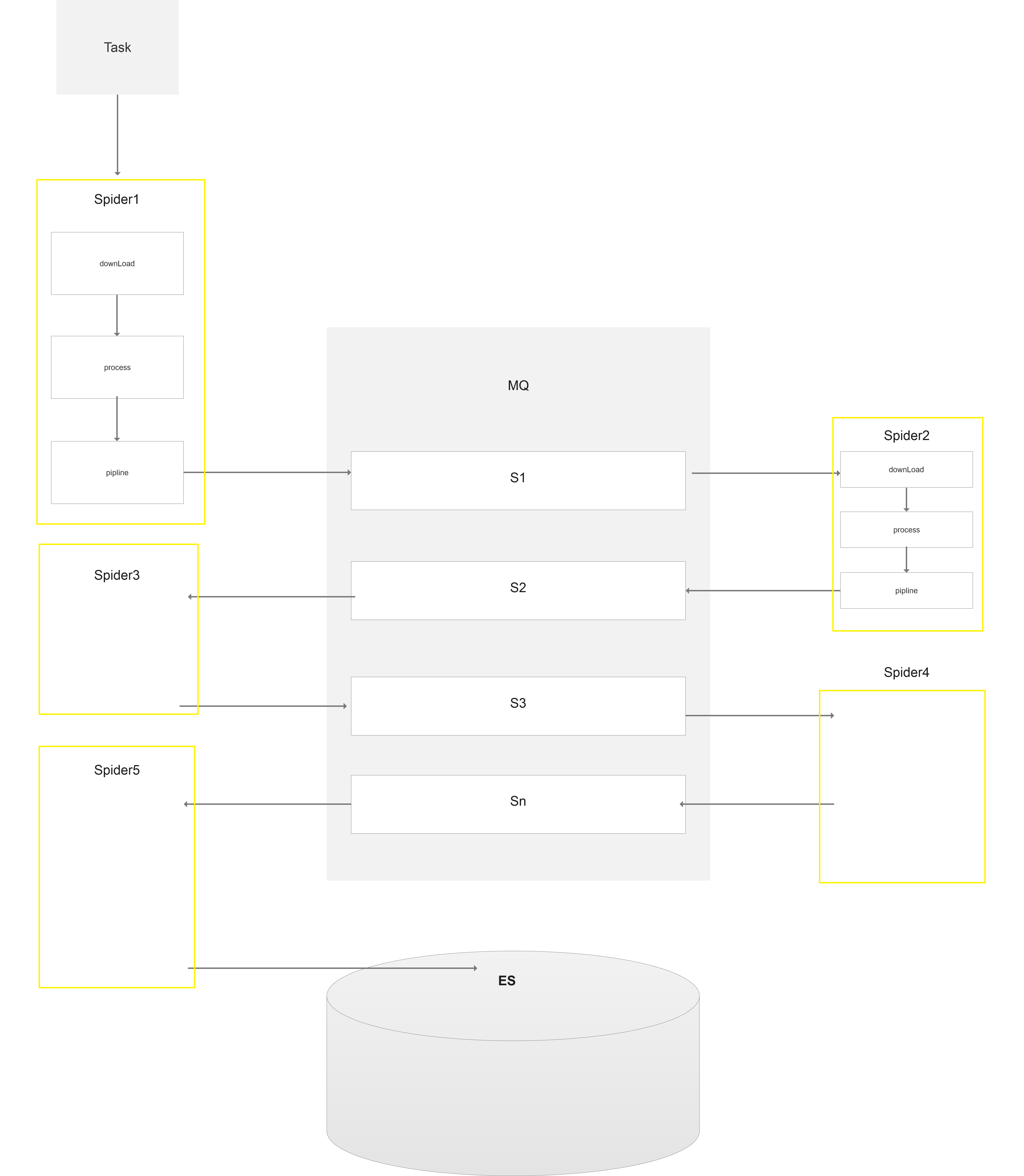
此处有多个spider,前面几层的spider分别处理不同模块的数据,将处理好的数据放入mq,供下一级的spider来调用。
本次爬取的最终页面是商品的详情页,所以最后一级的spider将详情数据爬取完之后存储到ES之中。
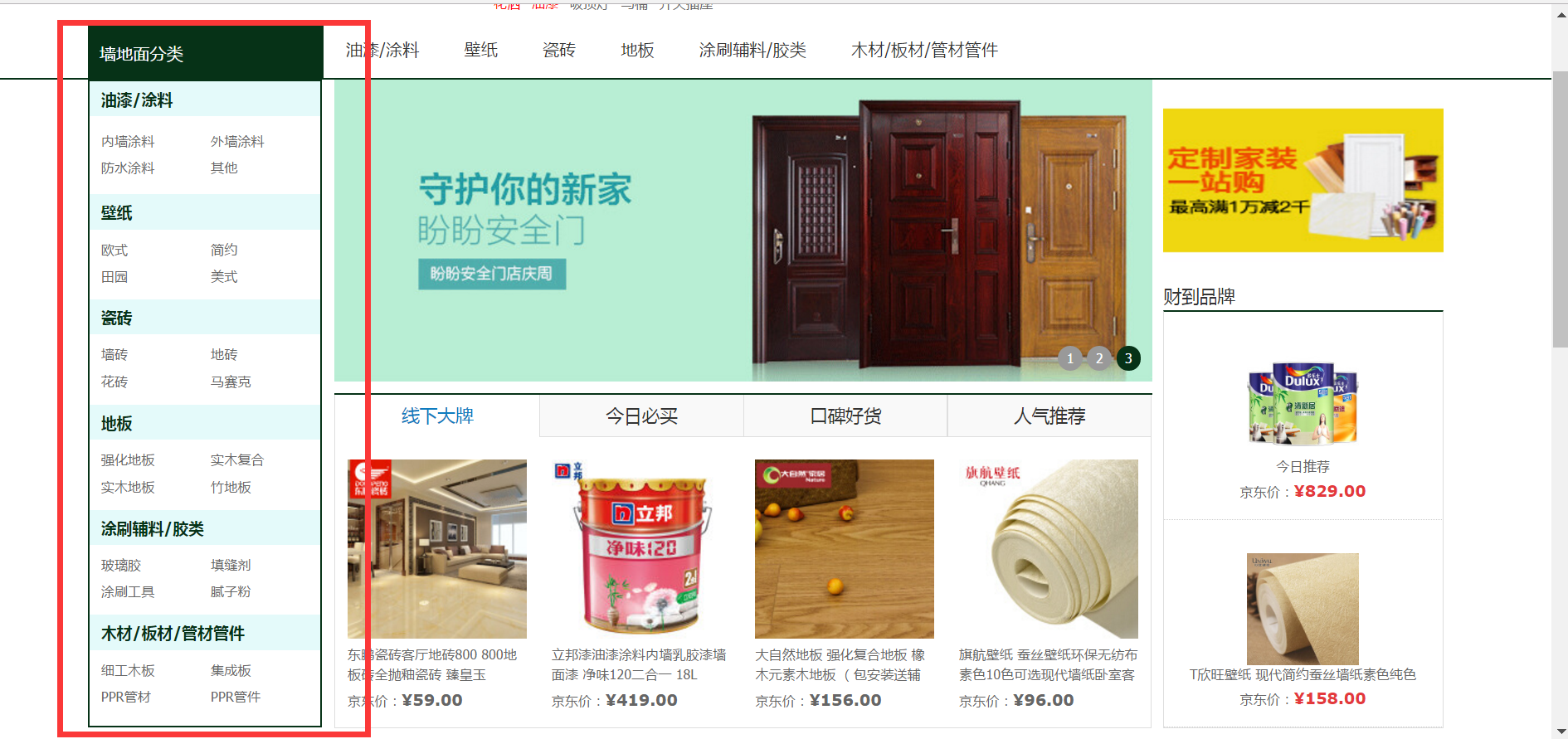
spider1处理京东建材主页:
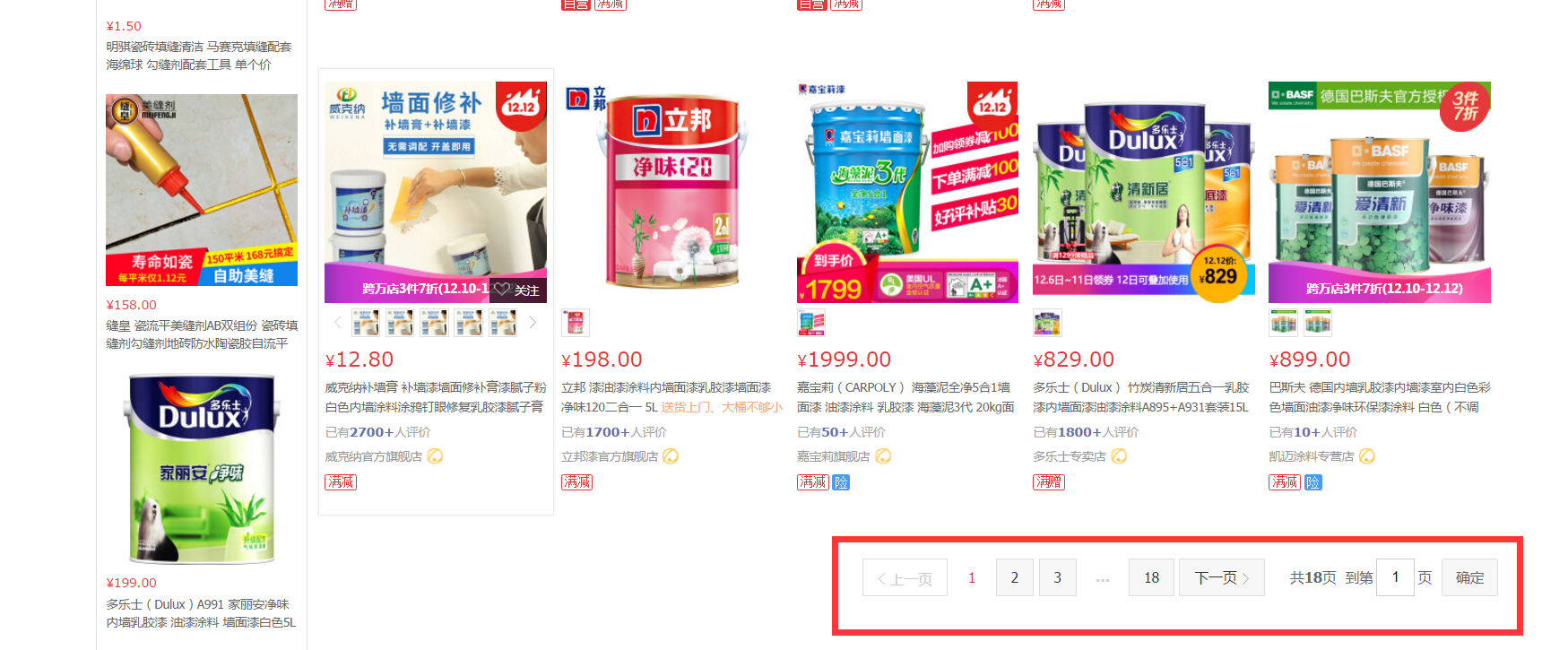
spider2:处理京东分页栏:
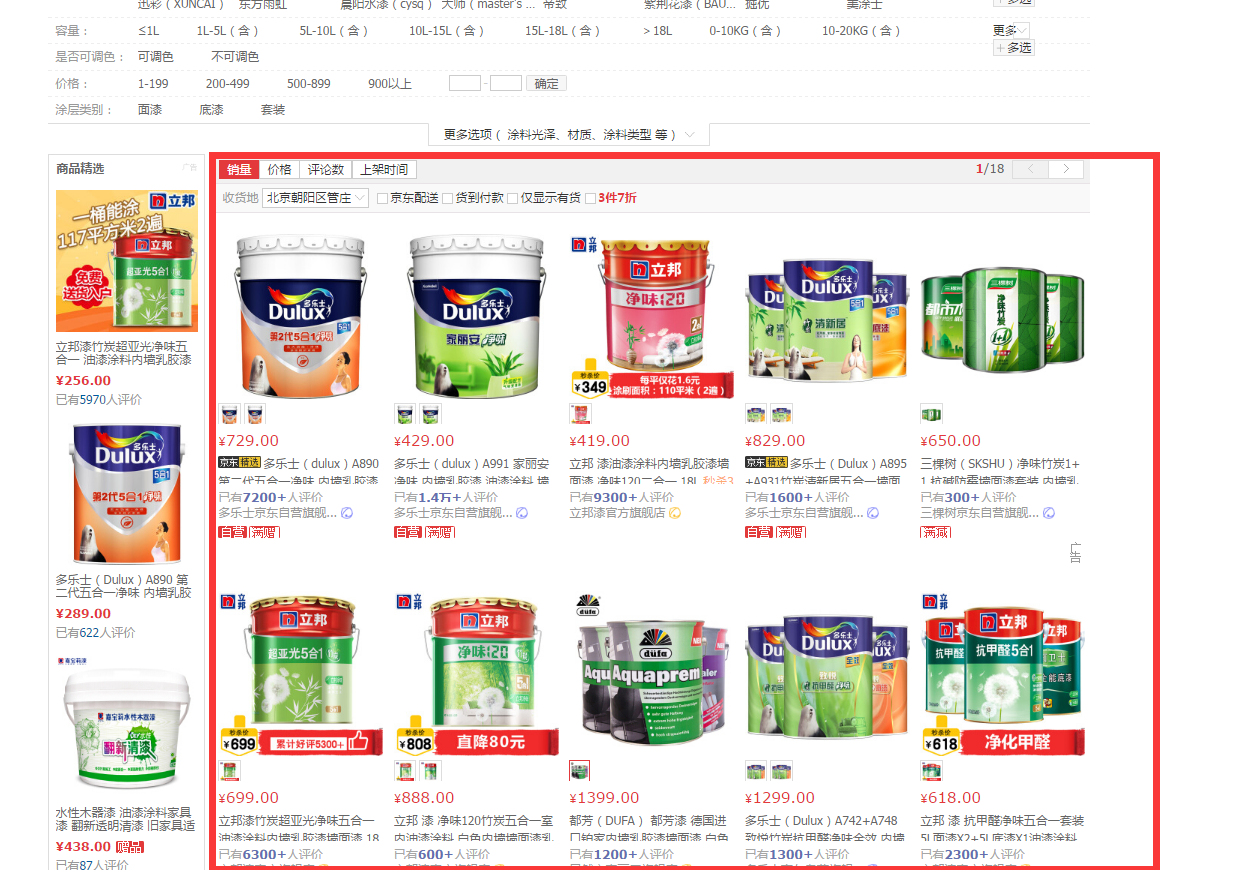
spider3:处理京东列表:
spider4:处理产品详情:
根据上面的框架图。我们发现每一个spider都需要跟MQ链接,第一级的Spider不需要对MQ进行消费,最后一级的Spider不需要负责Mq数据的生产。 其他的spider既需要对MQ进行消费,也需要对MQ进行生产。
因此我们给没一个spider都绑上一个消费者和生产者,框架示意图如下:
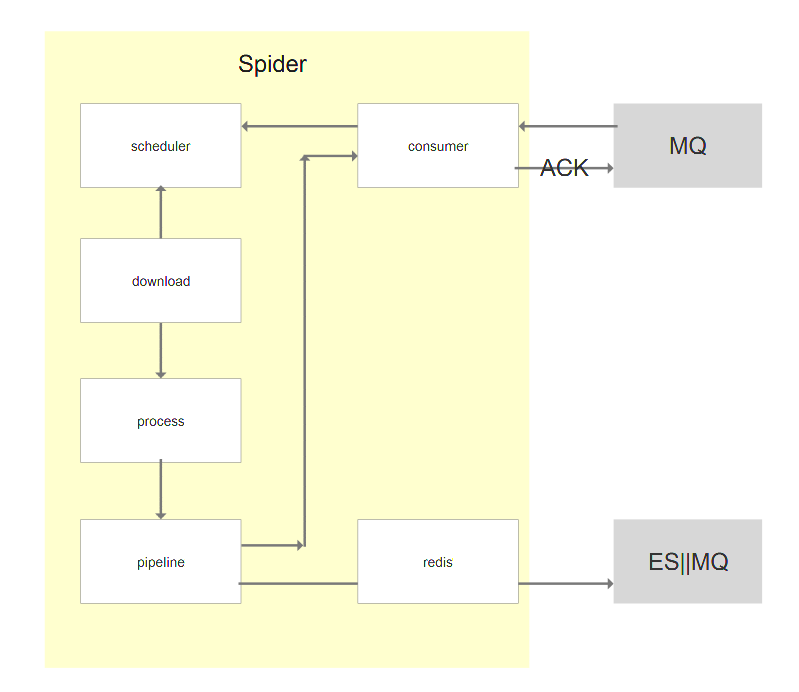
pipline获取想要的数据后,在reids储存爬取过的路径,如果有重复爬取过的路径就不进行保存。
WebMagic作为一款优秀爬虫框架,拓展性良好,我们在原先的框架上稍作拓展。
首先附上Spider拓展后的代码:
package com.chinaredstar.jc.core.spider; import com.chinaredstar.jc.core.page.CrawlerPage; import com.chinaredstar.jc.crawler.consumer.Consumer; import com.chinaredstar.jc.infras.utils.JSONUtil; import com.rabbitmq.client.QueueingConsumer; import org.apache.commons.collections.map.HashedMap; import us.codecraft.webmagic.Request; import us.codecraft.webmagic.Spider; import us.codecraft.webmagic.SpiderListener; import us.codecraft.webmagic.processor.PageProcessor; import java.io.IOException; import java.util.ArrayList; import java.util.Map; /** * @author zhuangj * @date 2017/12/1 */ public class JcSpider extends Spider { /** * 队列消费者,为spider提供数据 */ private Consumer consumer; /** * 队列消费者,为spider提供数据 */ private String consumerQueueName; /** * 用于确认Mq中的消息是否执行完毕 */ private Map<String,QueueingConsumer.Delivery> ackMap=new HashedMap(); /** * 剩余消息数量 */ private Integer messageNum=0; /** * 父节点爬虫,父节点停止,子节点才能停止 */ private JcSpider parentSpider; public JcSpider(PageProcessor pageProcessor) { super(pageProcessor); exitWhenComplete=false; } public Consumer getConsumer() { return consumer; } public void setConsumer(Consumer consumer) { this.consumer = consumer; } public JcSpider getParentSpider() { return parentSpider; } public void setParentSpider(JcSpider parentSpider) { this.parentSpider = parentSpider; } public Integer getMessageNum() { return messageNum; } public void setMessageNum(Integer messageNum) { this.messageNum = messageNum; } public String getConsumerQueueName() { return consumerQueueName; } public void setConsumerQueueName(String consumerQueueName) { this.consumerQueueName = consumerQueueName; } @Override protected void initComponent() { super.initComponent(); this.setSpiderListeners(new ArrayList<>()); this.requestMessageListen(); // this.startConsumer(consumerQueueName); } public void startConsumer(String queueName) { if(consumer==null){ this.exitWhenComplete=true; return; } logger.info("queueName:{},startConsumer",queueName); JcSpider jcSpider = this; Runnable myRunnable = () -> { try { messageNum=consumer.getQueueMsgNum(queueName); Status parentStatus = Status.Stopped; if(parentSpider!=null){ parentStatus=parentSpider.getStatus(); } while (!parentStatus.equals(Status.Stopped) || messageNum > 0) { if(!jcSpider.getStatus().equals(Status.Running)){ Thread.sleep(500); } QueueingConsumer.Delivery delivery = consumer.getDeliveryMessage(queueName); String message = new String(delivery.getBody()); CrawlerPage crawlerPage = JSONUtil.toObject(message, CrawlerPage.class); Request request = crawlerPage.translateRequest(); //添加监听 ackMap.put(request.getUrl(),delivery); jcSpider.addRequest(request); messageNum=consumer.getQueueMsgNum(queueName); if(messageNum==0){ Thread.sleep(500); } } System.out.println("spider:"+getUUID()+",consumer stop"); if(parentSpider!=null){ System.out.println("parentStatus:"+parentSpider.getStatus().name()); } System.out.println("messageNum:"+messageNum); //父级没有消息,消息队列没有消息,爬虫完成后就退出了 Thread.sleep(2000); this.exitWhenComplete=true; } catch (Exception e) { e.printStackTrace(); } }; Thread thread = new Thread(myRunnable); thread.start(); } /** * 添加请求RequestMessage */ private void requestMessageListen(){ this.getSpiderListeners().add(new SpiderListener() { @Override public void onSuccess(Request request) { ackMq(request); } @Override public void onError(Request request) { ackMq(request); } }); } public void ackMq(Request request){ try { QueueingConsumer.Delivery delivery=ackMap.get(request.getUrl()); if(delivery!=null){ consumer.ackMessage(delivery); ackMap.remove(request.getUrl()); } } catch (IOException e) { e.printStackTrace(); } } }
我们在原先的webMagic spider基础上添加一个异步的消费者consumer(consumer封装了rabbitMq的消费操作,比较简单就不附代码),它的作用:
- 负责读取MQ中待消费的信息,并将需要爬取数据添加的spider的requestList。
- 记录所有读取到消息。当spider消费完这段消息后,返回消息的ack给MQ,表示消息已经被成功消费。
- 读取queue中的消息剩余量,作为关闭spider的条件之一
spider基础上添加一个父级的spider,它的作用:
- 配合consumer读取消息剩余量关闭spider。如果父级的spider不存在或者已经关闭,当前spider已经消费完毕,queue中也没有剩余的消息。当前的spider就可以关闭了
spider根据级别添加MqPipeline或者EsPipeline,将处理后的数据添加到MQ或者ES之中:
MqPipeline代码如下:
package com.chinaredstar.jc.core.pipeline; import com.chinaredstar.jc.core.page.CrawlerPage; import com.chinaredstar.jc.core.util.RedisUtil; import com.chinaredstar.jc.crawler.producer.Producer; import com.chinaredstar.jc.infras.utils.JSONUtil; import org.apache.commons.collections4.CollectionUtils; import us.codecraft.webmagic.ResultItems; import us.codecraft.webmagic.Task; import us.codecraft.webmagic.pipeline.Pipeline; import java.io.IOException; import java.util.List; /** * 消息队列pipeline * @author lenovo * @date 2017/12/1 */ public class MqPipeline implements Pipeline { private Producer producer; public MqPipeline(Producer producer) { this.producer = producer; } public Producer getProducer() { return producer; } public void setProducer(Producer producer) { this.producer = producer; } @Override public void process(ResultItems resultItems, Task task) { try { List<CrawlerPage> crawlerPageList= resultItems.get("nextPageList"); if(CollectionUtils.isEmpty(crawlerPageList)) { return; } String key=task.getUUID(); for(CrawlerPage page:crawlerPageList){ //校验路径是否爬取过 String url=page.getCurrentUrl(); if(RedisUtil.sContain(key,url)){ continue; } producer.basicPublish(JSONUtil.toJSonString(page)); RedisUtil.sAdd(key,url); } } catch (IOException e) { e.printStackTrace(); } } }
EsPipeline如下:
package com.chinaredstar.jc.core.pipeline; import com.chinaredstar.jc.core.es.EsConnectionPool; import com.chinaredstar.jc.infras.utils.json.JsonFormatter; import org.elasticsearch.action.admin.indices.create.CreateIndexRequest; import org.elasticsearch.action.admin.indices.exists.indices.IndicesExistsRequest; import org.elasticsearch.action.admin.indices.exists.indices.IndicesExistsResponse; import org.elasticsearch.action.bulk.BulkRequestBuilder; import org.elasticsearch.action.bulk.BulkResponse; import org.elasticsearch.action.index.IndexRequestBuilder; import org.elasticsearch.client.transport.TransportClient; import org.elasticsearch.common.xcontent.XContentType; import us.codecraft.webmagic.ResultItems; import us.codecraft.webmagic.Task; import us.codecraft.webmagic.pipeline.Pipeline; import java.io.IOException; import java.net.UnknownHostException; /** * Created by zhuangj on 2017/12/1. */ public class EsPipeline implements Pipeline { private String taskName; private EsConnectionPool pool=new EsConnectionPool(3); public EsPipeline(String taskName) { this.taskName=taskName; } @Override public void process(ResultItems resultItems, Task task) { try { TransportClient client=pool.get(); this.createIndex(client,taskName); this.insertData(client,taskName,"crawler",null, JsonFormatter.toJsonAsString(resultItems.getAll())); // System.out.println("save ES:" + JsonFormatter.toJsonAsString(resultItems.getAll())); pool.returnToPool(client); } catch (IOException e) { e.printStackTrace(); } catch (InterruptedException e) { e.printStackTrace(); } } /** * 创建索引 */ private boolean createIndex(TransportClient client,String index) { try { if (isIndexExist(client,index)) { return true; } client.admin().indices().create(new CreateIndexRequest(index)).actionGet(); return true; }catch (Exception e){ return false; } } /** * 查询索引是否存在 * @param index * @return */ private boolean isIndexExist(TransportClient client,String index) throws UnknownHostException, InterruptedException { IndicesExistsRequest request = new IndicesExistsRequest(index); IndicesExistsResponse response = client.admin().indices().exists(request).actionGet(); return response.isExists(); } /** * 导入数据 * * @param index * @param type * @param id * @param data * @throws IOException */ private BulkResponse insertData(TransportClient client,String index, String type, String id, String data) throws IOException, InterruptedException { //核心方法BulkRequestBuilder拼接多个Json BulkRequestBuilder bulkRequest = client.prepareBulk(); IndexRequestBuilder requestBuilder = client.prepareIndex(index, type, id).setSource(data, XContentType.JSON); bulkRequest.add(requestBuilder); //插入文档至ES, 完成! BulkResponse bulkRequestBuilder=bulkRequest.execute().actionGet(); return bulkRequestBuilder; } }
上方的EsPipine中创建了一个EsConnectionPool,使用池技术重用ES的conection,提高了数据储存到ES中速度。
(后面发现Esclient使用异步方式来处理请求,本身自带多线程功能。此处不需要使用池技术,只需要将client设置为单例,就可以了。)
在业务代码中,将spider创建出来,并递归地创建子级spider
package com.chinaredstar.jc.crawler.biz.service.impl; import com.chinaredstar.jc.core.downloader.JcHttpClientDownloader; import com.chinaredstar.jc.core.page.CrawlerPage; import com.chinaredstar.jc.core.pipeline.EsPipeline; import com.chinaredstar.jc.core.pipeline.MqPipeline; import com.chinaredstar.jc.core.processor.jd.JdProcessorLevelEnum; import com.chinaredstar.jc.core.spider.JcSpider; import com.chinaredstar.jc.crawler.biz.service.IJdService; import com.chinaredstar.jc.crawler.channel.MqChannel; import com.chinaredstar.jc.crawler.common.MqConnectionFactory; import com.chinaredstar.jc.crawler.consumer.Consumer; import com.chinaredstar.jc.crawler.exchange.DefaultExchange; import com.chinaredstar.jc.crawler.exchange.Exchange; import com.chinaredstar.jc.crawler.producer.Producer; import org.springframework.stereotype.Service; import us.codecraft.webmagic.processor.PageProcessor; import java.io.IOException; import java.util.List; import java.util.concurrent.TimeoutException; /** * * 京东数据爬取服务类 * @author zhuangj * @date 2017/11/29 */ @Service public class JdServiceImpl implements IJdService { @Override public List<CrawlerPage> startSpider(String url,String taskName,Integer maxLevel) throws IOException, TimeoutException, InterruptedException { for(int level=1;level<maxLevel;level++){ createJcSpider(url, taskName, maxLevel,level,null); } return null; } @Override public List<CrawlerPage> startSpider(String url, String taskName, Integer level, Integer maxLevel) throws IOException, TimeoutException, InterruptedException { createJcSpider(url, taskName, maxLevel,level,null); return null; } private void createJcSpider(String url, String taskName, Integer maxLevel,Integer level,JcSpider parentSpider) throws IOException, TimeoutException, InterruptedException { PageProcessor pageProcessor= JdProcessorLevelEnum.getProcessorByLevel(level); JcSpider jcSpider=new JcSpider(pageProcessor); jcSpider.setUUID(taskName+level); jcSpider.setDownloader(new JcHttpClientDownloader()); jcSpider.setParentSpider(parentSpider); String producerQueueName=taskName+level; String consumerQueueName=taskName+(level-1); MqChannel mqChannelProducer=createMqChannel(producerQueueName); Producer producer=createProduct(mqChannelProducer); MqChannel mqChannelConsumer=createMqChannel(consumerQueueName); Consumer consumer=createConsumer(mqChannelConsumer); jcSpider.setConsumer(consumer); jcSpider.setConsumerQueueName(consumerQueueName); //最后一级直接进入ES,所以不用进MQ,不需要MQ生产者 if(level<maxLevel){ jcSpider.addPipeline(new MqPipeline(producer)); }else { jcSpider.addPipeline(new EsPipeline(taskName)); } //第一级不需要从MQ中取数据,所以不需要消费者 if(level==1){ jcSpider.addUrl(url); jcSpider.setConsumer(null); } jcSpider.thread(10).start(); jcSpider.startConsumer(consumerQueueName); //创建子集 if(level<maxLevel){ //稍等等待父级spider和consumer启动 Thread.sleep(2000); createJcSpider(url,taskName,maxLevel,level+1,jcSpider); } } /** * 创建消费者 * @param mqChannel * @return * @throws IOException * @throws TimeoutException */ private Producer createProduct(MqChannel mqChannel) throws IOException, TimeoutException { return mqChannel.createProducer(); } /** * 创建生产者 * @param mqChannel * @return * @throws IOException * @throws TimeoutException */ private Consumer createConsumer(MqChannel mqChannel) throws IOException, TimeoutException { return mqChannel.createConsumer(); } /** * 创建连接渠道 * @return * @throws IOException * @throws TimeoutException */ private MqChannel createMqChannel(String queueName) throws IOException, TimeoutException { MqChannel mqChannel=MqConnectionFactory.getConnectionChannel(); Exchange exchange=new DefaultExchange(mqChannel.getChannel(),queueName); mqChannel.setExchange(exchange); return mqChannel; } }
最后启动项目,跑一遍结果:
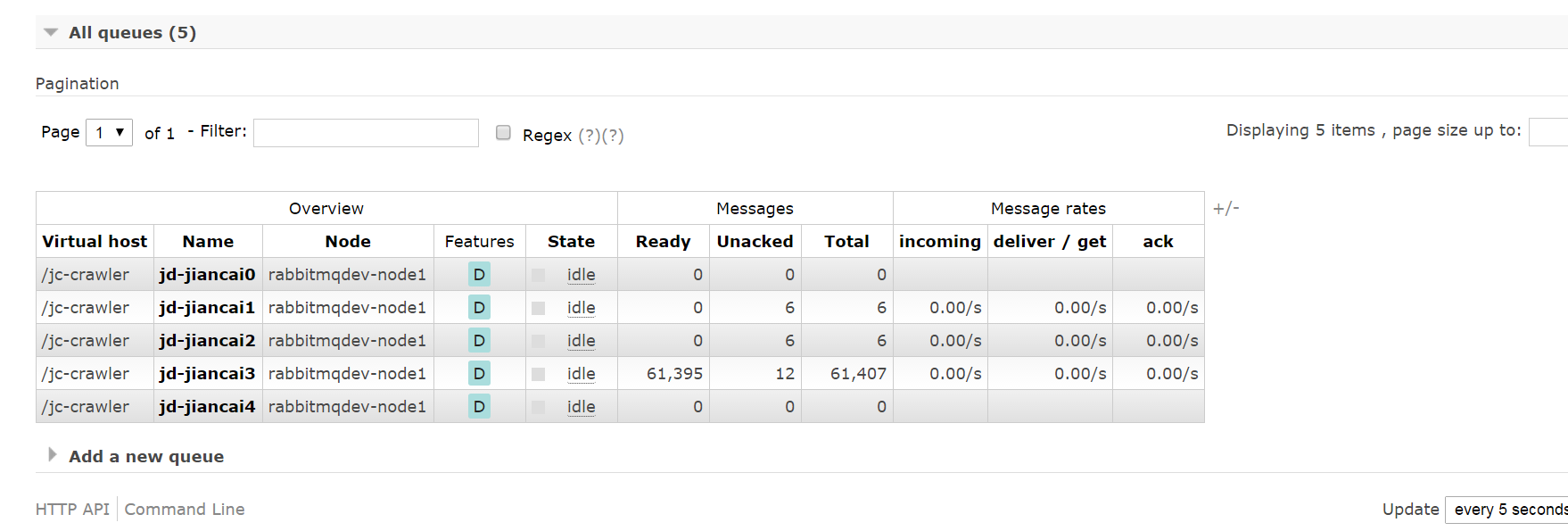
rabbitMq中的创建的相应的队列并且跑起了数据,unacked问题尚未解决。
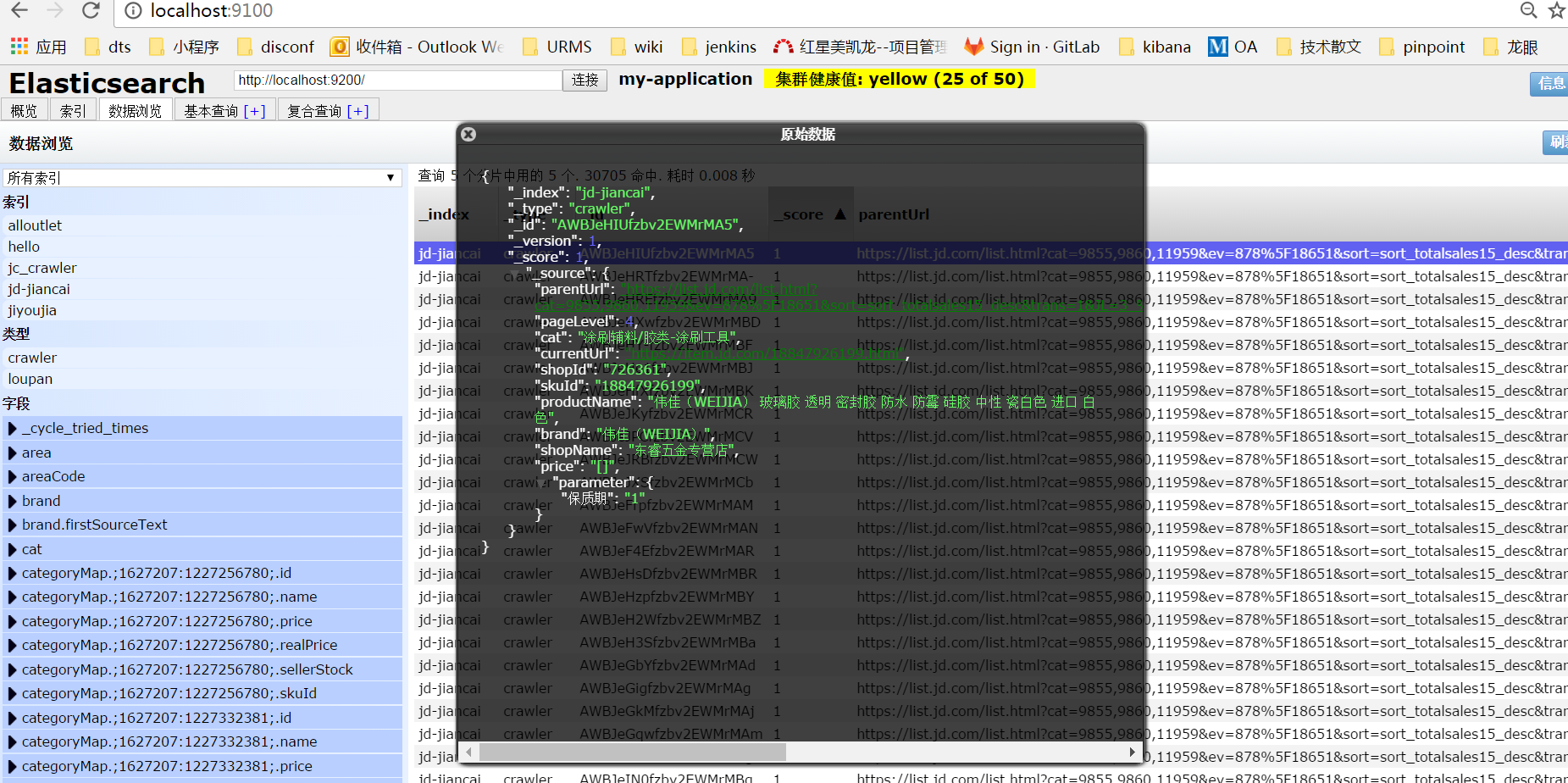
数据存入ES:
因为分析相对简单,只获取了部分数据。
有任何的不合适的地方还请指正。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号