Spark SQL学习笔记
一、Spark SQL基础
1、Spark SQL简介
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象叫做DataFrame并且作为分布式SQL查询引擎的作用。
为什么要学习Spark SQL?我们已经学习了Hive,它是将Hive SQL转换成MapReduce然后提交到集群上执行,大大简化了编写MapReduce的程序的复杂性,由于MapReduce这种计算模型执行效率比较慢。所以Spark SQL的应运而生,它是将Spark SQL转换成RDD,然后提交到集群执行,执行效率非常快!同时Spark SQL也支持从Hive中读取数据。
- Spark SQL的特点:
容易整合(集成)

统一的数据访问方式

兼容Hive
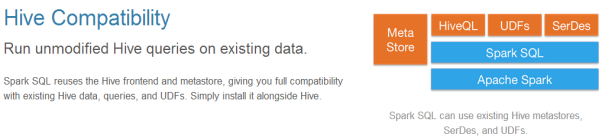
标准的数据连接

2、基本概念:Datasets和DataFrames
- DataFrame
DataFrame是组织成命名列的数据集。它在概念上等同于关系数据库中的表,但在底层具有更丰富的优化。DataFrames可以从各种来源构建,
例如:
结构化数据文件
hive中的表
外部数据库或现有RDDs
DataFrame API支持的语言有Scala,Java,Python和R。
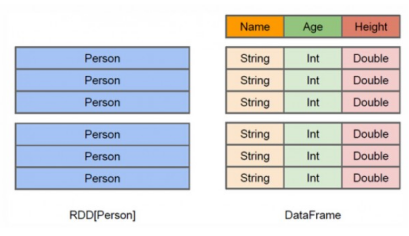
从上图可以看出,DataFrame多了数据的结构信息,即schema。RDD是分布式的 Java对象的集合。DataFrame是分布式的Row对象的集合。DataFrame除了提供了比RDD更丰富的算子以外,更重要的特点是提升执行效率、减少数据读取以及执行计划的优化
- Datasets
Dataset是数据的分布式集合。Dataset是在Spark 1.6中添加的一个新接口,是DataFrame之上更高一级的抽象。它提供了RDD的优点(强类型化,使用强大的lambda函数的能力)以及Spark SQL优化后的执行引擎的优点。一个Dataset 可以从JVM对象构造,然后使用函数转换(map, flatMap,filter等)去操作。 Dataset API 支持Scala和Java。 Python不支持Dataset API。
3、测试数据
使用员工表的数据,并已经将其保存到了HDFS上。
4、创建DataFrames
- 通过Case Class创建DataFrames
1)定义case class(相当于表的结构:Schema)
注意:由于mgr和comm列中包含null值,简单起见,将对应的case class类型定义为String
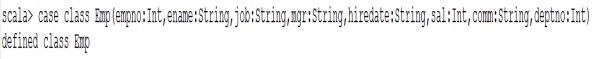
2)将HDFS上的数据读入RDD,并将RDD与case Class关联
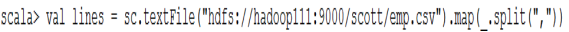

3)将RDD转换成DataFrames
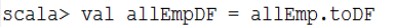
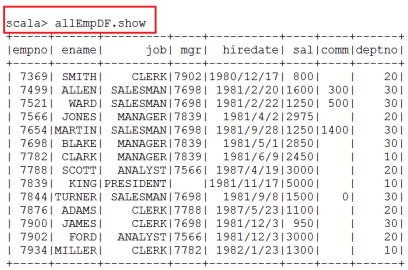
4)通过DataFrames查询数据
- 使用SparkSession
1)什么是SparkSession
Apache Spark 2.0引入了SparkSession,其为用户提供了一个统一的切入点来使用Spark的各项功能,并且允许用户通过它调用DataFrame和Dataset相关API来编写Spark程序。最重要的是,它减少了用户需要了解的一些概念,使得我们可以很容易地与Spark交互。
在2.0版本之前,与Spark交互之前必须先创建SparkConf和SparkContext。然而在Spark 2.0中,我们可以通过SparkSession来实现同样的功能,而不需要显式地创建SparkConf, SparkContext 以及 SQLContext,因为这些对象已经封装在SparkSession中。

2)创建StructType,来定义Schema结构信息

val myschema = StructType(List(StructField("empno", DataTypes.IntegerType), StructField("ename", DataTypes.StringType),StructField("job", DataTypes.StringType),StructField("mgr", DataTypes.StringType),StructField("hiredate", DataTypes.StringType),StructField("sal", DataTypes.IntegerType),StructField("comm", DataTypes.StringType),StructField("deptno", DataTypes.IntegerType)))
注意,需要:import org.apache.spark.sql.types._
3)读入数据并且切分数据
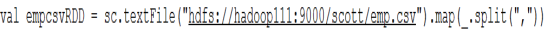
4)将RDD中的数据映射成Row
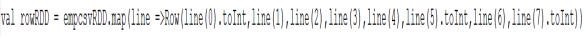
注意,需要:import org.apache.spark.sql.Row
5)创建DataFrames
val df = spark.createDataFrame(rowRDD,myschema)
再举一个例子,使用JSon文件来创建DataFame
源文件:$SPARK_HOME/examples/src/main/resources/people.json
val df = spark.read.json("源文件")
查看数据和Schema信息

5、DataFrame操作
DataFrame操作也称为无类型的Dataset操作
- 查询所有的员工姓名

- 查询所有的员工姓名和薪水,并给薪水加100块钱
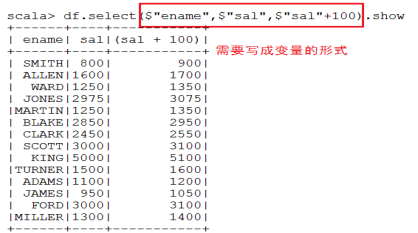
- 查询工资大于2000的员工

- 求每个部门的员工人数

完整的例子,请参考:
http://spark.apache.org/docs/2.1.0/api/scala/index.html#org.apache.spark.sql.Dataset
- 在DataFrame中使用SQL语句
将DataFrame注册成表(视图):df.createOrReplaceTempView("emp")
执行查询:
spark.sql("select * from emp").show
spark.sql("select * from emp where deptno=10").show
spark.sql("select deptno,sum(sal) from emp group by deptno").show
6、Global Temporary View
上面使用的是一个在Session生命周期中的临时views。在Spark SQL中,如果你想拥有一个临时的view,并想在不同的Session中共享,而且在application的运行周期内可用,那么就需要创建一个全局的临时view。并记得使用的时候加上global_temp作为前缀来引用它,因为全局的临时view是绑定到系统保留的数据库global_temp上。
1)创建一个普通的view和一个全局的view
df.createOrReplaceTempView("emp1")
df.createGlobalTempView("emp2")
2)在当前会话中执行查询,均可查询出结果。
spark.sql("select * from emp1").show
spark.sql("select * from global_temp.emp2").show
3)开启一个新的会话,执行同样的查询
spark.newSession.sql("select * from emp1").show (运行出错)
spark.newSession.sql("select * from global_temp.emp2").show
7、创建Datasets
DataFrame的引入,可以让Spark更好的处理结构数据的计算,但其中一个主要的问题是:缺乏编译时类型安全。为了解决这个问题,Spark采用新的Dataset API (DataFrame API的类型扩展)。
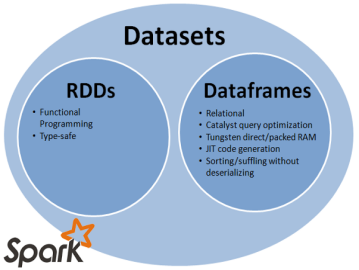
Dataset是一个分布式的数据收集器。这是在Spark1.6之后新加的一个接口,兼顾了RDD的优点(强类型,可以使用功能强大的lambda)以及Spark SQL的执行器高效性的优点。所以可以把DataFrames看成是一种特殊的Datasets,即:Dataset(Row)
- 创建DataSet,方式一:使用序列
1)定义case class
case class MyData(a:Int,b:String)
2)生成序列,并创建DataSet
val ds = Seq(MyData(1,"Tom"),MyData(2,"Mary")).toDS
3)查看结果

- 创建DataSet,方式二:使用JSON数据
3)定义case class
case class Person(name: String, gender: String)
3)通过JSON数据生成DataFrame
val df = spark.read.json(sc.parallelize("""{"gender": "Male", "name": "Tom"}""" :: Nil))
3)将DataFrame转成DataSet
df.as[Person].show
df.as[Person].collect
- 创建DataSet,方式三:使用HDFS数据
1)读取HDFS数据,并创建DataSet
val linesDS = spark.read.text("hdfs://hadoop111:9000/data/data.txt").as[String]
2)对DataSet进行操作:分词后,查询长度大于3的单词
val words = linesDS.flatMap(_.split(" ")).filter(_.length > 3)
words.show
words.collect
3)执行WordCount程序
val result = linesDS.flatMap(_.split(" ")).map((_,1)).groupByKey(x => x._1).count
result.show
排序:result.orderBy($"value").show
8、Datasets的操作案例
- emp.json文件数据
{"empno":7369,"ename":"SMITH","job":"CLERK","mgr":"7902","hiredate":"1980/12/17","sal":800,"comm":"","deptno":20}
{"empno":7499,"ename":"ALLEN","job":"SALESMAN","mgr":"7698","hiredate":"1981/2/20","sal":1600,"comm":"300","deptno":30}
{"empno":7521,"ename":"WARD","job":"SALESMAN","mgr":"7698","hiredate":"1981/2/22","sal":1250,"comm":"500","deptno":30}
{"empno":7566,"ename":"JONES","job":"MANAGER","mgr":"7839","hiredate":"1981/4/2","sal":2975,"comm":"","deptno":20}
{"empno":7654,"ename":"MARTIN","job":"SALESMAN","mgr":"7698","hiredate":"1981/9/28","sal":1250,"comm":"1400","deptno":30}
{"empno":7698,"ename":"BLAKE","job":"MANAGER","mgr":"7839","hiredate":"1981/5/1","sal":2850,"comm":"","deptno":30}
{"empno":7782,"ename":"CLARK","job":"MANAGER","mgr":"7839","hiredate":"1981/6/9","sal":2450,"comm":"","deptno":10}
{"empno":7788,"ename":"SCOTT","job":"ANALYST","mgr":"7566","hiredate":"1987/4/19","sal":3000,"comm":"","deptno":20}
{"empno":7839,"ename":"KING","job":"PRESIDENT","mgr":"","hiredate":"1981/11/17","sal":5000,"comm":"","deptno":10}
{"empno":7844,"ename":"TURNER","job":"SALESMAN","mgr":"7698","hiredate":"1981/9/8","sal":1500,"comm":"0","deptno":30}
{"empno":7876,"ename":"ADAMS","job":"CLERK","mgr":"7788","hiredate":"1987/5/23","sal":1100,"comm":"","deptno":20}
{"empno":7900,"ename":"JAMES","job":"CLERK","mgr":"7698","hiredate":"1981/12/3","sal":950,"comm":"","deptno":30}
{"empno":7902,"ename":"FORD","job":"ANALYST","mgr":"7566","hiredate":"1981/12/3","sal":3000,"comm":"","deptno":20}
{"empno":7934,"ename":"MILLER","job":"CLERK","mgr":"7782","hiredate":"1982/1/23","sal":1300,"comm":"","deptno":10}
- 使用emp.json 生成DataFrame
val empDF = spark.read.json("/root/resources/emp.json")
查询工资大于3000的员工
empDF.where($"sal" >= 3000).show
- 创建case class
case class Emp(empno:Long,ename:String,job:String,hiredate:String,mgr:String,sal:Long,comm:String,deptno:Long)
- 生成DataSets,并查询数据
val empDS = empDF.as[Emp]
- 查询工资大于3000的员工
empDS.filter(_.sal > 3000).show
- 查看10号部门的员工
empDS.filter(_.deptno == 10).show
- 多表查询
1)创建部门表
val deptRDD=sc.textFile("/root/temp/dept.csv").map(_.split(","))
case class Dept(deptno:Int,dname:String,loc:String)
val deptDS = deptRDD.map(x=>Dept(x(0).toInt,x(1),x(2))).toDS
2)创建员工表
case class Emp(empno:Int,ename:String,job:String,mgr:String,hiredate:String,sal:Int,comm:String,deptno:Int)
val empRDD = sc.textFile("/root/temp/emp.csv").map(_.split(","))
val empDS = empRDD.map(x => Emp(x(0).toInt,x(1),x(2),x(3),x(4),x(5).toInt,x(6),x(7).toInt)).toDS
3)执行多表查询:等值链接
val result = deptDS.join(empDS,"deptno")
//另一种写法:注意有三个等号
val result = deptDS.joinWith(empDS,deptDS("deptno")=== empDS("deptno"))
joinWith和join的区别是连接后的新Dataset的schema会不一样
- 查看执行计划:result.explain
二、使用数据源
1、通用的Load/Save函数
- 什么是parquet文件?
Parquet是列式存储格式的一种文件类型,列式存储有以下的核心:
可以跳过不符合条件的数据,只读取需要的数据,降低IO数据量。
压缩编码可以降低磁盘存储空间。由于同一列的数据类型是一样的,可以使用更高效的压缩编码(例如Run Length Encoding和Delta Encoding)进一步节约存储空间。
只读取需要的列,支持向量运算,能够获取更好的扫描性能。
Parquet格式是Spark SQL的默认数据源,可通过spark.sql.sources.default配置
- 通用的Load/Save函数
读取Parquet文件
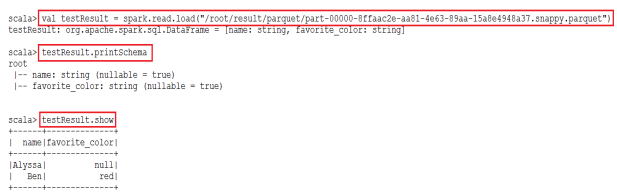
val usersDF = spark.read.load("/root/resources/users.parquet")
查询Schema和数据

查询用户的name和喜爱颜色,并保存
usersDF.select($"name",$"favorite_color").write.save("/root/result/parquet")
验证结果
- 显式指定文件格式:加载json格式
直接加载:val usersDF = spark.read.load("/root/resources/people.json")
//会出错
val usersDF = spark.read.format("json").load("/root/resources/people.json")
- 存储模式(Save Modes)
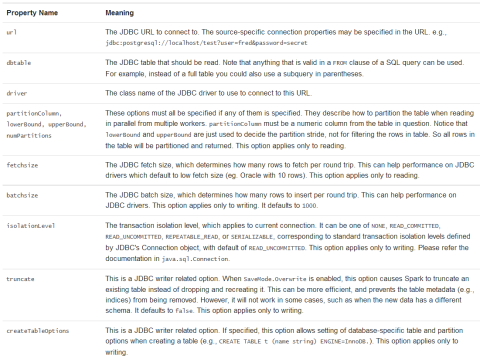
可以采用SaveMode执行存储操作,SaveMode定义了对数据的处理模式。需要注意的是,这些保存模式不使用任何锁定,不是原子操作。此外,当使用Overwrite方式执行时,在输出新数据之前原数据就已经被删除。SaveMode详细介绍如下表:

usersDF.select($"name").write.save("/root/result/parquet1")
--> 出错:因为/root/result/parquet1已经存在
usersDF.select($"name").write.mode("overwrite").save("/root/result/parquet1")
- 将结果保存为表
usersDF.select($"name").write.saveAsTable("table1")
也可以进行分区、分桶等操作:partitionBy、bucketBy
2、Parquet文件
Parquet是一个列格式而且用于多个数据处理系统中。Spark SQL提供支持对于Parquet文件的读写,也就是自动保存原始数据的schema。当写Parquet文件时,所有的列被自动转化为nullable,因为兼容性的缘故。
案例:
读入json格式的数据,将其转换成parquet格式,并创建相应的表来使用SQL进行查询。(emp.json文件数据在前文)

- Schema的合并:
Parquet支持Schema evolution(Schema演变,即:合并)。用户可以先定义一个简单的Schema,然后逐渐的向Schema中增加列描述。通过这种方式,用户可以获取多个有不同Schema但相互兼容的Parquet文件。

val df1 = sc.makeRDD(1 to 5).map(i => (i, i * 2)).toDF("single", "double")
df1.write.parquet("/root/myresult/test_table/key=1")
val df2 = sc.makeRDD(6 to 10).map(i => (i, i * 3)).toDF("single", "triple")
df2.write.parquet("/root/myresult/test_table/key=2")
val df3 = spark.read.option("mergeSchema", "true").parquet("/root/myresult/test_table/")
df3.printSchema()
3、JSON Datasets
Spark SQL能自动解析JSON数据集的Schema,读取JSON数据集为DataFrame格式。读取JSON数据集方法为SQLContext.read().json()。该方法将String格式的RDD或JSON文件转换为DataFrame。
需要注意的是,这里的JSON文件不是常规的JSON格式。JSON文件每一行必须包含一个独立的、自满足有效的JSON对象。如果用多行描述一个JSON对象,会导致读取出错。读取JSON数据集示例如下:
- Demo1:使用Spark自带的示例文件 --> people.json 文件
定义路径:
val path ="/root/resources/people.json"
读取Json文件,生成DataFrame:
val peopleDF = spark.read.json(path)
打印Schema结构信息:
peopleDF.printSchema()
创建临时视图:
peopleDF.createOrReplaceTempView("people")
执行查询
spark.sql("SELECT name FROM people WHERE age=19").show
4、使用JDBC
Spark SQL同样支持通过JDBC读取其他数据库的数据作为数据源。
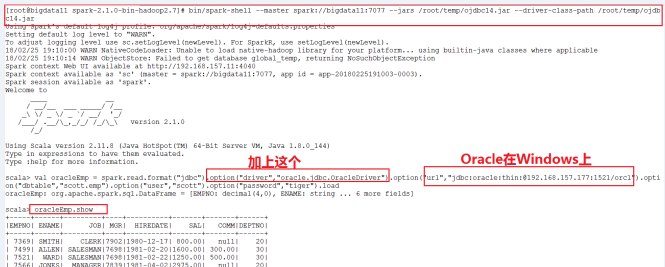
Demo演示:使用Spark SQL读取Oracle数据库中的表。
- 启动Spark Shell的时候,指定Oracle数据库的驱动
spark-shell --master spark://spark81:7077 \\
--jars /root/temp/ojdbc6.jar \\
--driver-class-path /root/temp/ojdbc6.jar
- 读取Oracle数据库中的数据
- 方式一:
val oracleDF = spark.read.format("jdbc").
option("url","jdbc:oracle:thin:@192.168.88.101:1521/orcl.example.com").
option("dbtable","scott.emp").
option("user","scott").
option("password","tiger").
load
- 方式二:
//导入需要的类:
import java.util.Properties
//定义属性:
val oracleprops = new Properties()
oracleprops.setProperty("user","scott")
oracleprops.setProperty("password","tiger")
//读取数据:
val oracleEmpDF =
spark.read.jdbc("jdbc:oracle:thin:@192.168.88.101:1521/orcl.example.com",
"scott.emp",oracleprops)
注意:下面是读取Oracle 10g(Windows上)的步骤
5、使用Hive Table
首先,搭建好Hive的环境(需要Hadoop)
配置Spark SQL支持Hive
只需要将以下文件拷贝到$SPARK_HOME/conf的目录下,即可
$HIVE_HOME/conf/hive-site.xml
$HADOOP_CONF_DIR/core-site.xml
$HADOOP_CONF_DIR/hdfs-site.xml
- 使用Spark Shell操作Hive
//创建表
spark.sql("create table src (key INT, value STRING) row format delimited fields terminated by ','")
//导入数据
spark.sql("load data local path '/root/temp/data.txt' into table src")
//查询数据
spark.sql("select * from src").show
- 使用spark-sql操作Hive
启动spark-sql的时候,需要使用--jars指定mysql的驱动程序
操作Hive
show tables;
select * from 表;
三、性能优化
1、在内存中缓存数据
性能调优主要是将数据放入内存中操作。通过spark.cacheTable("tableName")或者dataFrame.cache()。使用spark.uncacheTable("tableName")来从内存中去除table。
Demo案例:
- 从Oracle数据库中读取数据,生成DataFrame
val oracleDF = spark.read.format("jdbc")
.option("url","jdbc:oracle:thin:@192.168.88.101:1521/orcl.example.com")
.option("dbtable","scott.emp")
.option("user","scott")
.option("password","tiger").load
-
将DataFrame注册成表: oracleDF.registerTempTable("emp")
-
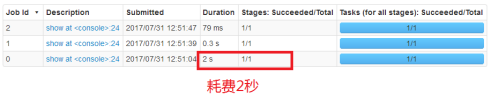
执行查询,并通过Web Console监控执行的时间
spark.sql("select * from emp").show
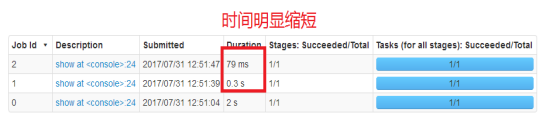
- 将表进行缓存,并查询两次,并通过Web Console监控执行的时间
spark.sqlContext.cacheTable("emp")
- 清空缓存:
spark.sqlContext.cacheTable("emp")
spark.sqlContext.clearCache
2、性能优化相关参数
- 将数据缓存到内存中的相关优化参数
spark.sql.inMemoryColumnarStorage.compressed
//默认为 true
//Spark SQL 将会基于统计信息自动地为每一列选择一种压缩编码方式。
spark.sql.inMemoryColumnarStorage.batchSize
//默认值:10000
//缓存批处理大小。缓存数据时, 较大的批处理大小可以提高内存利用率和压缩率,但同时也会带来 OOM(Out Of Memory)的风险。
- 其他性能相关的配置选项(不过不推荐手动修改,可能在后续版本自动的自适应修改)
spark.sql.files.maxPartitionBytes
//默认值:128 MB
//读取文件时单个分区可容纳的最大字节数
spark.sql.files.openCostInBytes
//默认值:4M
//打开文件的估算成本, 按照同一时间能够扫描的字节数来测量。当往一个分区写入多个文件的时候会使用。高估更好, 这样的话小文件分区将比大文件分区更快 (先被调度)。
spark.sql.autoBroadcastJoinThreshold
//默认值:10M
//用于配置一个表在执行 join 操作时能够广播给所有 worker 节点的最大字节大小。通过将这个值设置为 -1 可以禁用广播。注意,当前数据统计仅支持已经运行了 ANALYZE TABLE <tableName> COMPUTE STATISTICS noscan 命令的 Hive Metastore 表。
spark.sql.shuffle.partitions
//默认值:200
//用于配置 join 或聚合操作混洗(shuffle)数据时使用的分区数。
四、在IDEA中开发Spark SQL程序
1、指定Schema格式
package sparksql
import org.apache.spark.sql.{Row, SQLContext, SaveMode, SparkSession}
import org.apache.spark.sql.types._
import org.apache.spark.{SparkConf, SparkContext}
object SpecifyingSchema {
def main(args: Array[String]) {
//创建Spark Session对象
val spark = SparkSession.builder().master("local").appName("UnderstandingSparkSession").getOrCreate()
//从指定的地址创建RDD
val personRDD = spark.sparkContext.textFile("D:\\temp\\student.txt").map(_.split(" "))
//通过StructType直接指定每个字段的schema
val schema = StructType(
List(
StructField("id", IntegerType, true),
StructField("name", StringType, true),
StructField("age", IntegerType, true)
)
)
//将RDD映射到rowRDD
val rowRDD = personRDD.map(p => Row(p(0).toInt, p(1).trim, p(2).toInt))
//将schema信息应用到rowRDD上
val personDataFrame = spark.createDataFrame(rowRDD, schema)
//注册表
personDataFrame.createOrReplaceTempView("t_person")
//执行SQL
val df = spark.sql("select * from t_person order by age desc limit 4")
//显示结果
df.show()
//停止Spark Context
spark.stop()
}
}
2、使用case class
package demo
import org.apache.spark.sql.SparkSession
//使用case class
object Demo2 {
def main(args: Array[String]): Unit = {
//创建SparkSession
val spark = SparkSession.builder().master("local").appName("My Demo 1").getOrCreate()
//从指定的文件中读取数据,生成对应的RDD
val lineRDD = spark.sparkContext.textFile("d:\\temp\\student.txt").map(_.split(" "))
//将RDD和case class 关联
val studentRDD = lineRDD.map( x => Student(x(0).toInt,x(1),x(2).toInt))
//生成 DataFrame,通过RDD 生成DF,导入隐式转换
import spark.sqlContext.implicits._
val studentDF = studentRDD.toDF
//注册表 视图
studentDF.createOrReplaceTempView("student")
//执行SQL
spark.sql("select * from student").show()
spark.stop()
}
}
//case class 一定放在外面
case class Student(stuID:Int,stuName:String,stuAge:Int)
3、就数据保存到数据库
package demo
import java.util.Properties
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
//作用:读取本地一个文件, 生成对应 DataFrame,注册表
object Demo1 {
def main(args: Array[String]): Unit = {
//创建SparkSession
val spark = SparkSession.builder().master("local").appName("My Demo 1").getOrCreate()
//从指定的文件中读取数据,生成对应的RDD
val personRDD = spark.sparkContext.textFile("d:\\temp\\student.txt").map(_.split(" "))
//创建schema ,通过StructType
val schema = StructType(
List(
StructField("personID",IntegerType,true),
StructField("personName",StringType,true),
StructField("personAge",IntegerType,true)
)
)
//将RDD映射到Row RDD 行的数据上
val rowRDD = personRDD.map(p => Row(p(0).toInt,p(1).trim,p(2).toInt))
//生成DataFrame
val personDF = spark.createDataFrame(rowRDD,schema)
//将DF注册成表
personDF.createOrReplaceTempView("myperson")
//执行SQL
val result = spark.sql("select * from myperson")
//显示
//result.show()
//将结果保存到oracle中
val props = new Properties()
props.setProperty("user","scott")
props.setProperty("password","tiger")
result.write.jdbc("jdbc:oracle:thin:@192.168.88.101:1521/orcl.example.com","scott.myperson",props)
//如果表已经存在,append的方式数据
//result.write.mode("append").jdbc("jdbc:oracle:thin:@192.168.88.101:1521/orcl.example.com","scott.myperson",props)
//停止spark context
spark.stop()
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号