recurrent model for visual attention
paper url: https://papers.nips.cc/paper/5542-recurrent-models-of-visual-attention.pdf
year: 2014
abstract
这篇文章出发点是如何减少图像相关任务的计算量, 提出通过使用 attention based RNN 模型建立序列模型(recurrent attention model, RAM), 每次基于上下文和任务来适应性的选择输入的的 image patch, 而不是整张图片, 从而使得计算量独立于图片大小, 从而缓解 CNN 模型中计算量与输入图片的像素数成正比的缺点. 该文通过强化学习的方式来学习任务明确的策略, 从而解决模型是不可微的问题.
RAM 模型在几个图像分类任务上,在处理杂乱图像(cluttered images)时, 它明显优于基于CNN的模型,并且在动态视觉控制问题上,无需明确的训练信号, 它就能学习跟踪一个简单的对象。
introduction
该文将注意力问题视为与视觉环境交互时以目标为导向的序列决策过程。
人类感知的一个重要特性是人们不会倾向于一次完整地处理整个场景。 相反,人们将注意力有选择地集中在视觉空间的某些部分,以便在需要的时间和地点获取信息,并随着时间的推移组合来自不同固定位置(fixation)的信息,以建立场景的内部表示,指导下一步眼睛看下哪里以及决策。 将计算资源聚焦在场景的各部分上节省了“带宽”,因为需要处理的“像素”更少。 但它也大大降低了任务复杂性,因为感兴趣的对象可以置于固定位置(fixation)的中心,并且固定区域外的视觉环境(“混乱”)的不相关特征自然被忽略。
model architecture
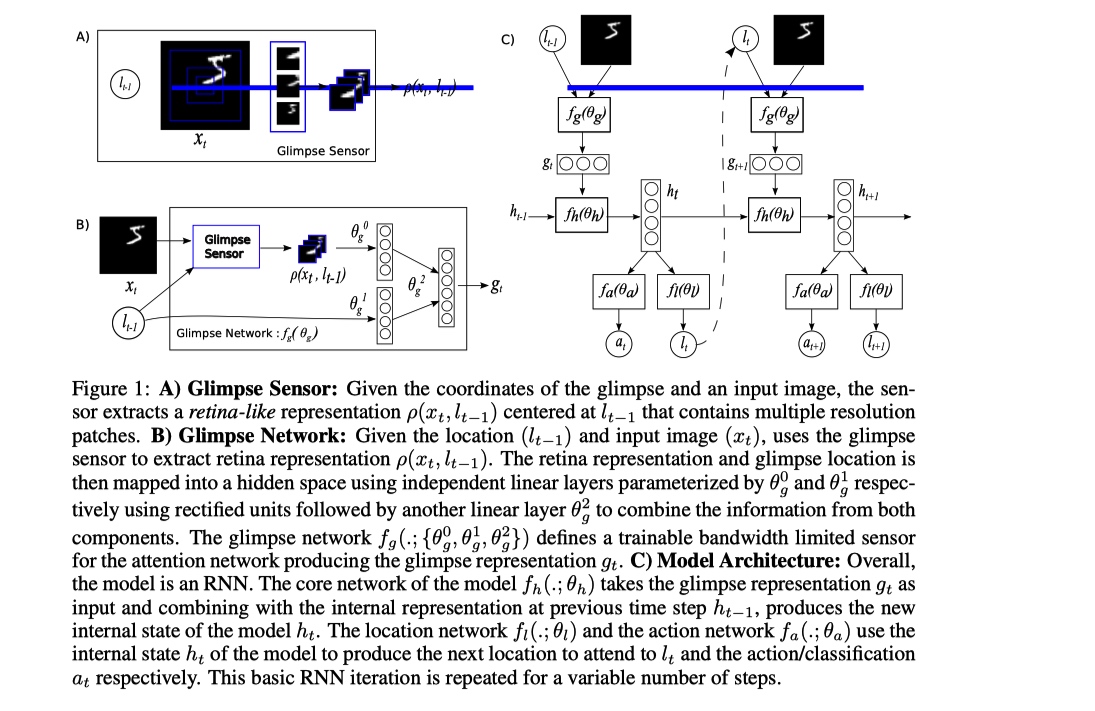 

thought
这篇论文时间比较早, 在当时 CNN backbone 以及目标检测的发展和现在相比相差太多. 在解决 CNN 的计算量问题上, 通过不输出整张图片, 而是利用 RNN 模型建模, 然后使用 attention+强化算法 来决定序列每一个阶段模型看向图片的哪一个 patch, 从而获取与任务相关的关键信息, 过滤掉了无关信息, 从而使得模型计算量独立于图片的输入尺寸, 减小计算量.
利用 RNN 模型来进行视觉任务特征提取, 对于我个人来说是很新颖的思想. 个人觉得, 就视觉 attention 来说, 我感觉不将整张图片作为输入, 而是每次只送入 image patch 的做法是当时妥协的产物. 我觉的视觉 attention 只有在获取全局信息之后, 然后才能基于相关性, 选择的关注一些相关性高的区域来提升处理效率. 如果一开始就是盲人摸象, 我不知道该如何相信系统的决策, ps:个人不了解强化学习相关知识.
总之, 思想很新, 但是实现过于复杂, 而且这种基于局部信息的 attention 感觉并不可靠.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号