Hadoop伪分布式安装
一、Hadoop安装装准备工作
首先主机关闭防火墙
# service iptables stop
# chkconfig iptables off
之后修改主机名,注意Hadoop要求主机名中不能出现横线-或下划线_,修改network文件,完成后source该文件,再修改hosts文件,然后重启系统
# vim /etc/sysconfig/network
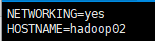
source /etc/sysconfig/network
vim /etc/hosts

二、Hadoop下载安装
本文章以Hadoop-2.10.0版本为例,首先从官网上下载该版本的Hadoop压缩包
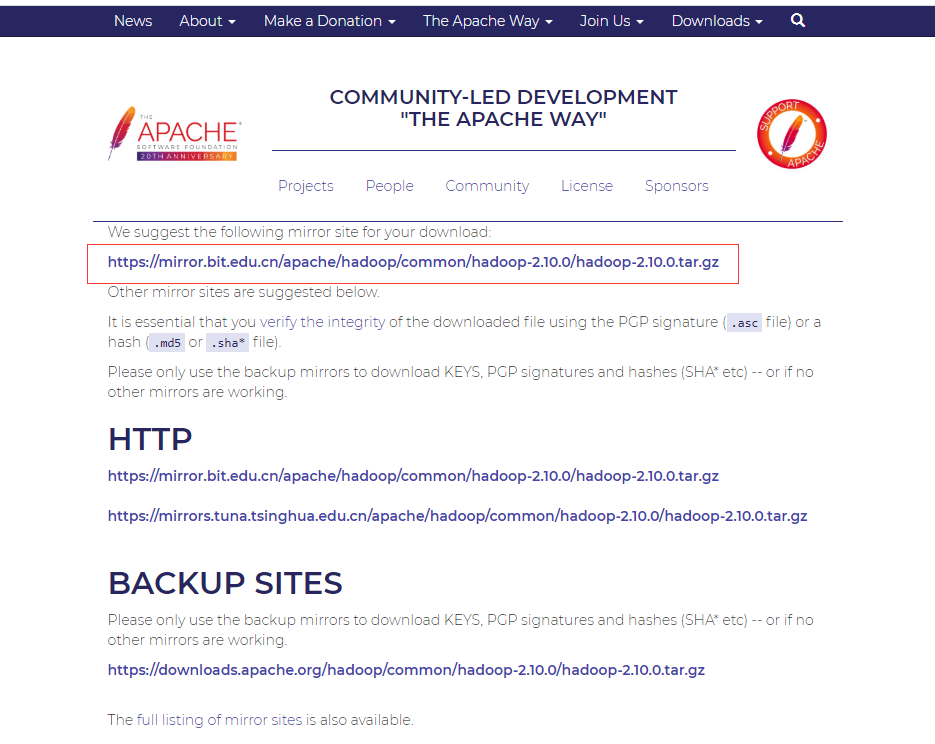
然后上传到云主机或虚拟机,进行解压,完成后切换到/home/software/hadoop-2.10.0.tar.gz/etc/hadoop目录下
# tar -zvxf hadoop-2.10.0.tar.gz
三、修改配置文件
# cd /home/software/hadoop-2.10.0/etc/hadoop
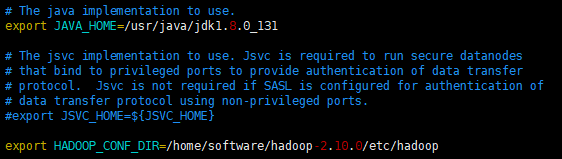
1、编辑配置文件hadoop-env.sh,修改Java_home路径(JDK安装路径)和Hadoop配置文件路径(就是该配置文件所在的路径)
2、编辑配置文件core-site.xml,注意里面的主机名和安装路径按照自己的来配置
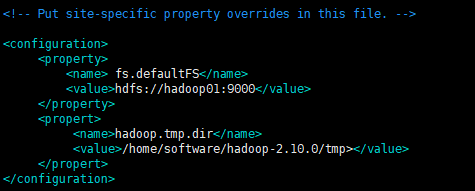
<configuration> <property> <name> fs.defaultFS</name> <value>hdfs://hadoop01:9000</value> </property> <propert> <name>hadoop.tmp.dir</name> <value>/home/software/hadoop-2.10.0/tmp</value> </propert> </configuration>
3、编辑hdfs-site.xml文件
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
4、复制模板文件mapred-site.xml.template,完成后编辑mapred-site.xml
# cp mapred-site.xml.template mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
5、编辑yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop01</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
6、编辑slaves文件,把localhost改为当前主机的主机名即可

7、配置hadoop的环境变量
a. 编辑profile文件:
vim /etc/profile
b. 添加Hadoop的环境变量,例如:
export HADOOP_HOME=/home/software/hadoop-2.10.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
c. 保存退出,重新生效:
source /etc/profile
8、格式化namenode:
hadoop namenode -format
9、启动Hadoop:
start-all.sh
四、注意事项
1、如果Hadoop的配置没有生效,那么需要重启Linux;
2、在格式化的时候,会有这样的输出:Storage directory /tmp/hadoop-root/dfs/name has been successfully,表示格式化成功;
3. Hadoop如果启动成功,会出现5个进程:Namenode,Datanode,Secondarynamenode,ResourceManager,NodeManager;
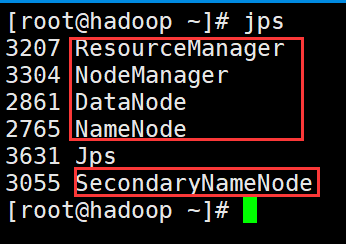
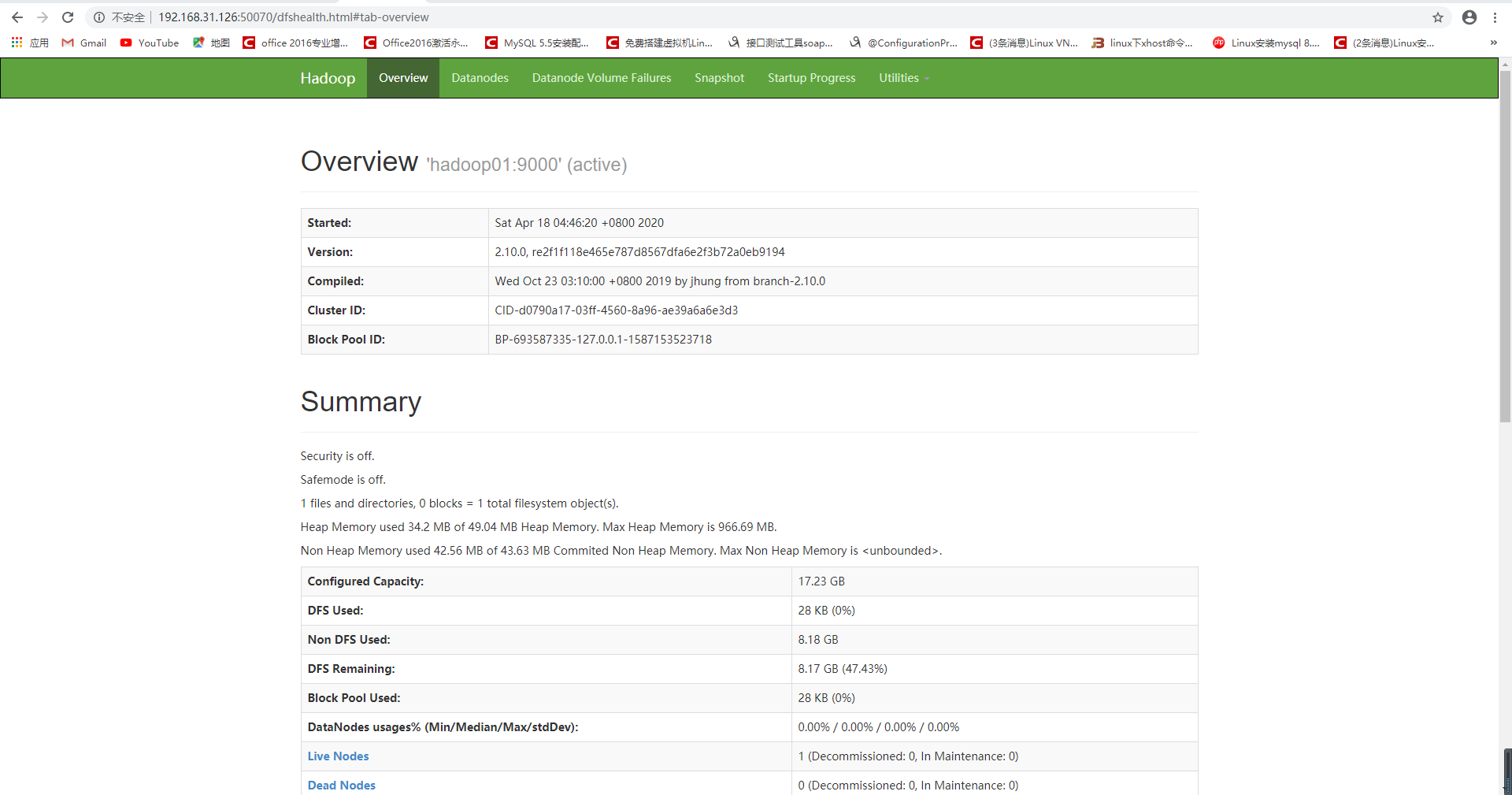
4、Hadoop启动成功后,可以通过浏览器访问HDFS的页面,访问地址为:IP地址:50070
5、Hadoop启动成功后,可以通过浏览器访问Yarn的页面,访问地址为:http://IP地址:8088