spark基本面试题
- 序言
- 一、spark基本常识
- 1、spark中的RDD是什么,有哪些特性?
- 2、概述一下spark中常用算子区别(map,mapPartitions, foreach, foreachPartition)
- 3、map与flatMap的区别
- 4、reduceByKey是不是action?
- 5、cache后面能不能接其他算子?它是不是action操作?
- 6、RDD有哪些缺陷?
- 7、本地数据性是在哪个环节确定的?
- 8、RDD的弹性表现在哪几点?
- 9、常规的容错方式有那集中类型?
- 10、Spark提交你的jar包时所用的命令是什么?
- 11、spark有哪些组件?
- 12、Spark工作机制
- 13、什么是粗粒度,什么是细粒度,各自的优缺点是什么?
- 14、driver的功能是什么?
- 15、spark中worker的主要工作是什么?
- 16、RDD的创建有哪几种方式?
- 16、列举你常用的action?
- 二、spark要点
- 1、Spark shuffle时,是否会在磁盘上存储
- 2、谈谈spark中的宽窄依赖
- 3、spark中如何划分stage
- 4、spark中cache和persist的区别
- 5、spark中的数据倾斜的现象,原因,后果
- 6、spark数据倾斜的处理
- 7、spark有哪些聚合类的算子,我们应该避免什么类型的算子?
- 8、spark并行度怎么设置比较合适
- 9、spark中数据的位置是被谁管理的?
- 10、spark数据本地性有哪几种?
- 11、RDD有几种操作类型?
- 12、spark如何处理不能被序列化的对象?
- 13、collect功能是什么?底层是怎么实现的?
- 14、spark技术栈有哪些组件,每个组件都有什么功能,适合什么应用场景?
序言
本文内容是整理和收集spark基本问题,材料源于各类平台文章中,本文编写仅作为学习参看使用。
其中有CSDN博主「为了九亿少女的期待」,原文链接:https://blog.csdn.net/Lwj879525930/article/details/82559596
一、spark基本常识
1、spark中的RDD是什么,有哪些特性?
RDD(Resilient Distributed Dataset)叫做分布式数据集模式spark中最基本的数据抽象,它代表一个不可变,可分区,里面的元素可以并行计算的集合。
Resilient:表示弹性的,弹性表示
Destributed:分布式,可以并行在集群计算
Dataset:就是一个集合,用于存放数据的
五大特性:
1)一个分区列表,RDD中的数据都存储在一个分区列表中
2)作用在每一个分区列表中的函数。
3)一个RDD依赖于其他多个RDD,RDD的容错机制就是根据这个特性而来的。
4)可选的,针对于kv类型的RDD才有这个特性,作用是决定了数据的来源及数据处理后的去向。
5)可选项,数据本地性,数据位置最优。
2、概述一下spark中常用算子区别(map,mapPartitions, foreach, foreachPartition)
map:用于遍历RDD,将函数应用的每一个元素,返回新的RDD(transformation算子)
mapPartitions:用于遍历RDD的每一个分区,返回生成一个新的 RDD(transformation算子)
foreach:用于遍历RDD,将函数应用于每一个元素,无返回值(action算子)
foreachPartition:用于遍历操作RDD中的每一个分区,无返回值(action算子)
追述:一般使用mapPatitions和foreachPatition算子比map和foreach更加高效,推荐使用
3、map与flatMap的区别
map:对RDD每个元素转换,文件中的每一行数据返回一个数组对象。
flatMap:对RDD每一元素进行转换,然后再扁平化,将所有的对象合并为一个对象,文件中的所有行数据仅返回一个数组对象,会抛弃值为null的值。
4、reduceByKey是不是action?
不是,很多人都会以为是action, reduce rdd 是action。
5、cache后面能不能接其他算子?它是不是action操作?
cache可以接其他算子,但是接了算子之后,起不到缓存应有的效果,因为会重新出发cache。cache不是action操作。
6、RDD有哪些缺陷?
不支持细粒度的写和更新操作(如网络爬虫),spark写数据是粗粒度的,就是批量写入数据,未来提高效率。但是读数据是细粒度的,也就是说可以一条条的读。
不支持增量迭代计算,但Flink支持。
7、本地数据性是在哪个环节确定的?
具体的task运行在哪台机器上,dag划分stage的时候确定的。
8、RDD的弹性表现在哪几点?
1)自动的进行内存和磁盘的存储和切换;
2)基于Lingage的高效容错;
3)Task如果失败就会自动进行特定次数的重试;
4)Stage如果失败会自动进行特定次数的重试,而且只会自己算失败的分片;
5)checkpoint和persist,数据计算之后持久化缓存
6)数据调度弹性,DAG TASK调度和资源无关;
7)数据分片的高度弹性,a.分片很多碎片可以合并成大的,b.par
9、常规的容错方式有那集中类型?
1).数据检查点,会发生拷贝,浪费资源;
2).记录数据的更新,每次更新都会记录下来,比较复杂且比较消耗性能。
10、Spark提交你的jar包时所用的命令是什么?
spark-submit
11、spark有哪些组件?
-
Master:集群管理节点,不参与计算。
-
Worker:计算节点,进程本身不参与计算,和master汇报。
-
Driver:运行程序的main方法,创建spark context对象。
-
Client:用户提交程序的入口。
12、Spark工作机制
用户在client提交作业后,会由Driver运行main方法并创建spark context上下文。执行RDD算子,形成dag图输入dagscheduler,按照add之间的依赖关系划分stage输入task scheduler。 task scheduler会将stage划分为task set分发到各个节点的executor中执行。
13、什么是粗粒度,什么是细粒度,各自的优缺点是什么?
-
粗粒度:启动时就分配好资源,程序启动,后续具体使用就使用分配好的资源,不需要再分配资源。好处:作业特别多时,资源复用率较高,使用粗粒度。缺点:容易浪费资源,如果一个job有1000个task,完成999个,还有一个没完成,那么就使用粗粒度。如果999个资源闲置在那里,就会造成大量的资源浪费。
-
细粒度:用资源的时候分配,用完了就立即收回资源,启动会麻烦一点,启动一次分配一次,会比较麻烦。
14、driver的功能是什么?
-
一个spark作业运行时包括一个driver进程,也就是作业的主进程,具有main函数,并且有sparkContext的实例,是程序的入口。
-
功能:负责向集群申请资源,向master注册信息,负责了作业的调度,负责了作业的解析,生成stage并调度task到executor上,包括DAGScheduler,TaskScheduler。
15、spark中worker的主要工作是什么?
主要功能:管理当前节点内存,CPU的使用情况,接收Master发送过来的资源指令,通过executorRunner启动程序分配任务,worker就类似于包工头,管理分配新进程,做计算的服务,相当于process服务,需要注意的是:
- 1)worker会不会汇报当前信息给master?Worker心跳给master主要只有workid,不会以心跳的方式发送资源信息给master,这样master就知道worker是否存活,只有故障的时候才发送资源信息。
- 2)Worker会不会运行代码?具体运行的是executor。可以运行具体application斜的业务逻辑代码,操作代码的节点,不会去运行代码。
16、RDD的创建有哪几种方式?
- 1)使用程序中的集合创建RDD
- 2)使用本地文件系统创建RDD
- 3)使用hdfs创建RDD
- 4)基于数据库db创建RDD
- 5)基于Nosql创建RDD
- 6)基于s3创建RDD
- 7)基于数据流,如socket创建RDD
16、列举你常用的action?
collect, reduce, take, count, asveAsTextFile等。
二、spark要点
1、Spark shuffle时,是否会在磁盘上存储
会
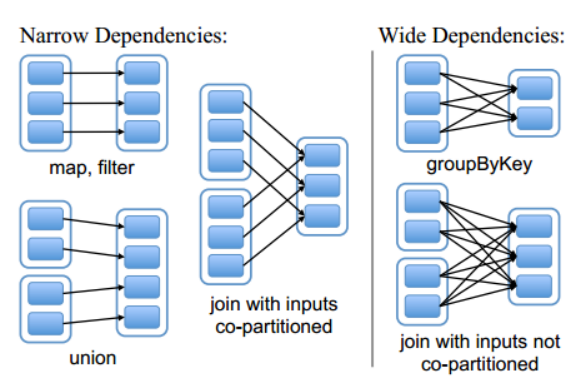
2、谈谈spark中的宽窄依赖
宽依赖:指的是多个子RDD的Partition会依赖于同一个父RDD的Partition,关系是一对多,父RDD的一个分区的数据去到了子RDD的不同分区里面,会有shuffle产生。
窄依赖:指的是每一个父的Partition最多被子RDD的一个Partition使用,是一对一的,也就是父RDD的一个分区去到了子RDD的一个分区中,这个过程没有shuffle产生。
分区的标准就是看父RDD的一个分区的数据流的流向,要是流向一个partition的话就是窄依赖,否则就是宽依赖,如图所示:
3、spark中如何划分stage
stage的概念:spark任务会根据RDD之间的依赖关系,形成一个DAG有向无环图,DAG会提交给DAGScheduler,DAGScheduler会把DGA划分互相依赖的多个stage,划分依据就是宽窄依赖,遇到宽窄依赖就划分stage,每个stage包含一个或多个task,然后将这些task以taskSet的形式提交给TaskScheduler运行,stage是由一组并行的task组成。
- 1)spark程序中可以因为不同的action触发众多的job,一个程序中可以有很多的job,每一个job是由一个或者多个stage构成的,后面的stage依赖于前面的stage,也就是说只有前面以来的stage计算完毕后,后面的stage才会运行;
- 2)Stage的划分标准就是宽窄依赖:何时产生宽依赖就会产生一个新的stage,例如reduceByKey,groupByKey,join的算子,会导致宽依赖的产生;
- 3)切割规则:从后往前,遇到宽依赖就切割stage。
- 4)图例:

4、spark中cache和persist的区别
cache:缓存数据,默认是缓存在内存中,其本质还是调用persist。
persist:缓存数据,有丰富的数据缓存策略。。数据可以保存在内存中也可以保存磁盘中,使用的时候指定对应的缓存级别就可以了。
5、spark中的数据倾斜的现象,原因,后果
-
1)数据倾斜的现象:
多数task执行速度较快,少数task执行时间非常长,或者等待很长时间后提示你内存不足,执行失败。 -
2)数据倾斜的原因:
数据问题:key本身分布不均匀(包括大量的key为空);key的设置不合理。
Spark使用问题:shuffle时的并发度不够;计算方式有误。 -
3)数据倾斜的后果:
spark中的stage的执行时间受限于最后那个执行完成的task,因此运行缓慢的任务会拖垮整个程序运行的速度(分布式程序运行的速度是由最慢的那个task决定的)。
过多的数据在同一个task中运行,会把executor撑爆。
6、spark数据倾斜的处理
发生数据倾斜的时候,不要急于提高executor的资源,修改参数或是修改程序,首先要检查数据本身,是否存在异常数据。
(一)数据问题造成的数据倾斜
-
1)找出异常的key值
a.如果任务长时间卡在最后一个或最后几个任务,首先要对key进行抽样分析,判断是哪些key造成的。选取key,对数据进行抽样,统计出现的次数,根据出现的次数大小排列数前几个。
b.比如:df.select(“key”).sample(false,0.1).(k=>(k,1)).reduceBykey(+).map(k=>(k._2,k._1)).sortByKey(false).take(10)
c.如果发现多数数据分布都较为均匀,二个别数据比其他数据大上若干个数量级,则说明发生了数据倾斜。 -
2)经过分析,倾斜的数据主要有以下三种情况:
a.null(空值)或是一些无意义的信息()之类的,大多是这个原因引起。
b.无效数据,大量重复的测试数据或是对结果影响不大的有效数据。
c.有效数据,业务导致的正常数据分布。 -
3)解决办法:
a.第1,2种情况,直接对数据进行过滤即可(因为该数据对当前业务不会产生影响)。
b.第3种情况则需要进行一些特殊操作,常见的有以下几种做法 :
(1) 隔离执行,将异常的key过滤出来单独处理,最后与正常数据的处理结果进行union操作。
(2) 对key先添加随机值,进行操作后,去掉随机值,再进行一次操作。
(3) 使用reduceByKey 代替 groupByKey(reduceByKey用于对每个key对应的多个value进行merge操作,最重要的是它能够在本地先进行merge操作,并且merge操作可以通过函数自定义.)
(4) 使用map join。
(二)spark使用不当造成的数据倾斜
-
1)提高shuffle并行度
a. DataFrame和sparkSql可以设置spark.sql.shuffle.partitions参数控制shuffle的并发度,默认为20.
b. RDD操作可以设置spark.default.parallelism控制并发度,默认参数头不同的ClusterManager控制。
c. 局限性:只是让每个task执行更少的不同的key。无法解决个别key特别大的情况造成的倾斜,如果某些key的大小非常大,即使一个task单独执行它,也会受到数据倾斜的困扰。 -
2)使用map join 代替 reduce join
a. 在校表不是特别大(取决于你的executor大小)的情况下使用,可以使程序避免shuffle的过程,自然也就没有数据倾斜的困扰了。
b. 局限性:因为先是将小数据发送到每个executor上,所以数据量不能太大。
7、spark有哪些聚合类的算子,我们应该避免什么类型的算子?
在我们的开发过程中,能避免则尽可能避免使用reduceByKey,join,distinct,repartition等会进行shuffle的算子,尽量使用map类的非shuffle算子。这样的话,没有shuffle操作或者仅有较少shuffle操作的spark作业,可以大大减少性能开销。
8、spark并行度怎么设置比较合适
Spark并行度,每个core承载24个partition,如32个core,那么64128之间的并行度,也就是设置64~128怕热提提欧尼,并行度和数据规模无关,只和内存使用量和cpu使用时间有关。
9、spark中数据的位置是被谁管理的?
每个数据分片都对应具体物理位置,数据的位置是被blockManager管理,无论数据是在磁盘、内存还是tacyan,都是有blockManager管理。
10、spark数据本地性有哪几种?
-
PROCESS_LOCAL是指读取缓存在本地节点的数据。
-
NODE_LOCAL是指读取本地节点硬盘数据。
-
ANY是指读取非本地节点数据。
-
通常读取数据PROCESS_LOCAL>NODE_LOCAL>ANY,尽量使用数据以PROCESS_LOCAL或NODE_LOCAL方式读取。其中PROCESS_LOCAL还和cache有关,如果RDD经常用的话将该RDD cache到内存中,注意,由于cache是lazy的,所以必须要通过一个action的触发,才能真正的将该RDD cache到内存中。
11、RDD有几种操作类型?
-
1)transformation,进行数据状态的转换,对已有的RDD创建新的RDD。
-
2)action,触发具体的作业,对RDD最后取结果的一种操作。
-
3)crontroller,对性能效率和容错方面的支持。persist , cache, checkpoint。
12、spark如何处理不能被序列化的对象?
- 将不能被序列化的对象封装成object
13、collect功能是什么?底层是怎么实现的?
- Driver通过collect把集群中各个节点的内容收集过来汇总成结果,collect返回结果是Array类型的,collect把各个节点上的数据抓过来,抓过来的数据是Array型,collect对Array抓过来的结果进行合并,合并后Array中只有一个元素,是tuple类型(KV类型)的。
14、spark技术栈有哪些组件,每个组件都有什么功能,适合什么应用场景?
-
1)Spark core:是其它组件的基础,spark的内核,主要包含:有向循环图、RDD、Lingage、Cache、Broadcast等,并封装了底层通讯框架,是Spark的基础。
-
2)SparkStreaming是一个对实时数据流进行高通量、容错处理的流式处理系统,可以多多种数据源(如kafka、Flume、Twitter、Zero和TCP套接字)进行类似Map、Reduce和Join等复杂操作,将流式计算分解成一系列短小的批处理作业。
-
3)Spark sql:Shark是SparkSQL的前身,sparkSQL的一个重要特点是其能够统一处理关系表和RDD,是的开发人员可以轻松的使用SQL命令进行外部查询,同时进行更复杂的数据分析。
-
4)BlinkDB:是一个用于在海量数据上运行交互式SQL查询的大规模并行查询引擎,它允许用户通过权衡数据精度来提升查询响应时间,其数据的精度被控制在允许的误差范围内。
-
5)MLBase是Spark生态圈的一部分专注于机器学习,让机器学习的门槛更低,让一些并不了解机器学习的用户也能方便使用MLbase。MLbase分为四部分:MLlib,MLI,ML Qptimizer和MLRuntime。
-
6)GraphX是Spark中用于图河图并行计算。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号