
Redis cluster 学习笔记
Redis Cluster(集群)
redis cluster是redis官方发布的集群解决方案,用于解决redis单机情况下,数据量太大可能导致的各种问题(如备份文件过大等)。redis cluster是去中心化的,每个节点负责整个集群的一部分数据,通过信息交换来获取彼此的数据信息。
数据存储
rerdis cluster的数据存储与单机模式下基本一致,区别是redis cluster只能使用0号数据库。redis cluster将数据分成16384个槽,将这些槽分别指派给不同的节点,所有在redis里存储的key都会被放置到特定的槽里面。每个节点负责一部分槽数据,当所有的槽都被指派完成后,集群才能进行工作,如某个槽没有节点在处理的时候,整个集群都会处于下线状态。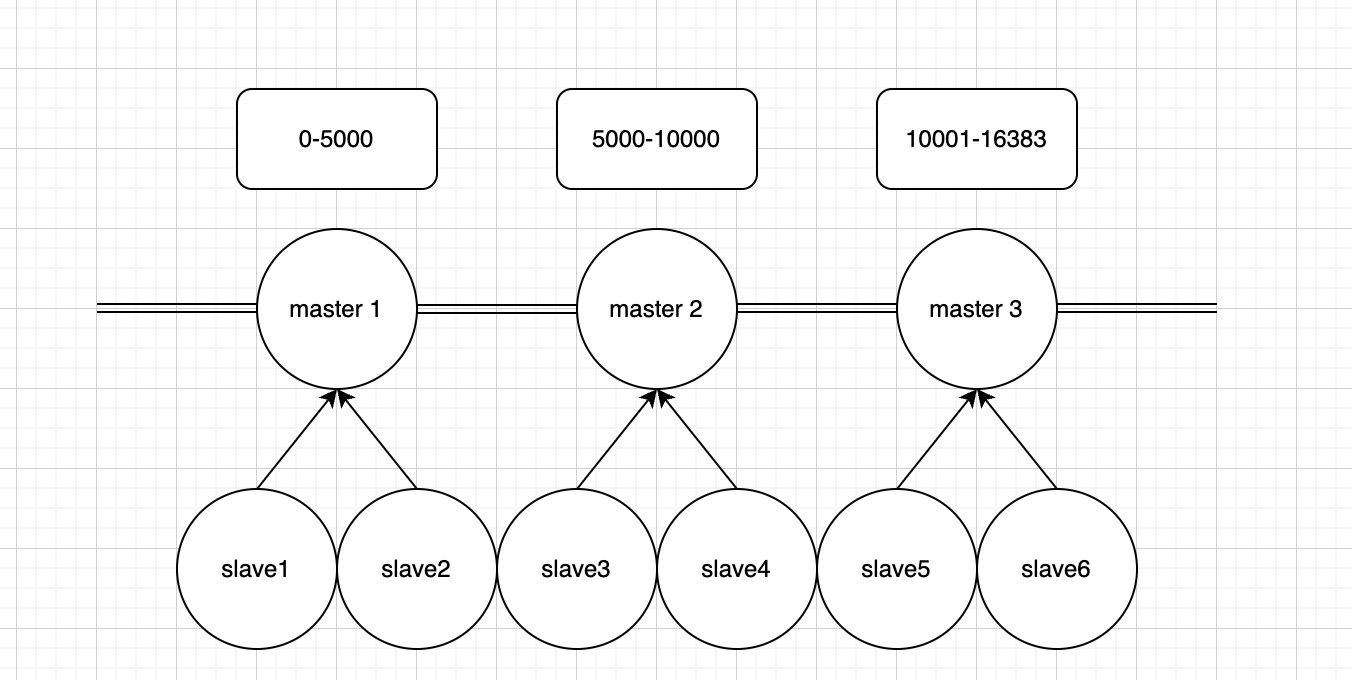
当redis收到一个key操作的命令,如get命令,redis的key通过CRC16算法进行HASH再将结果对16384进行取模(crc(key)&16383),得到的结果就是这个key所存在槽位置,再将该key存放到负责该槽位的对应节点。
有的时候我们需要将多个key放在一个槽底下,否则如事务或者mget、mset不起效果。redis cluster也允许通过打tag的方式将特定的key强制放在某个槽底下,比如使用{ergouzi}.hello,{ergouzi}.kitty,当redis检测到第一个{}之后,会取出{}里面的数据进行crc和&16383的计算,如上两个key,取出来都是ergouzi,计算之后他们将会被放入同一个槽中。
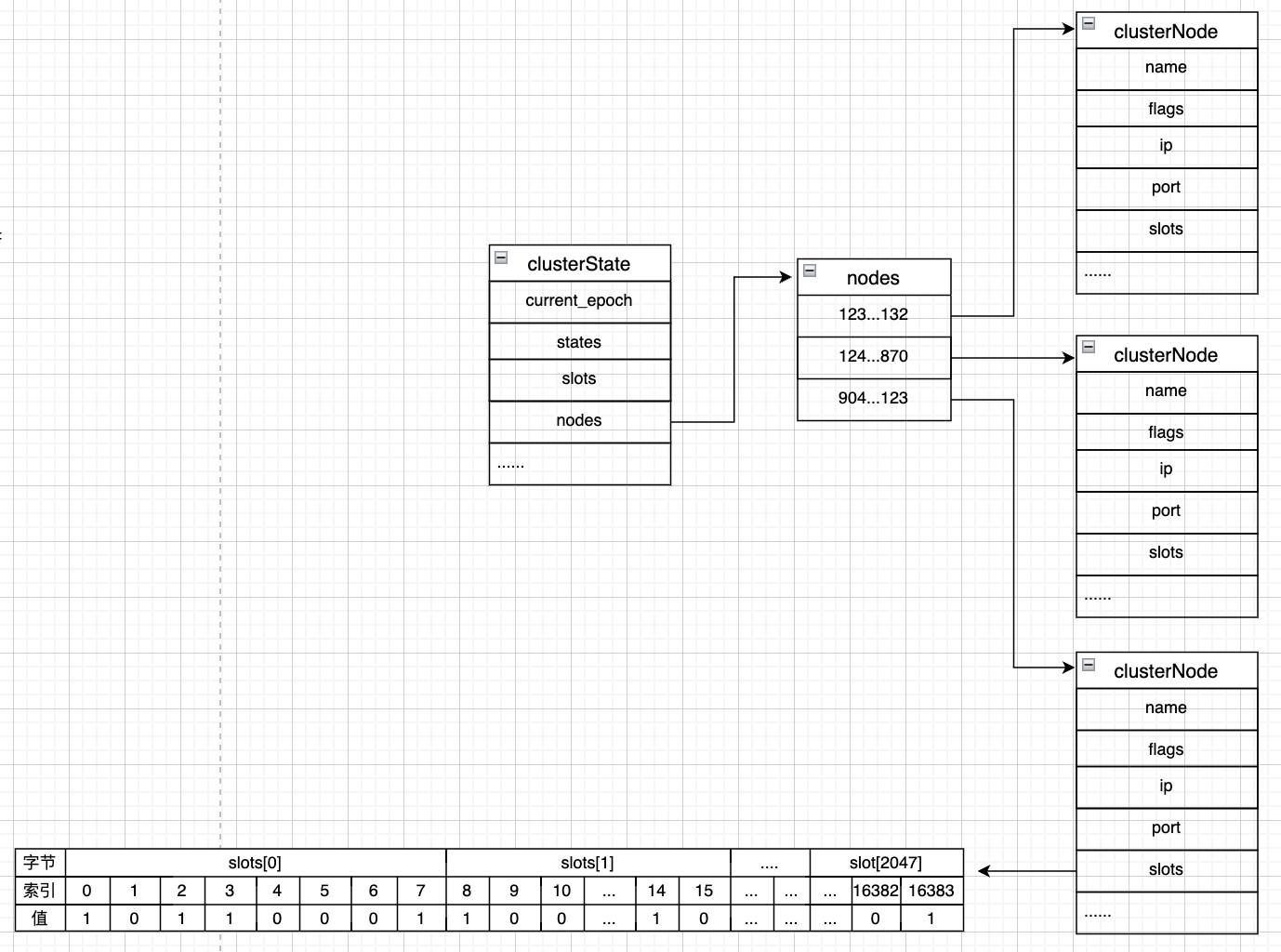
每一个redis节点都会存储一个ClusterState的对象,这个对象里记录着当前的集群状态。ClusterState里有一个nodes属性,存放当前集群里的所有节点,每一个节点用一个clusterNode对象来保存,clusterNode里有一个属性slots,里面存储的值表示当前slot是否由当前节点负责,1表示该槽位的数据由当前节点负责。slots数组的为16384/8=2048个字节,每个字节可以存放8个槽位的状态。当节点之间进行通信,比如A节点告知B节点,当前负责的槽位,就可以将该slots发送给B节点,B节点就知道哪些槽位由A节点负责。
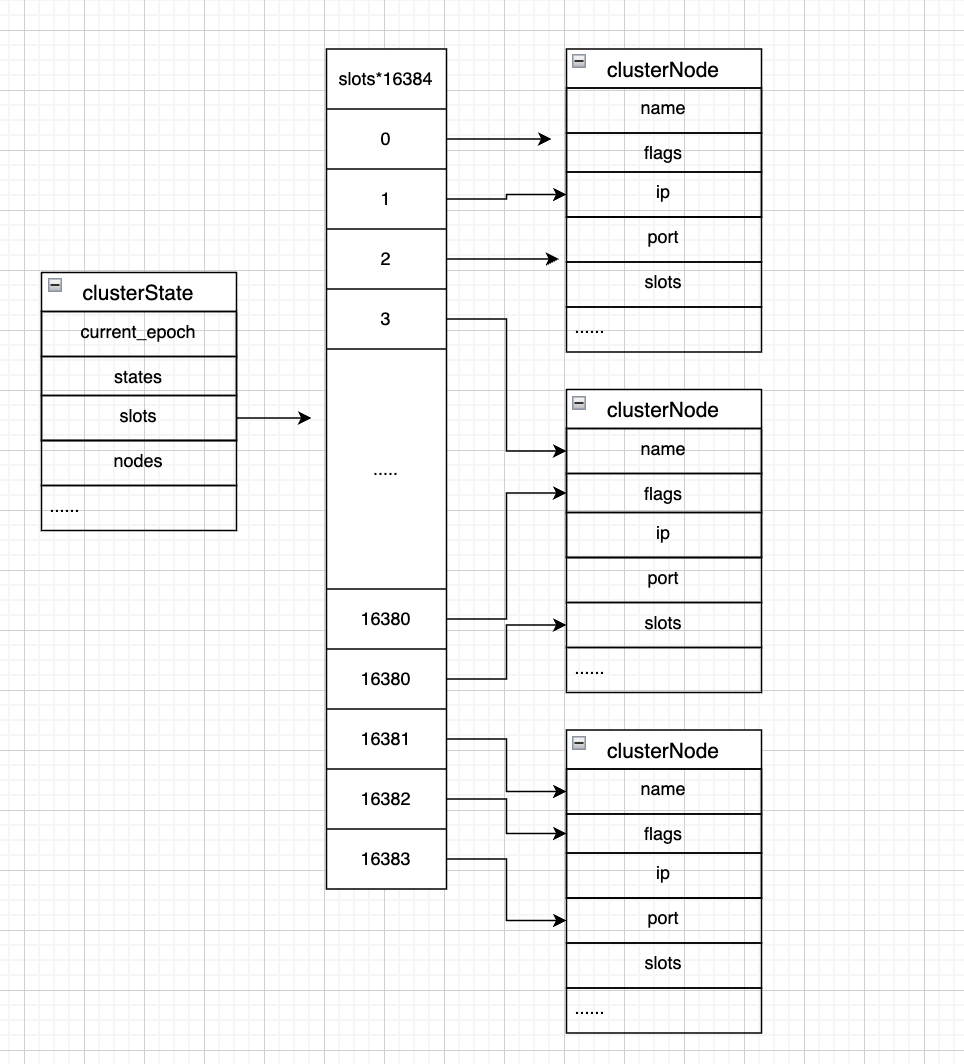
但是当一个节点收到客户端的请求,需要确认某个槽位是由哪个节点负责时,如果通过遍历clusterNode的list,效率将会变的低下。因此在clusterState里面也存储着一组slots,这个slots直接指向对应的node节点。通过查询clusterState的slots,redis就能在O(1)的时间复杂度下直接查询到由哪个节点负责该槽位,并返回MOVE命令,让客户端到对应的节点进行数据查询。
重新分片
redis cluster可以重新指派槽位负责的节点,并且将槽位里对应的key也一起迁移过去。整个迁移过程不需要下线,集群可以在线上工作的同时进行重新分片,源节点和目标节点都能同时工作,实现线上环境的无损发布。
redis cluster在进行槽迁移的时候,从源节点获取内容 => 存到目标节点 => 从源节点删除内容。在对某个槽进行迁移的时候,会将源节点上的槽位和目标节点的槽位设置为过渡中的状态(源节点的槽位为migrating,目标节点的槽位状态为importing),然后每次从源节点的槽中获取N个key,然后遍历的向目标节点发送命令,迁移这N个key。然后重复获取源节点的key,再重复遍历保存到目标节点,保存完成后删除源节点的key,直到该槽位的key全部从源节点保存到目标节点。redis-trib再随机对集群中的任一节点发送消息,告知该槽位已经更换了节点,通过gossip协议,将该消息通知给集群里的所有节点。
假设当节点在迁移的过程中出现了问题,如网络卡顿导致集群下线了。因为源节点和目标节点的槽位都被标志为迁移中,等到下次上线的时候,槽位的迁移会接着进行,保证数据在重新分片之后一定是正常可用的。
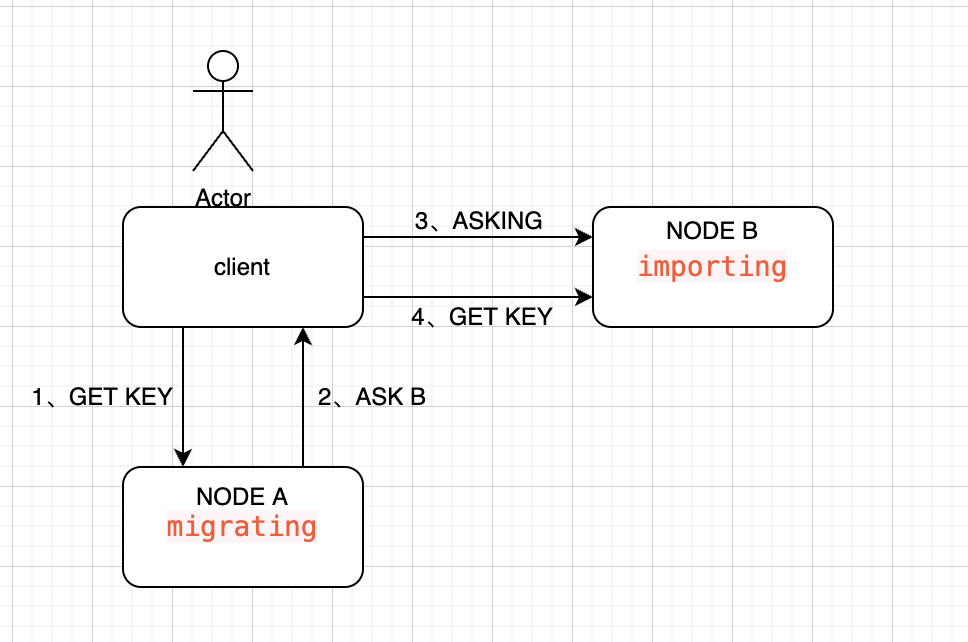
当集群的槽正在迁移的时候,如果有用户访问处于当前槽,则会轮流访问源槽位和目标槽位。例如客户端发起get key的命令,通过hash计算后确认该key数属于节点A的槽位,client向该节点发送get请求,假设该key存在,则直接返回,流程结束。假设A中不存在该key,节点A会返回一个ASK B的响应,通过客户端去节点B查询。客户端收到这个ASK B的响应后,会对节点B连续发送一个ASKING请求和一个GET KEY的请求。发送ASKING请求的意思,是要求B节点需要查询自己的数据,查询该KEY是否存在,假设没有先发送asking请求,那么客户端直接去Node B进行get key时,node b查询时发现该槽位归Node A管理,会返回一个MOVE指令,让客户端去节点A查询,这就会导致重定向的死循环。
故障转移
当集群中有一台master因为故障无法正常工作时,比如断网导导致下线,redis cluster会自发从这个主节点的从节点下选择一台来替代当前master,保证整个集群能够正常工作。整个故障转移的流程如下:
①、判断master节点主观下线:redis集群里的每个节点,会定期想其他节点发送ping消息,如果在规定时间没有收到其他节点返回的pong消息,则将该节点标识为疑似下线,并将该信息储存到 clusterState的下线报告里。假设集群中A节点发送给B节点的PING消息,没有收到PONG回应,A节点会将B节点标识为疑似下线, 并向其他的节点发送信息(使用grossip协议),告知其他的节点,节点A将节点B设置为疑似下线。收到消息的节点会在自己的失效报告中记录该信息。
②、判断mater节点客观下线:当节点(如A)的失效报告中,发现有集群半数以上的节点都将某个节点(如B)设置为疑似下线(n/2+1),则A节点将B节点状态记录为客观下线,并向其他节点告知节 点B已经客观下线。
③、进行新的master节点选举: 当节点B客观下线之后,节点B的从节点将会发起Master选举,选举的流程基于Raft算法,将当前纪元+1,向除B以外的其他master发起投票邀请。其他的master节点 收到投票邀请之后,会将选票交给第一个申请投票的从节点。当某一个从节点获取到选票超过半数,则该从节点成为新的master,如果没有一个从节点获取到超过半数的选票,则纪元+1,重新进行下一轮的选举。
④、设置从节点follow新的master:当一个从节点被设置为master之后,会向集群广播自己已经成为master,接管了原master负责的槽位。其他的从节点则将新的master节点设置为mater。如果已 下线的master重新上线,将原先旧的master设置为从节点。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号