

各种版本 WordCount
1 hadoop的MapReduce版
①mapper类
//KEYIN 输入数据的key //VALUEIN 输入数据的value //KEYOUT 输出数据的key //VALUEOUT 输出数据的value public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ private Text k = new Text(); private IntWritable v = new IntWritable(1); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //1.一行单词 String[] words = value.toString().split(" "); //2.循环写出 for (String word : words) { k.set(word); context.write(k, v); } } }
②reducer类
//KEYIN VALUEIN map阶段输出的key和value public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ private IntWritable v = new IntWritable(); @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { //1.累加求和 int sum = 0; for (IntWritable value : values) { sum += value.get(); } //2.写出 v.set(sum); context.write(key, v); } }
③driver类
public class WordCountDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration(); //1.获取Job对象 Job job = Job.getInstance(conf ); //2.设置Jar存储位置 job.setJarByClass(WordCountDriver.class); //3.关联Mapper和Reducer类 job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); //4.设置map阶段输出数据的key和value类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //5.设置最终数据输出的key和value类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //6.设置输入路径和输出路径 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); //7.提交Job boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } }
运行时须指定输入输出路径
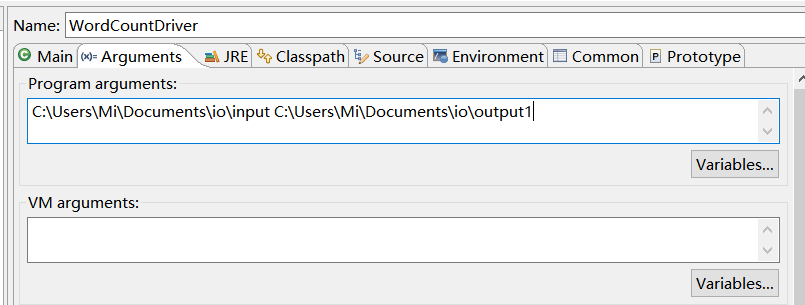
2 Java8 Stream版
public static void main(String[] args) throws ParseException { ArrayList<String> list = new ArrayList<>(); list.add("scala hadoop linux scala"); list.add("word hello world hadoop spark"); list.add("hello world spark scala"); Map<String, Long> result = list.stream() .flatMap(str -> Arrays.stream(str.split(" "))) .collect(Collectors.groupingBy( Function.identity() //按照单词自身分组 , Collectors.counting()) //分组后直接count ); System.out.println(result); //{world=2, spark=2, scala=3, linux=1, hello=2, hadoop=2, word=1} }
3 scala原始版
def main(args: Array[String]): Unit = {
//word count
val lines = List[String]("scala hadoop linux scala","word hello world hadoop spark","hello world spark scala")
//空格切割扁平化
val res1: immutable.Seq[String] = lines.flatMap(_.split(" "))
println(res1) //List(scala, hadoop, linux, scala, word, hello, world, hadoop, spark, hello, world, spark, scala)
//映射成元组
val res2: immutable.Seq[(String, Int)] = res1.map((_, 1))
println(res2) //List((scala,1), (hadoop,1), (linux,1), (scala,1), (word,1), (hello,1), (world,1), (hadoop,1), (spark,1), (hello,1), (world,1), (spark,1), (scala,1))
//将上一步的元组分组
val res3: Map[String, immutable.Seq[(String, Int)]] = res2.groupBy(_._1)
println(res3) //Map(world -> List((world,1), (world,1)), hadoop -> List((hadoop,1), (hadoop,1)), spark -> List((spark,1), (spark,1)), scala -> List((scala,1), (scala,1), (scala,1)), linux -> List((linux,1)), hello -> List((hello,1), (hello,1)), word -> List((word,1)))
//value的长度就是单词的个数
val res4: Map[String, Int] = res3.map(x => (x._1, x._2.size))
println(res4) //Map(world -> 2, hadoop -> 2, spark -> 2, scala -> 3, linux -> 1, hello -> 2, word -> 1)
//倒序展示
val res = res4.toList.sortBy(_._2).reverse
println(res) //List((scala,3), (hello,2), (spark,2), (hadoop,2), (world,2), (word,1), (linux,1))
}
4 spark版
单词文件
Hello Scala Hello Spark Hello BigData Hadoop Yarn Scala Java
代码
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("word count")
val sc = new SparkContext(conf)
//从文件生成RDD
val rdd = sc.textFile("input/word.txt")
//切割扁平化
val flatMapRDD: RDD[String] = rdd.flatMap(_.split(" "))
//映射成元组
val mapRDD: RDD[(String, Int)] = flatMapRDD.map((_, 1))
//按照key进行聚合
val reduceByKeyRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_ + _)
//倒序展示
reduceByKeyRDD.sortBy(_._2,false).collect().foreach(println)
//(Hello,3)
//(Scala,2)
//(Yarn,1)
//(Java,1)
//(BigData,1)
//(Spark,1)
//(Hadoop,1)
}
