Network in Network

论文要点:
- 用更有效的非线性函数逼近器(MLP,multilayer perceptron)代替 GLM 以增强局部模型的抽象能力。抽象能力指的模型中特征是对于同一概念的变体的不变形。
- 使用 global average pooling 代替全连接层,提高模型的泛化能力。
GLM 与 MLP 的输入都是局部“像素”
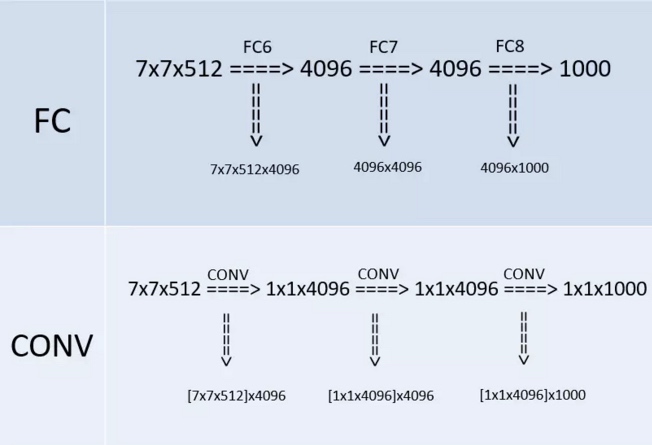
全连接层可以替换成 1×1 卷积层
这个要好好想想!!!

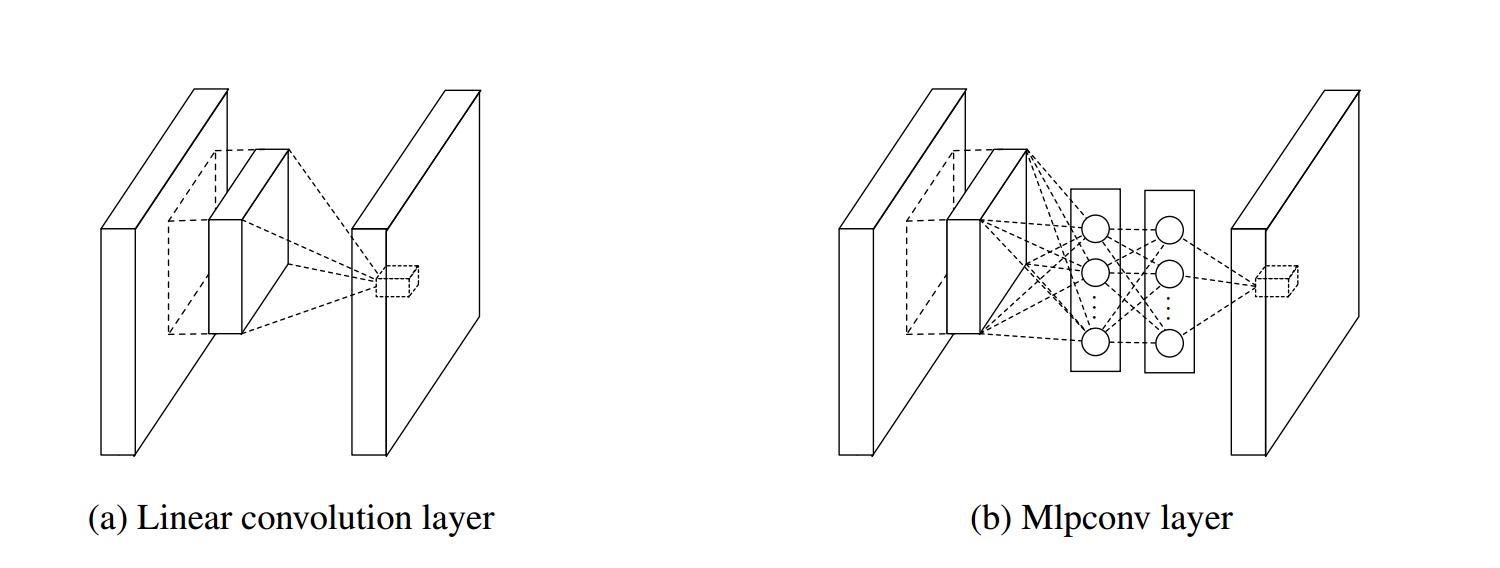
Mlpconv layer
结合下图,来谈谈 Mlpconv layer 的要点:
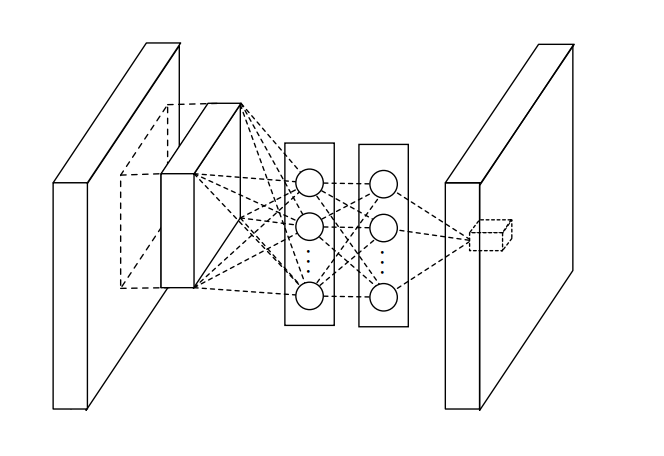 

从交叉通道(即交叉特征映射)池化的角度来看,上图中的网络结构等效于在正常卷积层上的级联交叉通道参数池化层。 每个池化层都会在输入特征图(input feature map)上执行加权线性重组,然后通过整流线性单元。 交叉通道池化所生成的特征图再作为下一交叉通道池化的输入,依次进行下去。这种级联的交叉通道参数池化结构允许交叉通道信息的进行复杂且可学习的交互。 交叉通道参数化池层也等价于具有1x1卷积核的卷积层。
上面是论文中对 NiN 一个很重要的解释,下面解释一下:交叉通道参数池化层也等价于具有1x1卷积核的卷积层到底是何意?
我们就以上图 MLP 的第一层为例说明一下,我们看到上图中一个 patch 作为 MLP 得输入,MLP 第一层的神经元我们可以看成是传统 CNN 中的 filter,即我们在同一个 patch 上同时使用多个 filter(然后通过relu),并且在 MLP 中的第二层将这些 filter 的输出进行线性组合(然后通过 relu),然后通过第三层输出一个值。 这与通过传统 CNN 卷积然后使用 1×1 卷积将一个 patch 上的多个 filter 加权线性组合的总体效果相同,比如一个3层 MLP 来可以通过两次 1×1 卷积(每次过 relu)来达到相同效果。
注意!!! 一个 MLP filter 在一个 patch 上只输出一个值,一个 MLP filter在整个输入层上共享参数,所以和传统 filter 一样, 这里使用多个MLP filter, 而MLP filter 的个数就是下一层feature map的深度。举例如下,下图为使用 NiN 改进的 AlexNet 的网络结构
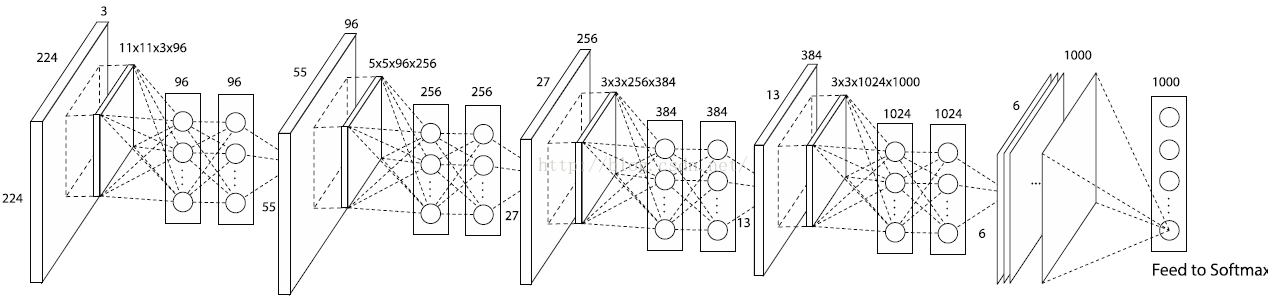 

global average pooling
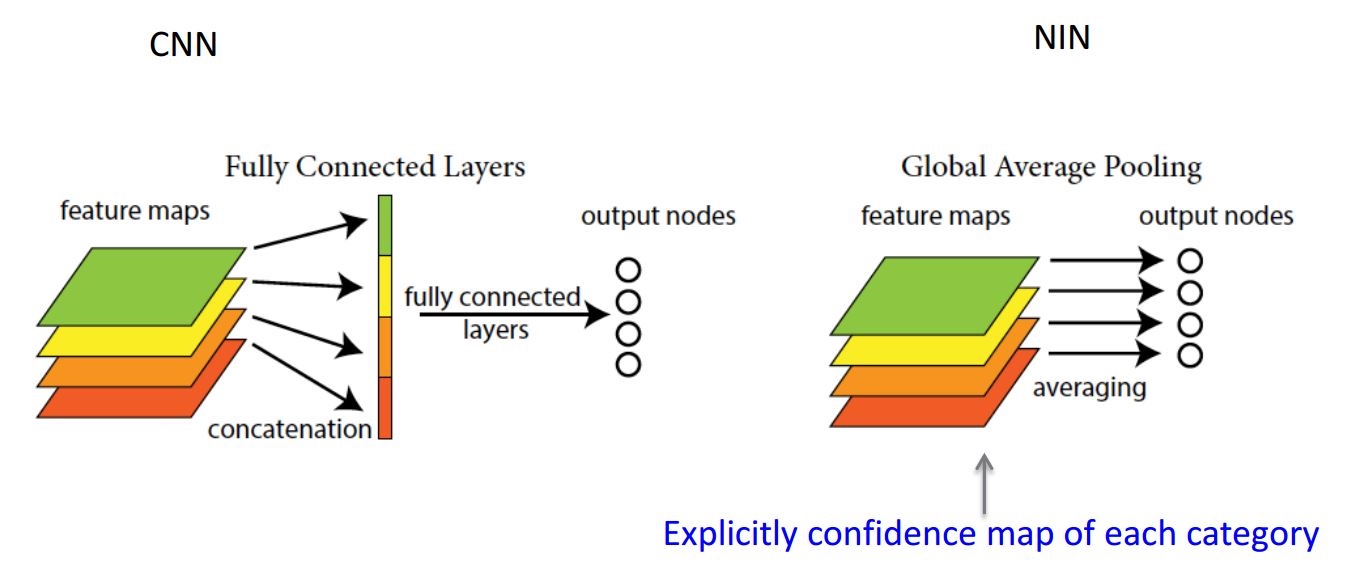 

global average pooling 与 average pooling 的差别就在 "global" 这一个字眼上。global 与 local 在字面上都是用来形容 pooling 窗口区域的。 local 是取 feature map 的一个子区域求平均值,然后滑动这个子区域; global 显然就是对整个 feature map 求平均值了。因此,global average pooling 的最后输出结果仍然是 10 个 feature map,而不是一个,只不过每个 feature map 只剩下一个像素罢了,这个像素就是求得的平均值,10个feature map就变成一个10维的向量,然后直接输入到softmax中。
global average pooling 极大地减少了模型的参数个数,防止模型过拟合,自带正则化光环

 浙公网安备 33010602011771号
浙公网安备 33010602011771号