模型融合
1.线性加权融合方法
从算法的角度来看,则最常用的是采用加权型的混合推荐技术,即将来自不同推荐算法生成的候选结果及结果的分数,进一步进行组合(Ensemble)加权,生成最终的推荐排序结果。
具体来看,比较原始的加权型的方法是根据推荐效果,固定赋予各个子算法输出结果的权重,然后得到最终结果。很显然这种方法无法灵活处理不同的上下文场景,因为不同的算法的结果,可能在不同的场景下质量有高有低,固定加权系统无法各取所长。所以更好的思路是设置训练样本,然后比较用户对推荐结果的评价、与系统的预测是否相符,根据训练得到的结果生成加权的模型,动态的调整权重。
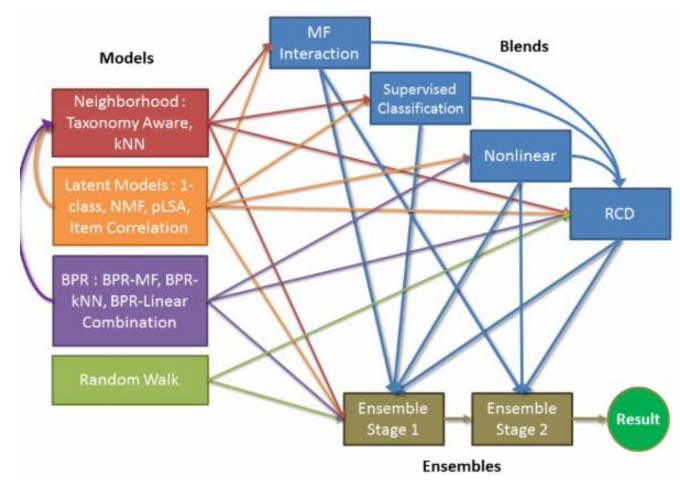
加权混合技术能明显提高推荐精度
加权混合的模型有很多,除了简单的线性模型外,常用的有回归模型(Logistic Regression)、RBM(Restricted Boltzmann Machines)、GBDT(Gradient Boosted Decision Trees),这三种混合模型在推荐算法竞赛中大放异彩,在2009年结束的Netflix百万美元推荐竞赛中,优胜队伍将充分运用和多种加权混合模型的优势,组合后的算法推荐精度非常高。获胜队的Yehuda Koren在论文The BellKor Solution to the Netflix Grand Prize中对此有非常详细的介绍。另外值得一提的是台湾大学推荐团队,他们通过混合甚至二次混合的方式(如上图),将众多单独推荐算法的结果进行最合理的加权组合,在最近几届的KDD Cup数据挖掘竞赛中所向披靡,经常取得极为优异的推荐效果。
实际coding,加权可以参数可以通过线下测试集获得(需要线下与线上数据分布类似)
2.交叉融合法
交叉融合常被称为Blending方法,其思路是在推荐结果中,穿插不同推荐模型的结果,以确保结果的多样性。
这种方式将不同算法的结果组合在一起推荐给用户
交叉融合法的思路是“各花入各眼”,不同算法的结果着眼点不同,能满足不同用户的需求,直接穿插在一起进行展示。这种融合方式适用于同时能够展示较多条结果的推荐场景,并且往往用于算法间区别较大,如分别基于用户长期兴趣和短期兴趣计算获得的结果。
使用blending进行ensemble代码
https://github.com/emanuele/kaggle_pbr/blob/master/blend.py#L57
3.瀑布融合法
瀑布型(Waterfall Model)融合方法采用了将多个模型串联的方法。每个推荐算法被视为一个过滤器,通过将不同粒度的过滤器前后衔接的方法来进行:
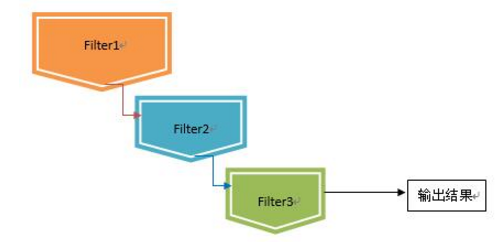
在瀑布型混合技术中,前一个推荐方法过滤的结果,将作为后一个推荐方法的候选集合输入,层层递进,候选结果在此过程中会被逐步遴选,最终得到一个量少质高的结果集合。这样设计通常用于存在大量候选集合的推荐场景上。
设计瀑布型混合系统中,通常会将运算速度快、区分度低的算法排在前列,逐步过渡为重量级的算法,让宝贵的运算资源集中在少量较高候选结果的运算上。在面对候选推荐对象(Item)数量庞大,而可曝光的推荐结果较少,要求精度较高、且运算时间有限的场景下,往往非常适用。
笔者看过天池-移动推荐大赛的最终解决方案,在样本选择时,top 5团队均选择历史用过交互的商品,而非商品全集。这也是一种Filter。
4.多而不同之融合
不同是指参数、特征、样本不同,下面以特征不同为例。
不同的原始数据质量,对推荐计算的结果有很大的影响。以用户兴趣模型为例,我们既可以从用户的实际购买行为中,挖掘出用户的“显式”兴趣,又可以用用户的点击行为中,挖掘用户“隐式”兴趣;另外从用户分类、人口统计学分析中,也可以推测用户偏好;如果有用户的社交网络,那么也可以了解周围用户对该用户兴趣的影响。
所以通过使用不同的数据来源,抽取不同的特征,输入到推荐模型中进行训练,然后将结果合并。这种思路能解决现实中经常遇到的数据缺失的问题,因为并非所有用户都有齐全的各类数据,例如有些用户就缺少交易信息,有些则没有社交关系数据等。通过特征融合的方法能确保模型不挑食,扩大适用面。
5.预测融合法
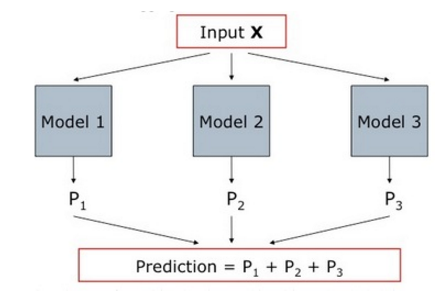
推荐算法也可以被视为一种“预测算法”,即我们为每个用户来预测他接下来最有可能喜欢的商品。而预测融合法的思想是,我们可以对每个预测算法再进行一次预测,即不同的算法的预测结果,我们可以训练第二层的预测算法去再次进行预测,并生成最终的预测结果。
如下图所示,我们把各个推荐算法的预测结果作为特征,将用户对商品的反馈数据作为训练样本,形成了第二层预测模型的训练集合,具体流程如下
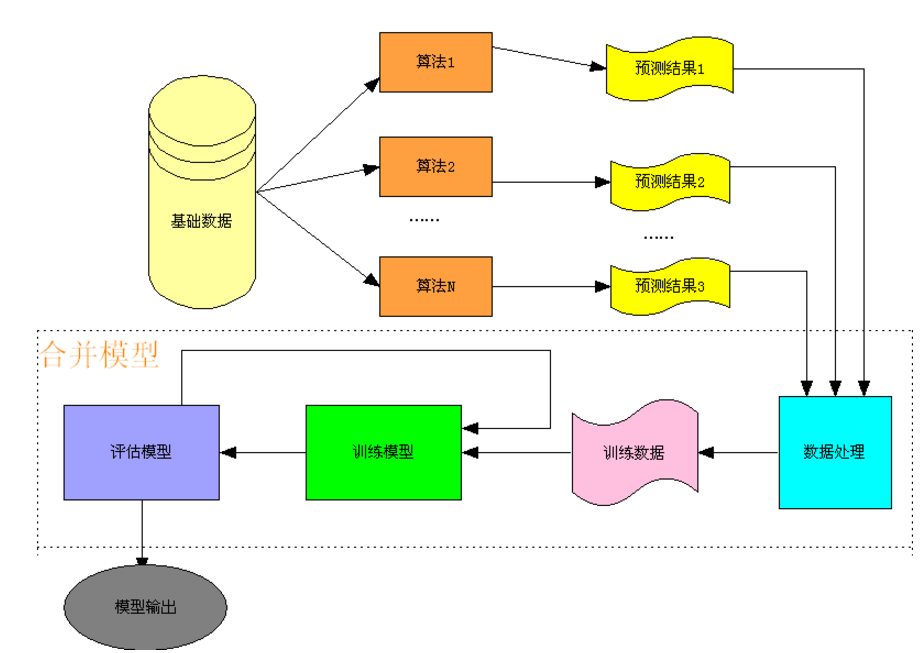
图中的二层预测模型可以使用常用的分类算法,如SVM、随机森林、最大熵等,但达观实践中,融合效果较好的是GBDT(Gradient Boosting Decision Tree)方法。
6.加性融合
一个很赞的idea
非线性的树模型Additive Groves(AG)是一个加性模型,由很多个Grove组成,不同的Grove之间进行bagging得出最后的预测结果,由此可以减小过拟合的影响。
每一个Grove有多棵树组成,在训练时每棵树的拟合目标为真实值与其他树预测结果之和之间的残差。当达到给定数目的树时,重新训练的树会逐棵替代以前的树。经过多次迭代后,达到收敛。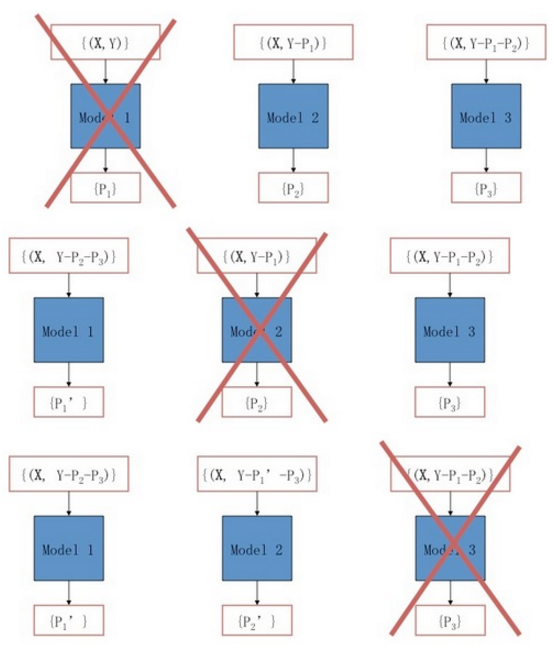
最后,强势安利一波,Kaggle关于ensemble的文档
http://mlwave.com/kaggle-ensembling-guide/
参考文献
(1)http://blog.sina.com.cn/s/blog_5357c0af0102uxof.html
(2)http://www.csdn.net/article/2015-01-30/2823783
转载:http://blog.csdn.net/a819825294 https://blog.csdn.net/a819825294/article/details/51699985

 浙公网安备 33010602011771号
浙公网安备 33010602011771号