Typescript express 新手教程 S7 MongoDB的聚合介绍
太长不看
- 介绍了木地板提供的聚合操作
聚合
木地板DB提供了 MongoDB aggregation framework,想象一个数据处理管线,Document进入一个多段管道并被处理为 聚合 后的复合数据。
因为单纯从某一个库获取的信息是相对完整 且单一的,大多数情况下业务会要求获取的数据:
- 只包含一个库中的数据的一步分信息
- 或者是从一个库关联到多个库后拼装在一起的复合数据
在木地板数据库中,这些数据的处理和计算(获取)可以通过聚合来完成。
因为这个过程在一个多段管道中完成,那么通过传入一个数组给aggregate函数来达到“多段”的目的,该数组的每一个元素都是一个对象,对象的名字就是在该段管道需要进行的操作的名字(只能是木地板支持的操作)。
const arrayOfJohns = await this.user.aggregate(
[
{
$match: {
name: 'John',
},
},
],
);
上面的code 是一个简单示例,其中$match是一个聚合操作,其效果类似find方法(Model上的方法),如果$match后还有其他聚合操作,那么$match的结果会被输送到下一个聚合操作。
这就是 多段 数据管道的概念解释。
$group
group 接受一个字段_id和一个表达式,_id必填,根据_id的表达式来进行group分组,_id字段的值是这个表达式,
这个过程给会给每个(分出来的)组都创建一条document,
而该聚合功能(group)是基于_id(的值,也就是配置表达式)来进行分组操作的,
如果只关注必须传入_id,看上去让人摸不着头脑,类似于生硬的告诉coder,"_id 是一个 分组的默认字段",但是实际上,它就是一个identification,
传入_id的表达式就是分组操作的 “条件”。
# 更新后的 userDto
import { IsOptional, IsString, ValidateNested } from 'class-validator';
import CreateAddressDto from './address.dto';
class CreateUserDto {
@IsString()
public firstName: string;
@IsString()
public lastName: string;
@IsString()
public email: string;
@IsString()
public password: string;
@IsOptional()
@ValidateNested()
public address?: CreateAddressDto;
}
export default CreateUserDto;
# ReportController
import * as express from 'express';
import Controller from '../interfaces/controller.interface';
import userModel from '../user/user.model';
class ReportController implements Controller {
public path = '/report';
public router = express.Router();
private user = userModel;
constructor() {
this.initializeRoutes();
}
private initializeRoutes() {
this.router.get(`${this.path}`, this.generateReport);
}
private generateReport = async (request: express.Request, response: express.Response, next: express.NextFunction) => {
const usersByCountries = await this.user.aggregate(
[
{
$group: {
_id: {
country: '$address.country',
},
},
},
]
);
response.send({
usersByCountries
});
}
}
export default ReportController;
上述聚合操作:
- 假设有n个user,最多有n个不同的user.address,那么group后创建document,就会有n组,group结果里每组的默认字段都肯定是_id,因为每组都是一个doc,就有n个doc
- country表达是的意思更明显,在创建后的doc中,每个doc的_id字段的值都是一个包含country的BSON,country的值为 user.address.country
- 除了_id还可以加入更多配置,相对应的聚合结果就更丰富
- 当然_id中也可加入更多配置,相应的结果也更丰富
- $用于告诉木地板,你需要access 原始doc (user)
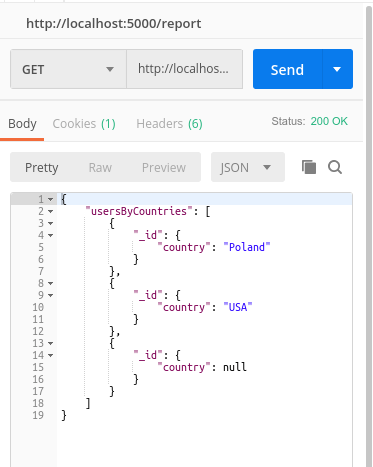
上面的group结果有两个问题
其中一个是有的用户没有country ,结果是null,下面介绍另一个操作$match,同时介绍如何使用多个stage
组合多个stage 完成多阶段聚合操作
前文讲过,通过把多段聚合操作传入一个数组来完成多段聚合,下面code就是实现细节,顺便说一下,user的 address 是一个嵌入形式的引用
const usersByCountries = await this.user.aggregate(
[
{
$match: {
'address.country': {
$exists: true,
},
},
},
{
$group: {
_id: {
country: '$address.country',
},
},
},
]
);
- 首先通过 操作符$exist来进行 address.country是否存在的判断,这一步在group前完成,去掉了不必要的数据
- $match 也是一个聚合操作,接受一个表达式并进行 匹配
上一节的group的第二个问题是聚合后结果没有其他数据,只有一个country,实际上除了传入_id,还可以传入其他配置,这就需要
accumulator operator。
举个简单例子 $sum,可以返回数值类的数据的和,比如可以计算某个country中的 user的和
const usersByCountries = await this.user.aggregate(
[
{
$match: {
'address.country': {
$exists: true,
},
},
},
{
$group: {
_id: {
country: '$address.country',
},
count: {
$sum: 1,
}
},
},
]
);
$sum 对一次group后得出的每一个doc 进行运算(也就是遍历group后的所有doc,当然这是和group同步进行的,而不是会遍历两次),
上面需要获取的是一个group里的user的个数,所以对每一个user,就+1到result。
再比如,假设user中有一个 age字段,$sum:'$age' 就能把所有用户的 age累加并给出结果。
// 把$sum想象成每一个分组独立的加法寄存器
配合$sum,还有一个$push,这个操作符可以把group后的值以数组形式返回,还是用user举例
const usersByCountries = await this.user.aggregate(
[
{
$match: {
'address.country': {
$exists: true,
},
},
},
{
$group: {
_id: {
country: '$address.country',
},
users: {
$push: {
name: '$name',
_id: '$_id',
},
},
count: {
$sum: 1,
}
},
},
]
);
结果如图:
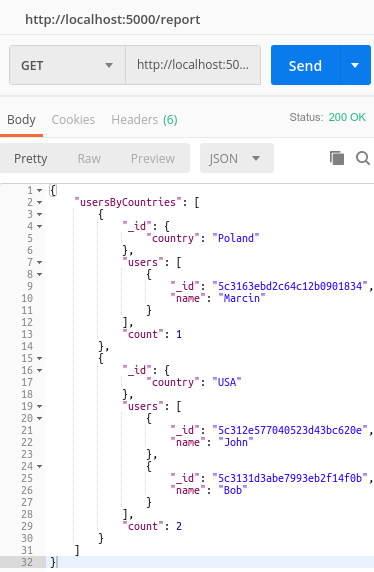
$push中需要传入的字段会在最终结果中出现,这里的$_id是一个经验之谈,因为可以用于其他阶段的聚合。
$lookup
$lookup还是一个聚合操作,这个阶段特别类似sql的join,也就是从表A的某个字段查表B,然后拼接结果。之前说过的populate,也很类似join。
还以user举例,前面的group操作获取了 users,里边有(着意加入的)_id,那么就可以用这个包含很多_id的数组去lookup 整个user表(木地板 3.3.4以后,可以直接在array上进行该操作)
const usersByCountries = await this.user.aggregate(
[
{
$match: {
'address.country': {
$exists: true,
},
},
},
{
$group: {
_id: {
country: '$address.country',
},
users: {
$push: {
_id: '$_id',
},
},
count: {
$sum: 1,
}
},
},
{
$lookup: {
from: 'users',
localField: 'users._id',
foreignField: '_id',
as: 'users',
}
}
]
);
语法解释如下:
- from:这个步骤接受的collection(也就是要执行join的数据集合)
- localField:当前表中的哪个字段是用于和from中配置的表join的? 找的字段在本表中是什么
- foreignField: 是from里配置的表中要join的字段 。找的字段在"from"那个表里边是什么?
- as:join后的结果的 键
from: it specifies the collection in the database to perform the join with
localField: it is the field from our existing document that we want to look for in the collection
foreignField: it is a field in the collection specified in the “from” collection
as: the name of the property holding the result. If there are multiple results, it is an array.
{
$lookup:
{
from: <collection to join>,
localField: <field from the input documents>,
foreignField: <field from the documents of the "from" collection>,
as: <output array field>
}
}
上面的code中
- 首先去除了user中没填写country的用户
- 然后对用户按照country:$address.country来进行分组
- 分组同时在每一组里维护一个users,users的内容是该组内的user的_id,而且每组还维护了user的总和
- 分组后,用users_id去users找 _id字段 ,结果以users显示
注意,lookup很慢,一般不做,上面操作可以用$push替代。
再举个例子,比如要获取某个特定country的 user发的帖子
{
$lookup: {
from: 'posts',
localField: 'users._id',
foreignField: 'author',
as: 'articles',
}
}
- 从posts中找
- 用users._id字段
- 找posts中的 author字段
- 找的结果是articles
上面的聚合 在分组里加入了一个 articles字段,值就是用users数组的_id去post找的结果
{
"_id": {
"country": "Poland"
},
"users": [
{
"_id": "5c3163ebd2c64c12b0901834",
"name": "Marcin"
}
],
"count": 1,
"articles": [
{
"_id": "5c3215545ed1b14df7468ed3",
"title": "Lorem ipsum",
"content": "Dolor sit amet",
"author": "5c3163ebd2c64c12b0901834",
"__v": 0
}
]
}
$addFields 和 $sort
$sort,顾名思义,就是按照一定顺序排序
{
$group: {
_id: {
country: '$address.country',
},
users: {
$push: {
_id: '$_id',
name: '$name',
},
},
count: {
$sum: 1,
},
},
},
{
$sort: {
count: 1,
},
}
count:1 就是升序,count:-1就是降序。注意,这个count是按照前一步分组后的count,
如果想要按照country分组,每组中按照user发表的post的个数来排序,其实还可以用$addField (stage)来完成,这里还要配合$size操作符,
比如下面的code,加入了一个field,维护articles的 长度
const usersByCountries = await this.user.aggregate(
[
{
$match: {
'address.country': {
$exists: true,
},
},
},
{
$group: {
_id: {
country: '$address.country',
},
users: {
$push: {
_id: '$_id',
name: '$name',
},
},
count: {
$sum: 1,
},
},
},
{
$lookup: {
from: 'posts',
localField: 'users._id',
foreignField: 'author',
as: 'articles',
},
},
{
$addFields: {
amountOfArticles: {
$size: '$articles'
},
},
},
{
$sort: {
amountOfArticles: 1,
},
},
],
);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号