

一文彻底搞懂BERT
一文彻底搞懂BERT
一、什么是BERT?
没错下图中的小黄人就是文本的主角Bert ,而红色的小红人你应该也听过,他就是ELMo。2018年发布的BERT 是一个 NLP 任务的里程碑式模型,它的发布势必会带来一个 NLP 的新时代。BERT 是一个算法模型,它的出现打破了大量的自然语言处理任务的记录。在 BERT 的论文发布不久后,Google 的研发团队还开放了该模型的代码,并提供了一些在大量数据集上预训练好的算法模型下载方式。Goole 开源这个模型,并提供预训练好的模型,这使得所有人都可以通过它来构建一个涉及NLP 的算法模型,节约了大量训练语言模型所需的时间,精力,知识和资源。BERT模型的全称是:BERT(Bidirectional Encoder Representations from Transformers)。从名字中可以看出,BERT模型的目标是利用大规模无标注语料训练、获得文本的包含丰富语义信息的Representation。

二、Bert模型原理
-
BERT模型简介
BERT BASE: 与OpenAI Transformer 的尺寸相当,以便比较性能。
BERT LARGE: 一个非常庞大的模型,是原文介绍的最先进的结果。
BERT的基础集成单元是Transformer的Encoder。关于Transformer的介绍可以阅读Paper--Attention is All You Need。

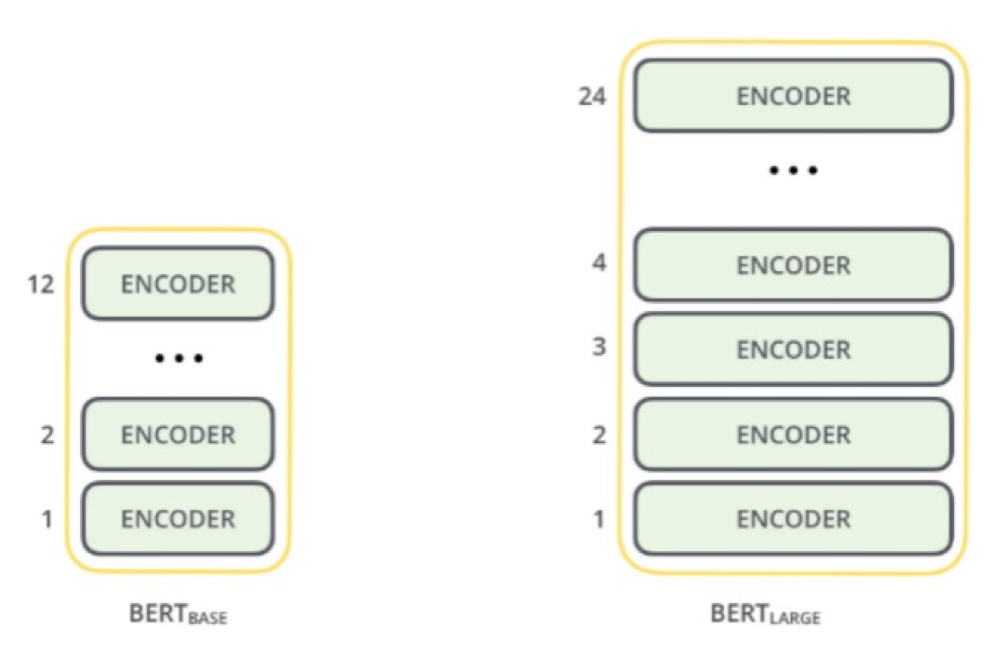
2 个 BERT 的模型都有一个很大的编码器层数,(论文里面将此称为 Transformer Blocks) - 基础版本就有 12 层,进阶版本有 24 层。同时它也有很大的前馈神经网络 ( 768 和 1024 个Hidden units),还有很多 Attention heads(12和16 个)。这超过了 Transformer 论文中的参考配置参数(6 个编码器层,512 个隐藏层单元,和 8 个注意头)。在我们平时实际使用bert的过程中一般只会使用Bert-base,因为Bert模型的太大了,庞大的参数一般人的电脑配置难以驾驭,当然有TPU的土豪除外...
-
模型的输入和输出
BERT模型的主要输入是文本中各个词的原始词向量,该向量既可以随机初始化,也可以利用Word2Vector等算法进行预训练以作为初始值;输出是文本中各个词融合了全文语义信息后的向量表
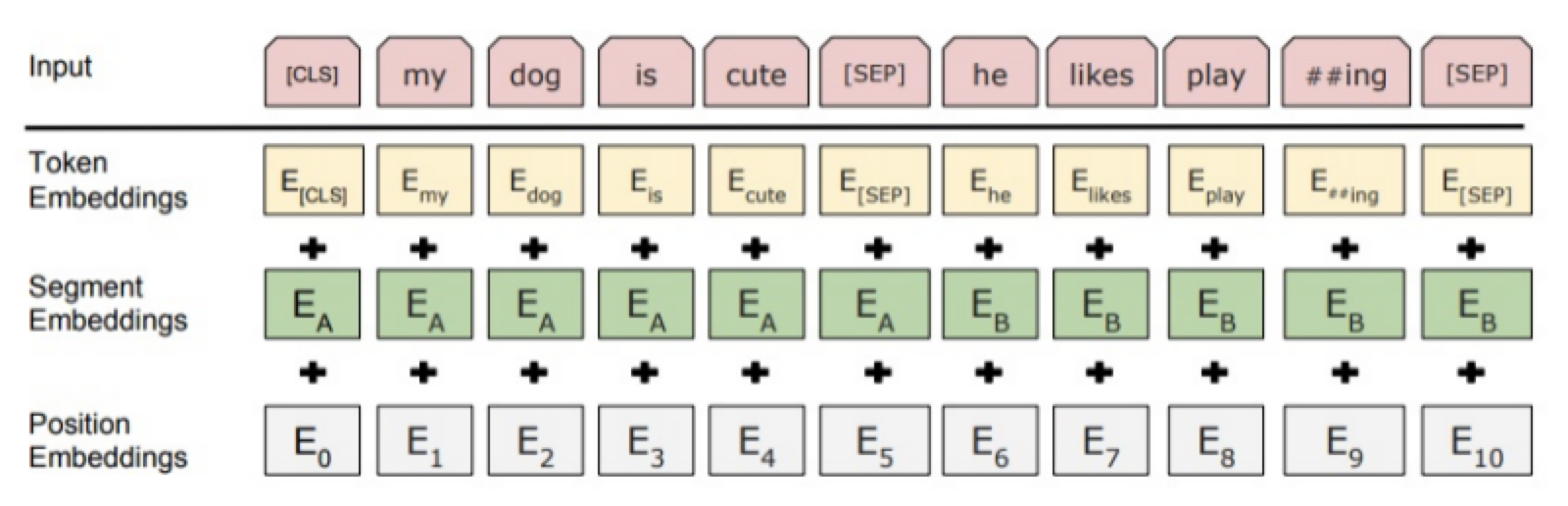
从上图中可以看出,BERT模型的输入具体分为三种信息:
Token Embeddings:是每个词的词向量,第一个单词是[CLS] Token,其取值在模型训练过程中自动学习,用于刻画文本的全局语义信息,可以用于之后的分类任务。[SEP] Token是用来分割输入的两条句子。
Segment Embeddings:用来区别两种句子(是否是正常顺序的两个句子),因为Bert预训练不光做MLM还要做以两个句子为输入的分类任务。
Position Embeddings:由于出现在文本不同位置的词所携带的语义信息存在差异(比如:“我爱你”和“你爱我”),因此,BERT模型对不同位置的词分别附加一个不同的向量以作区分。
特别地,在目前的BERT模型中,文章作者还将英文词汇作进一步切割,划分为更细粒度的语义单位(WordPiece),例如:将playing分割为play和ing;此外,对于中文,目前作者尚未对输入文本进行分词,而是直接将单个字作为构成文本的基本单位。输出是文本中各个词融合了全文语义信息后的向量表示。
-
模型的预训练任务
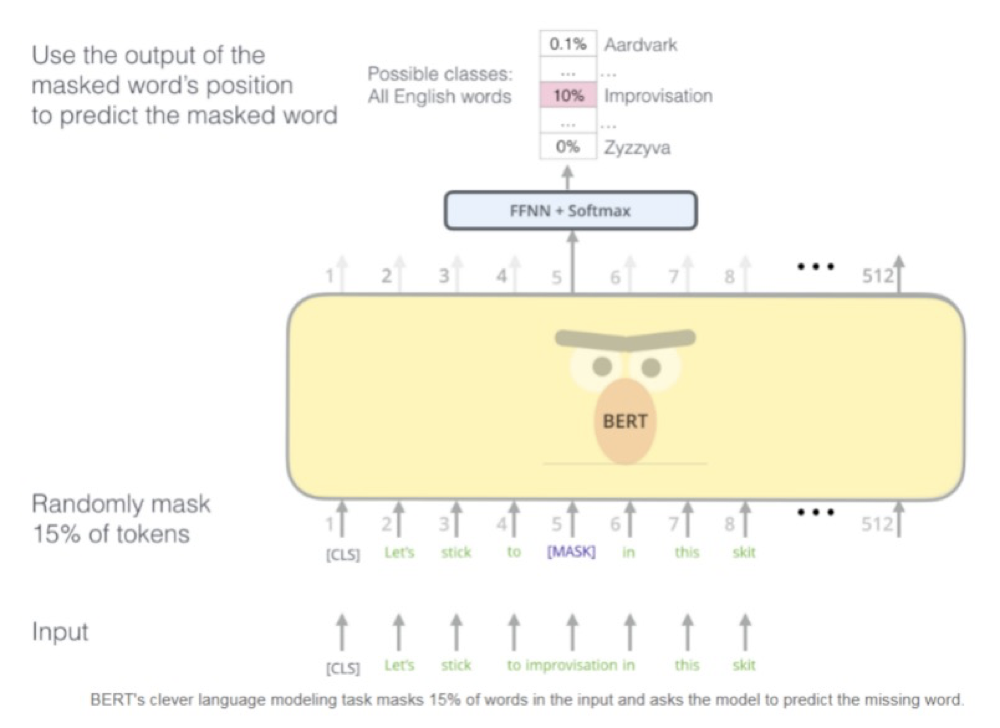
1) Task 1#: Masked Language Model
为了达到真正的bidirectional的LM的效果,作者创新性的提出了Masked LM,如下图所示,简单来说就是将句子中的一部分词mask掉,然后让模型去预测被mask掉的词(可以理解为我们大家初中都做过的完形填空)。这样有个缺点是在预训练的过程中把一些词mask起来,但是未来的fine tuning过程中的输入是没有mask的,这样模型有可能没见过这些词。这个量积累下来还是很大的。在训练过程中作者随机mask 15%的token,而不是把像CBOW一样把每个词都预测一遍。最终的损失函数只计算被mask掉那个token(其实这样也会导致一个问题就是训练的效率会比较低,因为每次反向传播只能计算15%的词)。Mask具体如何做也是有技巧的,前面说过如果全部用标记[MASK]代替会影响模型的fine tuning,所以作者mask的时候10%的单词会被随机替代成其他单词,还有10%的单词保持不变,剩下80%才被替换为[MASK] token。要注意的是Masked LM预训练阶段模型是不知道真正被mask的是哪个词,所以模型每个词都要关注。因为序列长度太大(512)会影响训练速度,所以90%的steps都用seq_len=128训练,余下的10%步数训练512长度的输入。
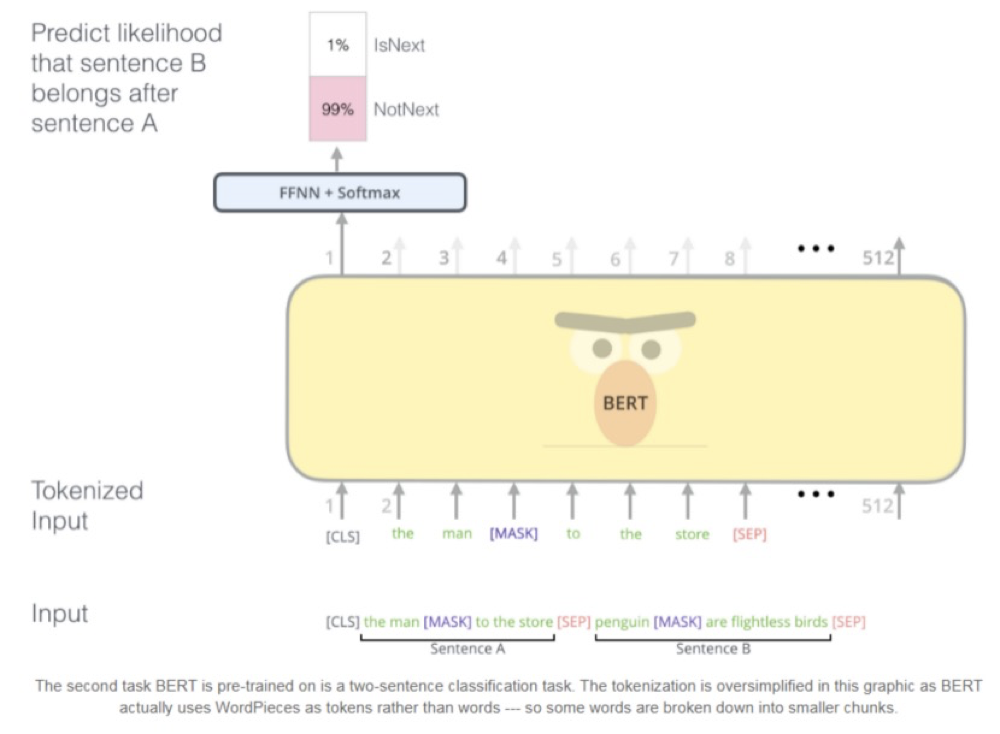
2) Task 2#: Next Sentence Prediction
Next Sentence Prediction的任务可以解释为:给定一篇文章中的两句话,判断第二句话在文本中是否紧跟在第一句话之后,目的是让模型理解两个句子之间的联系,如下图所示。将一篇文章的各段打乱,让我们通过重新排序把原文还原出来,这其实需要我们对全文大意有充分、准确的理解。Next Sentence Prediction任务实际上就是段落重排序的简化版:只考虑两句话,判断是否是一篇文章中的前后句。在实际预训练过程中,作者从文本语料库中随机选择50%正确语句对和50%错误语句对进行训练,与Masked LM任务相结合,让模型能够结合上下文预料更准确地表示每个词和句子的语义信息。
-
模型Fine tuning
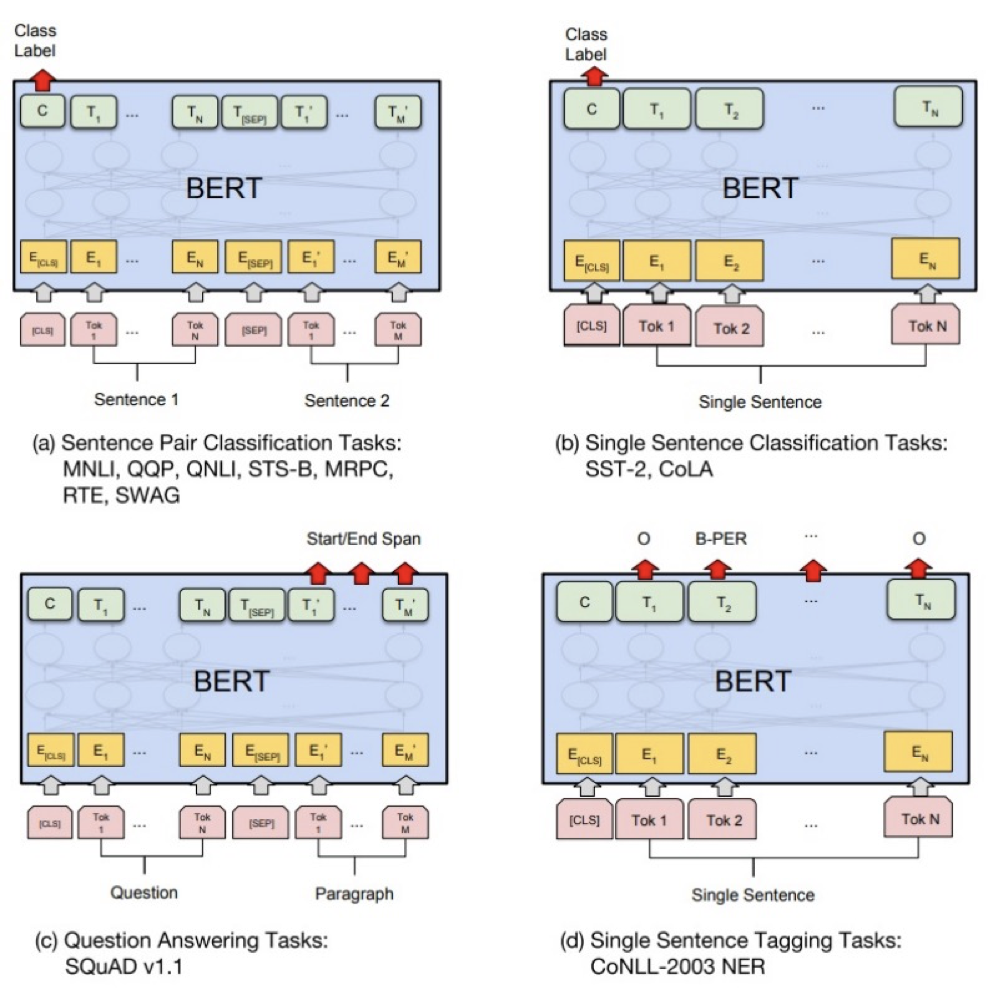
Bert的fine-tuning之前对模型的修改非常简单,如果做Sentence pair classification 任务,那么就两句话一起输入例如:[CLS]我喜欢吃苹果[SEP]你喜欢吃梨子,最后取第一个token [CLS]的输出表示,喂给一个softmax层得到分类结果输出。Single sentence classification 就更简单,也是输入一句话,然后取第一个token [CLS]的输出来进行分类。对于Q&A问题着同时输入[CLS]Question[SEP]Answer,然后取输出的Answer中Start和End之间即为答案。对于Single sentence tagging tasks(NER),取所有token的最后层transformer输出,喂给softmax层做分类。总之不同类型的任务需要对模型做不同的修改,但是修改都是非常简单的,最多加一层神经网络即可。如下图所示:
三、总结
Bert的优点:BERT是截至2018年10月的最新state of the art模型,通过预训练和精调横扫了11项NLP任务,这首先就是最大的优点了。而且它还用的是Transformer,也就是相对基于RNN的模型Bert更加高效、能捕捉更长距离的依赖。对比起之前的预训练模型,它捕捉到的是真正意义上的bidirectional context信息。
Bert的缺点:主要就是MLM预训练时的mask问题,[MASK]标记在实际预测中不会出现,训练时用过多[MASK]会影响模型在fine tuning的下游任务上帝的表现;每个batch只有15%的token被预测,所以BERT收敛得比left-to-right模型要慢(它们会预测每个token)。全文读下来你会发现其实Bert也没有我们想象中的那么神奇,但是实际中Bert却是如此的强大,其中重要的原因也是Google拥有庞大的语料库(钱)来进行训练,当然TPU(钱)也是必不可少的。
论文地址:https://arxiv.org/pdf/1810.04805
代码地址(TensorFlow和Pytorch两个版本):
https://github.com/google-research/bert
https://github.com/huggingface/pytorch-pretrained-BERT

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步