A Discriminative Feature Learning Approach for Deep Face Recognition
url: https://kpzhang93.github.io/papers/eccv2016.pdf
year: ECCV2016
abstract
对于人脸识别任务来说, 网络学习到的特征具有判别性是一件很重要的事情. 增加类间距离, 减小类内距离在人脸识别任务中很重要.
那么, 该如何增加类间距离, 减小类内距离呢?
通常, 我们使用 softmax loss 作为分类任务的loss, 但是, 单单依赖使用 softmax 监督学习到的特征只能将不同类别分开, 却无法约束不同类别之间的距离以及类内距离. 为了达到增加类间距离, 减小类内距离的目的, 就需要额外的监督信号, center loss 就是其中一种.
center loss 包含两个流程:
- 学习一个类别的深度特征的中心
- 使用该中心约束属于该类别的特征表示
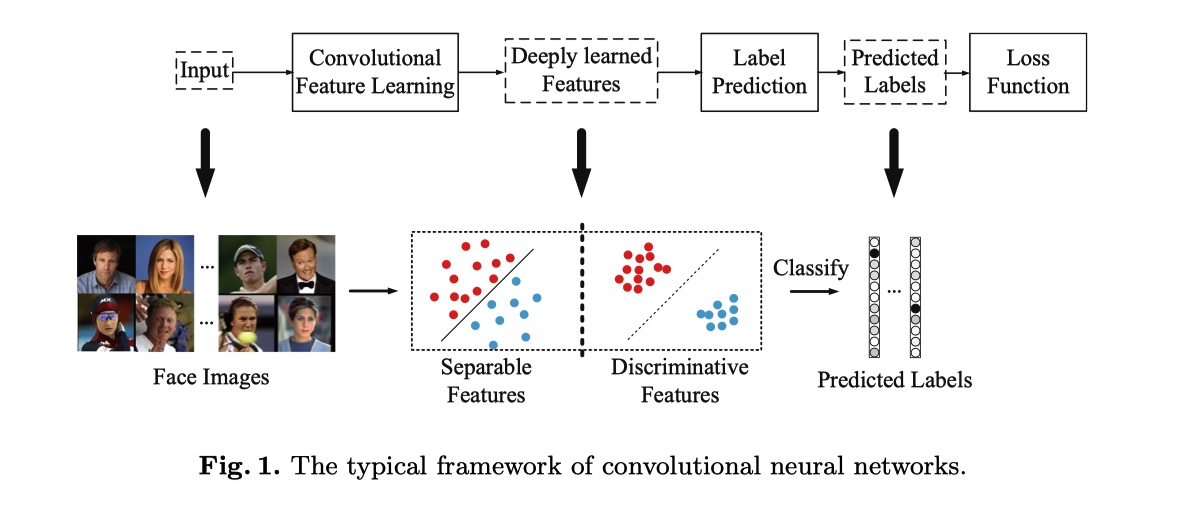 

最常用的CNN执行特征学习和标签预测,将输入数据映射到深度特征(最后隐藏层的输出),然后映射到预测标签,如上图所示。最后一个完全连接层就像一个线性分类器,不同类的深层特征通过决策边界来区分。
center loss design
如何开发一个有效的损失函数来提高深度学习特征的判别力呢?
直观地说,最小化类内方差同时保持不同类的特征可分离是关键。
center loss 形式如下:
 

\(c_{y_i} \in R^d\) 为第\(y_i\)类的特征表示的中心
center 更新策略
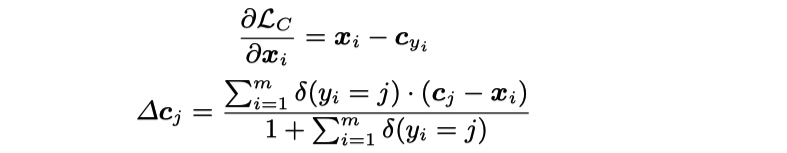 

total loss 函数
 

 

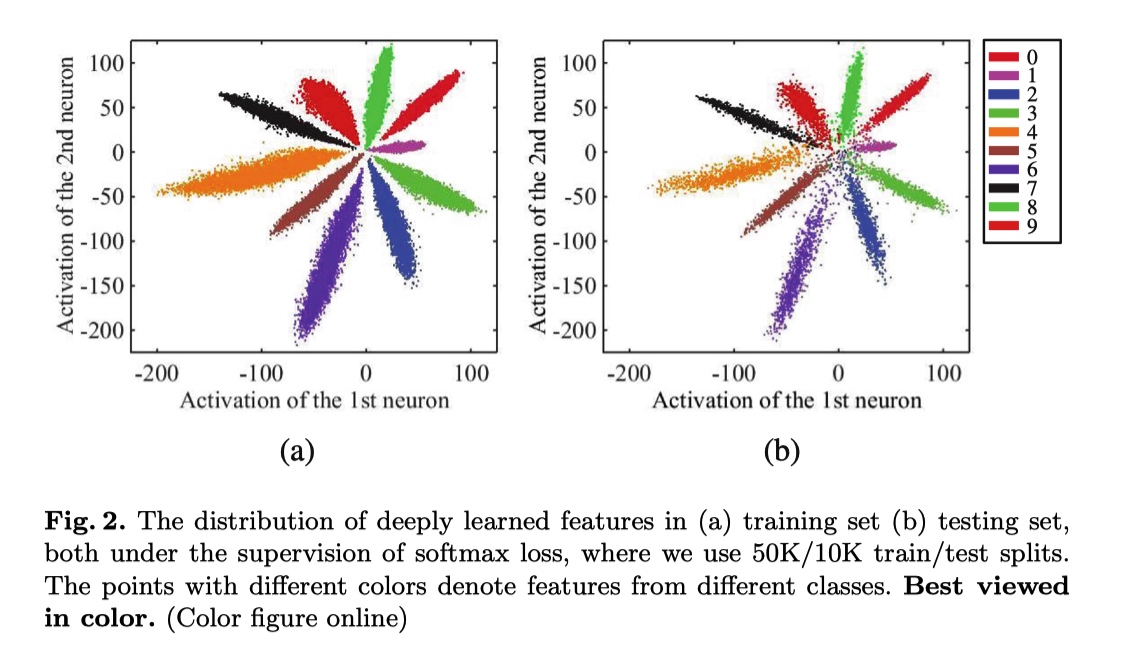
toy experiment 可视化

 

超参设置实验
\(\lambda \quad\) softmax 与 center loss的平衡调节因子
\(\alpha \quad\) center 学习率, 即$ center -= \alpha \times diff$
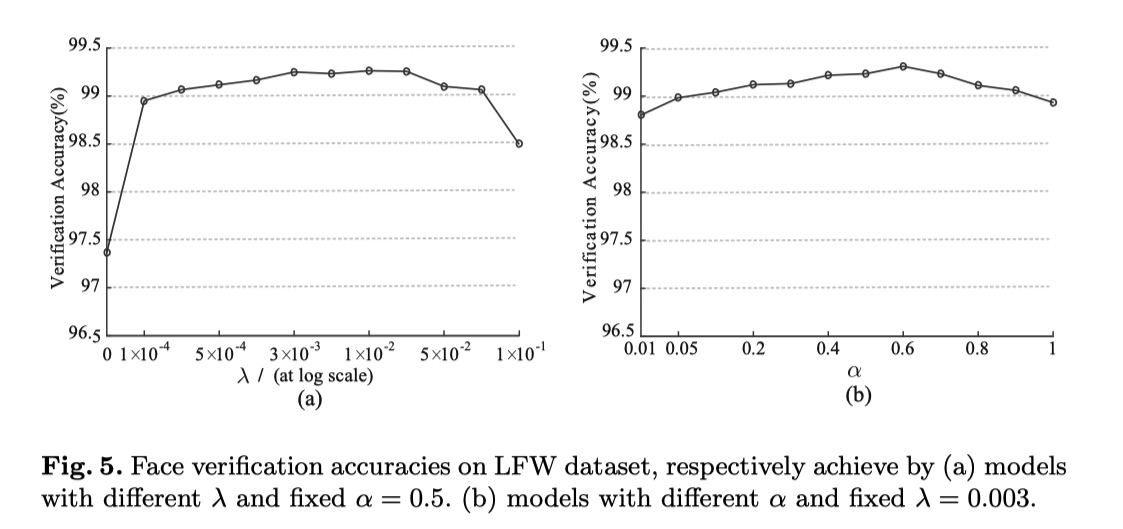 

experiment result
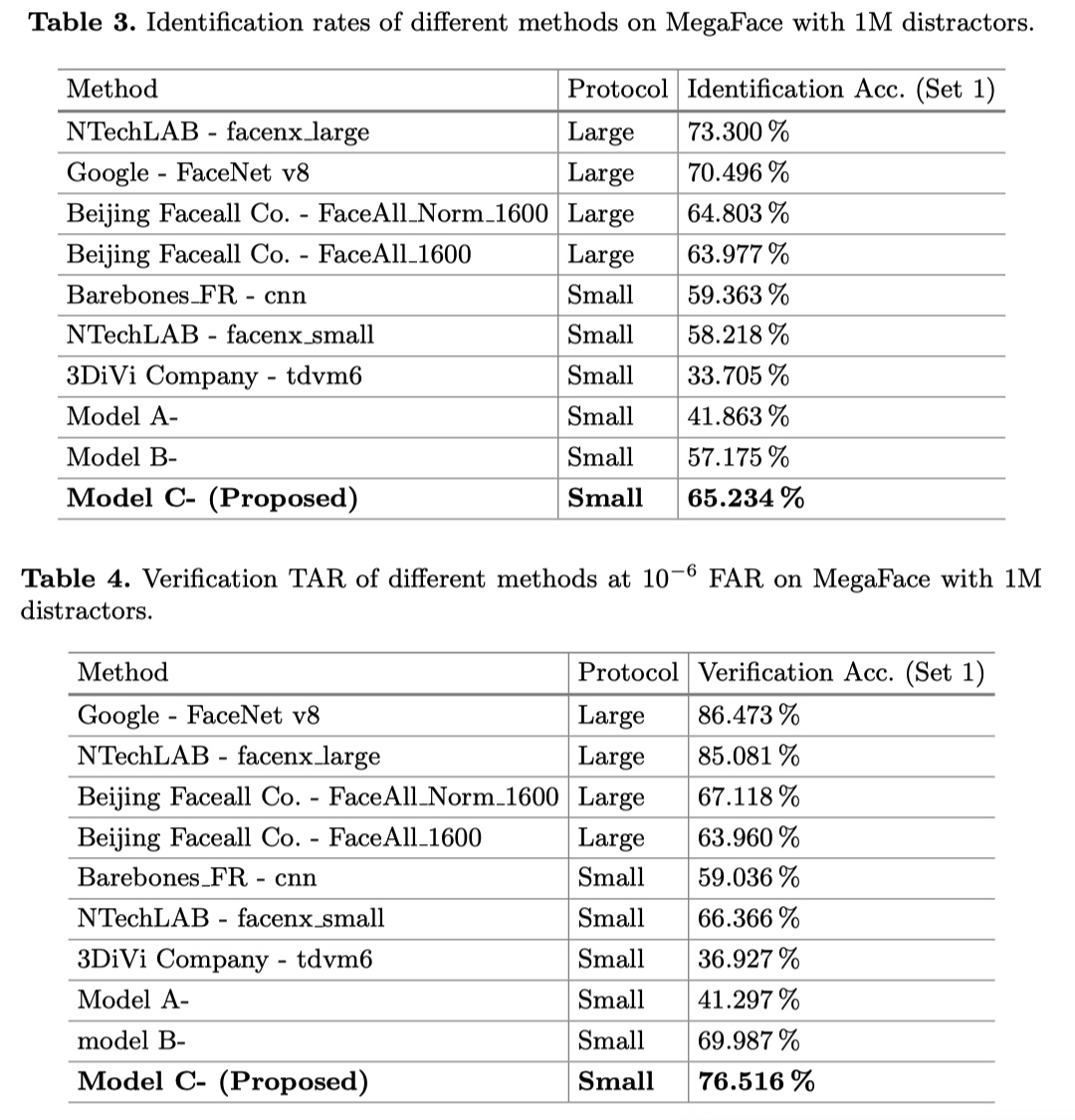 

thought
就身边的哥们用 center loss 的经验来看, center loss 在用于非人脸识别的任务上, 貌似效果一般或者没有效果. 可能只有像人脸任务一样, 类内深度特征分布聚成一簇的情况下, 该 loss 比较有效. 如果分类任务中, 类内特征差异比较大, 可能分为几个小簇(如年龄预测), 该 loss 可能就没有啥用处了. 而且 center loss 没有做特征归一化, 不同类的特征表示数量级可能不一样, 导致一个数量级比较大特征即使已经很相似了, 但是其微小的差距也可能比其他的数量级小的特征的不相似时的的数值大.
而且, 学习到的 center 只用于监督训练, 在预测过程中不包含任何与 center 的比较过程.
就学习 center 这一思想而言, 感觉 cosface 中提到的 large margin cosine loss 中用于学习 feature 与权重之间的 cosine 角度, 比较好的实现这种学习一个 center(以 filter 的权重为 center), 然后让 center 尽量与 feature 距离近的思想可能更好一点, 即能在训练时规范 feature 与 center 之间的距离, 又能在预测时候, 通过与 center 比对 cosine 大小来做出预测.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号