吴恩达深度学习课程第二课-改善深层神经网络
第一周 深度学习的实用层面
1.1 训练,配置,测试训练集
- 学习完如何构建神经网络,接下来学习如何高效运行神经网络
- 数据集划分: train,dev,test: 在train中训练模型,利用dev选择最佳模型,利用test测试最终模型


1.2 偏差Bias,方差Variance
- 欠拟合(高偏差),过拟合(高方差)
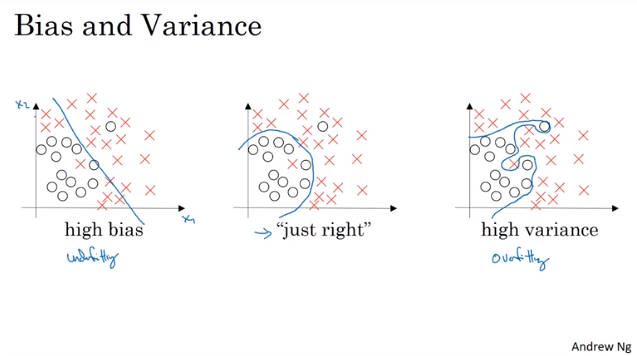

1.3 处理欠拟合,过拟合方案
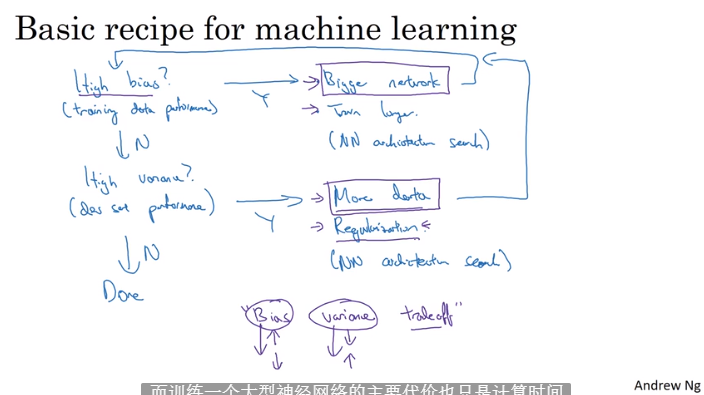
1.4 正则化Regularization

1.5 为什么正则化可以解决过拟合
- L2正则项将许多隐藏单元的影响减少了
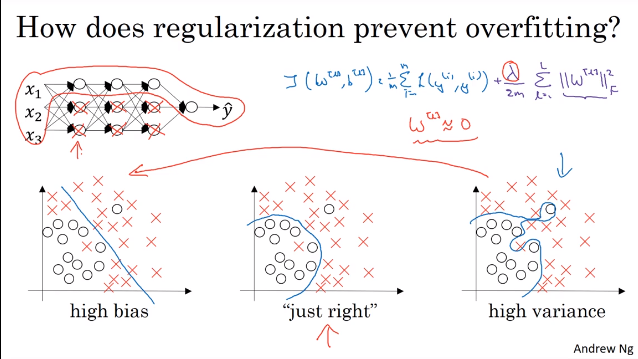
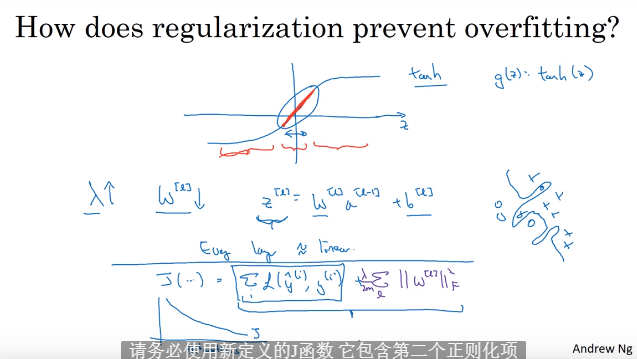
1.6 dropout正则化
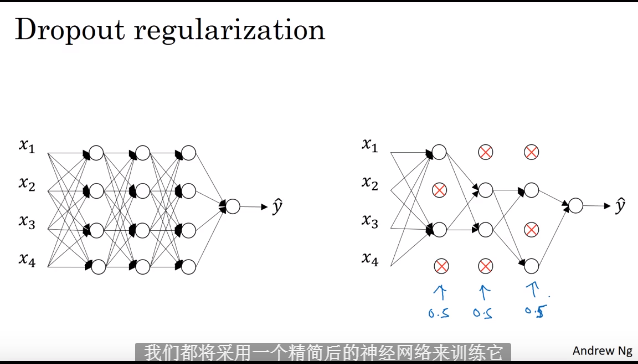
1.7 dropout的理解

- 计算机视觉领域,经常数据过少,容易产生过拟合,默认使用dropout方法
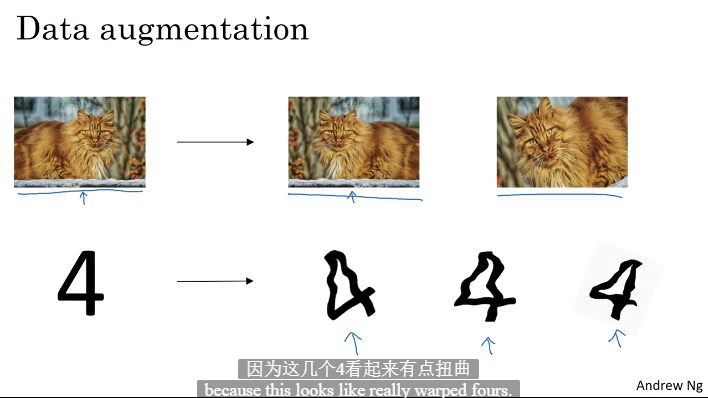
1.8 其他正则化方法
- 通过编码基于原数据增加训练数据
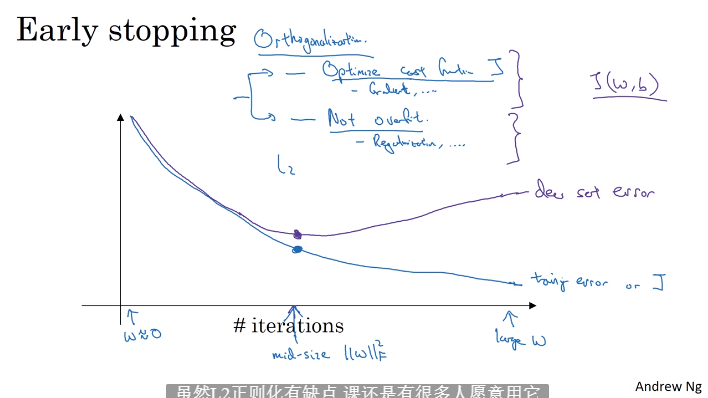
- 提前终止训练
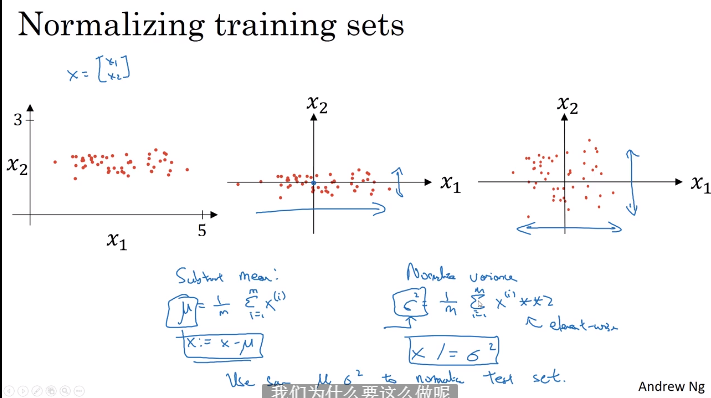
1.9 归一化输入
- 使用u实现0均值化,使用sgma实现方差1,使用相同u,sgma变换训练集,测试集,验证集
- 归一化有利于代价函数更快找到最优解

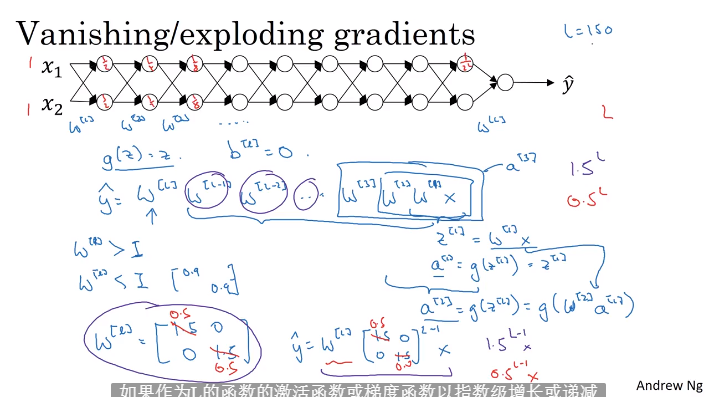
1.10 梯度消失与梯度爆炸
- 对于深度神经网络,多项权重相乘,如果都小于1会使得梯度接近0(消失),如果都大于1,会使得梯度非常大(爆炸)
- 梯度爆炸导致权重跟新幅度大,梯度消失导致权重跟新缓慢
1.11 神经网路的权重初始化
- 可以不彻底的解决梯度消失与爆炸问题
- 借用高斯分布随机数初始化权重

1.12 梯度的数值逼近

1.13 梯度检验
- 矩阵转一个大向量
- 双边检验梯度,用欧氏距离检测近似度

1.14 梯度检验实现的技巧

第二周 优化算法
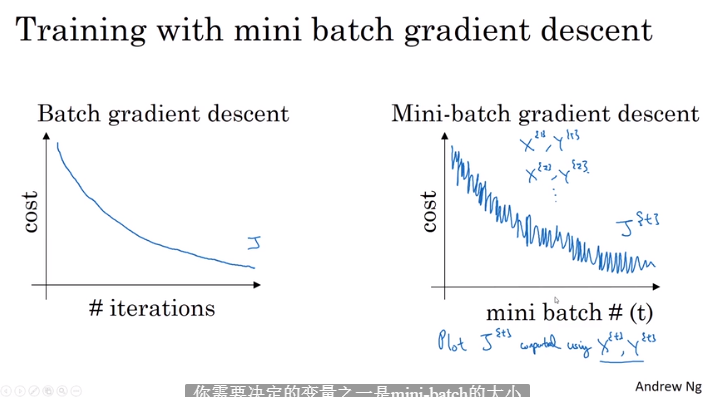
2.1 mini-batch 梯度下降


2.2 理解小批量梯度下降

2.3 指数加权平均
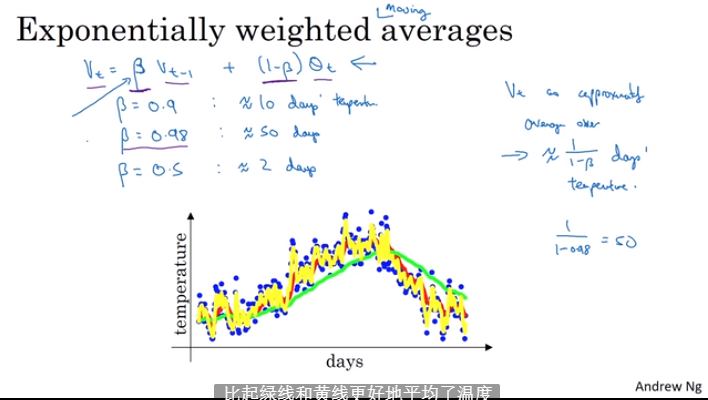
2.4 理解指数加权平均数

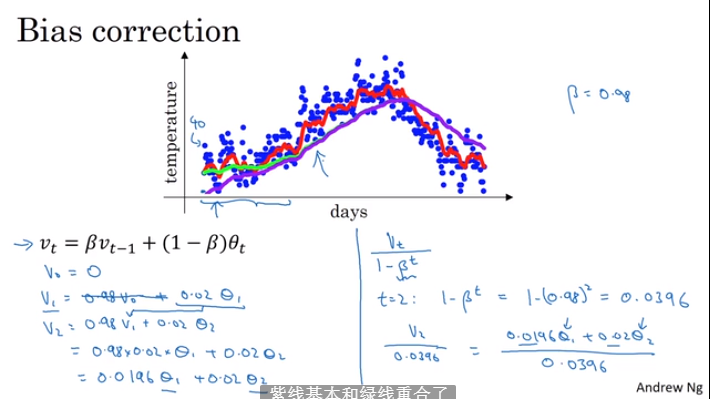
2.5 指数加权的偏差修正
2.6 动量梯度下降法


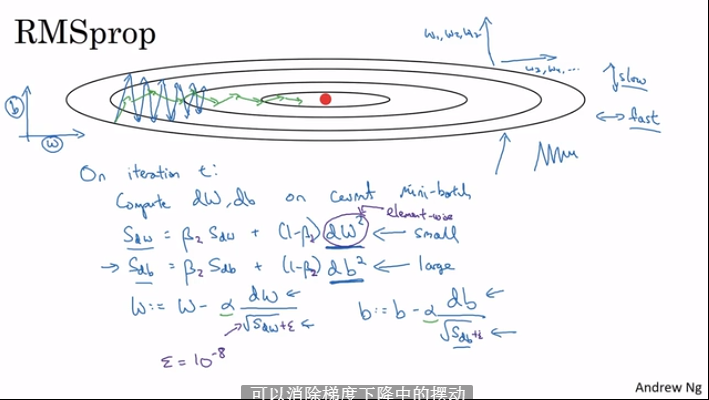
2.7 RMSprop
2.8 Adam优化算法
- 结合动量和RMSprop算法


2.9 学习率衰减
- 随时间进行减小学习率


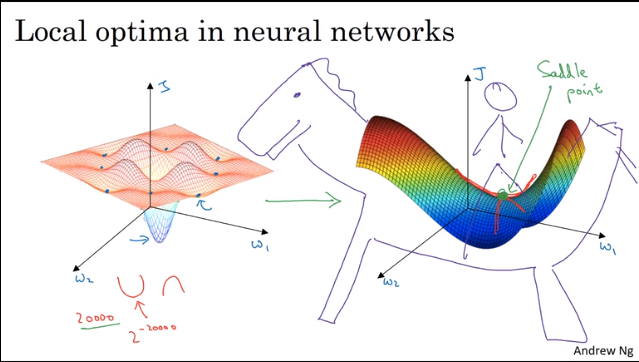
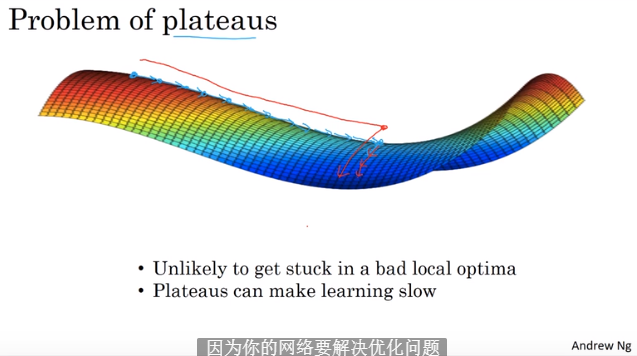
2.10 局部最优问题
第三周 超参数调试,batch正则化和程序框架
3.1 调试处理

- 随机选择分布的超参数进行调试
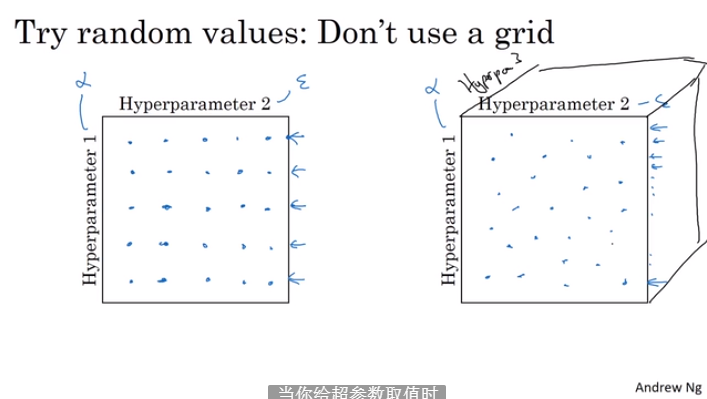
- 先缩小区域,在小区域内寻找

3.2 为超参数选择合适的范围
- 网格均匀选取

- 随机取值

- 取值逐渐精细

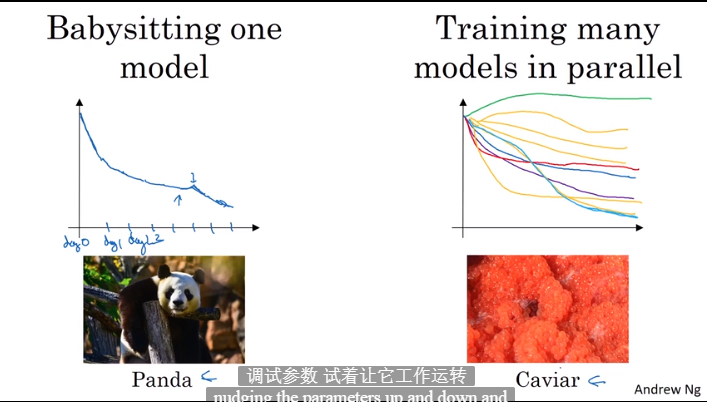
3.3 超参数训练的实践Pandas VS Caviar
- 偶然灵感寻找超参数
- 观察模型调整:数据多使用第一个,数据少使用第二个
3.4 正则化网络的激活函数
- 归一化有利于网络训练

3.5 将Batch norm 拟合神经网络
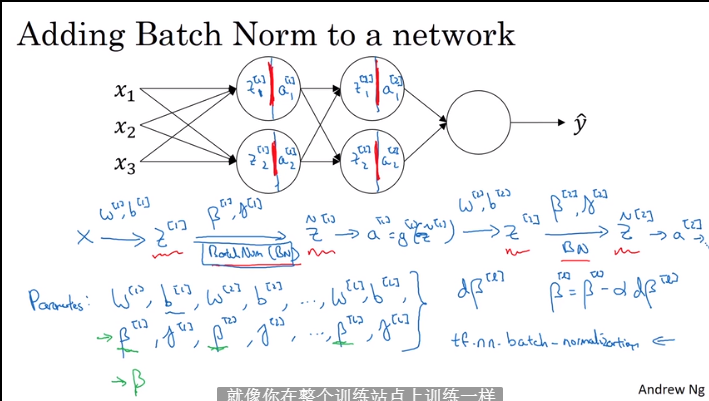


3.6 Batch Norm有效
归一化所有输入特征使其均值为0方差为1可以加速神经网络得学习

- 改变数据的分布
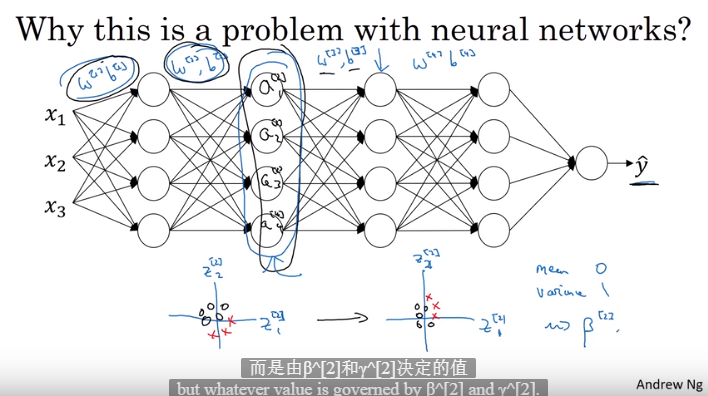
- 使网络层更加稳定,有轻微的正则化效果

3.7 测试时的Batch Norm

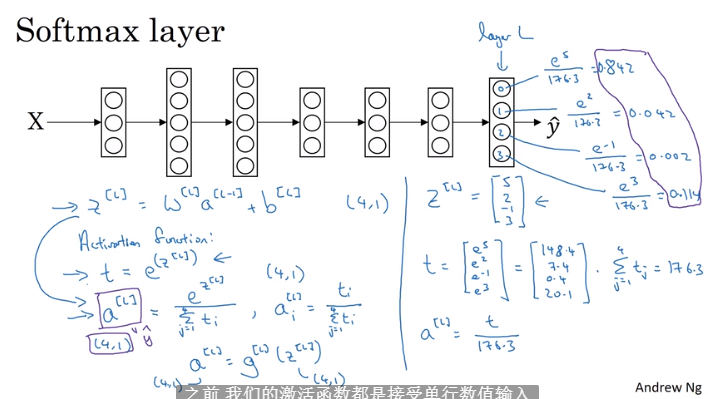
3.8 softmax回归
- 进行除了2分类的多分类问题
- 4个分类输出四个分类的概率
- 将输出Z转换为和为1的0-1之间的映射即是概率
- 单层逻辑回归的神经网络模型就是线性划分模型
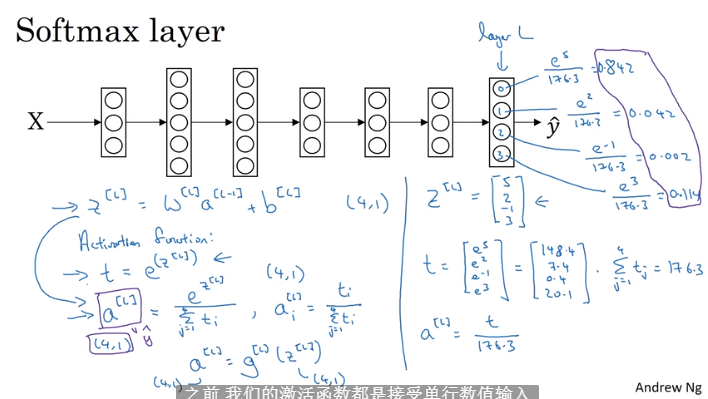
3.9 训练一个softmax分类器



3.10 深度学习框架
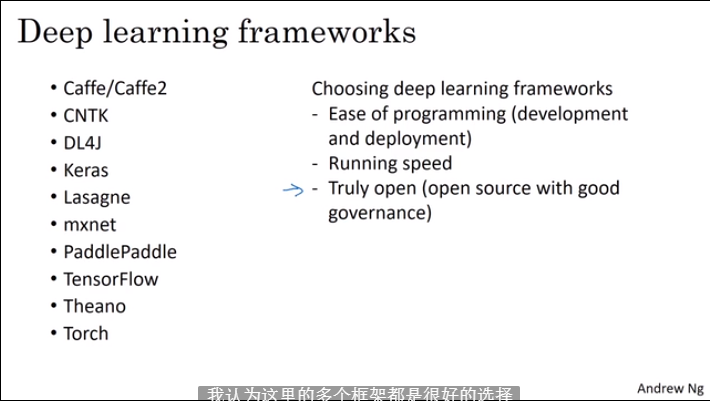
3.11 TensorFlow


 浙公网安备 33010602011771号
浙公网安备 33010602011771号