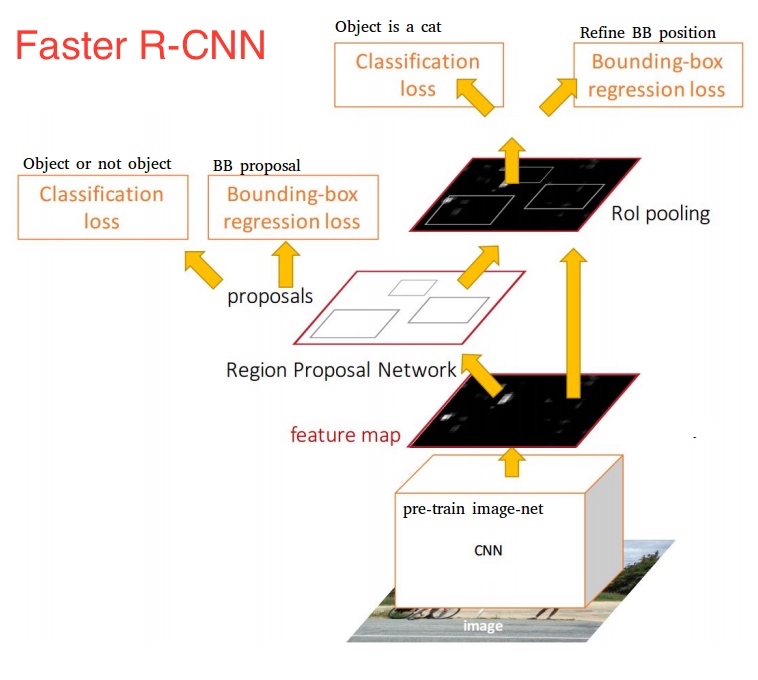
Faster R-CNN

目标检测的复杂性由如下两个因素引起,
1. 大量的候选框需要处理,
2. 这些候选框的定位是很粗糙的, 必须被微调
Faster R-CNN 网络将提出候选框的网络(RPN)和检测网络(Fast R-CNN)融合到一个网络架构中, 从而很优雅的处理上面的两个问题, 即候选框的提出和候选框的微调, 两个模块具体作用为:
1. RPN (Region Proposal Network),用于提出候选框 RoI(Region of Interest, 直译为感兴趣的区域, 即我们认为可能包含物体的区域);
2. Fast R-CNN (简称 FRCN) 检测器,它使用了 RPN 提出的 RoIs 进行分类和框的微调。
简单来说, Faster R-CNN 的前向推导过程如下
1. 图片经过 anchor 产生先验框 anchor boxes;
2. anchor boxes 通过 bbox regressor 调整位置;
3. 利用 objectness cls(分类器)的输出(判断候选框中是否包含物体, 有或者没有)降序排序, 基于排序进行 NMS, 首先处理得分较高的, 与较高得分的 bounding box 的 iou 值大于阈值的剔除掉(很大概率框中物体是同一物体), 提出 RoIs(训练时使用2000个)
4. 将 RoIs 交给 Fast R-CNN.
下面我们依次介绍 Fast R-CNN 和 RPN 这两个模块从而详细的了解下 Faster RCNN 目标检测的流程.
Fast R-CNN
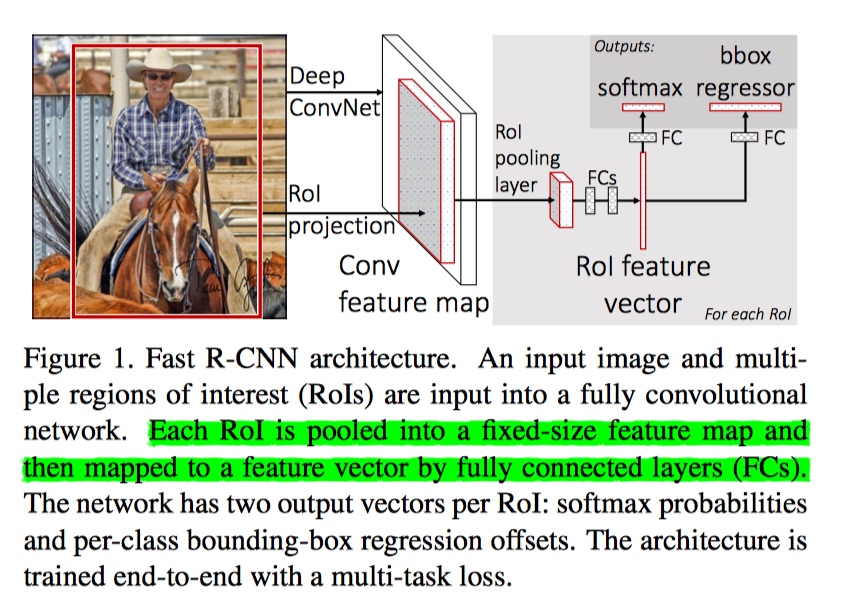 

Fast RCNN 的前向传播如下:
1. Fast RCNN 首先处理 整张图片, 提取整张图片的特征(提取的特征具体为最后一层卷积层输出的 Feature Map),
2. 然后使用 Seletive Search (一种性能不错的 Region Proposal 方法, 不过很慢, 处理一张图片大约需要2s, RPN 也是为了处理该问题提出的, 很优雅)生成 RoIs
3. 通过 RoI 映射, RoI 池化层从后一层卷积层输出的 Feature Map 中提取固定长度的特征向量, 然后该特征向量被馈送到全连接层,最终输入到两个输出层, 一个是K+1(K类+背景类) 路分类器和另一个是 4K categories-specific Bounding Box 坐标的回归器(对于每一个类别都会预测一组 bounding box坐标).
4. 按照物体的类别分组, 然后对于每一类按照预测概率(即 softmax 输出)降序排序, 进行 NMS, 去掉重复框.
假设数据集包括 K 种物体, 加上背景类, 共有 K+1类, [u ≥ 1], 所以 bbox reg(回归器)原本只需要预测 4K 个坐标(论文中也是这么说的), 但是为何 Caffe 的 prototxt 代码中是预测 4(K+1) 个Bounding Box坐标, 而不是4K 个呢? 反正背景类的也用不上, 只是为了数学上运算方便?
在介绍 Fast R-CNN 之前先来介绍一下一些很重要的概念, 对于理解 Fast R-CNN 至关重要.
RoI 池化层
RoI定义: RoI (Region of Interest), 直译为感兴趣的区域, 其实就是一个我们认为很有可能会包含物体的区域, 具体来说就是输入图片上的的一个矩形区域; 每个 RoI 由四元组(x,y,h,w)定义,(x,y) 为一个 RoI 矩形框左上角坐标, (h,w)为矩形的高度和宽度;
RoI 映射: RoI 的矩形框映射与最后一层卷积层输出的 Feature Map 之间的映射关系为, 尺度减小比例大约为卷积网络所有的 DownSampling stride 相乘
那么我们获得 RoI 对应的特征之后, 怎么处理呢?
这就说要这一节的主角啦, RoI 池化层(RoI pooling layer 或 RoI max pooling), 它的作用是将高宽为 h×w RoI 特征窗口划分为包含 H×W 个大小约 \(\frac{h}{H}×\frac{w}{W}\) 的子窗口的网格,然后将每个子窗口中的最大值汇集到相应的输出网格单元中来, 其中 H 和 W 是超参数, 独立于任何特定的 RoI。
Fast R-CNN 网络架构
Fast R-CNN VGG16 在 VGGNet16 网络上做如下 3 点改动:
1. 网络输入变为两个, 即整张图片和Selective Search 提出的 RoIs (即 object proposal)
2. 将 VGGNet 最后一层 Max Pooling 替换为 RoI MaxPooling 层, 输出大小为固定为 H×W 的 Feature Maps(输出固定尺寸的 feature maps 是为了能与后面全连接层协调)
3. 最后一层全连接层使用 2 个全连接层替换, 用于分类(N 类物体 + 背景类的概率分布)和 bbox 框的微调
Fast R-CNN 在 SPPNet 基础上改进, 借鉴了 SPPNet 使用 整张图片 作为网络输入, 然后通过 RoI 映射获取 RoI (输入图片上的矩形块)对应的特征, 大大减少检测网络特征提取所带来的开销, 相比较 R-CNN 来说, 简化了模型训练方法并极大的提高模型的训练速度和推导速度, Fast R-CNN VGG16 模型训练速度是 R-CNN 的10倍, SPPNet 的3倍, 推导速度是 R-CNN 的213x倍, SPPNet 的10x倍, 而且检测性能更好, 在 PASCAL VOC2012 数据集上, mAP 约为 66%(R-CNN ~ 62%).
R-CNN 的网络输入为 RoI 对应图片块, 而不是整张图片和 RoI, R-CNN 基于每个 RoI 图片块都会进行一次的神经网络的前向推导进行特征提取, 由于不同的 RoI 之间有很多重叠的部分, 所以这样的计算方式有多重复计算, 计算冗余很大.
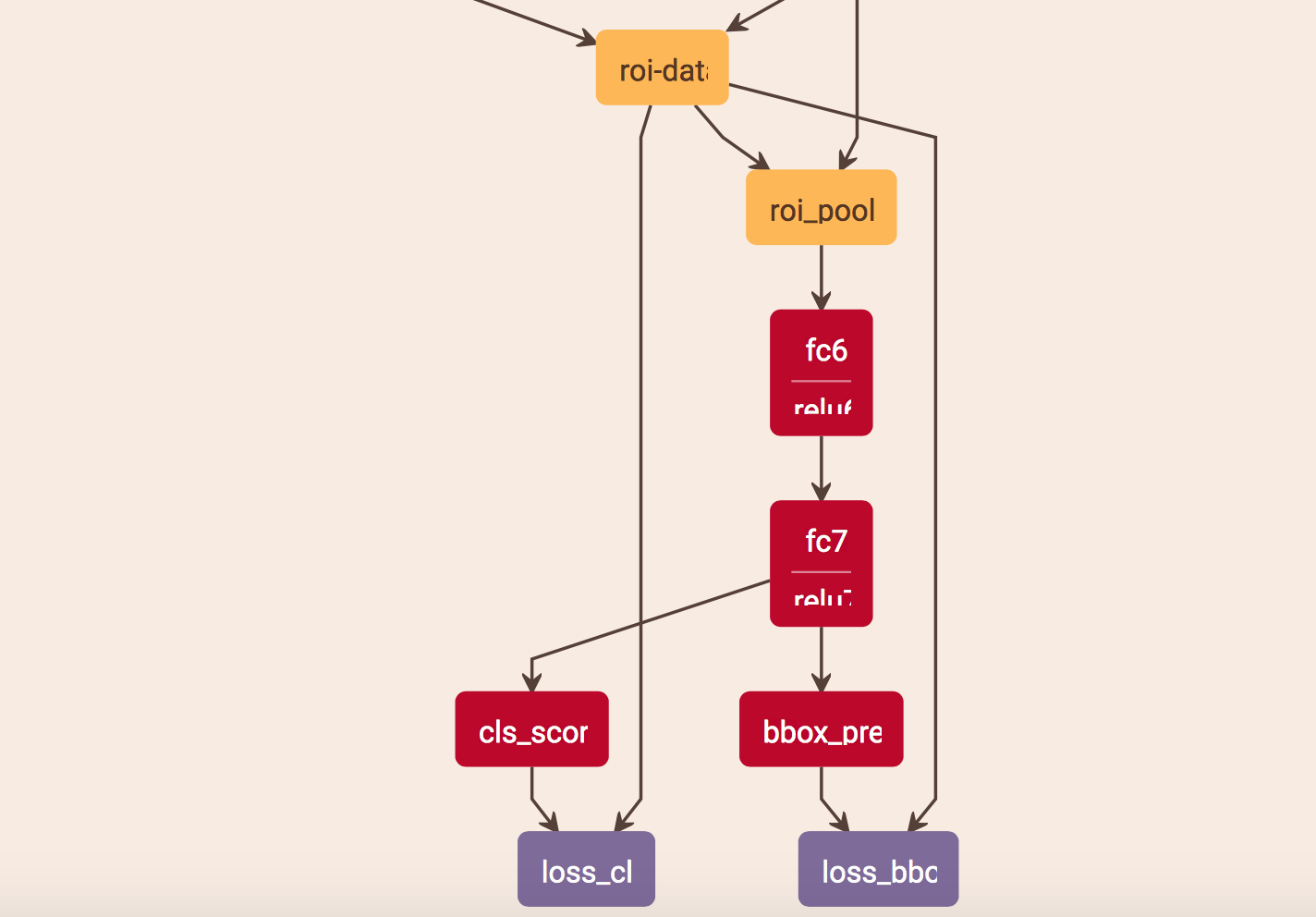
Fast R-CNN 的网络结构大约如下
?, 正则表达式用法, 表示多层 conv-bn-relu Block
Caffe Fast R-CNN VGG16 MSCOCO 网路结构
roi_pool5: 512x7x7
fc6: 4096
fc7: 4096
cls_score: 81
bbox_pred: 324

损失函数设计
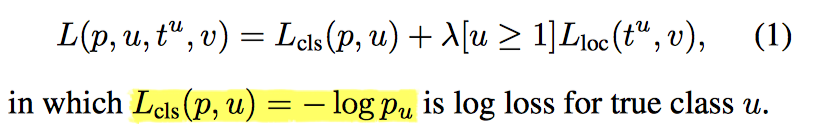 

其实就是交叉熵
 

正例和负例的定义
训练时, 与正例对应的 gt-box 定义为与该 region proposal 有具有最大 IOU 值的 gt-box, 且 IOU 值要大于等于0.5, 与任何 gt-box 的 IOU 值都小于 [0.1, 0.5) 的设置为负例, 小于0.1的做 hard example mining. 正例和负例的样本比例大于为 1:3
Truncated SVD
对于图像分类来说,与卷积层计算量相比,计算全连接层的计算量很少。而对于 Fast R-CNN 检测架构来说,对于一张图片, 我们只需要进行一次前向推导进行特征提取, 而 RoI 池化层之后的全连接层的计算需要进行多次, 这是由于对于一张图片, 需要处理 RoI 的数量很大,比如论文中, 输入 batch 为
2, 随机提取 128 个 RoI, 即每张图片 64 个 RoI, 即一张图片检测过程中, RoI 池化层之前的计算只需要一次, RoI 池化层之后的计算进行 64 次. 实验证明(如下图) 有 近一半 的正向传播时间用于计算全连接层。 通 Truncated SVD 分解, 可以很容易地加速全连接层的计算。
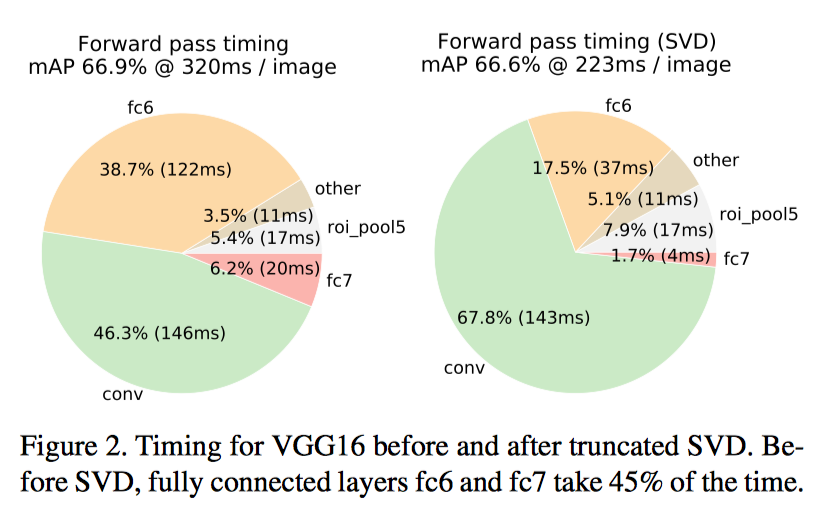 

Fast RCNN 算法的尺度不变性(Scale invariance)
我们采用两种策略实现尺度不变目标检测, 方法如下
方法1: 暴力学习(brute learning), 只输入单尺度, 通过让网络自己学习目标的尺度不变性
方法2: 使用图像金字塔(image pyramids), 提供多尺度输入
定义图片的 scale 为它的最短边的长度(最长边不超过1000, 宽高比保持不变), 论文中这里
1 scale [600]
5 scale [480, 576, 688, 864, 1200]
PASCAL 图片平均大小 384x473, 单 scale 方案需要上采样倍数约为(upsample)1.6, 那么Faster RCNN VGG16 有效的平均步长约为 16/1.6=10 pixels
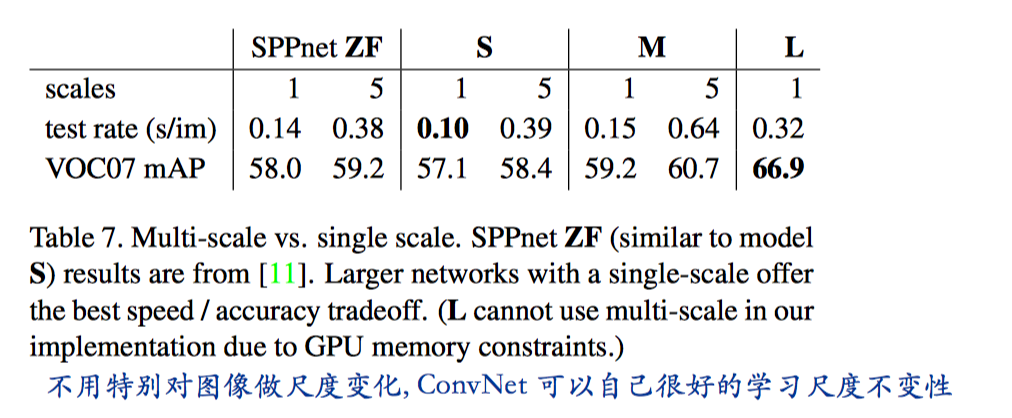 

从上图可知, Faster RCNN 验证了 SPPNet 论文中的观测现象, 单尺度检测的性能几乎和多尺度检测性能一样好(其实还是好了不少, ~1.2%mAP, 就是计算量开销太大, 不太值得, 特别是在深度模型下, 单尺度检测在性能和速度上取得了很好的权衡). \(\color{red}{说明深度 \text{ConvNet} 擅长于学习尺度不变性.}\)
那些层需要微调?
那么所有的卷积层都需要微调吗?
简而言之, 不需要微调所有的卷积层; 在较小的网络中,我们发现第一层卷积层是通用的,与任务无关, 是否微调第一层卷积层对于检测任务的 mAP 没有影响, 而且我们发现微调的卷积层越浅, 对 mAP 的贡献越小, Faster R-CNN VGG16 从第三层卷积层(conv3)开始微调, 而且训练 RoI 池化层之前的卷积层很重要
 

从越浅层开始微调, 需要训练的时间越长.
multi-task training
 

RPN
RPN(Region Proposal Network) 的提出, 将候选框提出过程融入卷积网络中, 通过与检测网络共享特征提取网络, 从而整个目标检测系统是一个单一的,统一的网络。 具体为使用 RPN 的技术代替之前候选框提出算法 Selection Search, 完成候选框(RoI)的提出, 那么 RPN 需要完成两个任务:
- 判断 anchors 中是否包含将要检测的 K 类物体(是或者否), 这里只是判断是否包含物体, 而没有判断到底是什么物体, 即 objectness proposal
- 提出 anchor 对应的 bounding box 的坐标, 即 region proposal
RPN 提出候选框是在输入图片上的坐标, 然后通过 RoI 映射投影到最后一层卷积层输出 Feature Map 上, 那么来看看首先看看 RPN 到底由那些部分组成.
RPN 简介
An RPN is a Fully Convolutional Network that simultaneously predicts object bounds and objectness scores at each position.
在 FRCN 中, 检测网络的运行时间大大减少(大约200ms), 推导时间的瓶颈就在 region proposal 上了, FRCN 使用 SS(Selective Search) 来提出候选框, SS CPU版本(无 GPU 版)执行时间大约为 2s, 相对于 FRCN 检测网络来说, 就慢了个数量级. 鉴于这样一种观察, Faster RCNN 中使用 RPN 代替 SS 进行 region proposal, 用于加快了推导速度, RPN 提出region proposal 的时间约为 0.01s, 比 SS 快了~200倍, 而且性能还要更好.
EdgeBoxes 通过在提出候选框的速度和质量上做权衡, 需要时间大约 0.2s
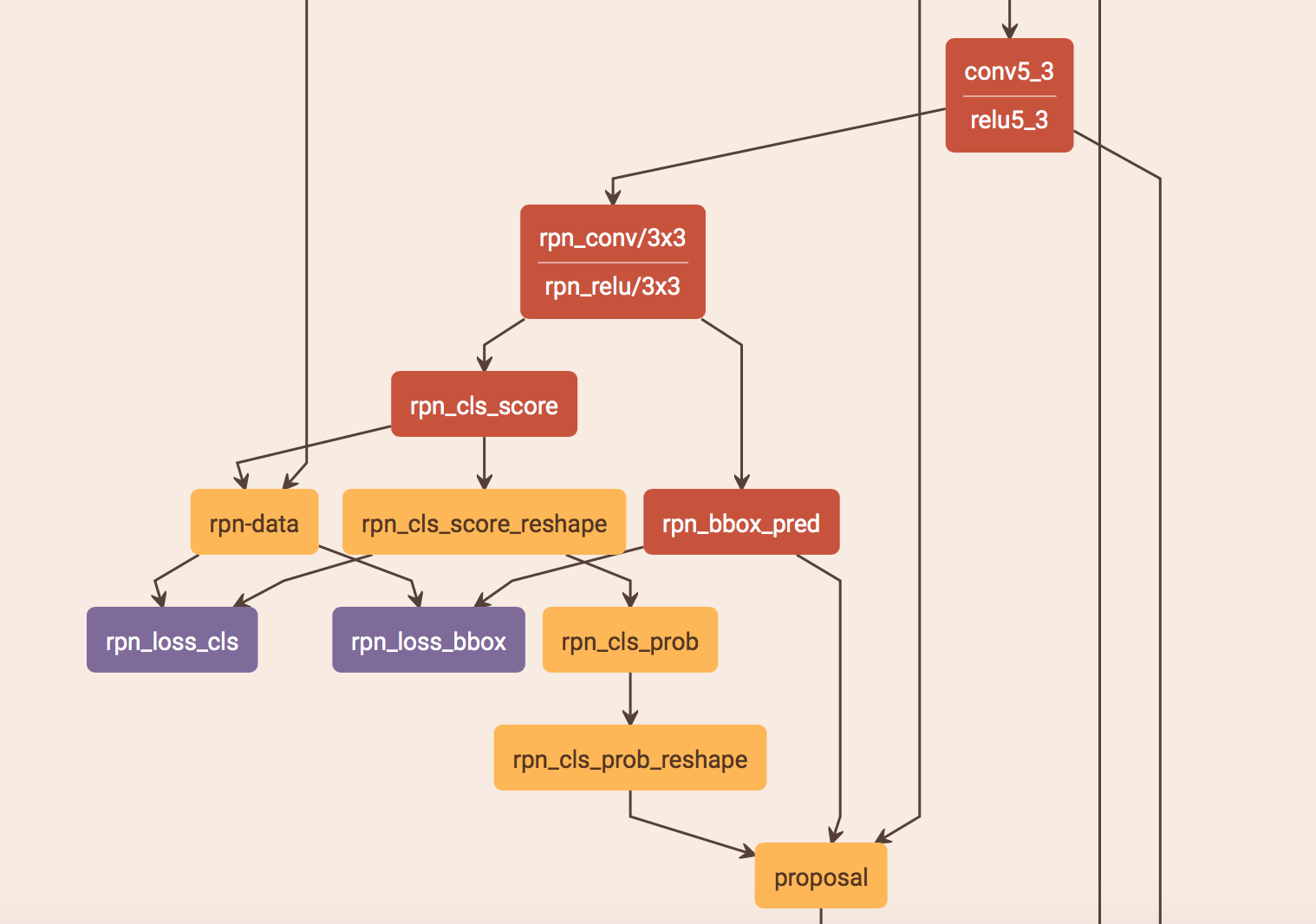
RPN 为全卷积网络(FCN), rpn_cls_score 和 rpn_bbox_pred 为 1x1 卷积
rpn_conv/3x3 num output: 512
// (4个尺度的候选框, 64 128 256 512, 3中宽高比, 共12个候选框)
rpn_cls_score num output: 24 (前景概率+背景概率)x12
rpn_bbox_pred num output: 48 (四个坐标) x 12
rpn_loss_cls: SoftmaxLoss
rpn_loss_bbox: SmoothL1

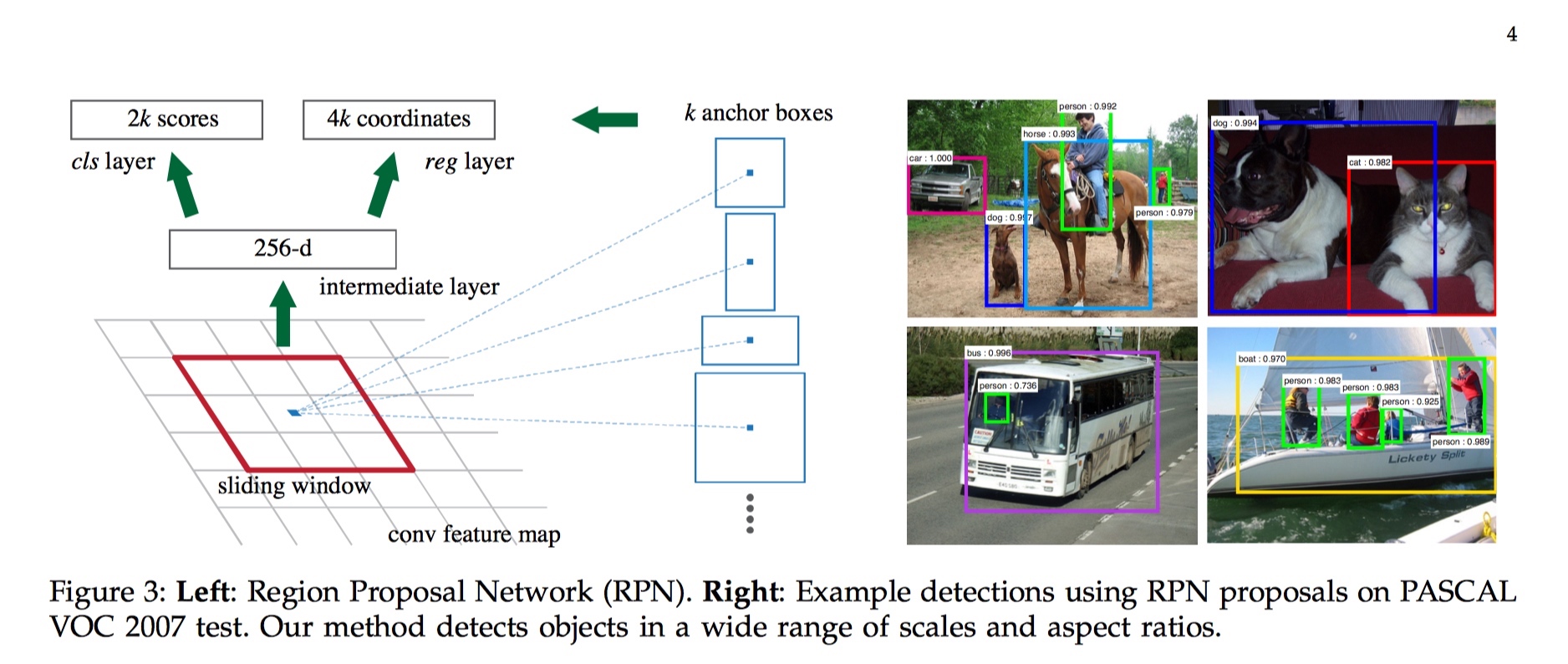
RPN 输入输出就如下,
输入: 整张图片
输出: objectness classification(前景 or 背景) + bounding box regression
\(\color{red}{\bf来说说 RPN 中关键概念 \space anchor}\)
anchor 定义为在最后一层共享卷积层上滑动的 3x3 卷积核的中心点, 称该点为 anchor, 将 anchor 投影到输入图片上, 那么以一个 anchor 为中心,一共可以生成 k 种 anchor boxes(理解为 region proposal 的先验分布就好了); 每个 anchor box 对应有一组缩放比例( scale)和宽高比(aspect). 论文中共使用 3 种 scale(128, 256, 512), 3 种 aspect(1:2, 1:1, 2:1), 所以每个 anchor 位置产生 9 个 anchor boxs.

为何要提出 anchor呢?
来说说 anchor 的优点: 它只依赖与单个 scale 的 images 和 feature map 不过却能解决 multiple scales and sizes 的问题.
为何选择 128 ,256, 512? 论文中用到的网络如 ZFNet 在最后一层卷积层的 feature map 上的一个像素的感受野就有 171(如何计算感受野看这里), filter size 3x3, 3x171=513. 而且论文中提到: 我们的算法允许比底层接受域更大的预测。 这样的预测并非不可能 - 如果只有对象的中间部分是可见的,那么仍然可以大致推断出对象的范围。
在预训练网络卷积层的最后一层 feature map 上进行 3x3 的卷积, anchor 就位于卷积核的中心位置.
记住这里 anchor boxes 坐标对应的就是在图片上的坐标, 而不是在最后一层卷积层 feature map 上的坐标.
anchor box 这么简单粗暴, 为什么有效?
列举了这么多, 相当于穷举了吧, 比如论文中所说,由于最后一层的全局 stride 为 16, 那么1000x600 的图片就能生成大约 60x40x9≈20000个 anchor boxes). 当然列举了这么多 anchor boxes, 这region proposal 也太粗糙啊, 总不能就这样把这么多的质量层次不齐 anchor boxes 都送给 Fast R-CNN来检测吧. 那该怎么剔除质量不好的呢? 这就是后面 RPN 的 bounding box regression 和 objectness classification 要解决的事情:)
有必要先说说 RPN 的 objectness cls 和 bbox regression 有什么用?
一句话就是 "少生优育"
bbox regression: 调整输入的 anchor boxer 的坐标, 使它更接近真实值, 就是一个 bbox regression, 输出称为 RPN proposal, 或者 RoIs. 提高 anchor boxer 的质量
objectness cls: 一些 RPN proposal(anchor boxer经过)可能相互重叠度很高, 为了减少冗余, 通过 objectness cls 的输出的分数 score 对这些 RPN proposal 做 NMS(non-maximum suppression), 论文中设置 \(\color{red}{threshold 为 0.7}\), 只保留 threshold < 0.7 的RPN proposal, 减少 anchor boxes 的数量
RPN 的任务是什么?
训练 RPN 网络来选择那些比较好的 anchor boxes.
因为现在我们要训练 RPN, 我们只提出了 anchor boxer, 却不知道这些 anchor boxes是不是包含物体, 就是没有标签啊! 那么问题来了? objectness cls 分类器和 bbox 回归器训练时没有标签啊. 怎么办?
办法就是使用 gt-bbox(ground-truth bounding box) 为指标生成 lable, 注意这里我们只是检测图片中有没有物体, 而不判断是哪一类物体.
positive anchor
从 gt-box 的角度来看的话, 我们希望每一个 gt-box 至少要有一个 anchor box 来预测它, 所以首先, 我们将与这个 gt-box 有最大 IoU 值 anchor box 标记为 positive anchor; 然后, 我们将与任意一个 gt-box 的 IoU 大于等于 0.7 的 anchor box 标记为 positive anchor;
这时候我们获得了 RPN 分类器的 label. 那么如何获取 bbox 回归器的 lable 呢?
在 positive anchor 中, 从 anchor-box 的角度出发, 选择最容易预测的 gt-box 进行预测, 即选择与该 anchor-box 具有最大 IoU 的 gt-box 进行预测(即该 gt-box 作为回归目标); 可以看出, 一个 gt-box 可以由多个 anchor box 负责, 但是一个 anchor box 最多负责预测一个 gt-box.
(上面的逻辑是anchor_target_layer.py 代码实现中的逻辑)
从理论角度来说, 可能还是存在 gt-box 没有被任何一个 anchor box 预测(虽然 gt-box 与某个 anchor-box 具有最大 IoU, 但是该 anchor-box 与其他的 gt-box 有最大 IoU, 而且理论上说 可能某个 anchor box 与多个 gt-box 有最大 IoU, 那么 anchor box 只会选择其中一个预测), 当然只是理论上, 实际上, 这要物体的重叠度不是很高, 这就不是问题, 而且 anchor box 也足够的多.
negative anchor
与任意 gt-box 的 IOU < 0.3, 即标记为 negative anchor, 标记为 0, 即不包含物体, 是背景, 从后面的损失函数知道, 背景不参与回归损失函数.
样本不平衡问题
如在二分类中正负样本比例存在较大差距,导致模型的预测偏向某一类别。如果正样本占据1%,而负样本占据99%,那么模型只需要对所有样本输出预测为负样本,那么模型轻松可以达到99%的正确率。一般此时需使用其他度量标准来判断模型性能。比如召回率 ReCall
RPN 网络训练时, 从一张图片随机抽取 256 个 anchor box, 其中 positive anchor, negative anchor 的比例大于为 1:1(由于 negative anchor 的数量比 positive anchor 的个数多得多, 所以如果使用全部的 anchor box, 那么损失函数就与偏向负例), 如果 positive anchor 少于 128个, 使用 negative anchor 补全到256个.
- IOU 位于 positive anchors, negative anchors 之间 anchor boxer 背景和物体掺杂, 的对于训练目标没有贡献, 不使用, 标记为 -1
- RPN 中 positive anchor 阈值为 0.7, FRCN 中 positive anchor 为 0.5, 可能是由于 RPN 中大约有 20000 个 anchor boxer, 而 RPN 提出的 RoIs 为 2000 个, RPN 为了去掉更多的 bbox, 所以阈值为选择的高一点?
损失函数设计
注意一点, 每个 regressor 只负责一个 (scale, aspect), 不与其他 regressor 共享权重, 所以需要训练 k 个 regressor, 即对于每个 anchor box, 都会预测一组坐标, 每组包含 k 个 bounding box 坐标
其他不多说, 只贴贴公式
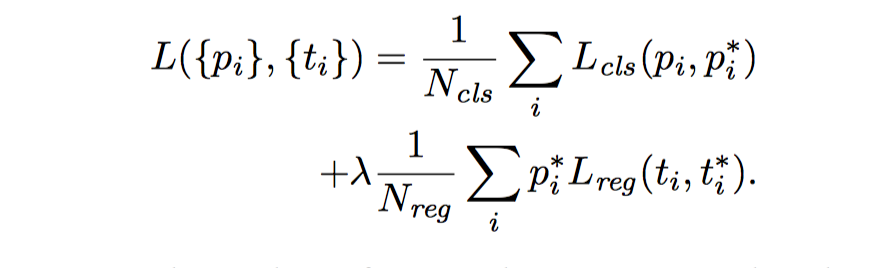 

In our current implementation (as in the released code), the cls term in upper Eqn is normalized by the mini-batch size (i.e., N_cls = 256) and the reg term is normalized by the number of anchor locations (i.e., N_reg ∼ 2, 400(1000/16x600/26~240)). By default we set λ = 10, and thus both cls and reg terms are roughly equally weighted.
 

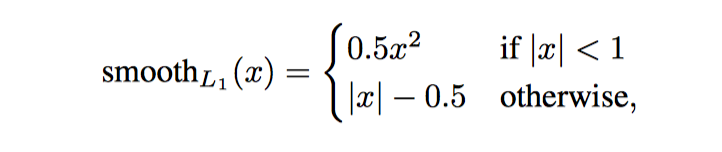 

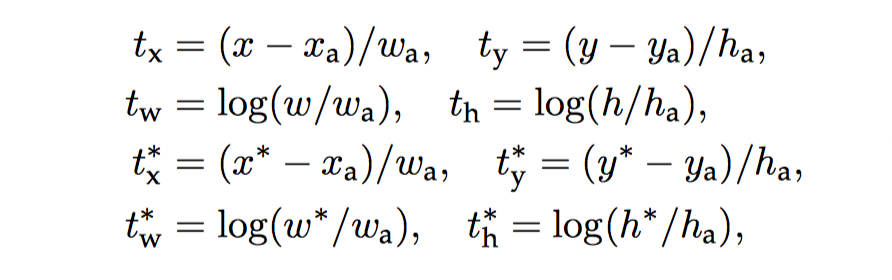 

- \(p^*_i\) 为一个 batch 中的第 i 个 anchor box 的真实标签, \(p_i\) 为分类器预测概率, 如果是 positive anchor, \(P^*_i\)为 1, 否则为 0.
- \(L_{reg}(t_i, t_i^*) = smooth_{L1}(t_i-t_i^*)\)
- \(p^*_iL_{reg}\) 表示 regression loss 只会被 positive anchor 激活.
- anchor boxes 的坐标表示为 (x, y, w ,h), (x, y) 为 box 的中心坐标.
- \(x,\space x_a, \space x^*\) 分别代表 bbox regressor 的预测坐标, anchor box 的坐标, 和 anchor box 对应的 gt-box 坐标.
训练
交替训练: 在这个解决方案中,我们首先训练 RPN,并使用这些 proposal 来训练 Fast R-CNN。 由 Fast R-CNN 调节的网络然后用于初始化 RPN,并且该过程被重复。
细节:
re-size image 最短边为 600 像素
total stride for ZFNet, VGGNet 16 pixels
跨图像边缘的 anchor boxes 处理
跨越图像边界的 anchor boxes 需要小心处理。 在训练期间,忽略了所有的跨界 anchor boxes,所以他们不会影响损失函数。 对于典型的1000×600图像,总共将有大约20000个(≈60×40×9)anchor boxes。 在忽略跨界锚点的情况下,每个图像有大约 6000 个 anchor boxes 用于训练。 如果跨界异常值在训练中不被忽略,它们会引入大的难以纠正误差项的,并且训练不会收敛。 然而,在测试过程中,我们仍然将完全卷积RPN应用于整个图像。 这可能会生成跨边界anchor boxes,我们将其剪切到图像边界(即将坐标限制在图片坐标内)。
一些实验总结
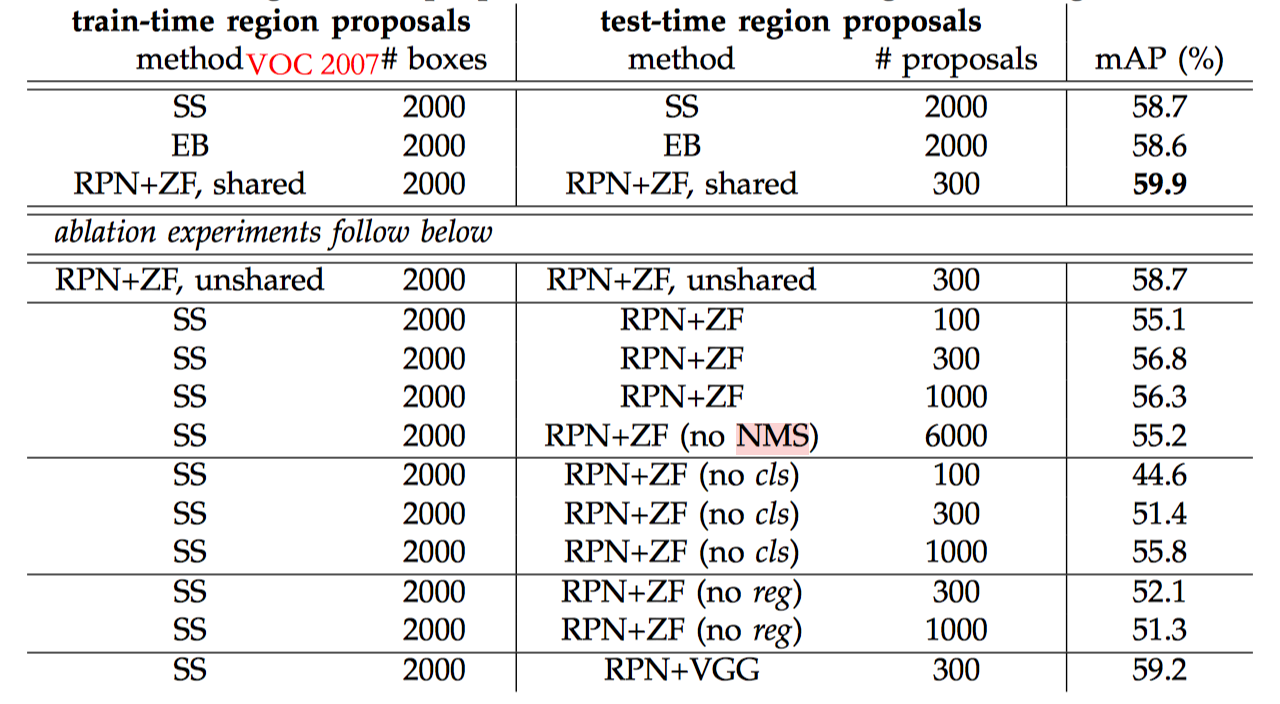 

RPN+FRCN( ZFNet), mAP=59.9
RPN+FRCN( VGGNet), mAP=69.9
- NMS 不会降低检测性能. 通过 NMS 得到 300 个 proposal的测试mAP为 55.1%, 使用top-ranked 6000个 proposal的mAP为 55.2%, 从而说明经过NMS之后的 top ranked proposal都是很精确的.
- 移除 RPN 的 classification(cls) 的话(自然没法做 NMS, NMS 就是依据cls 来做的), 当 proposal 很少时, 精确率下降很大, N = 100 时, mAP 为44.6%, 这说明了 cls 的得分越高的 proposal 中包含物体的可能性越高.
- 移除 RPN 的 boundingbox regression(reg) 的话, mAP 下降到 52.1% 说明了多 scale, 多 aspect 的 anchor boxes 并不足以应对精确检测, regressed box bounds 可以产生高质量的 proposals
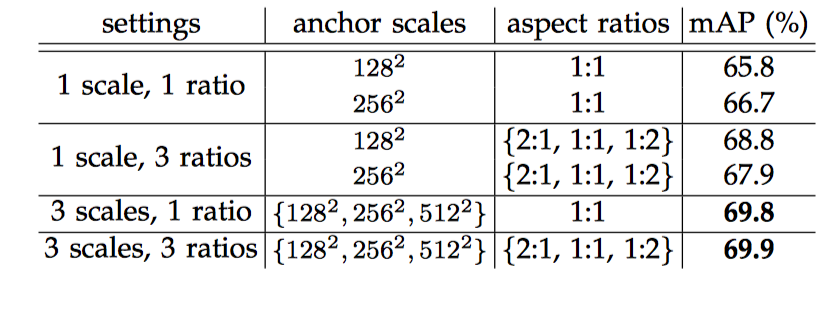
- 对于超参 scale, aspect 敏感性如下


 浙公网安备 33010602011771号
浙公网安备 33010602011771号