spark之RDD练习
目录
一、基础练习
练习一:翻倍列表中的数值并排序列表,并选出其中大于等于10的元素。
复制//通过并行化生成rdd
val rdd1 = sc.parallelize(List(5, 6, 14, 7, 3, 8, 2, 9, 1, 10))
//对rdd1里的每一个元素乘2然后排序
val rdd2 = rdd1.map(_ * 2).sortBy(x => x, true)
rdd1.collect
res0: Array[Int] = Array(2, 4, 6, 10, 12, 14, 16, 18, 20, 28)
//过滤出大于等于十的元素
val rdd3 = rdd2.filter(_ >= 10)
//将元素以数组的方式在客户端显示
rdd2.collect
res1: Array[Int] = Array(10, 12, 14, 16, 18, 20, 28)
练习二:将字符数组里面的每一个元素先切分在压平。
复制val rdd1 = sc.parallelize(Array("a b c", "d e f", "h i j"))
//将rdd1里面的每一个元素先切分在压平
val rdd2 = rdd1.flatMap(_.split(' '))
rdd1.collect
res2: Array[String] = Array(a, b, c, d, e, f, h, i, j)
练习三:求两个列表中的交集、并集、及去重后的结果
复制val rdd1 = sc.parallelize(List(5, 6, 4, 3))
val rdd2 = sc.parallelize(List(1, 2, 3, 4))
//求并集
val rdd3 = rdd1.union(rdd2)
rdd3.collect
res3: Array[Int] = Array(5, 6, 4, 3, 1, 2, 3, 4)
//去重
rdd3.distinct.collect
res5: Array[Int] = Array(4, 6, 2, 1, 3, 5)
//求交集
val rdd4 = rdd1.intersection(rdd2)
rdd4.collect
res4: Array[Int] = Array(4, 3)
练习四:对List列表中的kv对进行join与union操作
复制val rdd1 = sc.parallelize(List(("tom", 1), ("jerry", 3), ("kitty", 2)))
val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 1), ("shuke", 2)))
//求jion
val rdd3 = rdd1.join(rdd2)
rdd3.collect
res0: Array[(String, (Int, Int))] = Array((tom,(1,1)), (jerry,(3,2)))
//求并集
val rdd4 = rdd1 union rdd2
rdd4.collect
res1: Array[(String, Int)] = Array((tom,1), (jerry,3), (kitty,2), (jerry,2), (tom,1), (shuke,2))
//按key进行分组
val rdd5 = rdd4.groupByKey
rdd5.collect
res5: Array[(String, Iterable[Int])] =
Array((tom,CompactBuffer(1, 1)),
(jerry,CompactBuffer(3, 2)),
(shuke,CompactBuffer(2)),
(kitty,CompactBuffer(2)))
练习五:cogroup与groupByKey的区别
复制val rdd1 = sc.parallelize(List(("tom", 1), ("tom", 2), ("jerry", 3), ("kitty", 2)))
val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 1), ("shuke", 2)))
//cogroup
val rdd3 = rdd1.cogroup(rdd2)
//注意cogroup与groupByKey的区别
rdd3.collect
res0: Array[(String, (Iterable[Int], Iterable[Int]))] =
Array((tom,(CompactBuffer(1, 2),CompactBuffer(1))),
(jerry,(CompactBuffer(3),CompactBuffer(2))),
(shuke,(CompactBuffer(),CompactBuffer(2))),
(kitty,(CompactBuffer(2),CompactBuffer())))
//可看出groupByKey中对于每个key只有一个CompactBuffer(2),且CompactBuffer括号内的数值进行了合并成了列表
//而对于cogroup有多少个key就有几个CompactBuffer,且CompactBuffer括号内的数值就是原来的value
练习六:reduce聚合操作
复制val rdd1 = sc.parallelize(List(1, 2, 3, 4, 5))
//reduce聚合
val rdd2 = rdd1.reduce(_ + _)
rdd2: Int = 15
练习七:对List的kv对进行合并后聚合及排序
复制val rdd1 = sc.parallelize(List(("tom", 1), ("jerry", 3), ("kitty", 2), ("shuke", 1)))
val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 3), ("shuke", 2), ("kitty", 5)))
val rdd3 = rdd1.union(rdd2)
rdd3.collect
res5: Array[(String, Int)] = Array((tom,1), (jerry,3), (kitty,2), (shuke,1), (jerry,2), (tom,3), (shuke,2), (kitty,5))
//按key进行聚合
val rdd4 = rdd3.reduceByKey(_ + _)
rdd4.collect
res6: Array[(String, Int)] = Array((tom,4), (jerry,5), (shuke,3), (kitty,7))
//按value的降序排序
val rdd5 = rdd4.map(t => (t._2, t._1)).sortByKey(false).map(t => (t._2, t._1))
rdd5.collect
res9: Array[(String, Int)] = Array((kitty,7), (jerry,5), (tom,4), (shuke,3))
//第一个map进行kv调换,然后sortByKey(false)降序排序,之后再一次map对kv调换回来
二、Spark RDD的高级算子
1、mapPartitionsWithIndex

接收一个函数参数:
- 第一个参数:分区号
- 第二个参数:分区中的元素
复制//创建一个函数返回RDD中的每个分区号和元素:
val rdd1 = sc.parallelize(List(1,2,3,4,5,6,7,8,9), 2)
def func1(index:Int, iter:Iterator[Int]):Iterator[String] ={
iter.toList.map( x => "[PartID:" + index + ", value=" + x + "]" ).iterator
}
//调用:
rdd1.mapPartitionsWithIndex(func1).collect
res2: Array[String] =
Array([PartID:0, value=1], [PartID:0, value=2], [PartID:0, value=3],
[PartID:0, value=4], [PartID:1, value=5], [PartID:1, value=6],
[PartID:1, value=7], [PartID:1, value=8], [PartID:1, value=9])
2、aggregate
先对局部聚合,再对全局聚合
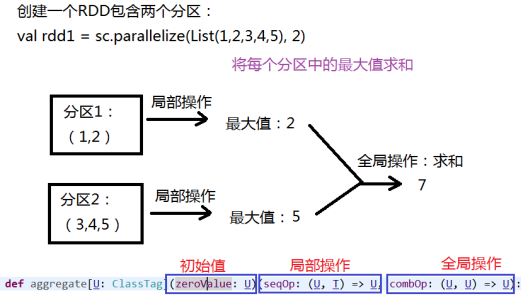
- 查看每个分区中的元素:
复制//创建一个函数返回RDD中的每个分区号和元素:
val rdd1 = sc.parallelize(List(1,2,3,4,5,6,7,8,9), 2)
def func1(index:Int, iter:Iterator[Int]):Iterator[String] ={
iter.toList.map( x => "[PartID:" + index + ", value=" + x + "]" ).iterator
}
//调用:
rdd1.mapPartitionsWithIndex(func1).collect
res2: Array[String] =
Array([PartID:0, value=1], [PartID:0, value=2], [PartID:0, value=3],
[PartID:0, value=4], [PartID:1, value=5], [PartID:1, value=6],
[PartID:1, value=7], [PartID:1, value=8], [PartID:1, value=9])
//将每个分区中的最大值求和(注意:初始值是0):
rdd1.aggregate(0)(math.max(_,_),_+_)
res3: Int = 7
//如果初始值时候10,则结果为:30。
rdd1.aggregate(10)(math.max(_,_),_+_)
res4: Int = 30
//如果是求和,注意:初始值是0:
scala> rdd1.aggregate(0)(_+_,_+_)
res5: Int = 15
//如果初始值是10,则结果是:45
scala> rdd1.aggregate(10)(_+_,_+_)
res6: Int = 45
- 一个字符串的例子:
复制val rdd2 = sc.parallelize(List("a","b","c","d","e","f"),2)
//修改一下刚才的查看分区元素的函数
scala> def func2(index:Int, iter:Iterator[(String)]):Iterator[String]=
{iter.toList.map(x=>"partID:" + index + ",val:" + x + "]").iterator}
//两个分区中的元素:
scala> rdd2.mapPartitionsWithIndex(func2).collect
res7: Array[String] = Array(partID:0,val:a], partID:0,val:b], partID:0,val:c], partID:1,val:d], partID:1,val:e], partID:1,val:f])
//运行结果:
scala> rdd2.aggregate("")(_+_,_+_)
res1: String = abcdef
scala> rdd2.aggregate("|")(_+_,_+_)
res2: String = ||abc|def
- 更复杂一点的例子
复制scala> val rdd3 = sc.parallelize(List("12","23","345","4567"),2)
//最后是x+y
scala> rdd3.aggregate("")((x,y)=>math.max(x.length,y.length).toString,(x,y)=>x+y)
res5: String = 24
//最后是y+x
scala> rdd3.aggregate("")((x,y)=>math.max(x.length,y.length).toString,(x,y)=>y+x)
res13: String = 42
val rdd4 = sc.parallelize(List("12","23","345",""),2)
//最后是x+y
scala> rdd4.aggregate("")((x,y) => math.min(x.length,y.length).toString,(x,y)=>x+y)
res17: String = 10
//最后是y+x
scala> rdd4.aggregate("")((x,y) => math.min(x.length,y.length).toString,(x,y)=>y+x)
res18: String = 01
作者:落花桂
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· 展开说说关于C#中ORM框架的用法!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?