random forest model
思考
传统机器学习方法都有特征提取的步骤(通过数学公式进行特征提取)
随机森林模型
随机选择条件进行建树,建立多个决策树形成森林。
决策树:进行选择或者预测的走向模型(树结构)
熵值公式:用于描述对选择的混乱程度。最常用的度量纯度的指标
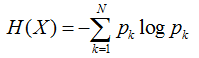
熵值越小说明样本越纯,熵值越大,说明样本越混乱。函数与熵值对应关系的解释
熵值:熵值代表着混乱的程度,熵差代表信息增益(对决策的贡献程度)
剪枝
剪枝的目的其实就是防止过拟合,它是决策树防止过拟合的最主要手段。有预剪枝和后剪枝两种方式
参考

