Elasticsearch学习笔记
一、概述
1、什么是搜索
百度:我们比如说想找寻任何的信息的时候,就会上百度去搜索一下,比如说找一部自己喜欢的电影,或者说找一本喜欢的书,或者找一条感兴趣的新闻(提到搜索的第一印象)。百度 != 搜索
1)互联网的搜索:电商网站,招聘网站,新闻网站,各种app
2)IT系统的搜索:OA软件,办公自动化软件,会议管理,日程管理,项目管理。
搜索,就是在任何场景下,找寻你想要的信息,这个时候,会输入一段你要搜索的关键字,然后就期望找到这个关键字相关的有些信息
2、用数据库做搜索

用数据库来实现搜索,是不太靠谱的。通常来说,性能会很差的。
3、全文检索和Lucene
1)全文检索,倒排索引
全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。全文搜索引擎数据库中的数据。
- 倒排索引
传统数据库存储:
| id | 描述 |
|---|---|
| 1 | 优秀员工 |
| 2 | 销售冠军 |
| 3 | 优秀团队领导 |
| 4 | 优秀项目 |
倒排索引处理步骤:
1、切词:
优秀员工 —— 优秀 员工
销售冠军 —— 销售 冠军
优秀团队领导 —— 优秀 团队 领导
优秀项目 —— 优秀 项目
2、建立倒排索引:
关键词 id
| 关键词 | id |
|---|---|
| 优秀 | 1,3,4 |
| 员工 | 1 |
| 销售 | 2 |
| 团队 | 3 |
| 。。。 | 。。。 |

2)lucene,就是一个jar包,里面包含了封装好的各种建立倒排索引,以及进行搜索的代码,包括各种算法。我们就用java开发的时候,引入lucene jar,然后基于lucene的api进行去进行开发就可以了。
4、什么是Elasticsearch
Elasticsearch,基于lucene,隐藏复杂性,提供简单易用的restful api接口、java api接口(还有其他语言的api接口)。
关于elasticsearch的一个传说,有一个程序员失业了,陪着自己老婆去英国伦敦学习厨师课程。程序员在失业期间想给老婆写一个菜谱搜索引擎,觉得lucene实在太复杂了,就开发了一个封装了lucene的开源项目,compass。后来程序员找到了工作,是做分布式的高性能项目的,觉得compass不够,就写了elasticsearch,让lucene变成分布式的系统。
Elasticsearch是一个实时分布式搜索和分析引擎。它用于全文搜索、结构化搜索、分析。
全文检索:将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。
结构化检索:我想搜索商品分类为日化用品的商品都有哪些,select * from products where category_id='日化用品'。
数据分析:电商网站,最近7天牙膏这种商品销量排名前10的商家有哪些;新闻网站,最近1个月访问量排名前3的新闻版块是哪些。
5、Elasticsearch适用场景
1)维基百科,类似百度百科,牙膏,牙膏的维基百科,全文检索,高亮,搜索推荐。
2)The Guardian(国外新闻网站),类似搜狐新闻,用户行为日志(点击,浏览,收藏,评论)+ 社交网络数据(对某某新闻的相关看法),数据分析,给到每篇新闻文章的作者,让他知道他的文章的公众反馈(好,坏,热门,垃圾,鄙视,崇拜)。
3)Stack Overflow(国外的程序异常讨论论坛),IT问题,程序的报错,提交上去,有人会跟你讨论和回答,全文检索,搜索相关问题和答案,程序报错了,就会将报错信息粘贴到里面去,搜索有没有对应的答案。
4)GitHub(开源代码管理),搜索上千亿行代码。
5)国内:站内搜索(电商,招聘,门户,等等),IT系统搜索(OA,CRM,ERP,等等),数据分析(ES热门的一个使用场景)。
6、Elasticsearch特点
1)可以作为一个大型分布式集群(数百台服务器)技术,处理PB级数据,服务大公司;也可以运行在单机上,服务小公司;树莓派
2)Elasticsearch不是什么新技术,主要是将全文检索、数据分析以及分布式技术,合并在了一起,才形成了独一无二的ES;lucene(全文检索),商用的数据分析软件(也是有的),分布式数据库(mycat);
3)对用户而言,是开箱即用的,非常简单,作为中小型的应用,直接3分钟部署一下ES,就可以作为生产环境的系统来使用了,数据量不大,操作不是太复杂;
4)数据库的功能面对很多领域是不够用的(事务,还有各种联机事务型的操作);特殊的功能,比如全文检索,同义词处理,相关度排名,复杂数据分析,海量数据的近实时处理;Elasticsearch作为传统数据库的一个补充,提供了数据库所不能提供的很多功能。
7、Elasticsearch核心概念
- 近实时
近实时,两个意思,从写入数据到数据可以被搜索到有一个小延迟(大概1秒);基于es执行搜索和分析可以达到秒级。
- Cluster(集群)
集群包含多个节点,每个节点属于哪个集群是通过一个配置(集群名称,默认是elasticsearch)来决定的,对于中小型应用来说,刚开始一个集群就一个节点很正常。
- Node(节点)
集群中的一个节点,节点也有一个名称(默认是随机分配的),节点名称很重要(在执行运维管理操作的时候),默认节点会去加入一个名称为“elasticsearch”的集群,如果直接启动一堆节点,那么它们会自动组成一个elasticsearch集群,当然一个节点也可以组成一个elasticsearch集群。
- Index(索引-数据库)
索引包含一堆有相似结构的文档数据,比如可以有一个客户索引,商品分类索引,订单索引,索引有一个名称。一个index包含很多document,一个index就代表了一类类似的或者相同的document。比如说建立一个product index,商品索引,里面可能就存放了所有的商品数据,所有的商品document。
- Type(类型-表)
每个索引里都可以有一个或多个type,type是index中的一个逻辑数据分类,一个type下的document,都有相同的field,比如博客系统,有一个索引,可以定义用户数据type,博客数据type,评论数据type。
商品index,里面存放了所有的商品数据,商品document
但是商品分很多种类,每个种类的document的field可能不太一样,比如说电器商品,可能还包含一些诸如售后时间 范围这样的特殊field;生鲜商品,还包含一些诸如生鲜保质期之类的特殊field
type,日化商品type,电器商品type,生鲜商品type
日化商品type:product_id,product_name,product_desc,category_id,category_name
电器商品type:product_id,product_name,product_desc,category_id,category_name,service_period
生鲜商品type:product_id,product_name,product_desc,category_id,category_name,eat_period
每一个type里面,都会包含一堆document
{
"product_id": "1",
"product_name": "长虹电视机",
"product_desc": "4k高清",
"category_id": "3",
"category_name": "电器",
"service_period": "1年"
}
{
"product_id": "2",
"product_name": "基围虾",
"product_desc": "纯天然,冰岛产",
"category_id": "4",
"category_name": "生鲜",
"eat_period": "7天"
}
- Document(文档-行)
文档是es中的最小数据单元,一个document可以是一条客户数据,一条商品分类数据,一条订单数据,通常用JSON数据结构表示,每个index下的type中,都可以去存储多个document。
- Field(字段-列)
Field是Elasticsearch的最小单位。一个document里面有多个field,每个field就是一个数据字段。
product document
{
"product_id": "1",
"product_name": "高露洁牙膏",
"product_desc": "高效美白",
"category_id": "2",
"category_name": "日化用品"
}
- mapping(映射-约束)
数据如何存放到索引对象上,需要有一个映射配置,包括:数据类型、是否存储、是否分词等。
这样就创建了一个名为blog的Index。Type不用单独创建,在创建Mapping 时指定就可以。Mapping用来定义Document中每个字段的类型,即所使用的 analyzer、是否索引等属性,非常关键等。创建Mapping 的代码示例如下:
client.indices.putMapping({
index : 'blog',
type : 'article',
body : {
article: {
properties: {
id: {
type: 'string',
analyzer: 'ik',
store: 'yes',
},
title: {
type: 'string',
analyzer: 'ik',
store: 'no',
},
content: {
type: 'string',
analyzer: 'ik',
store: 'yes',
}
}
}
}
});
- elasticsearch与数据库的类比
| 关系型数据库(比如Mysql) | 非关系型数据库(Elasticsearch) |
|---|---|
| 数据库Database | 索引Index |
| 表Table | 类型Type |
| 数据行Row | 文档Document |
| 数据列Column | 字段Field |
| 约束 Schema | 映射Mapping |
- ES存入数据和搜索数据机制

1)索引对象(index):存储数据的表结构 ,任何搜索数据,存放在索引对象上 。
2)映射(mapping):数据如何存放到索引对象上,需要有一个映射配置, 包括:数据类型、是否存储、是否分词等。
3)文档(document):一条数据记录,存在索引对象上 。
4)文档类型(type):一个索引对象,存放多种类型数据,数据用文档类型进行标识。
二 快速入门
单机版;head插件安装;集群搭建。
1、安装包下载
- 1)Elasticsearch官网: https://www.elastic.co/products/elasticsearch

2、安装Elasticsearch(单节点Linux环境)
- 1)解压elasticsearch-5.6.1.tar.gz到/opt/module目录下
[itstar@hadoop102 software]$ tar -zxvf elasticsearch-5.6.1.tar.gz -C /opt/module/
- 2)在/opt/module/elasticsearch-5.6.1路径下创建data和logs文件夹
[itstar@hadoop102 elasticsearch-5.6.1]$ mkdir data
[itstar@hadoop102 elasticsearch-5.6.1]$ mkdir logs
- 3)修改配置文件/opt/module/elasticsearch-5.2.2/config/elasticsearch.yml
[itstar@hadoop102 config]$ pwd
/opt/module/elasticsearch-5.6.1/config
[itstar@hadoop102 config]$ vi elasticsearch.yml
# ---------------------------------- Cluster -------------------------------------
cluster.name: my-application
# ------------------------------------ Node --------------------------------------
node.name: node-102
# ----------------------------------- Paths ---------------------------------------
path.data: /opt/module/elasticsearch-5.6.1/data
path.logs: /opt/module/elasticsearch-5.6.1/logs
# ----------------------------------- Memory -----------------------------------
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
# ---------------------------------- Network ------------------------------------
network.host: 192.168.1.102
# --------------------------------- Discovery ------------------------------------
discovery.zen.ping.unicast.hosts: ["hadoop102"]
(1)cluster.name
如果要配置集群需要两个节点上的elasticsearch配置的cluster.name相同,都启动可以自动组成集群,这里如果不改cluster.name则默认是cluster.name=my-application,
(2)nodename随意取但是集群内的各节点不能相同
(3)修改后的每行前面不能有空格,修改后的“:”后面必须有一个空格
- 4)配置linux系统环境(参考:http://blog.csdn.net/satiling/article/details/59697916)
(1)编辑limits.conf 添加类似如下内容
[itstar@hadoop102 elasticsearch-5.6.1]$ sudo vi /etc/security/limits.conf
添加如下内容:
* soft nofile 65536
* hard nofile 131072
* soft nproc 4096
* hard nproc 4096
(2)进入limits.d目录下修改配置文件。
[itstar@hadoop102 elasticsearch-5.6.1]$ sudo vi /etc/security/limits.d/90-nproc.conf
修改如下内容:
* soft nproc 1024
#修改为
* soft nproc 4096
(3)修改配置sysctl.conf
[itstar@hadoop102 elasticsearch-5.6.1]$ sudo vi /etc/sysctl.conf
添加下面配置:
vm.max_map_count=655360
并执行命令:
[itstar@hadoop102 elasticsearch-5.6.1]$ sudo sysctl -p
然后,重新启动elasticsearch,即可启动成功。
- 5)启动elasticsearch
[itstar@hadoop105 elasticsearch-5.6.1]$ bin/elasticsearch
- 6)测试elasticsearch
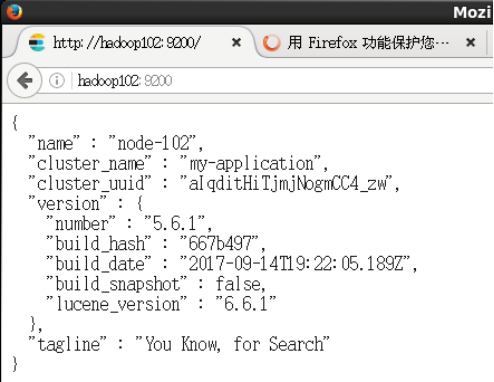
[itstar@hadoop102 elasticsearch-5.6.1]$ curl http://hadoop102:9200
curl -XGET 'localhost:9200/_cat/health?v&pretty'
{
"name" : "node-102",
"cluster_name" : "my-application",
"cluster_uuid" : "znZfW5tGQou9rKzb6pG6vA",
"version" : {
"number" : "5.6.1",
"build_hash" : "667b497",
"build_date" : "2017-09-14T19:22:05.189Z",
"build_snapshot" : false,
"lucene_version" : "6.6.1"
},
"tagline" : "You Know, for Search"
}
- 7)安装elasticsearch-head.crx插件
第一种安装方法:
(1)Google浏览器:打开浏览器,进入“更多工具”——>“扩展程序”,将插件拖入即可完成安装
(2)360浏览器:打开浏览器,双击elasticsearch-head.crx插件即可完成安装
(3)使用插件查看节点状态

第二种安装方法:
下载插件:https://github.com/mobz/elasticsearch-head
nodejs官网下载安装包:https://nodejs.org/dist/
node-v6.9.2-linux-x64.tar.xz
拷贝
安装nodejs:
解压
配置环境变量:
export NODE_HOME=/usr/local/node-v6.9.2-linux-x64 export PATH=$PATH:$NODE_HOME/bin
查看node和npm版本:
node -v
npm -v
解压head插件到/opt/module目录下:
unzip elasticsearch-head-master.zip
查看当前head插件目录下有无node_modules/grunt目录:
没有:执行命令创建:
npm install grunt --save --registry=https://registry.npm.taobao.org
安装head插件:
npm install -g cnpm --registry=https://registry.npm.taobao.org
安装grunt:
npm install -g grunt-cli --registry=https://registry.npm.taobao.org
编辑Gruntfile.js
vim Gruntfile.js
文件93行添加
hostname:'0.0.0.0'
检查head根目录下是否存在base文件夹
没有:将 _site下的base文件夹及其内容复制到head根目录下
mkdir base
cp base/* ../base/
启动grunt server:
grunt server -d
如果提示grunt的模块没有安装:
Local Npm module “grunt-contrib-clean” not found. Is it installed?
Local Npm module “grunt-contrib-concat” not found. Is it installed?
Local Npm module “grunt-contrib-watch” not found. Is it installed?
Local Npm module “grunt-contrib-connect” not found. Is it installed?
Local Npm module “grunt-contrib-copy” not found. Is it installed?
Local Npm module “grunt-contrib-jasmine” not found. Is it installed?
执行以下命令:
npm install grunt-contrib-clean -registry=https://registry.npm.taobao.org
npm install grunt-contrib-concat -registry=https://registry.npm.taobao.org
npm install grunt-contrib-watch -registry=https://registry.npm.taobao.org
npm install grunt-contrib-connect -registry=https://registry.npm.taobao.org
npm install grunt-contrib-copy -registry=https://registry.npm.taobao.org
npm install grunt-contrib-jasmine -registry=https://registry.npm.taobao.org
最后一个模块可能安装不成功,但是不影响使用。
浏览器访问head插件:
http://192.168.109.133:9100
- 8)停止集群
kill -9 进程号
3、安装Elasticsearch(多节点集群Linux环境)
- 1)分发Elasticsearch安装包至hadoop103和hadoop104
[itstar@hadoop102 module]$ xsync elasticsearch-5.6.1/
- 2)修改hadoop102配置信息
[itstar@hadoop102 config]$ vi elasticsearch.yml
添加如下信息:
node.master: true
node.data: true
- 3)修改hadoop103配置信息
(1)修改Elasticsearch配置信息
[itstar@hadoop103 config]$ vi elasticsearch.yml
node.name: node-103
node.master: false
node.data: true
network.host: 192.168.1.103
(2)修改Linux相关配置信息(同hadoop102)
- 4)修改hadoop104配置信息
(1)修改Elasticsearch配置信息
[itstar@hadoop104 config]$ vi elasticsearch.yml
node.name: node-104
node.master: false
node.data: true
network.host: 192.168.1.104
(2)修改Linux相关配置信息(同hadoop102)
-
5)分别启动三台节点的Elasticsearch
-
6)使用插件查看集群状态
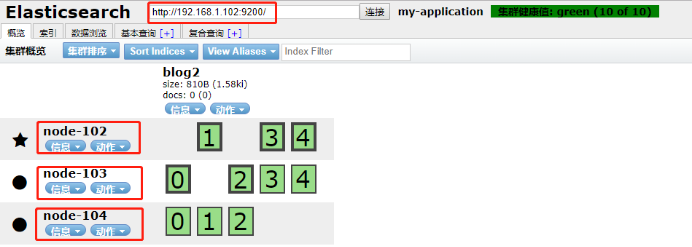
三 Java API操作
1、API基本操作
1、操作环境准备
- 1)创建maven工程
- 2)添加pom文件
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>5.6.1</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>5.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.9.0</version>
</dependency>
</dependencies>
- 3)等待依赖的jar包下载完成
当直接在ElasticSearch 建立文档对象时,如果索引不存在的,默认会自动创建,映射采用默认方式
2、获取Transport Client
(1)ElasticSearch服务默认端口9300。
(2)Web管理平台端口9200。
//org.elasticsearch.transport.client.PreBuiltTransportClient@4bff2185
//org.elasticsearch.transport.client.PreBuiltTransportClient@6f099cef
private TransportClient client;
@SuppressWarnings("unchecked")
@Before
public void getClient() throws Exception {
// 1 设置连接的集群名称
Settings settings = Settings.builder().put("cluster.name", "my-application").build();
// 2 连接集群
client = new PreBuiltTransportClient(settings);
client.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("hadoop102"), 9300));
// 3 打印集群名称
System.out.println(client.toString());
}
(3)显示log4j2报错,在resource目录下创建一个文件命名为log4j2.xml并添加如下内容
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="warn">
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%m%n"/>
</Console>
</Appenders>
<Loggers>
<Root level="INFO">
<AppenderRef ref="Console"/>
</Root>
</Loggers>
</Configuration>
3、创建索引
- 1)源代码
@Test
public void createIndex_blog(){
// 1 创建索引
client.admin().indices().prepareCreate("blog2").get();
// 2 关闭连接
client.close();
}
- 2)查看结果
{"blog2":{"aliases":{},"mappings":{},"settings":{"index":{"creation_date":"1507466730030","number_of_shards":"5","number_of_replicas":"1","uuid":"lec0xYiBSmStspGVa6c80Q","version":{"created":"5060299"},"provided_name":"blog2"}}}}
4、删除索引
- 1)源代码
@Test
public void deleteIndex(){
// 1 删除索引
client.admin().indices().prepareDelete("blog2").get();
// 2 关闭连接
client.close();
}
- 2)查看结果
浏览器查看http://hadoop102:9200/blog2
没有blog2索引了。
{"error":{"root_cause":[{"type":"index_not_found_exception","reason":"no such index","resource.type":"index_or_alias","resource.id":"blog2","index_uuid":"_na_","index":"blog2"}],"type":"index_not_found_exception","reason":"no such index","resource.type":"index_or_alias","resource.id":"blog2","index_uuid":"_na_","index":"blog2"},"status":404}
5、新建文档(源数据json串)
当直接在ElasticSearch建立文档对象时,如果索引不存在的,默认会自动创建,映射采用默认方式。
- 1)源代码
@Test
public void createIndexByJson() throws UnknownHostException {
// 1 文档数据准备
String json = "{" + "\"id\":\"1\"," + "\"title\":\"基于Lucene的搜索服务器\","
+ "\"content\":\"它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口\"" + "}";
// 2 创建文档
IndexResponse indexResponse = client.prepareIndex("blog", "article", "1").setSource(json).execute().actionGet();
// 3 打印返回的结果
System.out.println("index:" + indexResponse.getIndex());
System.out.println("type:" + indexResponse.getType());
System.out.println("id:" + indexResponse.getId());
System.out.println("version:" + indexResponse.getVersion());
System.out.println("result:" + indexResponse.getResult());
// 4 关闭连接
client.close();
}
- 2)结果查看

6、新建文档(源数据map方式添加json)
- 1)源代码
@Test
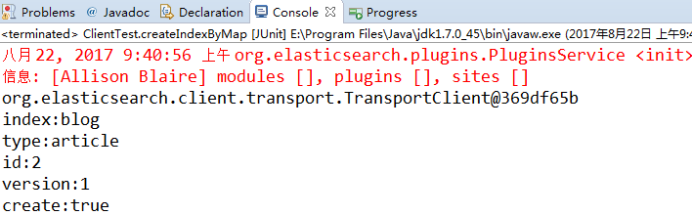
public void createIndexByMap() {
// 1 文档数据准备
Map<String, Object> json = new HashMap<String, Object>();
json.put("id", "2");
json.put("title", "基于Lucene的搜索服务器");
json.put("content", "它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口");
// 2 创建文档
IndexResponse indexResponse = client.prepareIndex("blog", "article", "2").setSource(json).execute().actionGet();
// 3 打印返回的结果
System.out.println("index:" + indexResponse.getIndex());
System.out.println("type:" + indexResponse.getType());
System.out.println("id:" + indexResponse.getId());
System.out.println("version:" + indexResponse.getVersion());
System.out.println("result:" + indexResponse.getResult());
// 4 关闭连接
client.close();
}
- 2)结果查看
7、新建文档(源数据es构建器添加json)
- 1)源代码
@Test
public void createIndex() throws Exception {
// 1 通过es自带的帮助类,构建json数据
XContentBuilder builder = XContentFactory.jsonBuilder().startObject().field("id", 3).field("title", "基于Lucene的搜索服务器").field("content", "它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。")
.endObject();
// 2 创建文档
IndexResponse indexResponse = client.prepareIndex("blog", "article", "3").setSource(builder).get();
// 3 打印返回的结果
System.out.println("index:" + indexResponse.getIndex());
System.out.println("type:" + indexResponse.getType());
System.out.println("id:" + indexResponse.getId());
System.out.println("version:" + indexResponse.getVersion());
System.out.println("result:" + indexResponse.getResult());
// 4 关闭连接
client.close();
}
- 2)结果查看

8、搜索文档数据(单个索引)
- 1)源代码
@Test
public void getData() throws Exception {
// 1 查询文档
GetResponse response = client.prepareGet("blog", "article", "1").get();
// 2 打印搜索的结果
System.out.println(response.getSourceAsString());
// 3 关闭连接
client.close();
}
- 2)结果查看

9、搜索文档数据(多个索引)
- 1)源代码
@Test
public void getMultiData() {
// 1 查询多个文档
MultiGetResponse response = client.prepareMultiGet().add("blog", "article", "1").add("blog", "article", "2", "3").add("blog", "article", "2").get();
// 2 遍历返回的结果
for(MultiGetItemResponse itemResponse:response){
GetResponse getResponse = itemResponse.getResponse();
// 如果获取到查询结果
if (getResponse.isExists()) {
String sourceAsString = getResponse.getSourceAsString();
System.out.println(sourceAsString);
}
}
// 3 关闭资源
client.close();
}
- 2)结果查看
{"id":"1","title":"基于Lucene的搜索服务器","content":"它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口"}
{"content":"它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口","id":"2","title":"基于Lucene的搜索服务器"}
{"id":3,"titile":"ElasticSearch是一个基于Lucene的搜索服务器","content":"它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。"}
{"content":"它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口","id":"2","title":"基于Lucene的搜索服务器"}
10、更新文档数据(update)
- 1)源代码
@Test
public void updateData() throws Throwable {
// 1 创建更新数据的请求对象
UpdateRequest updateRequest = new UpdateRequest();
updateRequest.index("blog");
updateRequest.type("article");
updateRequest.id("3");
updateRequest.doc(XContentFactory.jsonBuilder().startObject()
// 对没有的字段添加, 对已有的字段替换
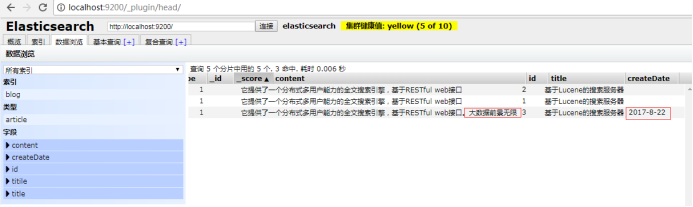
.field("title", "基于Lucene的搜索服务器")
.field("content","它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。大数据前景无限")
.field("createDate", "2017-8-22").endObject());
// 2 获取更新后的值
UpdateResponse indexResponse = client.update(updateRequest).get();
// 3 打印返回的结果
System.out.println("index:" + indexResponse.getIndex());
System.out.println("type:" + indexResponse.getType());
System.out.println("id:" + indexResponse.getId());
System.out.println("version:" + indexResponse.getVersion());
System.out.println("create:" + indexResponse.getResult());
// 4 关闭连接
client.close();
}
- 2)结果查看
11、更新文档数据(upsert)
设置查询条件, 查找不到则添加IndexRequest内容,查找到则按照UpdateRequest更新。
@Test
public void testUpsert() throws Exception {
// 设置查询条件, 查找不到则添加
IndexRequest indexRequest = new IndexRequest("blog", "article", "5")
.source(XContentFactory.jsonBuilder().startObject().field("title", "搜索服务器").field("content","它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。").endObject());
// 设置更新, 查找到更新下面的设置
UpdateRequest upsert = new UpdateRequest("blog", "article", "5")
.doc(XContentFactory.jsonBuilder().startObject().field("user", "李四").endObject()).upsert(indexRequest);
client.update(upsert).get();
client.close();
}
第一次执行
hadoop102:9200/blog/article/5

第二次执行
hadoop102:9200/blog/article/5

12、删除文档数据(prepareDelete)
- 1)源代码
@Test
public void deleteData() {
// 1 删除文档数据
DeleteResponse indexResponse = client.prepareDelete("blog", "article", "5").get();
// 2 打印返回的结果
System.out.println("index:" + indexResponse.getIndex());
System.out.println("type:" + indexResponse.getType());
System.out.println("id:" + indexResponse.getId());
System.out.println("version:" + indexResponse.getVersion());
System.out.println("found:" + indexResponse.getResult());
// 3 关闭连接
client.close();
}
- 2)结果查看

2 条件查询QueryBuilder
2、条件查询QueryBuilder
1、查询所有(matchAllQuery)
- 1)源代码
@Test
public void matchAllQuery() {
// 1 执行查询
SearchResponse searchResponse = client.prepareSearch("blog").setTypes("article")
.setQuery(QueryBuilders.matchAllQuery()).get();
// 2 打印查询结果
SearchHits hits = searchResponse.getHits(); // 获取命中次数,查询结果有多少对象
System.out.println("查询结果有:" + hits.getTotalHits() + "条");
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsString());//打印出每条结果
}
// 3 关闭连接
client.close();
}
- 2)结果查看

2、对所有字段分词查询(queryStringQuery)
- 1)源代码
@Test
public void query() {
// 1 条件查询
SearchResponse searchResponse = client.prepareSearch("blog").setTypes("article")
.setQuery(QueryBuilders.queryStringQuery("全文")).get();
// 2 打印查询结果
SearchHits hits = searchResponse.getHits(); // 获取命中次数,查询结果有多少对象
System.out.println("查询结果有:" + hits.getTotalHits() + "条");
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsString());//打印出每条结果
}
// 3 关闭连接
client.close();
}
- 2)结果查看
3 通配符查询(wildcardQuery)
* :表示多个字符(0个或多个字符)
?:表示单个字符
1)源代码
@Test
public void wildcardQuery() {
// 1 通配符查询
SearchResponse searchResponse = client.prepareSearch("blog").setTypes("article")
.setQuery(QueryBuilders.wildcardQuery("content", "*全*")).get();
// 2 打印查询结果
SearchHits hits = searchResponse.getHits(); // 获取命中次数,查询结果有多少对象
System.out.println("查询结果有:" + hits.getTotalHits() + "条");
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsString());//打印出每条结果
}
// 3 关闭连接
client.close();
}
- 2)结果查看

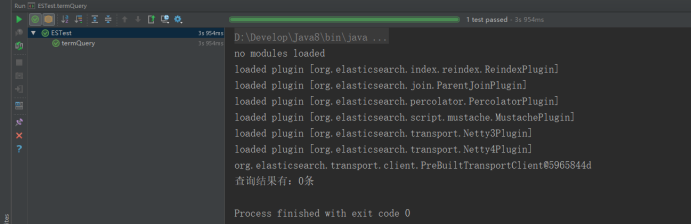
4、词条查询(TermQuery)
- 1)源代码
@Test
public void termQuery() {
// 1 第一field查询
SearchResponse searchResponse = client.prepareSearch("blog").setTypes("article")
.setQuery(QueryBuilders.termQuery("content", "全文")).get();
// 2 打印查询结果
SearchHits hits = searchResponse.getHits(); // 获取命中次数,查询结果有多少对象
System.out.println("查询结果有:" + hits.getTotalHits() + "条");
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsString());//打印出每条结果
}
// 3 关闭连接
client.close();
}
- 2)结果查看
5、模糊查询(fuzzy)
@Test
public void fuzzy() {
// 1 模糊查询
SearchResponse searchResponse = client.prepareSearch("blog").setTypes("article")
.setQuery(QueryBuilders.fuzzyQuery("title", "lucene")).get();
// 2 打印查询结果
SearchHits hits = searchResponse.getHits(); // 获取命中次数,查询结果有多少对象
System.out.println("查询结果有:" + hits.getTotalHits() + "条");
Iterator<SearchHit> iterator = hits.iterator();
while (iterator.hasNext()) {
SearchHit searchHit = iterator.next(); // 每个查询对象
System.out.println(searchHit.getSourceAsString()); // 获取字符串格式打印
}
// 3 关闭连接
client.close();
}
3、映射相关操作
- 1)源代码
@Test
public void createMapping() throws Exception {
// 1设置mapping
XContentBuilder builder = XContentFactory.jsonBuilder()
.startObject()
.startObject("article")
.startObject("properties")
.startObject("id1")
.field("type", "string")
.field("store", "yes")
.endObject()
.startObject("title2")
.field("type", "string")
.field("store", "no")
.endObject()
.startObject("content")
.field("type", "string")
.field("store", "yes")
.endObject()
.endObject()
.endObject()
.endObject();
// 2 添加mapping
PutMappingRequest mapping = Requests.putMappingRequest("blog4").type("article").source(builder);
client.admin().indices().putMapping(mapping).get();
// 3 关闭资源
client.close();
}
- 2)查看结果
四、IK分词器
针对词条查询(TermQuery),查看默认中文分词器的效果:
[itstar@hadoop105 elasticsearch]$ curl -XGET 'http://hadoop105:9200/_analyze?pretty&analyzer=standard' -d '中华人民共和国'
{
"tokens" : [
{
"token" : "中",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 0
},
{
"token" : "华",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "人",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "民",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "共",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<IDEOGRAPHIC>",
"position" : 4
},
{
"token" : "和",
"start_offset" : 5,
"end_offset" : 6,
"type" : "<IDEOGRAPHIC>",
"position" : 5
},
{
"token" : "国",
"start_offset" : 6,
"end_offset" : 7,
"type" : "<IDEOGRAPHIC>",
"position" : 6
}
]
}
1、IK分词器的安装
1 前期准备工作
- 1)CentOS联网
配置CentOS能连接外网。Linux虚拟机ping www.baidu.com 是畅通的
- 2)jar包准备
(1)elasticsearch-analysis-ik-master.zip
(下载地址:https://github.com/medcl/elasticsearch-analysis-ik)
(2)apache-maven-3.0.5-bin.tar.gz
2、jar包安装
1)Maven解压、配置 MAVEN_HOME和PATH。
[itstar@hadoop102 software]# tar -zxvf apache-maven-3.0.5-bin.tar.gz -C /opt/module/
[itstar@hadoop102 apache-maven-3.0.5]# sudo vi /etc/profile
#MAVEN_HOME
export MAVEN_HOME=/opt/module/apache-maven-3.0.5
export PATH=$PATH:$MAVEN_HOME/bin
[itstar@hadoop101 software]#source /etc/profile
验证命令:mvn -version
- 2)Ik分词器解压、打包与配置
//ik分词器解压
[itstar@hadoop102 software]$ unzip elasticsearch-analysis-ik-master.zip -d ./
//进入ik分词器所在目录
[itstar@hadoop102 software]$ cd elasticsearch-analysis-ik-master
//使用maven进行打包
[itstar@hadoop102 elasticsearch-analysis-ik-master]$ mvn package -Pdist,native -DskipTests -Dtar
//打包完成之后,会出现 target/releases/elasticsearch-analysis-ik-{version}.zip
[itstar@hadoop102 releases]$ pwd /opt/software/elasticsearch-analysis-ik-master/target/releases
//对zip文件进行解压,并将解压完成之后的文件拷贝到es所在目录下的/plugins/
[itstar@hadoop102 releases]$ unzip elasticsearch-analysis-ik-6.0.0.zip
[itstar@hadoop102 releases]$ cp -r elasticsearch /opt/module/elasticsearch-5.6.1/plugins/
//需要修改plugin-descriptor.properties文件,将其中的es版本号改为你所使用的版本号,即完成ik分词器的安装
[itstar@hadoop102 elasticsearch]$ vi plugin-descriptor.properties
//71行
elasticsearch.version=6.0.0
//修改为
elasticsearch.version=5.6.1
注意:需选择与es相同版本的ik分词器。
安装方法(2种):
1.
./elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.1.1/elasticsearch-analysis-ik-6.1.1.zip
2.
cp elasticsearch-analysis-ik-6.1.1.zip ./elasticsearch-6.1.1/plugins/
unzip elasticsearch-analysis-ik-6.1.1.zip -d ik-analyzer
3、
elasticsearch-plugin install -f file:///usr/local/elasticsearch-analysis-ik-6.1.1.zip
2、IK分词器的使用
1、命令行查看结果
- ik_smart模式
[itstar@hadoop102 elasticsearch]$ curl -XGET 'http://hadoop104:9200/_analyze?pretty&analyzer=ik_smart' -d '中华人民共和国'
curl -H "Content-Type:application/json" -XGET 'http://192.168.109.133:9200/_analyze?pretty' -d '{"analyzer":"ik_smart","text":"中华人民共和国"}'
{
"tokens" : [
{
"token" : "中华人民共和国",
"start_offset" : 0,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 0
}
]
}
- ik_max_word模式
[itstar@hadoop102 elasticsearch]$ curl -XGET 'http://hadoop104:9200/_analyze?pretty&analyzer=ik_max_word' -d '中华人民共和国'
curl -H "Content-Type:application/json" -XGET 'http://192.168.109.133:9200/_analyze?pretty' -d '{"analyzer":"ik_max_word","text":"中华人民共和国"}'
{
"tokens" : [
{
"token" : "中华人民共和国",
"start_offset" : 0,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "中华人民",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "中华",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "华人",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "人民共和国",
"start_offset" : 2,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "人民",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "共和国",
"start_offset" : 4,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "共和",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 7
},
{
"token" : "国",
"start_offset" : 6,
"end_offset" : 7,
"type" : "CN_CHAR",
"position" : 8
}
]
}
2 JavaAPI操作
- 1)创建索引
//创建索引(数据库)
@Test
public void createIndex() {
//创建索引
client.admin().indices().prepareCreate("blog4").get();
//关闭资源
client.close();
}
- 2)创建mapping
//创建使用ik分词器的mapping
@Test
public void createMapping() throws Exception {
// 1设置mapping
XContentBuilder builder = XContentFactory.jsonBuilder()
.startObject()
.startObject("article")
.startObject("properties")
.startObject("id1")
.field("type", "string")
.field("store", "yes")
.field("analyzer","ik_smart")
.endObject()
.startObject("title2")
.field("type", "string")
.field("store", "no")
.field("analyzer","ik_smart")
.endObject()
.startObject("content")
.field("type", "string")
.field("store", "yes")
.field("analyzer","ik_smart")
.endObject()
.endObject()
.endObject()
.endObject();
// 2 添加mapping
PutMappingRequest mapping = Requests.putMappingRequest("blog4").type("article").source(builder);
client.admin().indices().putMapping(mapping).get();
// 3 关闭资源
client.close();
}
- 3)插入数据
//创建文档,以map形式
@Test
public void createDocumentByMap() {
HashMap<String, String> map = new HashMap<>();
map.put("id1", "2");
map.put("title2", "Lucene");
map.put("content", "它提供了一个分布式的web接口");
IndexResponse response = client.prepareIndex("blog4", "article", "3").setSource(map).execute().actionGet();
//打印返回的结果
System.out.println("结果:" + response.getResult());
System.out.println("id:" + response.getId());
System.out.println("index:" + response.getIndex());
System.out.println("type:" + response.getType());
System.out.println("版本:" + response.getVersion());
//关闭资源
client.close();
}
- 4)词条查询
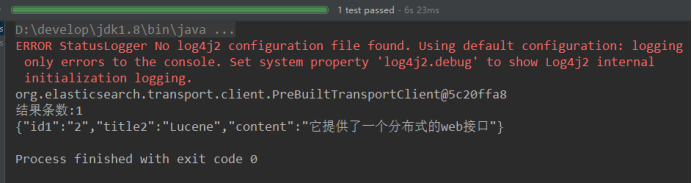
//词条查询
@Test
public void queryTerm() {
SearchResponse response = client.prepareSearch("blog4").setTypes("article").setQuery(QueryBuilders.termQuery("content","提供")).get();
//获取查询命中结果
SearchHits hits = response.getHits();
System.out.println("结果条数:" + hits.getTotalHits());
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsString());
}
}
- 5)结果查看
Store 的解释:
使用 elasticsearch 时碰上了很迷惑的地方,我看官方文档说 store 默认是 no ,我想当然的理解为也就是说这个 field 是不会 store 的,但是查询的时候也能查询出来,经过查找资料了解到原来 store 的意思是,是否在 _source 之外在独立存储一份,这里要说一下 _source 这是源文档,当你索引数据的时候, elasticsearch 会保存一份源文档到 _source ,如果文档的某一字段设置了 store 为 yes (默认为 no),这时候会在 _source 存储之外再为这个字段独立进行存储,这么做的目的主要是针对内容比较多的字段,放到 _source 返回的话,因为_source 是把所有字段保存为一份文档,命中后读取只需要一次 IO,包含内容特别多的字段会很占带宽影响性能,通常我们也不需要完整的内容返回(可能只关心摘要),这时候就没必要放到 _source 里一起返回了(当然也可以在查询时指定返回字段)。
五、Logstash
5.1 Logstash简介
Logstash is a tool for managing events and logs. You can use it to collect logs, parse them, and store them for later use (like, for searching).
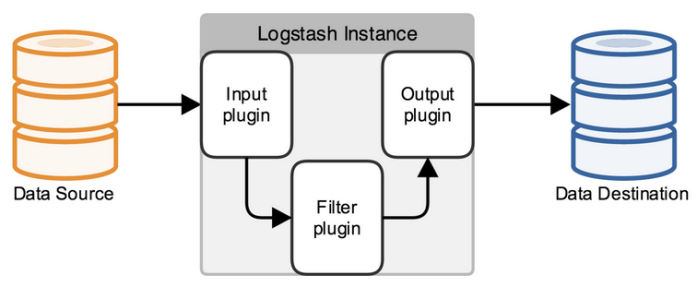
logstash是一个数据分析软件,主要目的是分析log日志。整一套软件可以当作一个MVC模型,logstash是controller层,Elasticsearch是一个model层,kibana是view层。
首先将数据传给logstash,它将数据进行过滤和格式化(转成JSON格式),然后传给Elasticsearch进行存储、建搜索的索引,kibana提供前端的页面再进行搜索和图表可视化,它是调用Elasticsearch的接口返回的数据进行可视化。logstash和Elasticsearch是用Java写的,kibana使用node.js框架。
这个软件官网有很详细的使用说明,https://www.elastic.co/,除了docs之外,还有视频教程。这篇博客集合了docs和视频里面一些比较重要的设置和使用。
2、Logstash 安装
直接下载官方发布的二进制包的,可以访问 https://www.elastic.co/downloads/logstash 页面找对应操作系统和版本,点击下载即可。
在终端中,像下面这样运行命令来启动 Logstash 进程:
# bin/logstash -e 'input{stdin{}}output{stdout{codec=>rubydebug}}'
注意:如果出现如下报错,请调高虚拟机内存容量。
Java HotSpot(TM) 64-Bit Server VM warning: INFO: os::commit_memory(0x00000000c5330000, 986513408, 0) failed; error='Cannot allocate memory' (errno=12)
#
# There is insufficient memory for the Java Runtime Environment to continue.
# Native memory allocation (mmap) failed to map 986513408 bytes for committing reserved memory.
# An error report file with more information is saved as:
# /usr/local/logstash-6.6.2/confs_test/hs_err_pid3910.log
然后你会发现终端在等待你的输入。没问题,敲入 Hello World,回车,
{
"@version" => "1",
"host" => "***",
"message" => "hello world",
"@timestamp" => 2019-03-18T02:51:18.578Z
}
每位系统管理员都肯定写过很多类似这样的命令:
cat randdata | awk '{print $2}' | sort | uniq -c | tee sortdata。
Logstash 就像管道符一样!
你输入(就像命令行的 cat )数据,然后处理过滤(就像 awk 或者 uniq 之类)数据,最后输出(就像 tee )到其他地方。
3、Logstash 配置
1 input配置
读取文件(File)
input {
file {
path => ["/var/log/*.log", "/var/log/message"]
type => "system"
start_position => "beginning"
}
}
output{stdout{codec=>rubydebug}}
有一些比较有用的配置项,可以用来指定 FileWatch 库的行为:
discover_interval
logstash 每隔多久去检查一次被监听的 path 下是否有新文件。默认值是 15 秒。
exclude
不想被监听的文件可以排除出去,这里跟 path 一样支持 glob 展开。
close_older
一个已经监听中的文件,如果超过这个值的时间内没有更新内容,就关闭监听它的文件句柄。默认是 3600 秒,即一小时。
ignore_older
在每次检查文件列表的时候,如果一个文件的最后修改时间超过这个值,就忽略这个文件。默认是 86400 秒,即一天。
sincedb_path
如果你不想用默认的 $HOME/.sincedb(Windows 平台上在 C:\Windows\System32\config\systemprofile.sincedb),可以通过这个配置定义 sincedb 文件到其他位置。
sincedb_write_interval
logstash 每隔多久写一次 sincedb 文件,默认是 15 秒。
stat_interval
logstash 每隔多久检查一次被监听文件状态(是否有更新),默认是 1 秒。
start_position
logstash 从什么位置开始读取文件数据,默认是结束位置,也就是说 logstash 进程会以类似 tail -F 的形式运行。如果你是要导入原有数据,把这个设定改成 "beginning",logstash 进程就从头开始读取,类似 less +F 的形式运行。
启动命令:../bin/logstash -f ./input_file.conf
测试命令:echo 'hehe' >> test.log echo 'hehe2' >> message
标准输入(Stdin)
我们已经见过好几个示例使用 stdin 了。这也应该是 logstash 里最简单和基础的插件了。
input {
stdin {
add_field => {"key" => "value"}
codec => "plain"
tags => ["add"]
type => "std"
}
}
output{stdout{codec=>rubydebug}}
用上面的新 stdin 设置重新运行一次最开始的 hello world 示例。我建议大家把整段配置都写入一个文本文件,然后运行命令:../bin/logstash -f ./input_stdin.conf。输入 "hello world" 并回车后,你会在终端看到如下输出:
{
"message" => "hello world",
"@version" => "1",
"@timestamp" => "2014-08-08T06:48:47.789Z",
"type" => "std",
"tags" => [
[0] "add"
],
"key" => "value",
"host" => "raochenlindeMacBook-Air.local"
}
解释
type 和 tags 是 logstash 事件中两个特殊的字段。通常来说我们会在输入区段中通过 type 来标记事件类型。而 tags 则是在数据处理过程中,由具体的插件来添加或者删除的。
最常见的用法是像下面这样:
input {
stdin {
type => "web"
}
}
filter {
if [type] == "web" {
grok {
match => ["message", %{COMBINEDAPACHELOG}]
}
}
}
output {
if "_grokparsefailure" in [tags] {
nagios_nsca {
nagios_status => "1"
}
} else {
elasticsearch {
}
}
}
2、codec配置
Codec 是 logstash 从 1.3.0 版开始新引入的概念(Codec 来自 Coder/decoder 两个单词的首字母缩写)。
在此之前,logstash 只支持纯文本形式输入,然后以过滤器处理它。但现在,我们可以在输入期处理不同类型的数据,这全是因为有了 codec 设置。
所以,这里需要纠正之前的一个概念。Logstash 不只是一个input | filter | output 的数据流,而是一个 input | decode | filter | encode | output 的数据流!codec 就是用来 decode、encode 事件的。
codec 的引入,使得 logstash 可以更好更方便的与其他有自定义数据格式的运维产品共存,比如 graphite、fluent、netflow、collectd,以及使用 msgpack、json、edn 等通用数据格式的其他产品等。
事实上,我们在第一个 "hello world" 用例中就已经用过 codec 了 —— rubydebug 就是一种 codec!虽然它一般只会用在 stdout 插件中,作为配置测试或者调试的工具。
采用 JSON 编码
在早期的版本中,有一种降低 logstash 过滤器的 CPU 负载消耗的做法盛行于社区(在当时的 cookbook 上有专门的一节介绍):直接输入预定义好的 JSON 数据,这样就可以省略掉 filter/grok 配置!
这个建议依然有效,不过在当前版本中需要稍微做一点配置变动 —— 因为现在有专门的 codec 设置。
配置示例
input {
stdin {
add_field => {"key" => "value"}
codec => "json"
type => "std"
}
}
output{stdout{codec=>rubydebug}}
输入:
{"simCar":18074045598,"validityPeriod":"1996-12-06","unitPrice":9,"quantity":19,"amount":35,"imei":887540376467915,"user":"test"}
运行结果:
{
"imei" => 887540376467915,
"unitPrice" => 9,
"user" => "test",
"@timestamp" => 2019-03-19T05:01:53.451Z,
"simCar" => 18074045598,
"host" => "zzc-203",
"amount" => 35,
"@version" => "1",
"key" => "value",
"type" => "std",
"validityPeriod" => "1996-12-06",
"quantity" => 19
}
3、filter配置
- Grok插件
logstash拥有丰富的filter插件,它们扩展了进入过滤器的原始数据,进行复杂的逻辑处理,甚至可以无中生有的添加新的 logstash 事件到后续的流程中去!Grok 是 Logstash 最重要的插件之一。也是迄今为止使蹩脚的、无结构的日志结构化和可查询的最好方式。Grok在解析 syslog logs、apache and other webserver logs、mysql logs等任意格式的文件上表现完美。
这个工具非常适用于系统日志,Apache和其他网络服务器日志,MySQL日志等。
配置:
input {
stdin {
type => "std"
}
}
filter {
grok {
match=>{"message"=> "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}" }
}
}
output{stdout{codec=>rubydebug}}
输入:55.3.244.1 GET /index.html 15824 0.043
输出:
{
"@version" => "1",
"host" => "zzc-203",
"request" => "/index.html",
"bytes" => "15824",
"duration" => "0.043",
"method" => "GET",
"@timestamp" => 2019-03-19T05:09:55.777Z,
"message" => "55.3.244.1 GET /index.html 15824 0.043",
"type" => "std",
"client" => "55.3.244.1"
}
grok模式的语法如下:
%{SYNTAX:SEMANTIC}
SYNTAX:代表匹配值的类型,例如3.44可以用NUMBER类型所匹配,127.0.0.1可以使用IP类型匹配。
SEMANTIC:代表存储该值的一个变量名称,例如 3.44 可能是一个事件的持续时间,127.0.0.1可能是请求的client地址。所以这两个值可以用 %{NUMBER:duration} %{IP:client} 来匹配。
你也可以选择将数据类型转换添加到Grok模式。默认情况下,所有语义都保存为字符串。如果您希望转换语义的数据类型,例如将字符串更改为整数,则将其后缀为目标数据类型。例如%{NUMBER:num:int}将num语义从一个字符串转换为一个整数。目前唯一支持的转换是int和float。
Logstash附带约120个模式。你可以在这里找到它们https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns
自定义类型
更多时候logstash grok没办法提供你所需要的匹配类型,这个时候我们可以使用自定义。
创建自定义 patterns 文件。
①创建一个名为patterns其中创建一个文件postfix (文件名无关紧要,随便起),在该文件中,将需要的模式写为模式名称,空格,然后是该模式的正则表达式。例如:
POSTFIX_QUEUEID [0-9A-F]{10,11}
②然后使用这个插件中的patterns_dir设置告诉logstash目录是你的自定义模式。
配置:
input {
stdin {
type => "std"
}
}
filter {
grok {
patterns_dir => ["./patterns"]
match => { "message" => "%{SYSLOGBASE} %{POSTFIX_QUEUEID:queue_id}: %{GREEDYDATA:syslog_message}" }
}
}
output{stdout{codec=>rubydebug}}
输入:
Jan 1 06:25:43 mailserver14 postfix/cleanup[21403]: BEF25A72965: message-id=<20130101142543.5828399CCAF@mailserver1
输出:
{
"queue_id" => "BEF25A72965",
"message" => "Jan 1 06:25:43 mailserver14 postfix/cleanup[21403]: BEF25A72965: message-id=<20130101142543.5828399CCAF@mailserver1",
"pid" => "21403",
"program" => "postfix/cleanup",
"@version" => "1",
"type" => "std",
"logsource" => "mailserver14",
"host" => "zzc-203",
"timestamp" => "Jan 1 06:25:43",
"syslog_message" => "message-id=<20130101142543.5828399CCAF@mailserver1",
"@timestamp" => 2019-03-19T05:31:37.405Z
}
GeoIP 地址查询归类
GeoIP 是最常见的免费 IP 地址归类查询库,同时也有收费版可以采购。GeoIP 库可以根据 IP 地址提供对应的地域信息,包括国别,省市,经纬度等,对于可视化地图和区域统计非常有用。
配置:
input {
stdin {
type => "std"
}
}
filter {
geoip {
source => "message"
}
}
output{stdout{codec=>rubydebug}}
输入:183.60.92.253
输出:
{
"type" => "std",
"@version" => "1",
"@timestamp" => 2019-03-19T05:39:26.714Z,
"host" => "zzc-203",
"message" => "183.60.92.253",
"geoip" => {
"country_code3" => "CN",
"latitude" => 23.1167,
"region_code" => "44",
"region_name" => "Guangdong",
"location" => {
"lon" => 113.25,
"lat" => 23.1167
},
"city_name" => "Guangzhou",
"country_name" => "China",
"continent_code" => "AS",
"country_code2" => "CN",
"timezone" => "Asia/Shanghai",
"ip" => "183.60.92.253",
"longitude" => 113.25
}
}
4、output配置
标准输出(Stdout)
保存成文件(File)
通过日志收集系统将分散在数百台服务器上的数据集中存储在某中心服务器上,这是运维最原始的需求。Logstash 当然也能做到这点。
和 LogStash::Inputs::File 不同, LogStash::Outputs::File 里可以使用 sprintf format 格式来自动定义输出到带日期命名的路径。
配置:
input {
stdin {
type => "std"
}
}
output {
file {
path => "../data_test/%{+yyyy}/%{+MM}/%{+dd}/%{host}.log"
codec => line { format => "custom format: %{message}"}
}
}
启动后输入,可看到文件
服务器间传输文件(File)
//配置:
//接收日志服务器配置:
input {
tcp {
mode => "server"
port => 9600
ssl_enable => false
}
}
filter {
json {
source => "message"
}
}
output {
file {
path => "/home/hduser/app/logstash-6.6.2/data_test/%{+YYYY-MM-dd}/%{servip}-%{filename}"
codec => line { format => "%{message}"}
}
}
//发送日志服务器配置:
input{
file {
path => ["/home/hduser/app/logstash-6.6.2/data_test/send.log"]
type => "ecolog"
start_position => "beginning"
}
}
filter {
if [type] =~ /^ecolog/ {
ruby {
code => "file_name = event.get('path').split('/')[-1]
event.set('file_name',file_name)
event.set('servip','接收方ip')"
}
mutate {
rename => {"file_name" => "filename"}
}
}
}
output {
tcp {
host => "接收方ip"
port => 9600
codec => json_lines
}
}
从发送方发送message,接收方可以看到写出文件。
写入到ES
//配置:
input {
stdin {
type => "log2es"
}
}
output {
elasticsearch {
hosts => ["192.168.109.133:9200"]
index => "logstash-%{type}-%{+YYYY.MM.dd}"
document_type => "%{type}"
sniffing => true
template_overwrite => true
}
}
//在head插件中可以看到数据。
//sniffing : 寻找其他es节点
//实战举例:将错误日志写入es。
//配置:
input {
file {
path => ["/usr/local/logstash-6.6.2/data_test/run_error.log"]
type => "error"
start_position => "beginning"
}
}
output {
elasticsearch {
hosts => ["192.168.109.133:9200"]
index => "logstash-%{type}-%{+YYYY.MM.dd}"
document_type => "%{type}"
sniffing => true
template_overwrite => true
}
}
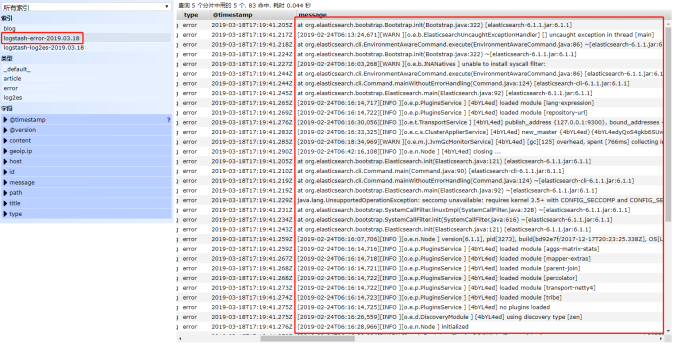
问题:一个错误被分成了多个document。如何解决?
六、Kibana
Kibana是一个开源的分析和可视化平台,设计用于和Elasticsearch一起工作。
你用Kibana来搜索,查看,并和存储在Elasticsearch索引中的数据进行交互。
你可以轻松地执行高级数据分析,并且以各种图标、表格和地图的形式可视化数据。
Kibana使得理解大量数据变得很容易。它简单的、基于浏览器的界面使你能够快速创建和共享动态仪表板,实时显示Elasticsearch查询的变化。
安装步骤:
解压:tar -zxvf kibana-6.6.2-linux-x86_64.tar.gz
修改 kibana.yml 配置文件:
server.port: 5601
server.host: "192.168.109.134" ----------部署kinana服务器的ip
elasticsearch.hosts: ["http://192.168.109.133:9200"]
kibana.index: ".kibana"
启动kibana,报错:
[error][status][plugin:remote_clusters@6.6.2] Status changed from red to red - X-Pack plugin is not installed on the [data] Elasticsearch cluster.
解决,卸载x-pack插件。
elasticsearch-plugin remove x-pack
kibana-plugin remove x-pack
安装好后启动即可。页面操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号