学霸数据处理项目之数据处理网页以及后台以及C#代码部分开发者手册
写在前面,本文将详细介绍学霸数据处理项目中的数据处理网页与后台函数,以及c#代码中每一个方法的意义及其一些在运行方面需要注意的细节,供开发人员使用,开发人员在阅读相关方法说明时请参照相关代码,对于本文中的错误和疏漏对您造成的不便深表歉意。
一、VisitRemoteServer.cs
此文件隶属于工程VisitRemoteServer,用途是访问远程服务器,将文件从远程服务器上下载到本地和 将本地文件上传到远程服务器,此文件主要用于生成dll并供php调用,其主要作用是将本地修改的control2.json(控制爬虫的文件)上传到爬虫所在的服务器变为control.json ,以及在远程服务器上的文件(state.json)(用于显示爬虫运行状况),下载到本地变为(state2.json)。整个C#工程是一个class library工程,详细的生成dll的过程见https://zhidao.baidu.com/question/1173763976976599699.html 或http://www.piaoyi.org/php/PHP-C-dll.html不再 缀续,但需要注意的是,最后在生成com组件以及注册成全局com组件的时候,如果使用vs自带的开发者工具命令行,会显示权限不足,使用管理员权限的命令行,在使用上述网址中的命令的时候,会显示无此命令,如若出现此类问题,可采用如下解决办法,使用管理员权限的命令行,切换到dll所在目录输入如下指令
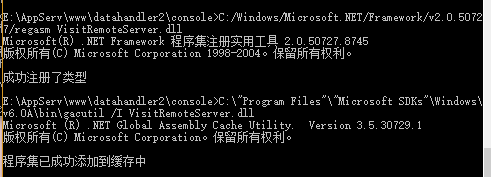
具体的目录可能因配置不同而有所差异,但目录结构应该类似 ,如此便解决了这个问题,但要此时想在php中使用如下dll中的函数依旧会有问题,我所使用的服务器框架时wamp框架,在安装目录下找到AppServ\php5\php.ini文件,使用文本编辑工具打开它,在末尾添加
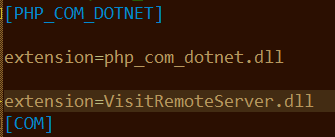
之后重启apache服务,即可在php中调用dll中函数了,为了测试函数的正确性,下面介绍如下代码
二、Crawler.php
此文件主要是对爬虫的操作和状态的检测。
1)getState中首先new了一个COM然后调用了之前dll写好的getFromNetWorkConnection函数,如若返回true,代表远程的state.json已经下载,此时读取本地state2.json(即为远程的state.json)并返回内容、
2)setState中首先将传入的字符串写进control2.json中,然后new com并调用setFromNetWorkConnection将文件上传从而实现对爬虫的操作 。之后将control2.json文件的内容返回是为了在网页上及时响应用户请求。
需要注意的是,C#代码中使用到的技术是虚拟磁盘技术,简单来讲就是把远程服务器视为本地的X盘,从而对其进行操作,其中的一个问题是,传入的参数远程路径一定具有唯一性代表性,本地路径一定存在,否则会报错,可以通过错误编号编号查找错误原因。
三、DownloadFile.cs
此文件与VisitRemoteServer.cs文件类似,此文件多了 一个deleteFileFromLocal方法,此工程并不是为了生成class library,而是为了java程序使用,c#程序如何由java程序调用请参照另一位小组成员博客,不再缀续。此方法主要是在数据处理过程前,需要将远程服务器 中的文件先下载到本地,然后进行处理,处理后在删除本地临时文件时使用。
四、setCrawler.php
此文件主要是由crawlerjs.js调用,然后间接调用Crawler.php中的setState方法
五、getCrawler.php
此文件主要是由crawlerjs.js调用,然后间接调用Crawler.php中的getState方法
六、DataProcessing.php
此文件主要由DataProcessing.js调用。
1)getState方法获取数据处理程序当前运行状态,就是读取state.json文件中的内容。
2)restart方法会判断当前数据处理程序是否处于运行状态,如果正在运行,则返回当前状态,不执行任何操作,否则,设置control.json为既可以运行,同时在运行前清除数据库中的文件处理标志位,最后运行java程序。
3)start方法,和restart方法类似,只不过它不会在运行前清除数据库中的文件处理标志位
4)myEnd方法,用于关闭数据处理程序,即将control.json文件中allowOpen置为false
文件中的switch语句会根据输入参数不同调用不同的处理函数,执行不同的操作,返回不同的值。
七、crawler.js
该文件用于对crawler.html文件中操作的响应。
1)isExistWeb函数用于判断该网页是否正在爬取中而不需要再度添加到候选列表中。
2)isExistKW函数用于判断该关键词 是否正在爬取中而不需要再度添加到候选列表中。
3)webFileSelect webFileSelected图片按钮选文件打开文件夹的一般格式函数,获取文件完整路径通过ajax同步通信获取到文件内容,并将解析处理完毕后的内容储存到control2.json文件上传,从而改变爬虫状态。
4)kWFileSelect kWFileSelected和上述原理相同
5)getFullPath获取对象的完整路径,根据不同的浏览器调用不同的函数获取完整路径,但由于浏览器处于对个人文件安全的保密需要,以firefox为例,这个完整路径并不是正常的绝对路径,而是一串乱码,但其含义确实是文件完整路径。
6)start开始爬虫,即 打开设置爬虫数的界面
7)confirm确认爬虫数,即将网页上显示的爬虫数存储到 control2.json文件中并上传。以及当输入爬虫数不合法时会在界面上显示一些异常信息。
8)stop关闭爬虫,其实是将爬虫个数限制为0,待所有已运行线程结束后,整个爬虫进入循环等待状态。
9)addWeb添加网址的方法,对的话会作为新的种子网址加入到候选列表,否则显示错误信息
10)addKeyWord添加关键词的方法,对的话会作为新的种子关键词加入到候选列表,否则显示错误信息
11)removeErrorInfo移除错误信息
12)delWeb删除一个候选网址
13)delKeyWord删除一个候选关键词
14)MyAutoRun2自动运行并实时更新爬虫的运行情况。
15)stateChanged_2是MyAutoRun2函数的回调函数,主要作用是根据返回信息实时更新爬虫的运行情况并显示在网页上
16)LoadWS网页刚开始打开时初始化网址列表和关键词列表。
17)stateChanged_WS是 LoadWS的回调 函数,主要作用是根据返回更新爬虫的网址列表和关键词列表并显示在网页上。
18)String.prototype.temp字符串匹配和替换函数。
八、DataProcessing.js
此文件主要由datahandler.html和crawler.html引用
1)MyAutoRun是自动运行函数,实时发送数据处理程序运行情况查询请求
2)begin发送开启 数据处理程序请求
3)rebegin发送重启数据处理程序请求
4)end发送关闭程序请求
5)stateChanged获取数据处理程序运行现状并展示在网页上。
6)divide字符串除法,将字符串转化为数字相除,用于进度条的长度计算。
7)stateChanged_end结束状态检查,如果结束失败则会继续发出结束请求。
8)GetXmlHttpObject获取xmlhttp对象用于网页前后端交互。
九、login.js
此文件主要由datahandler.html和crawler.html引用
即 为初始时登陆交互页面所需要的登陆框
1)login检查登陆信息,账户,密码是否正确,错误则提出错误信息,正确则退出登陆框
2)removeErrorInfo移除错误信息
3)showlogin判断当前是否处于登陆状态,如果不是,则弹出登陆框
4)gotoDataHandler切换到数据处理界面
5)gotoCrawler切换到爬虫界面
6)setCookie写入cookie
7)getCookie根据keyword获取关键词信息
8)delCookie删除cookie
十、运行准备
将所有文件放到对应目录下后,即可以运行程序了,文件对应目录如下,
本地服务器:(10.2.28.79)
数据处理程序(***.jar),state.json,control.json,state2.json,control2.json均放到Appserv/www/datahandle/console目录下
远程服务器:(10.2.28.78)
爬虫(***.jar),state.json,control.json,放到crawler.php文件中getState和 setState中的第一个参数(远程文件目录)的文件夹下。
十一、使用说明
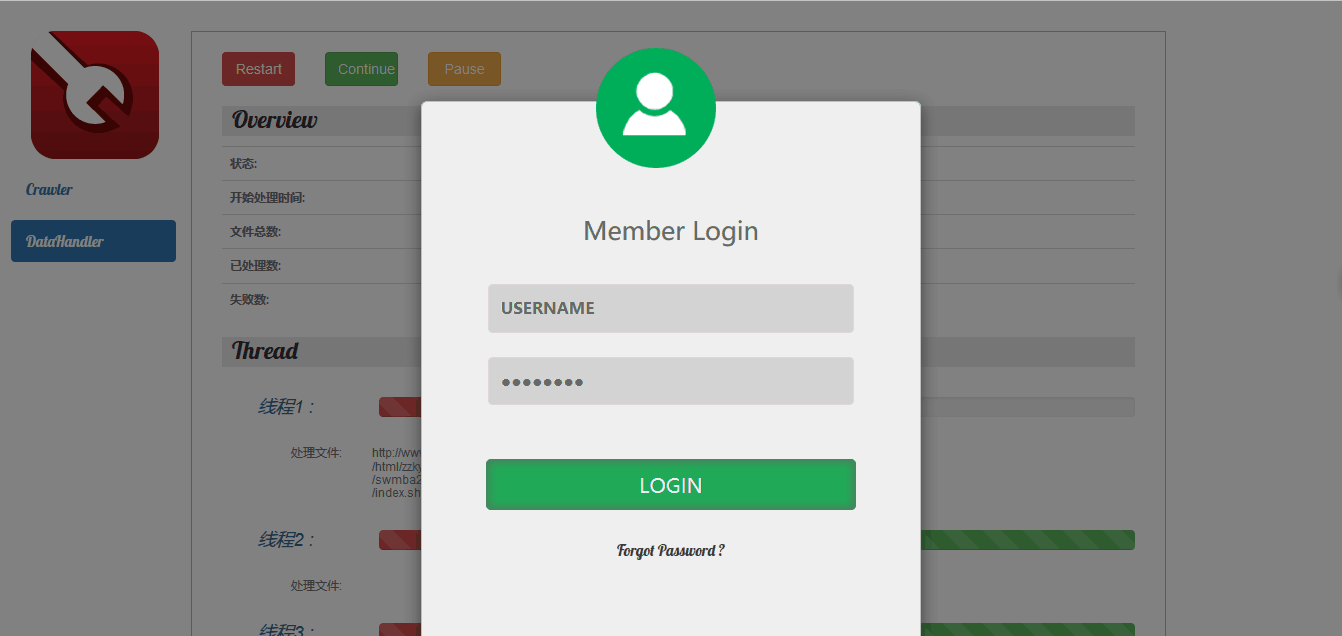
登陆界面:用户名为lwls,密码为123456
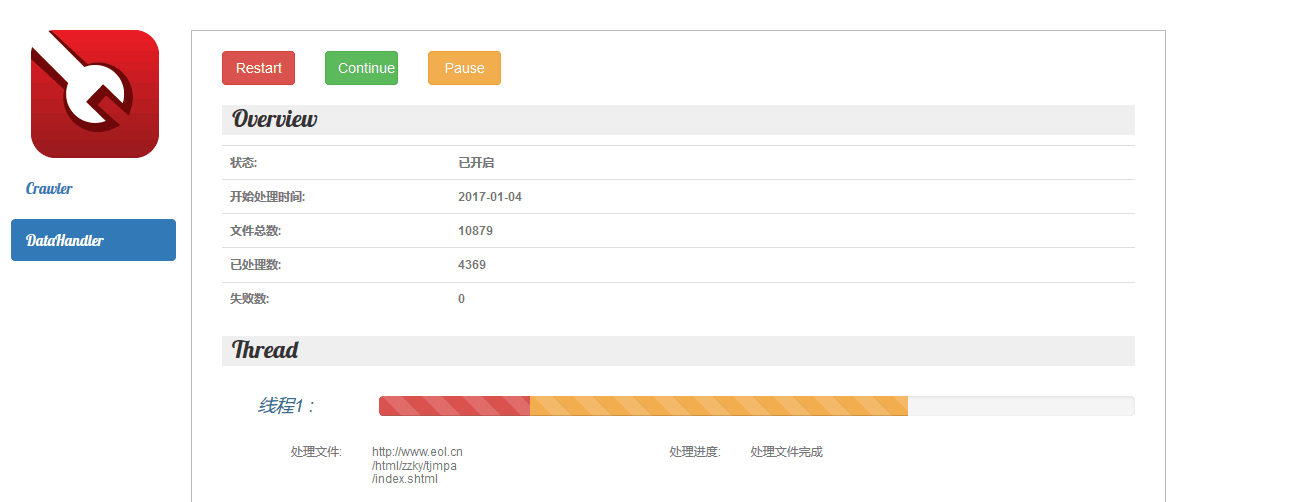
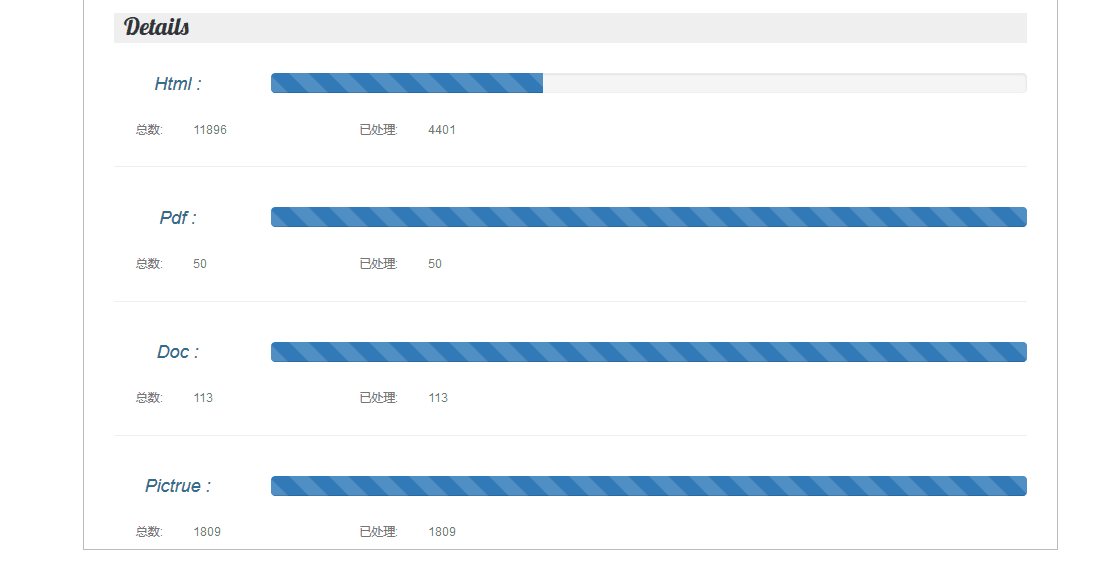
数据处理界面,显示各种文件信息,以及线程爬取信息,该界面总共有三个按钮,restart为重启,即清空数据库所有文件处理标示,重新开始处理,continue为继续,即接着处理数据库中文件标示为未处理的文件,pause为停止数据处理程序。
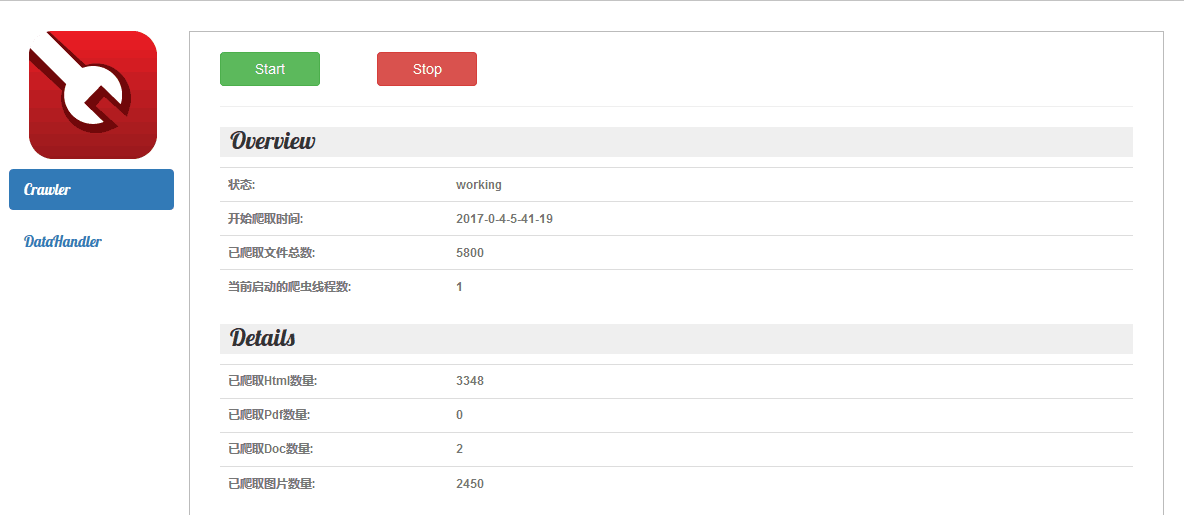
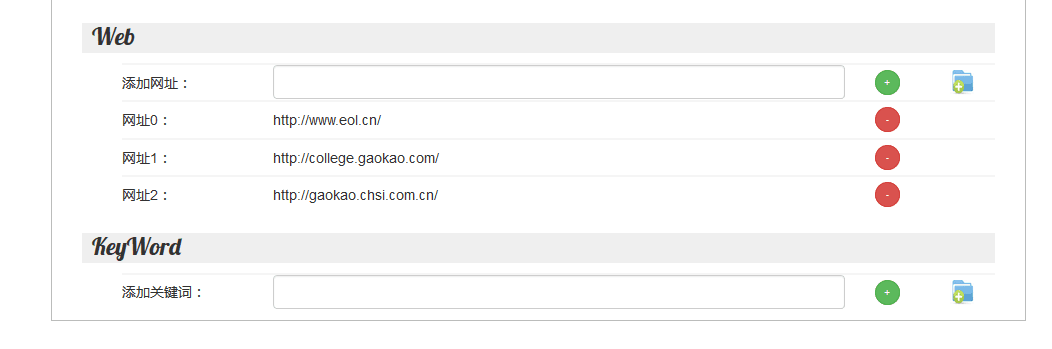
爬虫控制界面,使用左侧的导航栏可以在爬虫控制界面和数据处理界面之间切换,对于爬虫界面 而言,start是开启爬虫,stop是关闭爬虫,下方的添加网址和添加关键词功能可以在输入框内键入,然后按
按钮即可,也可以批量添加,使用 按钮选择文件添加,需要注意的是,添加的文件要符合json格式,例如添加网页为{"web":[{"URL":"http://stackoverflow.com"}]}添加关键词为 {"keyWord":[{"word":"A"}]}
按钮选择文件添加,需要注意的是,添加的文件要符合json格式,例如添加网页为{"web":[{"URL":"http://stackoverflow.com"}]}添加关键词为 {"keyWord":[{"word":"A"}]}
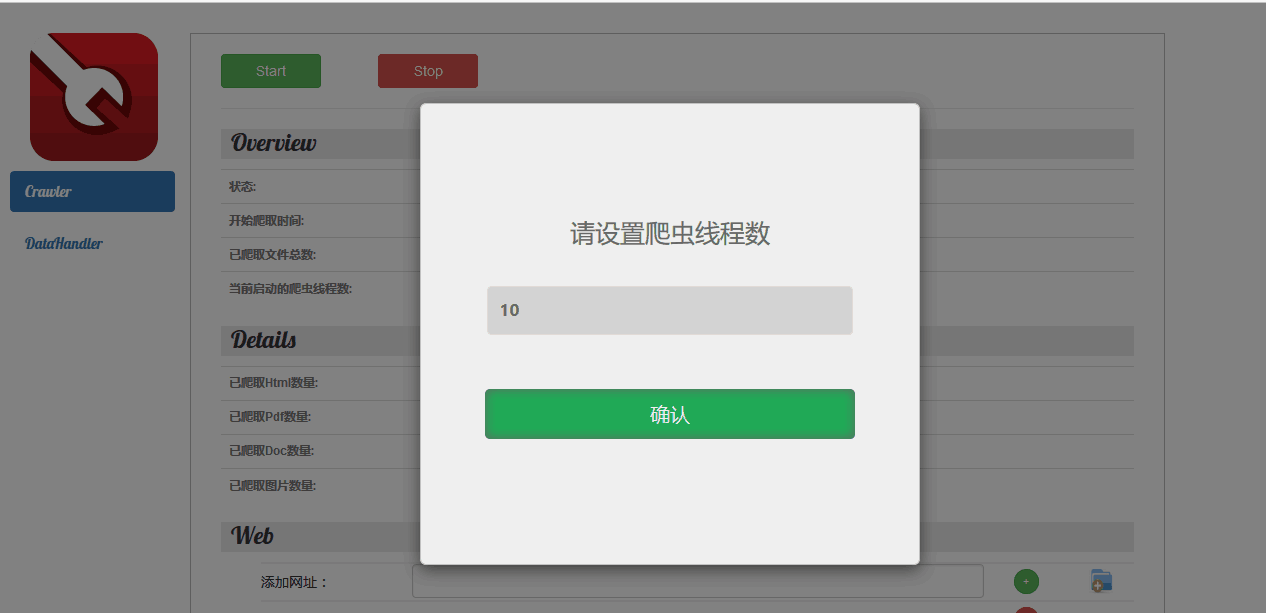
当点击 开始按钮时会弹出如下对话框,输入正确的数字点击确定就会执行,否则就会弹出报错信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号