Hive之分析函数
一、分析函数的语法
-
语法:
函数名([参数]) over(partition by [分组字段] order by [排序字段] asc/desc rows/range between 起始位置 and 结束位置) -
函数解读:
函数分为两个部分
第一部分是函数名称,开窗函数的数量较少,只有11个窗口函数+聚合函数(所有聚合函数都可以用作开窗函数),根据函数性质,有的要写参数,有的不需要写参数;
第二部分是over语句,over()是必须要写的,里面有三个参数,都是非必须参数,根据需求选写:
1.第一个参数是 partition by +分组字段,将数据根据此字段分成多份,如果不加partition by参数,那会把整个数据当做一个窗口。
2.第二个参数是 order by +排序字段,每个窗口的数据要不要进行排序。
3.第三个参数 rows/range between 起始位置 and 结束位置,这个参数仅针对滑动窗口函数有用,是在当前窗口下分出更小的子窗口。 -
其中起始位置和结束位置可写:
current row 边界是当前行
unbounded preceding 边界是分区中的第一行
unbounded following 边界是分区中的最后一行
expr preceding 边界是当前行减去expr的值
expr following 边界是当前行加上expr的值。rows是基于行数,range是基于值的大小
range是逻辑窗口,是指定当前行对应值的范围取值,列数不固定,只要行值在范围内,对应列都包含在内
rows是物理窗口,即根据order by 子句排序后,取的前N行及后N行的数据计算(与当前行的值无关,只与排序后的行号相关)
如 row 2 preceding,表示取前N行的数据计算,如 range 2 preceding,取前N行与当前行的差值不超过2的数据计算
二、sum() over(partition by)
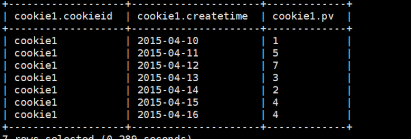
- 数据准备
cookie1,2015-04-10,1
cookie1,2015-04-11,5
cookie1,2015-04-12,7
cookie1,2015-04-13,3
cookie1,2015-04-14,2
cookie1,2015-04-15,4
cookie1,2015-04-16,4
- 查询语句
select
cookieid,
createtime,
pv,
sum(pv) over (partition by cookieid order by createtime rows between unbounded preceding and current row) as pv1,
sum(pv) over (partition by cookieid order by createtime) as pv2,
sum(pv) over (partition by cookieid) as pv3,
sum(pv) over (partition by cookieid order by createtime rows between 3 preceding and current row) as pv4,
sum(pv) over (partition by cookieid order by createtime rows between 3 preceding and 1 following) as pv5,
sum(pv) over (partition by cookieid order by createtime rows between current row and unbounded following) as pv6
from cookie1;
- 查询结果
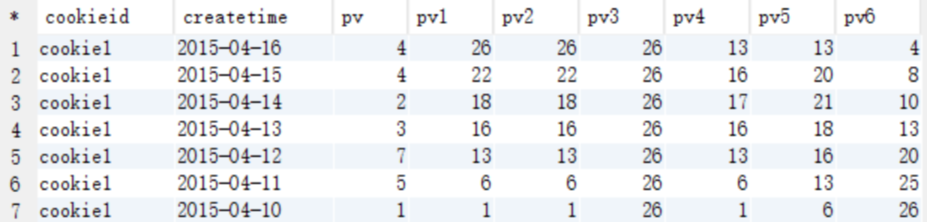
-
查询结果说明
- pv1: 分组内从起点到当前行的pv累积,如,11号的pv1=2015-04-10号的pv + 2015-04-11号的pv, 2015-04-12号=10号+11号+12号
- pv2: 同pv1
- pv3: 分组内(cookie1)所有的pv累加
- pv4: 分组内当前行+往前3行,如,11号=10号+11号, 12号=10号+11号+12号, 13号=10号+11号+12号+13号, 14号=11号+12号+13号+14号
- pv5: 分组内当前行+往前3行+往后1行,如,14号=11号+12号+13号+14号+15号=5+7+3+2+4=21
- pv6: 分组内当前行+往后所有行,如,13号=13号+14号+15号+16号=3+2+4+4=13,14号=14号+15号+16号=2+4+4=10
-
partition by 的参数说明
如果不指定ROWS BETWEEN,默认为从起点到当前行;
如果不指定ORDER BY,则将分组内所有值累加;
关键是理解ROWS BETWEEN含义,也叫做WINDOW子句:
PRECEDING:往前
FOLLOWING:往后
CURRENT ROW:当前行
UNBOUNDED:起点,
UNBOUNDED PRECEDING 表示从前面的起点,
UNBOUNDED FOLLOWING:表示到后面的终点
–其他AVG,MIN,MAX,和SUM用法一样。
三、avg()、min()、max() over(partition)
avg()、min()、max() over(partition) 与 sum() over(partition) 类似,都是对窗口做操作
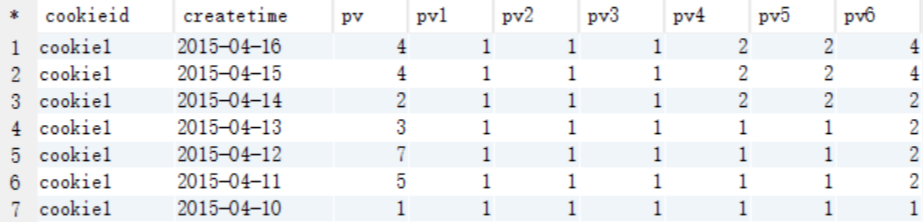
- min() over(partition) 的查询语句
select
cookieid,
createtime,
pv,
min(pv) over (partition by cookieid order by createtime rows between unbounded preceding and current row) as pv1, -- 默认为从起点到当前行
min(pv) over (partition by cookieid order by createtime) as pv2, --从起点到当前行,结果同pv1
min(pv) over (partition by cookieid) as pv3, --分组内所有行
min(pv) over (partition by cookieid order by createtime rows between 3 preceding and current row) as pv4, --当前行+往前3行
min(pv) over (partition by cookieid order by createtime rows between 3 preceding and 1 following) as pv5, --当前行+往前3行+往后1行
min(pv) over (partition by cookieid order by createtime rows between current row and unbounded following) as pv6 --当前行+往后所有行
from cookie1;
- 结果展示
四、row_number() over(partition by)
row_number()从1开始,为每一条分组记录返回一个数字
row_number() OVER (ORDER BY id DESC) 是先把id列降序,再为降序以后的每条id记录返回一个序号。
row_number() OVER (PARTITION BY COL1 ORDER BY COL2) 表示根据COL1分组,在分组内部根据 COL2排序,而此函数计算的值就表示每组内部排序后的顺序编号(组内连续的唯一的)
- 数据准备
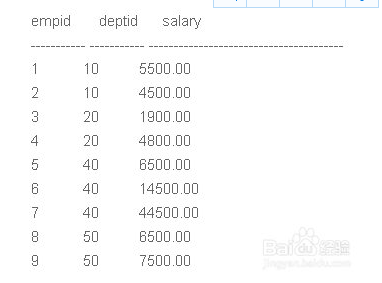
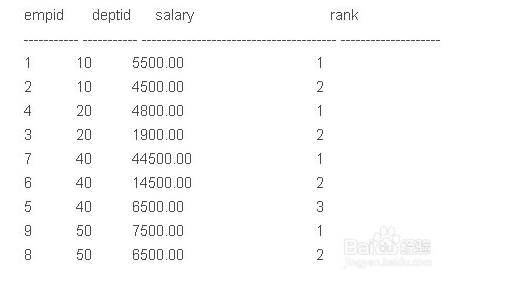
- 查询:需根据部门分组,显示每个部门的工资等级
SELECT *, Row_Number() OVER (partition by deptid ORDER BY salary desc) rank FROM employee
五、用over(partition by) 还是 group by
-
总结区别:over(partition by) 和 group by的区别
- group by:单纯分组,要查询非group by字段时需要用 collect_set()[0]处理,或者子查询处理
- over(partition by):不仅能分组,还能同时查询非分区字段,不仅可以使用sum()、avg()、min()、max()等功能,还可以使用row_number() 对数据进行排名功能
-
group by
在hive中使用group by时,是不能select 非group by 字段的。
select name,sex from people group by sex;
---------------------------------------------------
会报错:
FAILED: SemanticException [Error 10025]: Line 1:15 Expression not in GROUP BY key 'name'
解决这个问题的方式有很多:在子查询中做group by然后用left join 连接,在外层selec。还有就是用collect_set()包围这个非group by字段
select collect_set(name)[0],sex from people group by sex;
- over(partition by)
当然,用over(partition by)也能解决分组问题,在分组的同时会对相同key的进行回填处理
数据准备
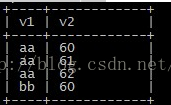
查询语句
select v1,v2,sum(v2) over(partition by v1) as sum from wmg_test;
结果展示
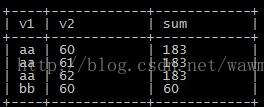
所以要做到取一条分组数据,就在外层去重
select distinct v1,sum_01
from (
select v1,sum(v2) over(partition by v1) as sum_01
from wmg_test
) a;
结果展示


