RUST入门.md
RUST入门
Hello World
mkdir -p projects/hello_world/
cd projects/hello_world
main.rs文件
fn main() {
let penguin_data = "\
common name,length (cm)
Little penguin,33
Yellow-eyed penguin,65
Fiordland penguin,60
Invalid,data
";
let records = penguin_data.lines();
for (i, record) in records.enumerate() {
if i == 0 || record.trim().len() == 0 {
continue;
}
let fields: Vec<_> = record
.split(",")
.map(|field| field.trim())
.collect();
if cfg!(debug_assertions) {
eprintln!("debug: {:?} -> {:?}", record, fields);
}
let name = fields[0];
if let Ok(length) = fields[1].parse::<f32>() {
println!("{}, {}cm", name, length);
}
}
}
编译和运行
rustc main.rs
./main
格式化:rustfmt
文档
安装Rust的同时也会在本地安装一个文档服务: 运行 rustup doc 让浏览器打开本地文档。
Cargo
Cargo 是 Rust 的构建系统和包管理器。
hello
构建如下:
-
cargo new hello_world --bin--bin为默认参数,表示构建二进制程序。可选--lib表示构建库。nsfoxer@nsfoxer-pc ~/temp> cargo new hello_world --bin Created binary (application) `hello_world` package nsfoxer@nsfoxer-pc ~/temp> tree hello_world hello_world ├── Cargo.toml └── src └── main.rs 1 directory, 2 filescargo会同时构建git项目。使用
--vcs none禁用git存储。 -
编译:
cargo build将获取所有依赖项。
nsfoxer@nsfoxer-pc ~/t/hello_world> tree . . ├── Cargo.lock ├── Cargo.toml ├── src │ └── main.rs └── target ├── CACHEDIR.TAG └── debug ├── build ├── deps │ ├── hello_world-efb3cc30327658a6 │ └── hello_world-efb3cc30327658a6.d ├── examples ├── hello_world ├── hello_world.d └── incremental └── hello_world-2bu9x4t5793bs ├── s-g1qy781nco-1nkogqh-2hbtkajf7iavr │ ├── 1afbzx1y0x1dbpio.o │ ├── 1ko7w99wy4kz2chh.o │ ├── 28cobucdo6rhinaa.o │ ├── 2goevba305ege8v6.o │ ├── 4d0psjpawt67vlja.o │ ├── 5byta3abs29cbrhj.o │ ├── 5dygtqqmhu41ip90.o │ ├── dep-graph.bin │ ├── gfq0hw1bwbsq84d.o │ ├── query-cache.bin │ └── work-products.bin └── s-g1qy781nco-1nkogqh.lock 9 directories, 20 filesCargo.lock包含依赖相关信息。使用--release开启编译优化。Caogo.toml包含项目的各种元信息。 -
运行:
./target/debug.hello_world
可以使用cargo run进行编译和运行。
可以使用cargo check进行代码检查。
目标
cargo允许Rust项目声明其各种依赖,并保证始终可重复构建。
- 引入两个含有各种信息的元数据文件;
- 获取并构建项目的依赖项;
- 调用
rustc或其他工具进行构建; - 使用 Rust 项目的约定(规范/风格)。
依赖
crates.io是 Rust 社区的中央存储库,用作发现和下载包的位置。cargo默认配置为,使用它来查找请求的包。
依赖来源地址:
- 基于rust官方仓库crates.io,通过版本说明来描述
- 基于项目源代码的git仓库地址,通过URL来描述
- 基于本地项目的绝对路径或者相对路径,通过类Unix模式的路径来描述
有一下写法:
[dependencies]
rand = "0.3"
hammer = { version = "0.5.0"}
color = { git = "https://github.com/bjz/color-rs" }
geometry = { path = "crates/geometry" }
添加依赖
[dependencies]
time = "0.1.12"
regex = "0.1.41"
cargo build将会获取依赖。如果regex在crates.io上更新了,在我们选择cargo update之前,我们仍会使用相同的版本进行构建.
文件布局
.
├── Cargo.lock
├── Cargo.toml
├── benches # 基准测试
│ └── large-input.rs
├── examples # 示例
│ └── simple.rs
├── src
│ ├── bin # 其他可执行文件
│ │ └── another_executable.rs
│ ├── lib.rs # 库文件
│ └── main.rs # 可执行文件
└── tests # 集成测试
└── some-integration-tests.rs
Carogo.toml && Carogo.lock
Cargo.toml是从广义上描述你的依赖,并由你编写.Cargo.lock包含有关您的依赖项的确切信息。它由 Cargo 维护,不应手动编辑.- 构建其他项目要依赖的库,请将
Cargo.lock放置在你的.gitignore - 构建可执行文件,如命令行工具或应用程序,请检查
Cargo.lock位于git管理下。
[dependencies]
rand = { git = "https://github.com/rust-lang-nursery/rand.git", rev = "9f35b8e" }
如上,依赖于github上的项目,当未指定其他信息时默认依赖github上的最新版本。例子中rev指定github的版本。
Cargo.lock会记录项目第一次构建时依赖版本,此时不需要进行手动添加加具体版本。
当我们准备选择,更新库的版本时,Cargo 会自动重新计算依赖关系,并为我们更新内容:
$ cargo update # updates all dependencies
$ cargo update -p rand # updates just “rand”
测试
cargo test:会查找src和tests的测试
通用编程
基本类型
-
整型
有符号 无符号 长度(字节) i8 u8 1 i16 u16 2 i32 (default) u32 4 i64 u64 8 i128 u128 16 isize usize arch 其中,isize表示与机器架构一致。
进制 示例 decimal 98_222 hex 0xff Octal 0o77 Binary 0b1110_0000 Byte(u8 only) b'A' 注:此处与c不同,byte属于整形,占位1字节。而char占位4字节。
-
浮点数
类型:
f32、f64现代CPU在32位和64位浮点数运算效率几乎一致。Rust默认使用64位浮点数。
f32,f64上的比较运算实现的是std::cmp::PartialEq特征(类似其他语言的接口), 但是并没有实现std::cmp::Eq特征。Rust的HashMap数据结构,是一个KV类型的hash map实现,它对于K没有特定类型的限制,但是要求能用作K的类型必须实现了std::cmp::Eq特征,因此这意味着你无法使用浮点数作为HashMap的Key。0.1 + 0.2 == 0.3 // 实际不相等 (0.1 + 0.2 - 0.3).abs() < 0.00001 // 可以使用这种方式进行替换 -
Nan
数学未定义的结果,例如
5/0,结果为Nan。NaN不能用来比较。 -
bool
值:
true和false,占位1字节。 -
字符
char:占位4字节,代表一个Unicode标量。 -
元类型
(): 唯一值也是() -
常量
const:const MAX_POINTS: u32 = 100_000 -
range序列
1..5; //生成 1-4 1..=5; // 生成 1-5 'a'..='z'; // 生成 a-z
let a = 10; // 编译器推断类型
let b: i32 = 20; // 指定类型i32
let mut c = 30i32; // 指定类型i32
let d = 20_i32; // 下划线指定类型i32
变量的”赋值“准确来说叫“绑定”,因为rust使用所有权机制。绑定意味着将一块内存对象绑定到一个变量名字上,其他变量不用有这块内存。
- 类型转换是显式的
- 数值上允许使用方法:
13.14_f32.round()
复合类型
-
元组
长度固定,不能改变长度大小。但内部类可以不一致。
let tup : (i32, f64, u8) = (500, 6.4, 1); // 类似ES6,模式匹配 解构 // 等价于 x = tup.0 // y = tup.1 // z = tup.2 let (x, y, z) = tup; // 使用 . 访问元祖 tup.0; tup.1; tup.2; // 可以在返回值的函数使用 fn calculate_length(s: String) -> (String, usize) { let lengrh = s.len(); (s, length) } -
数组
Rust的数组长度固定。内部类型也需要一致。
let a:[i32; 5] = {1, 2, 3, 4, 5} // 创建相同元素的数组 // 以下写法等价于 let a = [3, 3, 3, 3, 3] let a = [3; 5] // 数组访问 let first = a[0]; // 数组切片 let slice: &[i32] = &a[1..3];当访问数组越界时,程序会崩溃。rust内部包含了运行检查。
-
结构体
struct// 定义结构体 struct User { active: bool, username: String, email: String, sign_in_count: u64, } // 创建结构体 // 初始化实例要求每个字段都被初始化 let user1 = User { email: String::from("someone@example.com"), username: String::from("someusername123"), active: true, sign_in_count: 1, }; // 访问和修改结构体 // 只有整个结构体为mut时,才能修改其中的字段 let mut user2 = User {/*省略*/}; user.active = false; // 简化创建 // 当函数参数和结构体字段同名时,可以直接使用缩略的方式进行初始化,跟typescript中一模一样. fn build_user(email: String, username: String) -> User { User { email, username, active: true, sign_in_count: 1, } } // ..语法表明凡是我们没有显示声明的字段,全部从user1中自动获取。需要注意的是..user1必须在结构体的尾部使用。 let user2 = User { email: String::from("another@example.com"), ..user1 // user1的username字段无法使用,因内部username所有权转移到user2。但其他字段还能使用 }; user1.active; // 结构体数据所有权 // 可以让结构体从其他对象借用数据,但是需要使用生命周期,来确保结构体的作用范围要比它所借用的数据的作用范围要小。 #[derive(Debug)] struct User<'a> { // 添加生命周期 username: &'a str, email: &'a str, sign_in_count: u64, active: bool, } let user1 = User { email: "someone@example.com", username: "someusername123", active: true, sign_in_count: 1, }; println!("{:?}", user1); -
元祖结构体
结构体必须要有名称,但是结构体的字段可以没有名称,这种结构体长得很像元组,因此被称为元组结构体。
struct Color(i32, i32, i32); let black = Color(0, 0, 0); -
元结构体
定义一个类型,但是不关心该类型的内容, 只关心它的行为时,就可以使用
元结构体:struct AlwaysEqual; // 我们不关心为AlwaysEqual的字段数据,只关心它的行为,因此将它声明为元结构体,然后再为它实现某个特征 impl SomeTrait for AlwaysEqual { } -
枚举
// 创建枚举 enum PokerSuit { Clubs, Spades, Diamonds, Hearts, } // 枚举值 let heart = PokerSuit::Hearts; let diamond = PokerSuit::Diamonds; // 带值枚举 enum PokerCard { Clubs(u8), Spades(u8), Diamonds(u8), Hearts(u8), } // Option枚举用于处理空值 Option、Some、None均包含在prelude库中 enum Option<T> { Some(T), // 泛型 None, }
函数
Rust使用snake case进行命名,所有字母小写,以下划线分隔单词。
被调用函数定义在调用函数范围内即可。
fn main() {
another_function(5, 6);
}
fn another_function(x : i32, y : i32) {
println!("Another Funcion!");
}
函数参数必须显式声明,编译器由此不需要其他代码对参数类型进行推断。
rust是基于表达式(表达式是会计算并返回值;语句是只执行操作,但不返回值)
let x = 5; // 语句
let x = y = 6; // error
// 调用函数,调用宏,{}都是表达式
let y = {
let x = 3;
x + 1
} // y == 4
rust的函数返回值,等价于最后一个表达式的返回值,可以隐式返回:
fn five() -> i32 {
5
}
永不返回函数 !
fn dead_end() -> ! {
loop {
// 永不返回
}
}
控制流
-
if表达式
条件表达式必须产生一个bool值。
let number = 5; if number < 5 { // .... } else { // ..... } if number { // error, rust不会将非bool类型转换为bool类型 }if是一个表达式,可以直接生成值。但每条分支返回值类型应该相同。
let condition = true; let number = if condition { 5 } else if somthing{ 6 } else { "seven" // error, 返回值类型不同 }; -
loop
可以在将
break后的值,作为返回值let mut counter = 0; let result = loop { counter += 1; if counter == 10 { break counter * 10; // 返回一个100,类似return } }; -
while
-
continue
跳过本次循环
-
break
结束循环,可以带值,类似return
-
for
使用for进行迭代
let a = [10;9]; for element in a.iter() { println!("{}", elment); }使用
for时我们往往使用集合的引用形式,如果不使用引用的话,所有权会被转移到for语句块中,后面就无法再使用这个集合了.// 所有权转移到item 等价于 IntoIterator::into_iter(container) for item in container { // ... } // 之后,container还可使用 等价于 container.iter() for item in &container { // ... } // 可以修改元素 d等价于 container.iter_mut() for item in &mut container { // ... }可以在循环中同时获取元素索引:
let a = [1, 2, 3, 4]; for (i, v) in a.iter().enumerate() { /* ... */}
所有权
基本规则
- 每个值都有一个对应的变量作为其所有者
- 在同一时间内,有且只有一个所有者
- 当所有者离开其作用域时,其持有的值就会被释放
变量使用的内存在变量本身离开作用域后自动进行释放,(调用drop()的特殊函数)。为避免二次内存释放,rust在变量被移动时(复制到其他变量),将把此变量废弃,不再使用。rust不会自动深度拷贝,任何自动的赋值操作都可以被认为是高效的。
深度拷贝使用clone()方法。
拥有Copy的trait的变量类型赋值不会被废弃:所有整型 bool char 浮点型 内部字段全可Copy的元组
引用和借用
当变量赋值时,所有权就转移。当希望调用函数保留参数的所有权,必须将参数返回。
fn main() {
let s1 = String::from("ADMIN");
let (s2, len) = calculate_length(s1); // s2想保留s1的所有权,必须将s1返回,否则函数参数s获得s1的所有权,在函数结束后,s离开作用范围,内存被释放。
println!("The length of '{}' is {}.", s2, len);
}
fn calculate_length(s:String) -> (String, usize) {
let length = s.len();
return (s, length);
}
引用允许在不获得所有权下,使用值。
fn main() {
let s1 = String::from("ADMIN");
let len = calculate_length(&s1);
println!("The length of '{}' is {}.", s1, len);
}
fn calculate_length(s:&String) -> usize {
s.len() // s不会销毁s1的数据,因为s没有所有权
}
引用默认是不可变的,不能修改值。
可变引用
添加mut来接收可变引用。
fn main() {
let mut s1 = String::from("ADMIN");
add_string(&mut s1);
println!("The length of '{}' is {}.", s1, s1);
}
fn add_string(s : &mut String) {
s.push_str(" World!");
}
可变引用的限制:特定作用域的特定数据,一次只能声明一个可变引用。可以多次普通引用,但不能在有可变引用的情况下,再次普通引用。(类似于读写锁,可以同时有多个读,但是只能有一个写)
let mut s = "admin";
let r1 = &mut s;
let r2 = &mut s; // 错误,多次引用可变
悬垂引用:悬垂指针,指针指向某一内存,但此内存在其他地方被释放。rust使用生命周期防止悬垂引用。
字符串和切片
字符串
- 浅拷贝
- 深拷贝 (使用
clone可以进行深拷贝)
Copy
如果一个类型拥有 Copy特征,一个旧的变量在被赋值给其他变量后仍然可用。
let x = 5;
let y = x; // x仍可用
任何基本类型的组合可以是 Copy 的,不需要分配内存或某种形式资源的类型是 Copy 的。如下是一些 Copy 的类型:
- 所有整数类型,比如
u32。 - 布尔类型,
bool,它的值是true和false。 - 所有浮点数类型,比如
f64。 - 字符类型,
char。 - 元组,当且仅当其包含的类型也都是
Copy的时候。比如,(i32, i32)是Copy的,但(i32, String)就不是。
字符串切片
fn main() {
let s1 = String::from("ADMIN WORLD JKL");
println!("{}", frist_word(&s1));
}
fn frist_word(s: &String) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
return &s[..];
}
let a = [1, 2, 3, 4, 5];
let slice = &a[1..3];
在对字符串使用切片语法时需要格外小心,切片的索引必须落在字符之间的边界位置,也就是UTF8字符的边界:
let s = "中国人";
let a = &s[0..2];
println!("{}",a); // 错误,一个中文占用三个字节,因此没有落在边界处,也就是连中字都取不完整,此时程序会直接崩溃退出
字符串字面量是切片
let s = "hello";
let s1: &str = "hello";
字符串相加
+相当于add: fn add(self, s: &str) -> String{}
let s1 = String::from("hello, ");
let s2 = String::from("world!");
let s3 = s1 + &s2; // s1所有权移动到s3上
String和&str的转换
-
&str转String:String::from("hello")"hello".to_string() -
String转&str:/** * 以下使用deref隐式强制转换 */ let s = String::from("hello"); // String &s; // &str &s[..]; // &str s.as_str(); // &str
字符串索引
let s1 = String::from("hello");
let h = s1[0]; // 错误, 不允许
字符串的底层的数据存储格式实际上是[u8],一个字节数组。对于let hello = String::from("Hola");这行代码来说,hello的长度是4个字节,因为"hola"中的每个字母在UTF8编码中仅占用1个字节。而对于"汉字"这种类型,实际上是9个字节的长度,因为每个汉字在UTF8中的长度是3个字节,因此这种情况下对hello进行索引 访问&hello[0]没有任何意义。
还有一个原因导致了Rust不允许去索引字符:因为索引操作,我们总是期望它的性能表现是O(1),然而对于String类型来说,无法保证这一点,因为Rust可能需要从0开始去遍历字符串来定位合法的字符。
操作UTF8字符串
// 字符
for c in "汉字".chars() {
print!("{}",c);
}
println!();
// 字节
for c in "汉字".bytes() {
print!("{}",c);
}
// 输出
/**
汉, 字,
230, 177, 137, 229, 173, 151, %
*/
结构体
// 添加debug来使用 {:?} debug输出
#[derive(Debug)]
struct User {
username: String,
email: String,
active: bool,
sign_in_count: u64,
}
// 结构体的方法,可以有多个impl
impl User {
fn build_user(email:String, username: String) -> User {
User {
email,
username,
active: true,
sign_in_count: 1,
}
}
}
impl User {
// 方法,第一个参数永远是self,一般为引用类型,直接self一般用于强转类型
fn add_sign(& mut self, number: u64) {
self.sign_in_count += number;
}
}
fn main() {
// 定义user1,字符串来自String方法,否则错误。
let user1 = User::build_user(String::from("ex.@email.org"), String::from("example"));
let mut user2 = User {
email: String::from("test@q.org"),
username: String::from("test2"),
..user1 // 此处为简写,类似JavaScript中的ES6语法: 同名直接赋值
};
user2.add_sign(32);
println!("user1: {:?}", user1);
println!("user2: {:?}", user2);
// 结构元祖
struct Color(i32, i32, i32);
struct Point(i32, i32, i32);
// black 和 origin不能相互赋值,因为类型不同
let mut black = Color(0, 0, 0);
let mut origin = Point(0, 0, 0);
}
枚举enum和模式匹配match
match
enum Coin {
Penny,
Nickel,
Dime,
Quarter,
}
// 表达式赋值
let a = match coin {
Coin::Penny => {
println!("Lucky penny!");
1
},
Coin::Nickel => 5,
Coin::Dime => 10,
Coin::Quarter => 25,
};
// 模式绑定
fn value_in_cents(coin: Coin) -> u8 {
match coin {
Coin::Penny => 1,
Coin::Nickel => 5,
_ => (), // _ 通配符
Coin::Quarter(state) => {
println!("State quarter from {:?}!", state);
25
},
}
}
有时只想使用一个模式的值,可以使用if let
// 需要_通配符
let v = Some(3u8);
match v{
Some(3) => println!("three"),
_ => (),
}
// 可以直接使用if let
if let Some(3) = some_u8_value {
println!("three");
}
matches!宏
enum
#[derive(Debug)]
// 枚举可以和相关数据直接关联
enum Message {
Quit, // 没有关联任何数据
Move{x: i32, y: i32}, // 包含匿名结构体
Write(String), // 包含String
ChangeColor(i32, i32, i32), // 包含三个i32
}
fn main() {
let msg = Message::ChangeColor(0, 0, 0);
println!("msg {:?}", msg);
}
// if let往往用于匹配一个模式,而忽略剩下的所有模式的场景
if let PATTERN = SOME_VALUE {
}
// while let 只要模式匹配就一直进行 while 循环
// Vec是动态数组
let mut stack = Vec::new();
// 向数组尾部插入元素
stack.push(1);
stack.push(2);
stack.push(3);
// stack.pop从数组尾部弹出元素
while let Some(top) = stack.pop() {
println!("{}", top);
}
@绑定
@(读作at)运算符允许为一个字段绑定另外一个变量。
enum Message {
Hello { id: i32 },
}
let msg = Message::Hello { id: 5 };
match msg {
// @将值绑定到id_variable
Message::Hello { id: id_variable @ 3..=7 } => {
println!("Found an id in range: {}", id_variable)
},
// 获取不到值
Message::Hello { id: 10..=12 } => {
println!("Found an id in another range")
},
Message::Hello { id } => {
println!("Found some other id: {}", id)
},
}
Option
rust处理空值使用枚举Option处理,Option也会被预导入,定义为:
enum Option<T> {
Some(T),
None
}
fn main() {
let x: i8 = 8;
let y: Option<i8> = Some(9);
// error! x 和 y 类型不同
let sum = x + y;
}
match
#[derive(Debug)]
enum A {
Alibaba,
Tencent,
Baidu,
}
enum B {
US,
CN,
Coo(A), // 将Coo绑定一个A枚举
}
fn main() {
let t = B::Coo(A::Alibaba);
let value = match t {
B::US => 1000,
B::CN => 2000,
B::Coo(coo) => {
println!("coo: {:?}", coo);
20
},
};
println!("value: {:?}", value);
// println!("t: {:?}", t);
}
模式匹配必须匹配完所有类型,可以使用通配符_代替其他所有值。
可以使用if let 来简单控制。
泛型
特征trait
Trait特征类似接口,是把一些方法组合在一起,目的是定义一个实现某些目标所必需的行为的集合。
pub struct Post {
pub title: String, // 标题
pub author: String, // 作者
pub content: String, // 内容
}
// 定义特征
pub trait Summary {
fn summarize(&self) -> String; // 使用;结尾
}
// 实现特征
impl Summary for Post {
}
包管理
模块系统:
- 包
package: 一个Cargo提供的feature,可以用来构建、测试和分享包 - 单元包
crate: 一个由多个模块组成的树形结构,可以作为三方库进行分发,也可以生成可执行文件进行运行 - 模块
module: 可以一个文件多个模块,也可以一个文件一个模块,模块可以被认为是真实项目中的代码组织单元 - 路径
path
Package
Package就是一个项目,因此它包含有独立的Cargo.toml文件, 以及因为功能性被组织在一起的一个或多个包。一个package只能包含一个库(library)类型的包, 但是可以包含多个二进制可执行类型的包。
-
二进制:
cargo new projectsrc/main.rs是二进制包的根文件,该二进制包的包名跟所属package相同
-
库
libarary:cargo new my-test --lib
Ppackage 是一个项目工程,而包只是一个编译单元,基本上也就不会混淆这个两个概念了:src/main.rs 和 src/lib.rs 都是编译单元,因此它们都是包。
一个真实项目中典型的 Package,会包含多个二进制包,这些包文件被放在 src/bin 目录下,每一个文件都是独立的二进制包,同时也会包含一个库包,该包只能存在一个 src/lib.rs:
.
├── Cargo.toml
├── Cargo.lock
├── src
│ ├── main.rs
│ ├── lib.rs
│ └── bin
│ └── main1.rs
│ └── main2.rs
├── tests
│ └── some_integration_tests.rs
├── benches
│ └── simple_bench.rs
└── examples
└── simple_example.rs
- 唯一库包:
src/lib.rs - 默认二进制包:
src/main.rs,编译后生成的可执行文件与package同名 - 其余二进制包:
src/bin/main1.rs和src/bin/main2.rs,它们会分别生成一个文件同名的二进制可执行文件 - 集成测试文件:
tests目录下 - 性能测试benchmark文件:
benches目录下 - 项目示例:
examples目录下
模块定义
mod front_of _house {
mod hosting {
fn add() {}
}
}
src/main.rs 和 src/lib.rs 被称为包根(crate root).
crate
└── front_of_house
├── hosting
│ ├── add_to_waitlist
│ └── seat_at_table
└── serving
├── take_order
├── serve_order
└── take_payment
路径
父模块完全无法访问子模块中的私有项,但是子模块却可以访问父模块、父父..模块的私有项。
模块引用 绝对路径和相对路径
pub fn eat() {
// 绝对路径
crate::front_of_house::hosting::add();
// 相对路径
front_of_house::hosting::add();
}
-
使用pub暴露路径
-
super类似..,上一级路径 -
使用
use导入路径 -
as重命名 -
pub use重导出
use std::fmt::Result;
use std::io::Result as IOResult;
use std::*;
结构体和枚举可见性
- 将结构体设置为
pub,但它的所有字段依然是私有的 - 将枚举设置为
pub,它的所有字段也将对外可见。枚举的成员如果对外不可见,那么枚举没有任何用处,所以默认是可见的。
优先使用最细粒度(引入函数、结构体等)的引用方式,如果引起了某种麻烦(例如前面两种情况),再使用引入模块的方式。(use)
集合类型
动态数组 Vector
动态数组要求类型一致。
// 创建
let v: Vec<i32> = Vec::new();
// 当预先知道元素个数时,可以指定空间大小,提升性能
Vec::with_capacity(capacity);
// 使用宏
let mut v = vec![1,2,3];
// 更新
v.push(1);
// 读取
let third: &i32 = &v[2];
match v.get(2) {
Some(third) => third,
None => /**/ ,
}
// 迭代
for i in &v {
//
}
for i in &mut i {
// 可修改
}
// 存储不同元素
// 枚举
#[derive(Debug)]
enum IpAddr {
V4(String),
V6(String)
}
fn main() {
let v = vec![ // 存储类型是 enum IpAddr
IpAddr::V4("127.0.0.1".to_string()),
IpAddr::V6("::1".to_string())
];
for ip in v {
show_addr(ip)
}
}
fn show_addr(ip: IpAddr) {
println!("{:?}",ip);
}
// 特征对象
trait IpAddr {
fn display(&self);
}
struct V4(String);
impl IpAddr for V4 {
fn display(&self) {
println!("ipv4: {:?}",self.0)
}
}
struct V6(String);
impl IpAddr for V6 {
fn display(&self) {
println!("ipv6: {:?}",self.0)
}
}
fn main() {
let v: Vec<Box<dyn IpAddr>> = vec![ // 存储类型 Box(dyn IpAddr)
Box::new(V4("127.0.0.1".to_string())),
Box::new(V6("::1".to_string())),
];
for ip in v {
ip.display();
}
}
HashMap
使用new创建,使用insert创建。
// 需要先导入
use std::collections::HashMap;
fn main() {
// 创建
let mut gems = HashMap::new();
// 插入
gems.insert("pig", 1);
gems.insert("dog", 2);
gems.insert("cat", 3);
// 固定容量,提升性能
let mut gems = HashMap::with_capacity(3);
// 使用迭代器和collect创建方法
let teams_list = vec![
("中国队".to_string(), 100),
("美国队".to_string(),100),
("日本队".to_string(),50),
];
let teams_map: HashMap<_, _> = teams_list.into_iter().collect();
println!("{:?}", teams_map);
// 查询
// get
let score: Option<&i32> = teams_map.get("XXX"); // 这里是借用,当不使用借用时,所有权可能会转移
// 循环
for (k, v) in &teams_map { // 注意这里是引用
/**/
}
// 更新 更新会覆盖原有值
let v = scores.entry("blue").or_insert(5); // 当不存在时,插入5 or_insert 返回了 &mut v 引用,因此可以通过该可变引用直接修改 map 中对应的值
}
所有权转移
HashMap 的所有权规则与其它 Rust 类型没有区别:
- 若类型实现
Copy特征,该类型会被复制进HashMap,因此无所谓所有权 - 若没实现
Copy特征,所有权将被转移给HashMap中
如果你使用引用类型放入HashMap中,请确保该引用的生命周期至少跟 HashMap 活得一样久。
HashMap 使用的哈希函数是 SipHash,它的性能不是很高,但是安全性很高。
类型转换
详见: Rust圣经
as : 当大值转换为小值时,可能会丢失。
常见的转换形式
-
一般
let a = 3.1 as i8; let b = 100_i8 as i32; let c = 'a' as u8; // 将字符转为整数 97 -
内存地址转为指针
let mut values: [i32;2] = [1, 2]; let p1: *mut i32 = values.as_mut_ptr(); let first_address = p1 as usize; // 将p1内存地址转换为一个整数 let second_address = first_address + 4; // i32占4个字节大小 let p2 = second_adress as *mut i32; // 第二个元素的指针 unsafe { *p2 += 1; } assert_eq!(values[1], 3); // 数组切片原生之间的转换,不会改变数组的内存占用大小 let a: *const [u16] = &[1, 2, 3, 4, 5]; let b = a as * const [u8]; assert_eq!(std::mem::size_of_val(&a), std::mem::size_of_val(&b)); // 转换不具有传递性 就算 e as U1 as U2 是合法的,也不能说明 e as U2 是合法的(e 不能直接转换成 U2)。
TryInto转换
tryInto可以捕获溢出转换。
use std::convert::TryInto;
let a: u8 = 10;
let b: u16 = 1400;
let b_:u8 = b.try_into().unwrap(); // 运行时异常?try_into 会尝试进行一次转换,如果失败,则会返回一个 Result
if a < b_ {
println!("Ten is less than one hundred.");
}
通用类型转换
强制类型转换
在某些情况下,类型允许隐式转换,这会弱化类型系统,但允许代码在大多数情况下工作,而不是编译报错。
点操作符
方法调用的点操作符看起来简单,实际上非常不简单,它在调用时,会发生很多魔法般的类型转换,例如:自动引用、自动解引用,强制类型转换直到类型能匹配等。
假设有一个方法 foo,它有一个接收器(接收器就是 self、&self、&mut self 参数)。如果调用 value.foo(),编译器在调用 foo 之前,需要决定到底使用哪个 Self 类型来调用。现在假设 value 拥有类型 T。
再进一步,我们使用完全限定语法来进行准确的函数调用:
- 首先,编译器检查它是否可以直接调用
T::foo(value),称之为值方法调用 - 如果上一步调用无法完成(例如方法类型错误或者特征没有针对
Self进行实现,上文提到过特征不能进行强制转换),那么编译器会尝试增加自动引用,以为着编译器会尝试以下调用:<&T>::foo(value)和<&mut T>::foo(value),称之为引用方法调用 - 若上面两个方法依然不工作,编译器会试着解引用
T,然后再进行尝试。这里使用了Deref特征 —— 若T: Deref<Target = U>(T可以被解引用为U),那么编译器会使用U类型进行尝试,称之为解引用方法调用 - 若
T不能被解引用,且T是一个定长类型(在编译器类型长度是已知的),那么编译器也会尝试将T从定长类型转为不定长类型,例如将[i32; 2]转为[i32] - 若还是不行,那...没有那了,最后编译器大喊一声:汝欺我甚,不干了!
下面我们来用一个例子来解释上面的方法查找算法:
let array: Rc<Box<[T; 3]>> = ...;
let first_entry = array[0];
array 数组的底层数据隐藏在了重重封锁之后,那么编译器如何使用 array[0] 这种数组原生访问语法通过重重封锁,准确的访问到数组中的第一个元素?
- 首先,
array[0]只是Index特征的语法糖:编译器会将array[0]转换为array.index(0)调用,当然在调用之前,编译器会先检查array是否实现了Index特征。 - 接着,编译器检查
Rc<Box<[T; 3]>>是否有否实现Index特征,结果是否,不仅如此,&Rc<Box<[T; 3]>>与&mut Rc<Box<[T; 3]>>也没有实现。 - 上面的都不能工作,编译器开始对
Rc<Box<[T; 3]>>进行解引用,把它转变成Box<[T; 3]> - 此时继续对
Box<[T; 3]>进行上面的操作 :Box<[T; 3]>,&Box<[T; 3]>,和&mut Box<[T; 3]>都没有实现Index特征,所以编译器开始对Box<[T; 3]>进行解引用,然后我们得到了[T; 3] [T; 3]以及它的各种引用都没有实现Index索引(是不是很反直觉:D,在直觉中,数组都可以通过索引访问,实际上只有数组切片才可以!),它也不能再进行解引用,因此编译器只能祭出最后的大杀器:将定长转为不定长,因此[T; 3]被转换成[T],也就是数组切片,它实现了Index特征,因此最终我们可以通过index方法访问到对应的元素。
逃避
mem::transmute<T, U>: 将类型T转换为类型U,要求两者内存占用一致mem::transmute_copy<T, U>: 将类型T内存数据直接复制到类型U上
返回和错误处理
Rust没有异常处理,一般错误分两类:
- 可恢复错误,通常用于从系统全局角度来看可以接受的错误,例如处理用户的访问、操作等错误,这些错误只会影响某个用户自身的操作进程,而不会对系统的全局稳定性产生影响
Result<T, E> - 不可恢复错误,刚好相反,该错误通常是全局性或者系统性的错误,例如数组越界访问,系统启动时发生了影响启动流程的错误等等,这些错误的影响往往对于系统来说是致命的
panic!
panic! 不可恢复
panic!("crash"); 使用RUST_BACKTRACE=1 cargo run将获取更详细信息。
thread 'main' panicked at 'called `Result::unwrap()` on an `Err` value: TryFromIntError(())', src/main.rs:7:31
stack backtrace:
0: rust_begin_unwind
at /rustc/59eed8a2aac0230a8b53e89d4e99d55912ba6b35/library/std/src/panicking.rs:517:5
1: core::panicking::panic_fmt
at /rustc/59eed8a2aac0230a8b53e89d4e99d55912ba6b35/library/core/src/panicking.rs:101:14
2: core::result::unwrap_failed
at /rustc/59eed8a2aac0230a8b53e89d4e99d55912ba6b35/library/core/src/result.rs:1617:5
3: core::result::Result<T,E>::unwrap
at /rustc/59eed8a2aac0230a8b53e89d4e99d55912ba6b35/library/core/src/result.rs:1299:23
4: hello_world::main
at ./main.rs:7:18
5: core::ops::function::FnOnce::call_once
at /rustc/59eed8a2aac0230a8b53e89d4e99d55912ba6b35/library/core/src/ops/function.rs:227:5
note: Some details are omitted, run with `RUST_BACKTRACE=full` for a verbose backtrace.
默认处理方式是栈展开,逆序调用,最后调用的函数在最上方。rust_begin_unwind函数就是打印栈信息。
两种处理方式:
-
栈展开 -
直接终止:不会清理数据,直接交由操作系统善后。# 在release下遇到panic直接终止 [profile.release] panic = 'abort'
线程panic后,main不会终止。
原理:
当调用 panic! 宏时,它会
- 格式化
panic信息,然后使用该信息作为参数,调用std::panic::panic_any()函数 panic_any会检查应用是否使用了panic hook,如果使用了,该hook函数就会被调用(hook是一个钩子函数,是外部代码设置的,用于在panic触发时,执行外部代码所需的功能)- 当
hook函数返回后,当前的线程就开始进行栈展开:从panic_any开始,如果寄存器或者栈因为某些原因信息错乱了,那很可能该展开会发生异常,最终线程会直接停止,展开也无法继续进行 - 展开的过程是一帧一帧的去回溯整个栈,每个帧的数据都会随之被丢弃,但是在展开过程中,你可能会遇到被用户标记为
catching的帧(通过std::panic::catch_unwind()函数标记),此时用户提供的catch函数会被调用,展开也随之停止:当然,如果catch选择在内部调用std::panic::resume_unwind()函数,则展开还会继续。
还有一种情况,在展开过程中,如果展开本身 panic 了,那展开线程会终止,展开也随之停止。
一旦线程展开被终止或者完成,最终的输出结果是取决于哪个线程 panic:对于 main线程,操作系统提供的终止功能core::intrinsics::abort()会被调用,最终结束当前的panic进程;如果是其它子线程,那么子线程就会简单的终止,同时信息会在稍后通过std:🧵:join()` 进行收集。
可恢复错误Result
// 已经被引入`prelude`中
enum Result <T, E> {
Ok(T),
Err(E),
}
错误传播
fn read_username_from_file() -> Result<String, io::Error> {
let f = File::open("1.txt");
let mut f = match f {
Ok(file) => file,
Err(e) => return Err(e), // error 向上传播
};
let mut s = String::new();
match f.read_to_string(&mut s) {
Ok(_) => Ok(s),
Err(e) => Err(e), // 错误向上传播
}
}
?可以用来简化错误传播
/*
`?`相当于一个宏,类似
let mut f = match f {
// 打开文件成功,将file句柄赋值给f
Ok(file) => file,
// 打开文件失败,将错误返回(向上传播)
Err(e) => return Err(e),
};
*/
fn read() -> Result<String, io::Error> {
let mut f = File::open("1.txt")?;
let mut s = String::new();
f.read_to_string(&mut s)?;
Ok(s)
}
/*
`?`也可以进行自动类型提升(转换)
`?`会调用标准库的`From`特征的`from()`,`ReturnError`实现了`from()`。所以可以自动从`OtherError`转为`ReturnError`
*/
fn open_file() -> Result<File, Box<dyn std::error::Error>> {
let mut s = String::new();
File::open("1.txt")?.read_to_string(&mut s)?; // `?`也可以链式调用
Ok(s)
// fs::read_to_string("hello.txt")
}
/*
`?`可以用于`Option`的传播
*/
pub enum Option<T> {
Some(T),
None
}
// Result 通过 `?` 返回错误,那么 Option 就通过 `?` 返回 None
fn first(arr: &[i32]) -> Option<&i32> {
let v = arr.get(0)?;
Some(v)
// 可以直接 arr.get(0)
}
// note: `?`只会返回错误的值,不会返回正确的
fn first(arr: &[i32]) -> Option<&i32> {
arr.get(0)? // 错误,正确时,返回&i32,而不是
}
生命周期
在存在多个引用时,编译器有时会无法自动推导生命周期,此时就需要我们手动去标注,通过为参数标注合适的生命周期来帮助编译器进行借用检查的分析。
生命周期标注并不会改变任何引用的实际作用域 。
&i32 // 一个引用
&'a i32 // 具有显式生命周期的引用
&'a mut i32 // 具有显式生命周期的可变引用
// 表示两个参数first和second至少和‘a活的一样久
fn useless<'a>(first: &'a i32, second: &'a i32) {}
// 通过函数签名指定生命周期参数时,我们并没有改变传入引用或者返回引用的真实生命周期,而是告诉编译器当不满足此约束条件时,就拒绝编译通过。
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() {
x
} else {
y
}
}
函数的返回值如果是一个引用类型,那么它的生命周期只会来源于:
- 函数参数的生命周期
- 函数体中某个新建引用的生命周期
后者会导致悬垂指针的发生,编译不会通过。
生命周期语法用来将函数的多个引用参数和返回值的作用域关联到一起,一旦关联到一起后,Rust就拥有充分的信息来确保我们的操作是内存安全的。
结构体生命周期
// 结构体 ImportantExcerpt 所引用的字符串 str 必须比该结构体活得更久(一样久?)
struct ImportantExcerpt<'a> {
part: &'a str,
}
生命周期消除
- 消除规则不是万能的,若编译器不能确定某件事是正确时,会直接判为不正确,那么你还是需要手动标注生命周期
- 函数或者方法中,参数的生命周期被称为
输入生命周期,返回值的生命周期被称为输出生命周期
三条消除规则
编译器使用三条消除规则来确定哪些场景不需要显式地去标注生命周期。其中第一条规则应用在输入生命周期上,第二、三条应用在输出生命周期上。若编译器发现三条规则都不适用时,就会报错,提示你需要手动标注生命周期。
-
每一个引用参数都会获得独自的生命周期
例如一个引用参数的函数就有一个生命周期标注:
fn foo<'a>(x: &'a i32),两个引用参数的有两个生命周期标注:fn foo<'a, 'b>(x: &'a i32, y: &'b i32), 依此类推。 -
若只有一个输入生命周期(函数参数中只有一个引用类型),那么该生命周期会被赋给所有的输出生命周期,也就是所有返回值的生命周期都等于该输入生命周期
例如函数
fn foo(x: &i32) -> &i32,x参数的生命周期会被自动赋给返回值&i32,因此该函数等同于fn foo<'a>(x: &'a i32) -> &'a i32 -
若存在多个输入生命周期,且其中一个是
&self或&mut self,则&self的生命周期被赋给所有的输出生命周期拥有
&self形式的参数,说明该函数是一个方法,该规则让方法的使用便利度大幅提升。
静态生命周期
- 字符串字面量的生命周期都是
'static - 当你要为某个引用标注
'static时,请确保它真的活得那么久 - 实在遇到解决不了的生命周期标注问题,可以尝试
'static,有时候它会给你奇迹 (?????????)
闭包closure
let x = 1;
let sum = |y| x + y;
/*
闭包格式
|param1, param2,...| {
语句1;
语句2;
返回表达式
}
*/
由于闭包仅提供内部使用,所以可以由编译器自行推导参数类型,不需手动指定。
// 闭包trait Fn()->...
struct Cacher<T>
where
T: Fn(u32) -> u32,
{
query: T,
value: Option<u32>,
}
// 捕获作用域中的值
let x = 4;
let equal_to_x = |z| z == x; // 获取到x的值
let y = 4;
assert!(equal_to_x(y));
当闭包从环境中捕获一个值时,会分配内存去存储这些值。对于有些场景来说,这种额外的内存分配会成为一种负担。与之相比,函数就不会去捕获这些环境值,因此定义和使用函数不会拥有这种内存负担。
三种Fn
FnOnce:将拿走捕获变量的所有权FnMut:可变借用获取环境的值Fn: 不可变借用
一个闭包实现了哪种 Fn 特征取决于该闭包如何使用被捕获的变量,而不是取决于闭包如何捕获它们。
一个闭包并不仅仅实现某一种 Fn 特征,规则如下:
- 所有的闭包都自动实现了
FnOnce特征,因此任何一个闭包都至少可以被调用一次 - 没有移出所捕获变量的所有权的闭包自动实现了
FnMut特征 - 不需要对捕获变量进行改变的闭包自动实现了
Fn特征
闭包作为返回值
fn factory(x: i32) -> Box<dyn Fn(i32) -> i32> {
let num = 5;
if x > 1 {
Box::new(move |x| x + num)
} else {
Box::new(move |x| x - num)
}
}
迭代器 Iterator
迭代器需要实现IntoIterator特征,Rust的for使用语法糖实现将数组转换为迭代器。
for i in 1..10 { // 语法糖
// ...
}
for i in arr.into_iter() { // 显式使用
// ...
}
- 迭代器是惰性的,当不使用它时,将不发生任何事。只有开始使用时,才会有元素消耗。
next方法:arr.next()
三种迭代器
into_iter: 夺走所有权iter: 借用iter_mut: 可变借用
消费者适配器
let v1 = vec![1, 2, 3];
let v1_iter = v1.iter();
let total: i32 = v1_iter.sum();
assert_eq!(total, 6);
// v1_iter是借用了v1,因此v1可以照常使用
println!("{:?}",v1);
// 以下代码会报错,因为`sum`拿到了迭代器`v1_iter`的所有权
// println!("{:?}",v1_iter);
迭代器适配器
消费者适配器消耗迭代器,迭代器适配器生成迭代器。迭代器适配器是惰性的,需要消费者适配器来收尾。
// 全部 + 1
let v2: Vec<_> = arr.iter().map(|x| x + 1).collect();
// 生成hashmap
// `zip`是一个迭代器适配器,是将两个迭代器压缩到一起,形成Iterator<Item=(ValueFromA, ValueFromB)> 这样的新的迭代器
let folks: HashMap<_> = namse.into_iter().zip(ages.into_iter()).collect();
// 闭包作为得带起适配器的参数,可以捕获环境值
// `filter`用于过滤,使用闭包作为参数。参数`s`来自迭代器的值,相等时保留,不相等则剔除。
shoes.into_iter().filter(|s| s.size == 5).collect();
实现Iterator特征
struct Counter {
count: u32,
}
impl Counter {
fn new() -> Counter {
Counter { count: 0}
}
}
// 实现`Iterator`特征
impl Iterator for Counter {
type Item = u32;
// 只需实现`next`,其它方法都有默认实现
fn next(&mut self) -> Option<Self::Item> {
if self.count < 3 {
self.count += 1;
Some(self.count)
} else {
None
}
}
}
let mut counter = Counter::new();
assert_eq!(counter.next(), Some(1));
assert_eq!(counter.next(), Some(2));
assert_eq!(counter.next(), Some(3));
assert_eq!(counter.next(), None);
// `enumerate`获取 `(索引,值)`
注释和文档
Rust的注释分为三种:
- 代码注释: 用户是同项目协作开发者 (
// /**/) - 文档注释,支持
markdown,对项目的描述、公共API等 - 包和模块注释: 主要用于说明当前包和模块的功能,方便用户迅速了解一个项目
文档注释
cargo doc命令可以把文档注释转换为HTML网页文件。
使用///,也可以使用/** */减少 前者的使用
- 文档注释需要位于
lib类型的包中,例如src/lib.rs中 - 文档注释可以使用
markdown!例如# Examples的标题,以及代码块高亮 - 被注释的对象需要使用
pub对外可见, 记住:文档注释是给用户看的,内部实现细节不应该被暴露出去
常见的注释标题:
- Panics: 函数可能会出现的异常状况,这样调用函数的人就可以提前规避
- Errors: 描述可能出现的错误及什么情况会导致错误,有助于调用者针对不同的错误采取不同的处理方式
- Safety: 如果函数使用
unsafe代码,那么调用者就需要注意一些使用条件,以确保unsafe代码块的正常工作
包和模块的注释
这些注释需要添加到包、模块的最上方。包级别的注释也分为两种:行注释//!和块注释/*! ... */
文档测试(Doc Test)
Rust允许在文档中写单元测试用例
/// `add_one`将指定值加1
///
/// # Examples11
///
/// ```
/// let arg = 5;
/// let answer = world_hello::compute::add_one(arg);
///
/// assert_eq!(6, answer);
/// ```
pub fn add_one(x: i32) -> i32 {
x + 1
}
使用cargo test运行测试
文档测试也会造成panic
/// # Panics
///
/// The function panics if the second argument is zero.
///
/// ```rust
/// // panics on division by zero
/// world_hello::compute::div(10, 0);
/// ```
pub fn div(a: i32, b: i32) -> i32 {
if b == 0 {
panic!("Divide-by-zero error");
}
a / b
}
添加should_panic可以通过测试
/// # Panics
///
/// The function panics if the second argument is zero.
///
/// ```rust,should_panic
/// // panics on division by zero
/// world_hello::compute::div(10, 0);
/// ```
隐藏文档: 添加# /// # xxxxxx
跳转:
/// `add_one`返回一个[`Option`]类型
文档搜索别名:
#[doc(alias = "x")]
#[doc(alias = "big")]
pub struct BigX;
#[doc(alias("y", "big"))]
pub struct BigY;
}
特殊类型
newtype
// newtype 使用元祖结构体的方式
struct Meter(u32)
类型别名
type Meters = u32 // 编译器将把`Meters` 当作u32看待
类型别名仅仅只是别名,并不是全新类型,new type才是。
!永不返回
fn main() {
let i = 2;
let v = match i {
0..=3 => i,
_ => panic!("不合规定的值:{}",i) // 永不返回
};
}
动态类型大小
动态类型大小只有在运行时才知道大小,使用 DST(dynamically sized types)或者 unsized 类型来称呼它。
str是一个动态类型大小。
// error
let s1: str = "hello";
let s2: str = "ioioioio"; // str 长度不定
// correct
let s3: &str = "dadadasdas";
Rust中最常见的 DST 类型: str、[T]、dyn Trait。
Sized 特征
/*
泛型: 编译器需要知道泛型参数T的大小。泛型函数只能用于实现`Sized`特征的类型上。
*/
fn generic<T: Sized> (t: T) { // 编译器自动追加 `Sized`
// .........
}
// 使用 `?Sized` 表示类型 T 既有可能是固定大小的类型,也可能是动态大小的类型
fn generic<T: ?Sized> (t: &T) { // T为`&`,因为T不定长
// ............
}
格式化输出
println!("Hello"); // => "Hello"
println!("Hello, {}!", "world"); // => "Hello, world!"
println!("The number is {}", 1); // => "The number is 1"
println!("{:?}", (3, 4)); // => "(3, 4)"
println!("{value}", value=4); // => "4"
println!("{} {}", 1, 2); // => "1 2"
println!("{:04}", 42); // => "0042" with leading zeros
print!, 将格式化文本输出到标准输出,不带换行符println!, 同上,但是在行的末尾添加换行符format!, 将格式化文本输出到String字符串eprintln!: 输出到错误流
{}和{:?}
{}: 需要实现std::fmt::Display{:?}:需要实现std::fmt::Debug(可以使用#[derive(Debug)]派生){:#?}:和{:?}基本一致,不过输出更优美
实现{}
-
为自定义类型实现
Displaystruct Person { /* ... */} impl fmt::Display for Person { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!("xxxxxxxxx") } } -
为外部类型实现
Displaystruct Array(Vec<i32>); impl fmt::Dispaly for Array { // ............ }
{}参数
// 指定位置参数
println!("{0}, this is {1}. {1}, this is {0}", "Alice", "Bob");
// 带名称的变量 带名称的参数必须放在不带名称参数的后面
println!("{name} {}", 1, name = 2); // => "2 1"
格式化参数:
// 宽度
// 以下全部输出 "Hello x !"
// 为"x"后面填充空格,补齐宽度5
println!("Hello {:5}!", "x");
// 使用参数5来指定宽度
println!("Hello {:1$}!", "x", 5);
// 使用x作为占位符输出内容,同时使用5作为宽度
println!("Hello {1:0$}!", 5, "x");
// 使用有名称的参数作为宽度
println!("Hello {:width$}!", "x", width = 5);
// 数字填充 符号和0
// 宽度是5 => Hello 5!
println!("Hello {:5}!", 5);
// 显式的输出正号 => Hello +5!
println!("Hello {:+}!", 5);
// 宽度5,使用0进行填充 => Hello 00005!
println!("Hello {:05}!", 5);
// 负号也要占用一位宽度 => Hello -0005!
println!("Hello {:05}!", -5);
// 对齐
// 以下全部都会补齐5个字符的长度
// 左对齐 => Hello x !
println!("Hello {:<5}!","x");
// 右对齐 => Hello x
println!("Hello {:>5}!","x");
// 居中对齐 => Hello x !
println!("Hello {:^5}!","x");
// 对齐并使用指定符号填充 => Hello x&&&&!
// 指定符号填充的前提条件是必须有对齐字符
println!("Hello {:&<5}!", "x");
// 精度
let v = 3.1415926;
// 保留小数点后两位 => 3.14
println!("{:.2}",v);
// 带符号保留小数点后两位 => +3.14
println!("{:+.2}",v);
// 不带小数 => 3
println!("{:.0}",v);
// 通过参数来设定精度 => 3.1416,相当于{:.4}
println!("{:.1$}", v, 4);
let s = "hi我是Sunface孙飞";
// 保留字符串前三个字符 => hi我
println!("{:.3}", s);
// {:.*}接收两个参数,第一个是精度,第二个是被格式化的值 => Hello abc!
println!("Hello {:.*}!", 3, "abcdefg");
// 进制
// 二进制 => 0b11011!
println!("{:#b}!", 27);
// 八进制 => 0o33!
println!("{:#o}!", 27);
// 十进制 => 27!
println!("{}!", 27);
// 小写十六进制 => 0x1b!
println!("{:#x}!", 27);
// 大写十六进制 => 0x1B!
println!("{:#X}!", 27);
// 不带前缀的十六进制 => 1b!
println!("{:x}!", 27);
// 使用0填充二进制,宽度为10 => 0b00011011!
println!("{:#010b}!", 27);
// 指数
println!("{:2e}", 1000000000); // => 1e9
println!("{:2E}", 1000000000); // => 1E9
// 指针地址
let v= vec![1,2,3];
println!("{:p}",v.as_ptr()) // => 0x600002324050
// 转义`{}`
// {使用{转义,}使用} => Hello {}
println!("Hello {{}}");
智能指针
指针是一个包含了内存地址的变量,该内存地址引用或者指向了另外的数据。
&可以用作引用,同时表示借用其他变量的值 。
智能指针大多实现了Deref和Drop特征。
Box<T>堆对象分配
在Rust中,main线程的栈大小是8MB,普通线程是2MB。Box在堆上分配内存。与栈相反,堆上内存则是从低位地址向上增长。
堆栈的性能(CPU高速缓存器影响):
- 小型数据,在栈上的分配性能和读取性能都要比堆上高
- 中型数据,栈上分配性能高,但是读取性能和堆上并无区别,因为无法利用寄存器或 CPU 高速缓存,最终还是要经过一次内存寻址
- 大型数据,只建议在堆上分配和使用
Box使用场景:
- 特意的将数据分配在堆上
- 数据较大时,又不想在转移所有权时进行数据拷贝
- 类型的大小在编译期无法确定,但是我们又需要固定大小的类型时
- 特征对象,用于说明对象实现了一个特征,而不是某个特定的类型
//
let a = Box::new(3);
println!("a = {}", a); // a = 3 此处进行自动解引用
let b = a + 1; // error, 表达式中不能自动隐式解引用
/*
len = 1024, ptr = 0x7ffddca6e0b8
len = 1024, ptr = 0x7ffddca6f0b8
*/
let arr = [0; 1024];
let arr1 = arr; // 在栈上,深拷贝一份数据
println!("len = {:?}, ptr = {:?}", arr.len(), arr.as_ptr());
println!("len = {:?}, ptr = {:?}", arr1.len(), arr1.as_ptr());
/*
len = 1024, ptr = 0x563896638ba0
len = 1024, ptr = 0x563896638ba0
*/
let arr = Box::new([0;1024]);
println!("len = {:?}, ptr = {:?}", arr.len(), arr.as_ptr());
let arr1 = arr;
println!("len = {:?}, ptr = {:?}", arr1.len(), arr1.as_ptr());
enum List {
Cons(i32, Box<List>), // 动态类型大小转为固定类型大小 (栈->堆)
Nil,
}
let elems: Vec<Box<dyn Draw>> = vec![Box::new(Button { id: 1 }), Box::new(Select { id: 2 })]; // dyn trait
Box::leak
关联函数Box::leak可以消费掉Box并轻质目标值从内存中泄漏。
fn main() {
let s = gen_static_str();
println!("{}",s);
}
fn gen_static_str() -> &'static str{
let mut s = String::new();
s.push_str("hello, world");
Box::leak(s.into_boxed_str()) // 强制运行期间一直可用
}
Deref解引用
Deref:可以让智能指针像引用那样工作Drop:允许你指定智能指针超出作用域后自动执行的代码
// 自定义智能指针
struct Mybox<T>(T);
impl <T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
// 实现`Deref`
use std::ops::Deref;
impl <T> Deref for MyBox<T> {
type Target = T;
fn deref(&self) -> &Self.Target {
&self.0
}
}
对智能指针进行解引用时,实际:*(y.deref())。
至于 Rust 为何要使用这个有点啰嗦的方式实现,原因在于所有权系统的存在。如果 deref 方法直接返回一个值,而不是引用,那么该值的所有权将被转移给调用者,而我们不希望调用者仅仅只是 *T 一下,就拿走了智能指针中包含的值。
*不会无限次进行替换,只会替换一次,而不会继续进行替换然后产生形如 *((y.deref()).deref()) 的怪物。
隐式Deref
fn main() {
let s = String::from("hello world");
display(&s)
}
fn display(s: &str) {
println!("{}",s);
}
String实现了Deref特征,能被转换成一个&strs是一个String类型,当它被传给display函数时,自动通过Deref转换成了&str- 必须使用
&s的方式来触发Deref(&s相当于调用s的deref方法)
一个类型为 T 的对象 foo,如果 T: Deref<Target=U>,那么,相关 foo 的引用 &foo 在应用的时候会自动转换为 &U。
三种Deref:
- 当
T: Deref<Target=U>,可以将&T转换成&U,也就是我们之前看到的例子 - 当
T: DerefMut<Target=U>,可以将&mut T转换成&mut U - 当
T: Deref<Target=U>,可以将&mut T转换成&U
我们也可以为自己的类型实现 Deref 特征,但是原则上来说,只应该为自定义的智能指针实现 Deref。例如,虽然你可以为自己的自定义数组类型实现 Deref 以避免 myArr.0[0] 的使用形式,但是 Rust 官方并不推荐这么做,特别是在你开发三方库时。
Drop资源释放
Drop顺序:
- 变量级别,按照逆序的方式,
_x在_foo之前创建,因此_x在_foo之后被drop - 结构体内部,按照顺序的方式, 结构体
_x中的字段按照定义中的顺序依次drop
foo.drop()不能显式调用,且不会拿走所有权。而std::mem::drop是drop(foo),会拿走所有权。
Drop和Copy特征互斥:实现了Copy的特征会被编译器隐式的复制,因此非常难以预测析构函数执行的时间和频率。因此这些实现了Copy的类型无法拥有析构函数。
Rc和Arc
在多线程和图等一些情况下,需要一个值被多个变量拥有。为了解决此类问题,Rust在所有权机制之外又引入了额外的措施来简化相应的实现:通过引用计数的方式,允许一个数据资源在同一时刻拥有多个所有者。
Rc (reference counting)引用计数器
当希望在堆上分配一个对象供程序的多个部分使用且无法确定哪个部分最后一个结束时,就可以使用Rc成为数据值的所有者。
let s = String::from("hello");
let a = Box::new(s); // 所有权转移
let b = Box::new(s); // error
// 使用`Rc`解决
// 不要给clone字样所迷惑,以为所有的clone都是深拷贝。这里的clone仅仅复制了智能指针并增加了引用计数,并没有克隆底层数据,因此a和b是共享了底层的字符串s 实际上Rust中,还有不少clone都是浅拷贝,例如迭代器的克隆.
use std::rc::Rc;
let a = Rc::new(String::from("hello"));
let b = Rc::clone(&a);
assert_eq!(2, Rc::strong_count(&a));
assert_eq!(Rc::strong_count(&a),Rc::strong_count(&b))
Rc底层指向的是不可变引用。
但是可以修改数据也是非常有用的,只不过我们需要配合其它数据类型来一起使用,例如内部可变性的RefCell<T>类型以及互斥锁Mutex<T>。事实上,在多线程编程中,Arc跟Mutext锁的组合使用非常常见,它们既可以让我们在不同的线程中共享数据,又允许在各个线程中对其进行修改。
Rc/Arc是不可变引用,你无法修改它指向的值,只能进行读取, 如果要修改,需要配合后面章节的内部可变性RefCell或互斥锁Mutex- 一旦最后一个拥有者消失,则资源会自动被回收,这个生命周期是在编译期就确定下来的
- Rc只能用于同一线程内部,想要用于线程之间的对象共享, 你需要使用
Arc Rc<T>是一个智能指针,实现了Deref特征,因此你无需先解开Rc指针,再使用里面的T,而是可以直接使用T
Arc(Atomic Rc)
对Rc的原子化。内部的引用计数使用锁来保证多线程的安全,所以性能肯定比Rc低。两者APi一样。
use std::sync::Arc;
use std::thread;
fn main() {
let s = Arc::new(String::from("duoxiancheng"));
for _ in 0..10 {
let s = Arc::clone(&s);
let handle = thread::spawn(move || {
println!("{}", s);
});
}
}
Cell和RefCell
Cell和RefCell用于内部可变性,可以在拥有不可变引用的同时修改目标数据。
Cell
Cell和RefCell在功能上没有区别,区别在于Cell<T>适用于T实现Copy的情况:
use std::cell::Cell;
fn main() {
let c = Cell::new("asdf"); // &str实现了`Copy`特征
let one = c.get(); // 获取
c.set("qwer"); // 设置
let two = c.get();
println!("{},{}", one,two);
}
RefCell
| Rust规则 | 智能指针带来的额外规则 |
|---|---|
| 一个数据只有一个所有者 | Rc/Arc让一个数据可以拥有多个所有者 |
| 要么多个不可变借用,要么一个可变借用 | RefCell实现编译期可变、不可变引用共存 |
| 违背规则导致编译错误 | 违背规则导致运行时panic |
use std::cell::RefCell;
fn main() {
let s = RefCell::new(String::from("hello, world"));
let s1 = s.borrow();
let s2 = s.borrow_mut();
println!("{},{}",s1,s2); // 编译不报错,运行时panic
}
// `RefCell`用于自己确定代码是正确的,而编译器发生误判
RefCell简单总结
- 与Cell用于可Copy的值不同,RefCell用于引用
- RefCell只是将借用规则从编译期推迟到程序运行期,并不能帮你绕过这个规则
- RefCell适用于编译期误报或者一个引用被在多个代码中使用、修改以至于难于管理借用关系时
- 使用
RefCell时,违背借用规则会导致运行期的panic
当非要使用内部可变性时,首选Cell,只有值拷贝的方式不能满足你时,才去选择RefCell。
use std::cell::RefCell;
pub trait Messenger { // 外部库中定义
fn send(&self, msg: String);
}
pub struct MsgQueue {
msg_cache: RefCell<Vec<String>>,
}
impl Messenger for MsgQueue {
fn send(&self,msg: String) {
self.msg_cache.borrow_mut().push(msg); // 使RefCell解决不可变问题
}
}
fn main() {
let mq = MsgQueue{msg_cache: RefCell::new(Vec::new())};
mq.send("hello, world".to_string());
}
Rc+RefCell组合使用
let s = Rc::new(RefCell::new("可变,同时可被多个变量拥有".to_string()));
let s1 = s.clone();
let s2 = s.clone();
s2.borrow_mut().push_str(", on yeah!"); // 三者同时被修改
损耗:
性能损耗: 两者结合在一起使用的性能其实非常高,大致相当于没有线程安全版本的C++std::shared_ptr指针内存损耗:仅仅多分配了三个usize/isize,并没有其它额外的负担cpu损耗:非常低CPU缓存MISS:CPU缓存可能不够亲和
Cell::from_mut解决借用冲突
Cell::from_mut:将&mut T转为&Cell<T>Cell::as_slice_of_cells:将&Cell<[T]>转为&[Cell<T>]
循环引用和自引用
Weak
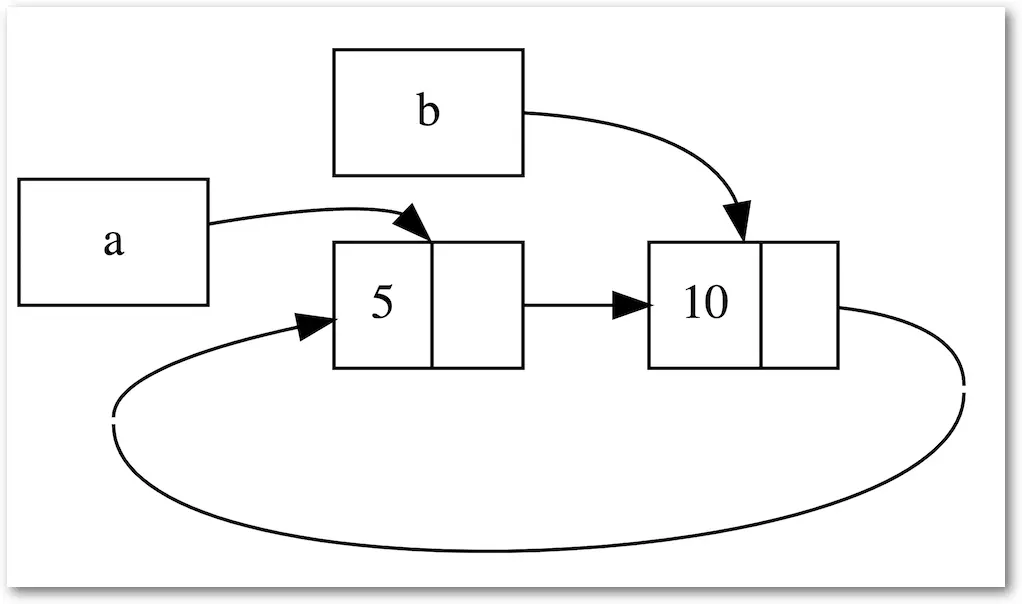
当a和b都是引用的话,会导致计数为2,drop掉
Weak非常类似于Rc,但是与Rc持有所有权不同,Weak不持有所有权,它仅仅保存一份指向数据的弱引用:如果你想要访问数据,需要通过Weak指针的upgrade方法实现,该方法返回一个类型为Option><Rc<T>>的值。
对于父子引用关系,可以让父节点通过Rc来引用子节点,然后让子节点通过Weak来引用父节点。
Weak通过use std::rc::Weak来引入,它具有以下特点:
- 可访问,但没有所有权,不增加引用计数,因此不会影响被引用值的释放回收
- 可由
Rc<T>调用downgrade方法转换成Weak<T> Weak<T>可使用upgrade方法转换成Option<Rc<T>>,如果资源已经被释放,则Option的值是None- 常用于解决循环引用的问题
一个简单的例子:
use std::rc::Rc;
fn main() {
// 创建Rc,持有一个值5
let five = Rc::new(5);
// 通过Rc,创建一个Weak指针
let weak_five = Rc::downgrade(&five);
// Weak引用的资源依然存在,取到值5
let strong_five: Option<Rc<_>> = weak_five.upgrade();
assert_eq!(*strong_five.unwrap(), 5);
// 手动释放资源`five`
drop(five);
// Weak引用的资源已不存在,因此返回None
let strong_five: Option<Rc<_>> = weak_five.upgrade();
assert_eq!(strong_five, None);
}
多线程并发编程
并发模型:
- 由于操作系统提供了创建线程的API,因此部分语言会直接调用该API来创建线程,因此最终程序内的线程数和该程序占用的操作系统线程数相等,一般称之为1:1线程模型,例如Rust
- 还有些语言在内部实现了自己的线程模型(绿色线程、协程),程序内部的M个线程最后会以某种映射方式使用N个操作系统线程去运行,因此称之为M:N线程模型, 其中M和N并没有特定的彼此限制关系。一个典型的代表就是Go语言
- 还有些语言使用了Actor模型,基于消息传递进行并发, 例如Erlang语言
线程使用
创建线程
use std::thread;
// 创建线程
thread::spawn(|| {
// xxxxxxxxxxxx
});
// 等待
let handle = thread::spawn( move || { // move 拿走变量所有权
for i in 0..10 {
// xxxxxxxxxxxxx
}
});
handle.join().unwrap(); // 等待线程结束 阻塞
for i in 0..5 {
// xxxxxxxxxxxx
}
性能:
创建线程:据不精确估算,创建一个线程大概需要0.24毫秒,随着线程的变多,这个值会变得更大,因此线程的创建耗时并不是不可忽略的,只有当真的需要处理一个值得用线程去处理的任务时,才使用线程。创建数量:CPU密集型的可以让线程数等于CPU核心。IO阻塞型可以更多。
线程屏障(Barrier)
/* 输出:
before wait
before wait
before wait
after wait
after wait
after wait
*/
use std::thread;
use std::sync::{Arc, Barrier};
pub fn main() {
let mut handles = Vec::with_capacity(3);
let barrier = Arc::new(Barrier::new(3));
for _ in 0..3 {
let b = barrier.clone();
handles.push(thread::spawn(move|| {
println!("before wait");
b.wait(); // 等待其他线程也进行这里才继续执行
println!("after wait");
}));
}
for handle in handles {
handle.join().unwrap();
}
}
线程局部变量
标准库thread_local宏:
// 使用thread_local宏可以初始化线程局部变量,然后在线程内部使用该变量的with方法获取变量值
use std::cell::RefCell;
use std::thread;
thread_local!(static FOO: RefCell<u32> = RefCell::new(1)); // 声明静态生命周期
FOO.with(|f| { // 使用with 取值
assert_eq!(*f.borrow(), 1);
*f.borrow_mut() = 2;
});
// 每个线程开始时都会拿到线程局部变量的FOO的初始值
let t = thread::spawn(move|| {
FOO.with(|f| {
assert_eq!(*f.borrow(), 1);
*f.borrow_mut() = 3;
});
});
// 等待线程完成
t.join().unwrap();
// 尽管子线程中修改为了3,我们在这里依然拥有main线程中的局部值:2
FOO.with(|f| {
assert_eq!(*f.borrow(), 2);
});
条件控制线程的执行和挂起
只被调用一次的函数
线程间的消息传递
消息通道
多发送者,单接收者:mpsc(multiple producer, single consumer):
use std::sync::mpsc;
use std::thread;
pub fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
tx.send(1).unwrap(); // 通道类型是i32
// tx.send(Some(1)).unwrap(); error 编译器自动推导出通道传递的值是i32类型
});
println!("receive {}", rx.recv().unwrap());
}
try_recv不阻塞
use std::sync::mpsc;
use std::thread;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
tx.send(1).unwrap();
});
// 由于线程创建太慢,直到主线程结束,子线程还没有发出
println!("receive {:?}", rx.try_recv());
}
所有权:
- 若值的类型实现了
Copy特征,则直接复制一份该值,然后传输过去,例如之前的i32类型 - 若值没有实现
Copy,则它的所有权会被转移给接收端,在发送端继续使用该值将报错
使用for接收
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("thread"),
];
for val in vals {
tx.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
} // 线程完成后,tx被销毁
});
for received in rx { // tx销毁后,for得到消息
println!("Got: {}", received);
}
}
同步通道:mpsc::sync_channel(0): 只有接收消息彻底成功后,发送消息才算完成
关闭通道使用: drop或自动进行
线程同步
锁共享内存:同步的灵魂,底层的实现。 场景: 需要简洁的实现以及更高的性能时。信号量
互斥锁Mutex
mutual exclusion
use std::sync::Mutex;
pub fn main() {
let m = Mutex::new(5);
{
/* 它实现了Deref特征,会被自动解引用后获得一个引用类型,该引用指向Mutex内部的数据
它还实现了Drop特征,在超出作用域后,自动释放锁,以便其它线程能继续获取锁 */
let mut num = m.lock().unwrap(); // MutexGuard<T>
*num = 6;
} // 自动解锁
println!("{:?}", m);
}
读写锁RwLock
use std::sync::RwLock;
let lock = RwLock::new(5);
// 同一时间允许多个读
{
let r1 = lock.read().unwrap();
let r2 = lock.read().unwrap();
assert_eq!(*r1, 5);
assert_eq!(*r2, 5);
} // 读锁在此处被drop
// 同一时间只允许一个写
{
let mut w = lock.write().unwrap();
*w += 1;
assert_eq!(*w, 6);
// 以下代码会panic,因为读和写不允许同时存在
// 写锁w直到该语句块结束才被释放,因此下面的读锁依然处于`w`的作用域中
// let r1 = lock.read();
// println!("{:?}",r1);
}// 写锁在此处被drop
条件变量(Condvar)
信号量
use std::sync::Arc;
use tokio::sync::Semaphore;
#[tokio::main]
async fn main() {
let semaphore = Arc::new(Semaphore::new(3));
let mut join_handles = Vec::new();
for _ in 0..5 {
let permit = semaphore.clone().acquire_owned().await.unwrap();
join_handles.push(tokio::spawn(async move {
//
// 在这里执行任务...
//
drop(permit);
}));
}
for handle in join_handles {
handle.await.unwrap();
}
}
Atomic原子类型
原子指的是一系列不可被CPU上下文交换的机器指令,这些指令组合在一起就形成了原子操作。在多核CPU下,当某个CPU核心开始运行原子操作时,会先暂停其它CPU内核对内存的操作,以保证原子操作不会被其它CPU内核所干扰。
原子类型是无锁类型,但是无锁不代表无需等待,因为原子类型内部使用了CAS循环,当大量的冲突发生时,该等待还是得等待!但是总归比锁要好。
CAS全称是Compare and swap, 它通过一条指令读取指定的内存地址,然后判断其中的值是否等于给定的前置值,如果相等,则将其修改为新的值。
use std::ops::Sub;
use std::sync::atomic::{AtomicU64, Ordering};
use std::thread::{self, JoinHandle};
use std::time::Instant;
const N_TIMES: u64 = 10000000;
const N_THREADS: usize = 10;
static R: AtomicU64 = AtomicU64::new(0);
fn add_n_times(n: u64) -> JoinHandle<()> {
thread::spawn(move || {
for _ in 0..n {
R.fetch_add(1, Ordering::Relaxed);
}
})
}
fn main() {
let s = Instant::now();
let mut threads = Vec::with_capacity(N_THREADS);
for _ in 0..N_THREADS {
threads.push(add_n_times(N_TIMES));
}
for thread in threads {
thread.join().unwrap();
}
assert_eq!(N_TIMES * N_THREADS as u64, R.load(Ordering::Relaxed));
println!("{:?}",Instant::now().sub(s));
}
:和Mutex一样,Atomic的值具有内部可变性,你无需将其声明为mut。
- Relaxed, 这是最宽松的规则,它对编译器和CPU不做任何限制,可以乱序
- Release 释放,设定内存屏障(Memory barrier),保证它之前的操作永远在它之前,但是它后面的操作可能被重排到它前面
- Acquire 获取, 设定内存屏障,保证在它之后的访问永远在它之后,但是它之前的操作却有可能被重排到它后面,往往和
Release在不同线程中联合使用 - AcqRel, Acquire和Release的结合,同时拥有它们俩提供的保证。比如你要对一个
atomic自增 1,同时希望该操作之前和之后的读取或写入操作不会被重新排序 - SeqCst 顺序一致性,
SeqCst就像是AcqRel的加强版,它不管原子操作是属于读取还是写入的操作,只要某个线程有用到SeqCst的原子操作,线程中该SeqCst操作前的数据操作绝对不会被重新排在该SeqCst操作之后,且该SeqCst操作后的数据操作也绝对不会被重新排在SeqCst操作前。
Send和Sync特征
Send和Sync是标记特征(marker trait,未定义任何行为)
- 实现
Send的类型可以在线程间安全的传递其所有权 - 实现了
Sync的类型可以在线程间安全的共享(通过引用)
以下没有实现Send和Sync:
- 原生指针两者都没实现,因为它本身就没有任何安全保证
UnsafeCell不是Sync,因此Cell和RefCell也不是Rc两者都没实现(因为内部的引用计数器不是线程安全的)
只要复合类型中有一个成员不是Send或Sync,那么该符合类型也就不是Send或Sync。
手动实现 Send 和 Sync 是不安全的,通常并不需要手动实现 Send 和 Sync trait,实现者需要使用unsafe小心维护并发安全保证。
全局变量
全局变量的生命周期是'static,但不一需要使用staic来声明。
编译器初始化
-
静态常量const MAX_ID: usize = usize::MAX / 2;- 关键字是
const而不是let - 定义常量必须指明类型(如i32)不能省略
- 定义常量时变量的命名规则一般是全部大写
- 常量可以在任意作用域进行定义,其生命周期贯穿整个程序的生命周期。编译时编译器会尽可能将其内联到代码中,所以在不同地方对同一常量的引用并不能保证引用到相同的内存地址
- 常量的赋值只能是常量表达式/数学表达式,也就是说必须是在编译期就能计算出的值,如果需要在运行时才能得出结果的值比如函数,则不能赋值给常量表达式
- 对于变量出现重复的定义(绑定)会发生变量遮盖,后面定义的变量会遮住前面定义的变量,常量则不允许出现重复的定义
- 关键字是
-
静态变量/* 只有在同一线程内或者不在乎数据的准确性时,才应该使用全局静态变量。 和常量相同,定义静态变量的时候必须赋值为在编译期就可以计算出的值(常量表达式/数学表达式),不能是运行时才能计算出的值(如函数) */ static mut REQUEST_RECV: usize = 0; fn main() { unsafe { // 必须使用unsafe,因为这种使用方式往往并不安全,其实编译器是对的,当在多线程中同时去修改时,会不可避免的遇到脏数据。 REQUEST_RECV += 1; assert_eq!(REQUEST_RECV, 1); } }- 静态变量不会被内联,在整个程序中,静态变量只有一个实例,所有的引用都会指向同一个地址
- 存储在静态变量中的值必须要实现Sync trait
-
原子类型:use std::sync::atomic::{AtomicUsize, Ordering}; static REQUEST_RECV: AtomicUsize = AtomicUsize::new(0); fn main() { for _ in 0..100 { REQUEST_RECV.fetch_add(1, Ordering::Relaxed); } println!("当前用户请求数{:?}",REQUEST_RECV); }
运行时初始化
lazy_staticBox::leak
异步编程
async异步
对于长时间运行的CPU密集型任务,例如并行计算,使用线程将更有优势。可以减少线程切换的损耗。
高并发更适合 IO 密集型任务,例如 web 服务器、数据库连接等等网络服务,使用async,既可以有效的降低 CPU 和内存的负担,又可以让大量的任务并发的运行,一个任务一旦处于IO或者其他等待(阻塞)状态,就会被立刻切走并执行另一个任务,而这里的任务切换的性能开销要远远低于使用多线程时的线程上下文切换。
async底层也基于线程实现,它基于线程封装了一个运行时,将多个任务映射到少量线程上。
编译器会为async函数生成状态机,然后将整个运行时打包进来,这会造成我们编译出的二进制可执行文件体积显著增大。
选择:
- 有大量
IO任务需要并发运行时,选async模型 - 有部分
IO任务需要并发运行时,选多线程,如果想要降低线程创建和销毁的开销,可以使用线程池 - 有大量
CPU密集任务需要并行运行时,例如并行计算,选多线程模型,且让线程数等于或者稍大于CPU核心数 - 无所谓时,统一选多线程
事实上,async 和多线程并不是二选一,在同一应用中,可以根据情况两者一起使用,当然,我们还可以使用其它的并发模型,例如上面提到事件驱动模型,前提是有三方库提供了相应的实现。
要完整的使用 async 异步编程,你需要依赖以下特性和外部库:
- 所必须的特征(例如
Future)、类型和函数,由标准库提供实现 - 关键字
async/await由Rust语言提供,并进行了编译器层面的支持 - 众多实用的类型、宏和函数由官方开发的
futures包提供(不是标准库),它们可以用于任何async应用中。 async代码的执行、IO操作、任务创建和调度等等复杂功能由社区的async运行时提供,例如tokio和async-std
async和.await简单使用
(协程?)
-
cargo add futures(需安装cargo-edit,自动添加依赖) -
use futures::executor::block_on; fn main() { let furture = do_somethng(); block_on(furture); // 阻塞当前线程,并等待指定的`furture`完成 } async fn do_somethng() { println!("go go go!"); } -
// await use futures::executor::block_on; fn main() { let furture = do_somethng(); block_on(furture); } async fn do_somethng() { do_some2().await; // 线程不会阻塞,该线程可以去执行其他[协程?] println!("go go go!"); } async fn do_some2() { println!("go 2 go 2 go 2!"); }
宏系统
宏是用来生成代码的。
定义格式:macro_rules! macro_name { macro_body },macro_body与匹配模式很像,pattern => do_something。
macro_rules! create_function {
($func_name:ident) => ( // ident 标识符
fn $func_name() {
println!("function {:?} is call", stringify!($func_name))
}
)
}
pub fn main() {
create_function!(fo);
fo();
}
- 宏定义需要在宏调用之前
- 宏和函数处于不同命名空间下
指示符
宏里的变量都是以$开头的,其余按字面去匹配。
ident:标识符,表示函数或变量expr:表达式block:代码块pat:模式,普通模式匹配中的模式,如Some(t)path:路径,双冒号分隔的限定名(qualified name),如std::cmp::PartialOrdtt:单个语法树ty:类型,语义类型,如i32item:条目meta:元条目stmt:单条语句
重复(repetition)
宏允许接收不定长参数,通过使用+、*来实现,类似正则表达式。+:一次或多次 *:零次或多次。
经常看到 $(...),*, $(...);*, $(...),+, $(...);+ 这样的用来表示重复。
macro_rules! vector {
($($x:expr),*) => {
{
let mut temp_vec = Vec::new();
$(temp_vec.push($x);)*
temp_vec
}
};
}
pub fn main() {
let a = vector![1, 2, 3, 4];
println!("{:?}", a);
}
递归
macro_rules! vector {
($($x:expr),*) => {
{
let mut temp_vec = Vec::new();
$(temp_vec.push($x);)*
temp_vec
}
};
}
pub fn main() {
let a = vector![1, 2, 3, 4];
println!("{:?}", a);
}
过程宏
过程宏(Procedure Macro)是Rust中的一种特殊形式的宏,它将提供比普通宏更强大的功能。
- 派生宏(Derive macro):用于结构体(struct)、枚举(enum)、联合(union)类型,可为其实现函数或特征(Trait)。
- 属性宏(Attribute macro):用在结构体、字段、函数等地方,为其指定属性等功能。如标准库中的#[inline]、#[derive(...)]等都是属性宏。
- 函数式宏(Function-like macro):用法与普通的规则宏类似,但功能更加强大,可实现任意语法树层面的转换功能。
派生宏
// 定义
#[proc_macro_derive(Builder)]
fn derive_builder(input: TokenStream) -> TokenStream {
let _ = input;
unimplemented!()
}
// 使用
#[derive(Builder)]
struct Command {
// ...
}
属性宏
// 定义
#[proc_macro_attribute]
fn sorted(args: TokenStream, input: TokenStream) -> TokenStream {
let _ = args;
let _ = input;
unimplementd!()
}
// 使用
#[sorted]
enum Letter {
A,
B,
// .......
}
函数宏
// 定义
#[proc_macro]
pub fn seq(input: TokenStream) -> TokenStream {
let _ = input;
unimplements!()
}
// 使用
seq! { n in 0..10 {
//........
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号